Java序列化
一、什么是Java序列化?
- 序列化:把Java对象转换为字节序列的过程
- 反序列:把字节序列恢复为Java对象的过程
二、为什么需要序列化?
Java对象是运行在JVM的堆内存中的,如果JVM停止后,它的生命也就戛然而止。
如果想在JVM停止后,把这些对象保存到磁盘或者通过网络传输到另一远程机器,怎么办呢?磁盘这些硬件可不认识Java对象,它们只认识二进制这些机器语言,所以我们就要把这些对象转化为字节数组,这个过程就是序列化啦~
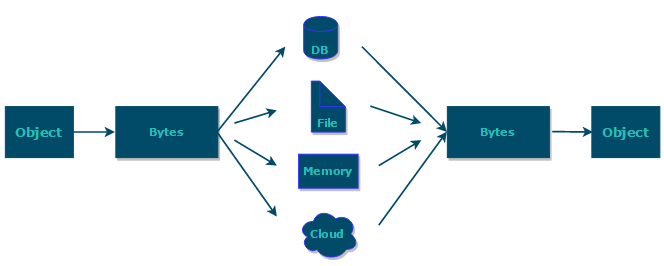
三、序列化用途
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
四、常见序列化协议有哪些?
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存在安全问题。比较常用的序列化协议有 Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。
像 JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差,一般不会选择
JDK 自带的序列化方式
JDK 自带的序列化,只需实现 java.io.Serializable接口即可。
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Builder
@ToString
public class RpcRequest implements Serializable {
private static final long serialVersionUID = 1905122041950251207L;
private String requestId;
private String interfaceName;
private String methodName;
private Object[] parameters;
private Class<?>[] paramTypes;
private RpcMessageTypeEnum rpcMessageTypeEnum;
}
serialVersionUID 有什么作用?
序列化号 serialVersionUID 属于版本控制的作用。反序列化时,会检查 serialVersionUID 是否和当前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的 serialVersionUID。
Kryo
Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。
另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 干货|移动端App自动化之触屏操作自动化
- 第九部分 使用函数 (四)
- L1-041:寻找250
- 376. 摆动序列 - 力扣(LeetCode)
- Uni-App三甲医院、医保定点三甲医院在线预约挂号系统源码
- 基于SpringBoot+Vue的农村电商对接平台(源码+文档+包运行)
- 计算机网络(10):下一代因特网
- 【全网首发】Linux系统最全笔记(建议收藏)
- 漏洞补丁修复之openssl版本从1.1.1q升级到1.1.1t以及python版本默认2.7.5升级到2.7.18新版本和Nginx版本升级到1.24.0
- 无人机支持的空中无蜂窝大规模MIMO系统中上行链路分布式检测