ClickHouse基础介绍
目录
?
前言
????????11月份的时候,有幸收到OceanBase官方的邀请,代表部门去参加了OceanBase2023年度发布大会(对OceanBase不了解的兄弟盟,后面有空我会发表一些关于Ob的文章哈),之前公司国产化信创适配改造过程中,对于OB有了一定的实践以及了解。整个大会让我印象最深刻的就是OceanBase列存实验室版本同业内一流的大宽表数据库ClickHouse现场进行了跑分PK。结果显示,在同等硬件条件下,OceanBase的性能达到了ClickHouse的同一水平,甚至比ClickHouse还高一点点。之前对ClickHouse基本不了解,会后对这兄弟产生了好奇。利用业余时间了解了一下,做了下总结。

1、什么是clickhouse
clickhouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯最大的搜索公司Yandex开发,于2016年开源,采用c++开发
2、OLAP场景的关键特征
- 大多数是读请求
- 数据总是以相当大批的写入(>1000rows)
- 不修改已添加的数据
- 每次查询都从数据中读取大量的行,但同时仅需要少量的列
- 宽表,即每个表包含大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50ms
- 列中的数据相对较小,如数字和短字符串
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对于数据一致性要求低
- 每个查询除了一个大表外,其余都很小
- 查询结果明显小于源数据,或者说,数据被过滤或聚合后能够被盛放在内存中
3、列式存储更适合于OLAP场景的原因
列式数据对于大多数查询而言,处理速度至少提高了100倍
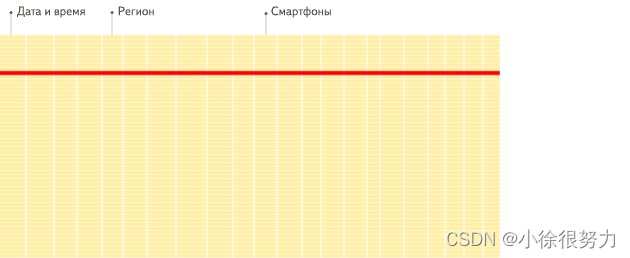
行式:
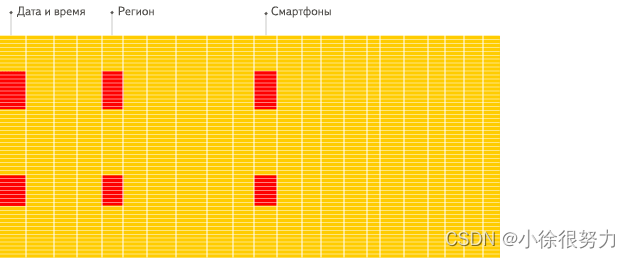
列式:
为何会有以上情况的发生?
- 针对分析类查询,通常只需要读取表中一小部分列。在列式数据库中你可以只读取你需要的数据。如果只需要读取100列中的5列数据,这将帮助你减少20倍的io消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储也容易压缩。
- 由于io的降低,这将帮助更多的数据被系统缓存。
4、clickhouse的独特功能
- 真正的列式数据库管理系统,即除了数据本身外不应该存在其它额外的数据。这意味着为了避免在值旁边存在它们的长度,必须支持固定长度数值类型
- 数据压缩,数据压缩在性能提升上有很关键的作用
- 数据存储,clickhouse专门设计在机械盘工作,因此存储成本更低。如果有ssd和额外ram也将充分利用
- 多核并行处理
- 多服务器分布式查询处理,在clickhouse中,数据可以保存在不同的shard上,每个shard都由一组用于容错的replica组成,查询可以并行的在所有shard上进行处理,这对用户是透明的
- 大部分情况兼容标准sql
- 向量引擎,数据不仅以列存储,还以向量块来处理。因此可以提高cpu效率
