python爬虫代码示例:爬取京东详情页图片
发布时间:2024年01月19日
python爬虫代码示例:爬取京东详情页图片
一、Requests安装及示例
爬虫爬取网页内容首先要获取网页的内容,通过requests库进行获取。
-
GitHub: https://github.com/requests/requests
-
PyPl: https://pypi.python.org/pypi/requests
-
官方文档:http://wwwpython-requests.org
-
中文文档:http://docs.python-requests.org/zh CN/latest
安装
pip install requests示例代码
import requestsurl??=?"http://store.weigou365.cn"res?=?requests.get(url)res.text
执行效果如下:

二、Selenium库
爬虫爬取网页有时需要模拟网页行为,比如京东、淘宝详情页面,图片加载随着滚动自动加载的。这种情况我们就要进行浏览器模拟操作才能获取要爬取的数据。
Selenium 是一个用于自动化浏览器操作的开源框架,主要用于网页测试,支持多种浏览器包括 Chrome、Firefox、Safari 等。它提供了一系列的API,允许你模拟用户在浏览器中的行为,例如点击按钮、填写表单、导航等。
官方网站: https://sites.google.com/a/chromium.org/chromedriver114之前版本:http://chromedriver.storage.googleapis.com/index.html116版本:https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/116.0.5845.96/win64/chromedriver-win64.zip117之后的版本:https://googlechromelabs.github.io/chrome-for-testing/
安装
pip install selenium示例代码
from selenium import webdriverbrowser?=?webdriver.Chrome()browser.get("https://baidu.com/")print(browser.title)browser.quit()?
三、爬取京东详情页面代码
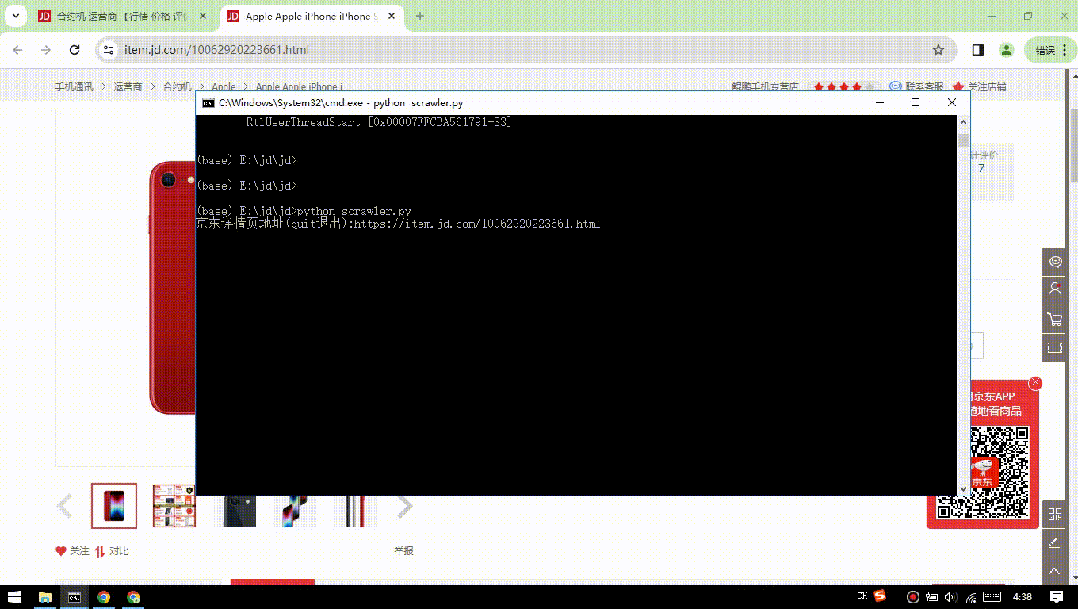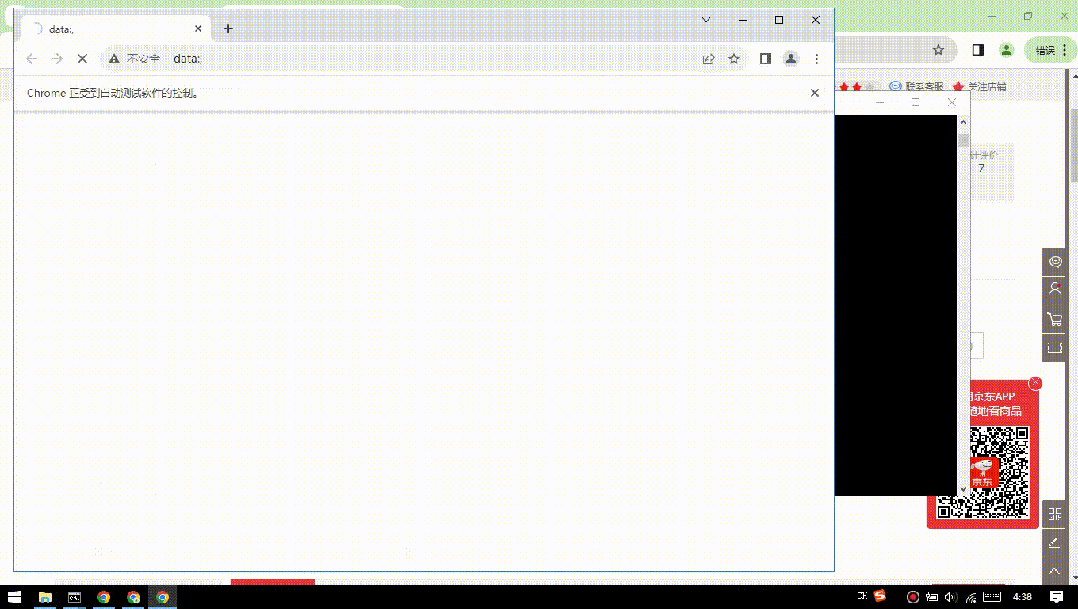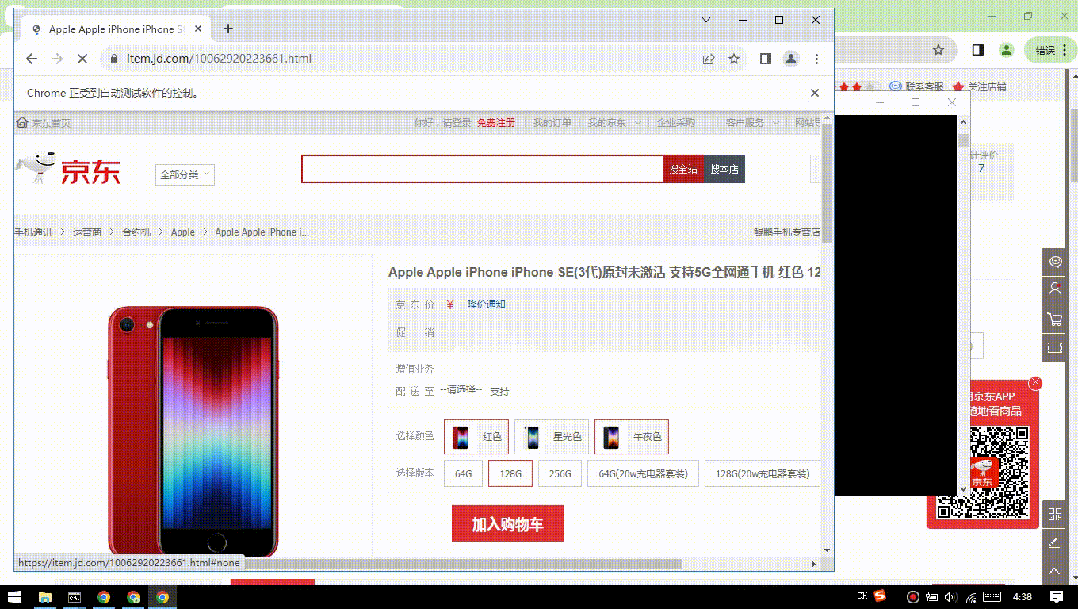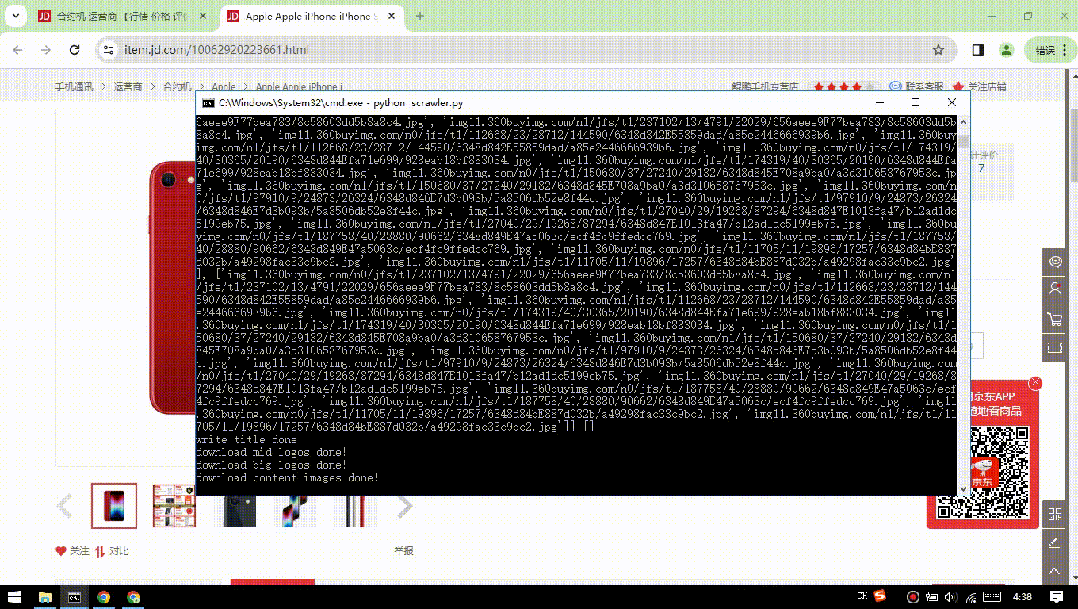
from selenium import webdriverfrom lxml import etreeimport timeimport openpyxlimport reimport osimport requestsheaders = {'content-type': 'application/json', 'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}def exchange_url(small,big,flag=0):lists = small[0].strip('/').split('/')return lists[0] + "/n" + str(flag) + "/" + big[0]def