halcon字符识别结果为“\x1A”
发布时间:2023年12月29日

最近在做OCR字符识别,遇到了点小问题,记录一下。
由于是项目初期,所以我就打算调halcon自带库去识别一下看看效果如何,结果分类器的结果显示为“\x1A”。如下图
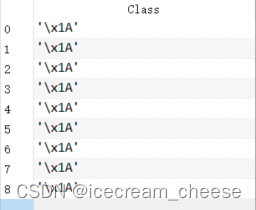
百度搜了一圈没有这个解答,所以就在halcon帮助文档里面找答案。
查看mlp分类器算子说明,有如下提示:
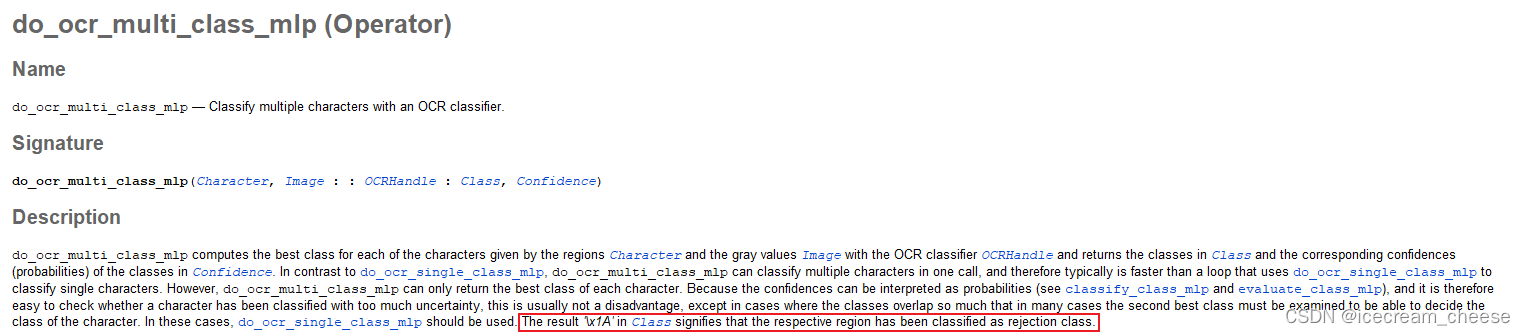
所以这里就可以找到解决方法,在引入字符库的时候,每个字符类型都会提供2中方案。如下图:

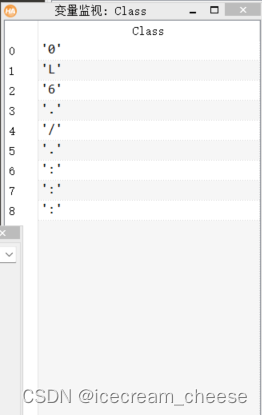
所以我们改一下,引用NoRej.occ。
那么问题到这里就解决了。
文章来源:https://blog.csdn.net/aizzl97/article/details/135293508
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用Python编写一个渗透测试探测工具
- 使用Android studio创建一个新项目并运行
- 外包干了2个月,技术退步明显...
- rip实验
- 从CNN ,LSTM 到Transformer的综述
- ChatGPT Plus续费充值,到账延迟,如何申诉?
- 【深度学习:(Contrastive Learning) 对比学习】深入浅出讲解对比学习
- 关于Redis的事务
- 域中的主机报错1231解决办法
- pytest-fixtured自动化测试详解