- 实时数据更新,click house支持具有主键的表,为了能够快速在主键范围内快速执行扫描,使用合并树对数据增量排序,因此支持数据不断添加到表中,添加时没有锁表
- 索引,通过主键对数据进行物理排序这使得你以较低延迟(数毫秒)接收特定值或范围的数据
- 适用于在线查询,低延迟意味着可以立即执行查询
- 支持近似计算,click house提供各种允许牺牲数据精度情况下对查询数据进行加速的方法
- 支持数据复制和数据完整性,clickhouse使用异步复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其它副本,以保证系统在不同副本上保持相同的数据。大多数情况下,clickhouse能在故障后自动恢复,在一些少数情况下需要手动恢复
5、clickhouse的缺点
- 没有完整的事务支持
- 缺乏高速率低延迟修改或删除已存在数据的能力,有可用于批量更新和删除数据的能力
- 稀疏索引使得clickhouse不适合通过其键检索单行的定点查询
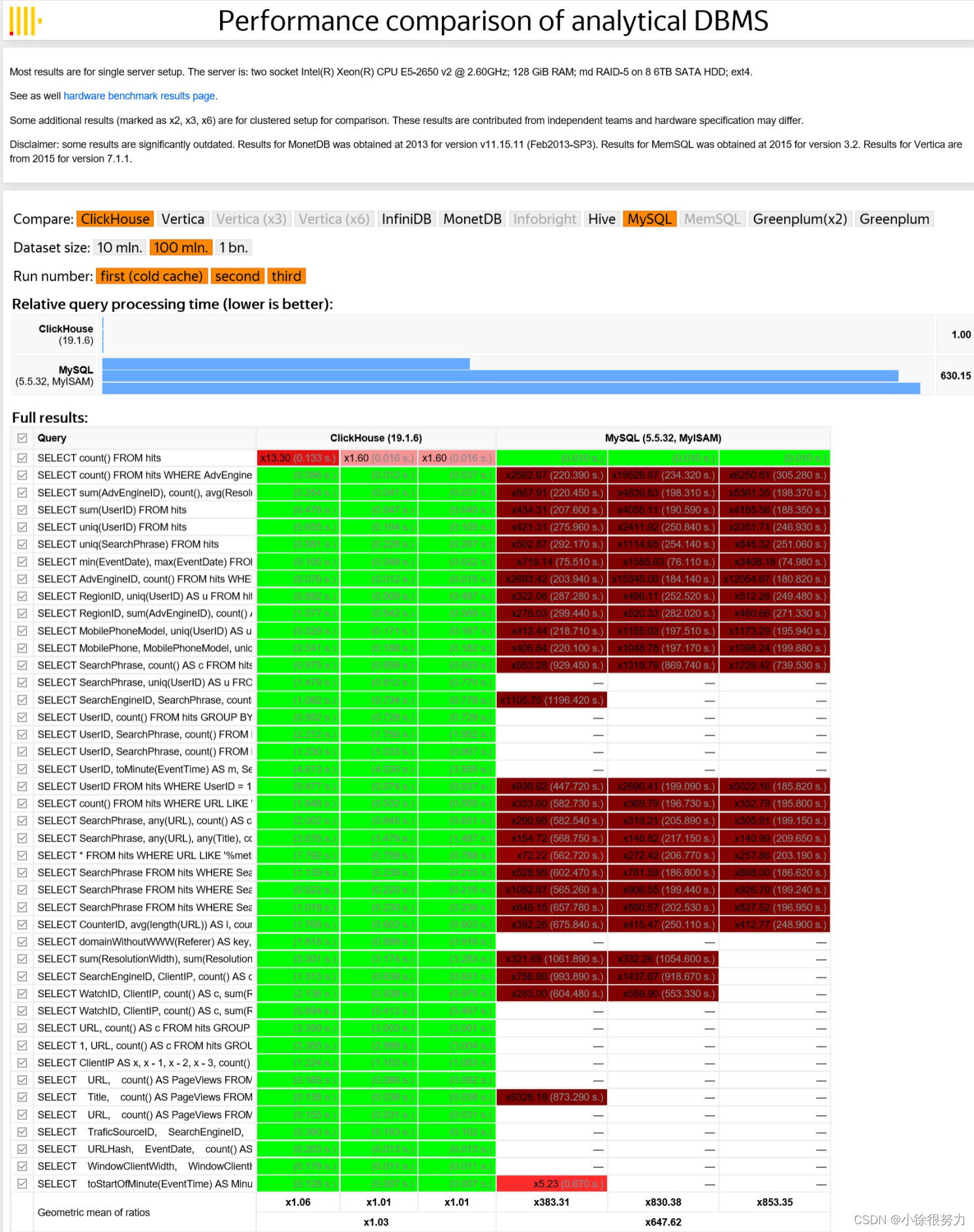
6、性能
根据Yandex的内部测试结果,clickhouse表现出了同类可比较产品更优的性能(长查询的吞吐量最高,短查询的延迟最低)
?
6.1、单个大查询的吞吐量
吞吐量可以以每秒处理的行数或每秒处理的字节数来衡量。如果数据被放置在page cache缓存的情况下,则不太复杂的查询在现代硬件上大约2-10G/s的速度在单个服务器上处理未压缩数据(对于简单查询,速度可以达到30G/s)
对于分布式处理,处理速度几乎是线性扩展的,但这受限于聚合或排序的结果不是那么大的情况下
6.2、处理短查询的延迟时间
如果一个查询使用主键且没有太多行(几十万行)进行处理,并且查询没有太多列,那么在数据被page cache的情况下,它的延迟应该小于50ms(最佳情况应该小于10ms)。否则,延迟取决于数据的查找次数。如果使用HDD,在数据没有加载的情况下,查询所需要的延迟可以通过一下公式计算得知:查找时间(10ms)*查询的列的数量*查询的数据库的数量
6.3、处理大量短查询的吞吐量
在相同情况下,clickhouse可以在单个服务器每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景,因此我们建议每秒最多100次查询
6.4、数据的写入性能
建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。可以使用多个insert并行插入,这将使性能线性提升
?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深度学习 pytorch的使用(张量1)
- SOLIDWORKS Routing2024新功能
- 通过myBatis将sql语句返回的值自动包装成一个java对象(1)以及SqlSessionFactory
- 广西高端建筑模板厂家
- 阿里云RDS MySQL 数据如何快速同步到 ClickHouse
- Java 的PostConstruct 、PreDestroy的简介
- Secondo数据库下载安装
- 排序算法:快速排序、堆排序
- Ts自封装WebSocket心跳重连
- Java毕业设计第96期-基于springboot的图书后台管理系统