get_image_path(model=""):path = "./imgs/" + str(time.strftime("%Y%m%d%H%M", time.localtime()) ) + "/"if model != "":path += modelif(os.path.exists(path)):passelse:os.makedirs(path)return pathdef download_img(title,url,headers,model=""):img_data = requests.get(url,headers=headers).contentfilename = url.strip('/').split('/').pop()if model != "":filename = model + "_" + filenameimg_path = os.path.join(get_image_path(model),filename)with open(img_path,'wb') as f:f.write(img_data)returndef get_source(driver,url):#发起请求driver.get(url)time.sleep(1)???#休息一秒然后操纵滚轮滑到最底部,这时浏览器数据全部加载,返回的源码中是全部数据driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")time.sleep(2)#得到代码source = driver.page_source#返回source源码以供解析return sourcedef writeExcel(title):wb = openpyxl.load_workbook("records.xlsx")ws = wb.activepath = get_image_path()path = os.path.abspath('.') + path.strip('.')ws.append([title,path])wb.save("records.xlsx")def get_page_title(html):db_title = html.xpath('//*[@class="itemInfo-wrap"]/div[@class="sku-name"]/text()')if(len(db_title) == 1):return db_title[0].replace("\n","").replace('\'',"").replace(" ","")return db_title[1].replace("\n","").replace('\'',"").replace(" ","")def get_page_logos(html):db_logo_items = html.xpath('//*[@id="spec-list"]/ul[@class="lh"]/li')bigs = mids = []for db_logo_item in db_logo_items:db_logo_small = db_logo_item.xpath("img/@src")db_logo_big = db_logo_item.xpath("img/@data-url")bigs.append(exchange_url(db_logo_small,db_logo_big))mids.append(exchange_url(db_logo_small,db_logo_big,1))return [mids,bigs]def