JMM内存模型
JMM
介绍
Java内存模型(Java Memory Model,JMM)JMM主要是为了规定了线程和内存之间的一些关系。
对于 Java 来说,你可以把 JMM 看作是 Java 定义的并发编程相关的一组规范,除了抽象了线程和主内存之间的关系之外,其还规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
根据JMM的设计,系统存在一个主内存(Main Memory),Java中所有变量都储存在主存中,对于所有线程都是共享的。每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是在工作内存中进行,线程之间无法相互直接访问,变量传递均需要通过主存完成。
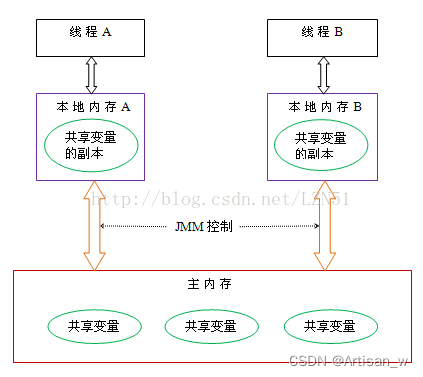
从上图来看,线程 1 与线程 2 之间如果要进行通信的话,必须要经历下面 2 个步骤:
线程 1 把本地内存中修改过的共享变量副本的值同步到主内存中去。
线程 2 到主存中读取对应的共享变量的值。
也就是说,JMM 为共享变量提供了可见性的保障。
不过,多线程下,对主内存中的一个共享变量进行操作有可能诱发线程安全问题。举个例子:
线程 1 和线程 2 分别对同一个共享变量进行操作,一个执行修改,一个执行读取。
线程 2 读取到的是线程 1 修改之前的值还是修改后的值并不确定,都有可能,因为线程 1 和线程 2 都是先将共享变量从主内存拷贝到对应线程的工作内存中。
与JVM的区别
jmm中的主内存、工作内存与jvm中的Java堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域。从更低层次上说,主内存就直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(甚至是硬件系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问读写的是工作内存。
指令重排
Java 源代码会经历 编译器优化重排 —> 指令并行重排 —> 内存系统重排 的过程,最终才变成操作系统可执行的指令序列。
指令重排序可以保证串行语义一致,但是没有义务保证多线程间的语义也一致 ,所以在多线程下,指令重排序可能会导致一些问题。
编译器和处理器的指令重排序的处理方式不一样。对于编译器,通过禁止特定类型的编译器重排序的方式来禁止重排序。对于处理器,通过插入内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)的方式来禁止特定类型的处理器重排序。指令并行重排和内存系统重排都属于是处理器级别的指令重排序。
原子性
一次操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么都不执行。在 Java 中,可以借助synchronized、各种 Lock 以及各种原子类实现原子性。synchronized 和各种 Lock 可以保证任一时刻只有一个线程访问该代码块,因此可以保障原子性。各种原子类是利用 CAS (compare and swap) 操作(可能也会用到 volatile或者final关键字)来保证原子操作。
可见性
当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。在 Java 中,可以借助synchronized、volatile 以及各种 Lock 实现可见性。如果我们将变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
有序性
由于指令重排序问题,代码的执行顺序未必就是编写代码时候的顺序。我们上面讲重排序的时候也提到过:指令重排序可以保证串行语义一致,但是没有义务保证多线程间的语义也一致 ,所以在多线程下,指令重排序可能会导致一些问题。在 Java 中,volatile 关键字可以禁止指令进行重排序优化。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ????—设计-七个-05-原则-模式—????
- 统计和绘图软件GraphPad Prism mac功能特点
- Spring Boot项目Jar包加密:防止反编译的安全实践
- 部署PXE远程安装服务
- C#使用条件语句判断用户登录身份
- Vue - 多行文本“展开、收起”功能
- 【编码魔法师系列_构建型4】原型模式(Prototype Pattern)
- 线性回归和逻辑回归对比学习-含代码和数据
- 如何解决安装Windows11时出现“这台电脑无法运行Windows11”
- 【洛谷算法题】P4414-[COCI2006-2007#2] ABC【入门2分支结构】Java题解