get_page_content(html):images = html.xpath('//div[@id="J-detail-content"]/p/img/@href')#pattern = re.compile(r"background-image:url\(([^)]*)",re.S)return imagesdef process(url):try:driver = webdriver.Chrome()driver.implicitly_wait(10)content = get_source(driver,url)html = etree.HTML(content)title = get_page_title(html)logos = get_page_logos(html)images = get_page_content(html)print(title,logos,images)#记录标题和图片地址writeExcel(title)print("write title done!")#下载中图for mid_url in logos[0]:img_url = "http://" + mid_url.replace("http","").replace(":","").replace("//","")download_img(title,img_url,headers,model="mid")print("download mid logos done!")#下载大图for big_url in logos[1]:img_url = "http://" + big_url.replace("http","").replace(":","").replace("//","")download_img(title,img_url,headers,model="big")print("download big logos done!")for img_url in images:img_url = "http://" + img_url.replace("http","").replace(":","").replace("//","")download_img(title,img_url,headers,model="imgs")print("download content images done!")finally:driver.close()if __name__ == "__main__":while(True):url = input('京东详情页地址(quit退出):')if(url == "quit"):break;process(url)????
上面代码保存.py文件。通过下面命令执行
python scrawler.py执行如下:
文章来源:https://blog.csdn.net/onebound_linda/article/details/135691628
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第八章[字符串]:8.1:字符串f-string格式化
- MySQL 系统表
- MATLAB - 加载预定义的机器人模型
- 怎么节约cdn流量- 速盾网络(Sudun)
- 解决 微信公众号token一直莫名其妙出现token过期问题
- 树莓派Ubuntu系统安装OpenCV教程
- MySQL篇—通过Clone插件进行本地克隆数据(第二篇,总共三篇)
- 打印乘法表(Java版)
- Ubuntu18.04安装GTSAM库(亲测可用)
- 大路灯和护眼台灯哪个好?2024五款大路灯推荐