ElasticSearch的集群管理命令
ElasticSearch版本
{
"name" : "data-slave1",
"cluster_name" : "data-es",
"cluster_uuid" : "xxxxxxxxxx-eMwxw",
"version" : {
"number" : "7.2.1",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "fkg6eb20",
"build_date" : "2021-07-24T17:58:29.979462Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
集群管理命令
Cat API
cat aliases
cat aliases 命令用于显示索引的别名,也包括过滤器和路由信息。
GET /_cat/aliases?v

- alias 别名
- index 索引别名指向
- filter 过滤规则
- routing.index 索引路由
- routing.search 搜索路由
cat allocation
cat allocation命令可以查看每个节点分配的分配数量以及它们所使用的硬盘空间大小
GET /_cat/allocation?v

- shards 分片数
- disk.indices 索引index占用的空间大小
- disk.used 已用磁盘空间
- disk.avail 可用磁盘空间
- disk.total 磁盘空间总量
- disk.percent 磁盘已使用百分比
- host 节点主机地址
- ip 节点ip
- node 节点名称
cat count
cat count 命令可以快速查询整个集群或者单个索引的文档数量。
GET /_cat/count?v

- epoch 自标准时间(1970-01-01 00:00:00)以来的秒数
- timestamp 时间,存在8小时时间差问题
- count 文档总数
GET /_cat/count/[索引名称]?v
cat fielddata
cat fielddata命令用于查看当前集群中每个数据节点上被fielddata所使用的堆内存大小。
GET /_cat/fielddata?v

在Elasticsearch中,Field Data是用于在聚合(aggregation)和排序(sorting)操作中对文档字段进行分析和处理的一种数据结构。它是一个缓存在内存中的数据结构,用于快速访问和处理字段值。
Field Data可以被认为是对文档字段进行预处理的一种形式,它将字段值从原始的文本形式转换成可供聚合和排序操作使用的数据类型。例如,将一个字符串形式的日期字段转换成一个时间戳,或将一个字符串形式的数字字段转换成一个数字。
使用Field Data可以有效地提高聚合和排序操作的性能,因为它可以避免在每次操作中都对原始字段值进行解析和转换。此外,Field Data还可以通过使用缓存来进一步提高性能,以便更快地访问和处理字段值。
然而,Field Data也有一些限制和注意事项。首先,Field Data需要占用一定的内存空间,因此在处理大量数据时可能会导致内存消耗过高。其次,Field Data只能在不可变的字段上使用,因为一旦字段值发生变化,就需要重新生成Field Data。
为了使用Field Data,可以在字段映射中将字段的fielddata属性设置为true。例如,以下是一个将timestamp字段设置为可使用Field Data的映射示例:
{
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"fielddata": true
}
}
}
}
需要注意的是,在大多数情况下,Elasticsearch会自动选择合适的字段数据存储方式。因此,只有在确实需要对字段进行聚合和排序操作时,才需要显式地启用Field Data。
cat health
cat health 命令用于显示集群的健康信息。
GET /_cat/health?v

- epoch 自标准时间(1970-01-01 00:00:00)以来的秒数
- timestamp 时间
- cluster 集群名称
- status 集群状态
- node.total 节点总数
- node.data 数据节点总数
- shards 分片总数
- pri 主分片总数
- repo 复制节点的数量
- init 初始化节点的数量
- unassign 未分配分片的数量
- pending_tasks 待定任务数
- max_task_wait_time 等待最长任务的等待时间
- active_shards_percent 活动分片百分比
cat indices
cat indices命令可以查看索引信息,包括索引健康状态、索引开关状态、分片数、副本数、文档数量、标记为删除的文档数量、占用的存储空间等信息
GET /_cat/indices?v

- health 索引的健康状态
- status 索引的开启状态
- index 索引名字
- uuid 索引的uuid
- pri 索引的主分片数量
- rep 索引的复制分片数量
- docs.count 索引下的文档总数
- docs.deleted 索引下删除状态的文档数
- store.size 主分片+复制分片的大小
- pri.store.size 主分片的大小
cat master
cat master命令可以显示master节点的节点ID、绑定的IP和节点名
GET /_cat/master?v

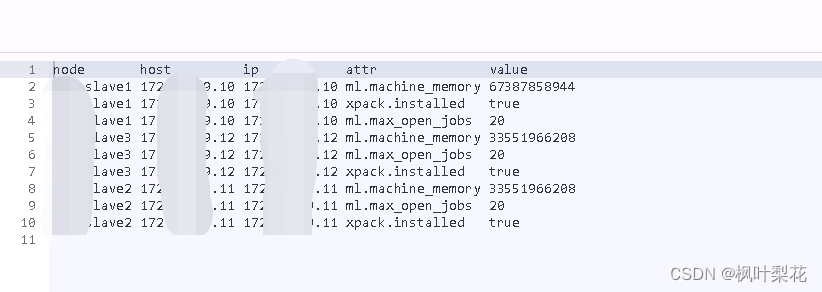
cat nodeattrs
cat nodeattrs命令可以显示指定节点的属性信息。
GET /_cat/nodeattrs?v
cat nodes
cat nodes命令可以查看集群拓扑结构
GET /_cat/nodes?v

- ip es节点ip
- heap.percent 堆内存占比
- ram.percent 内存使用占比
- cpu cpu使用率
- load_1m 1分钟内平均load情况,单位ms
- load_5m 5分钟内平均load情况,单位ms
- load_15m 15分钟内平均load情况,单位ms
- node.role 节点权限
- master 是否master节点,*为master节点
- name 节点名称
cat pending_tasks
cat pending_tasks命令用于查看正在执行的任务列表。
GET /_cat/pending_tasks?v

- insertOrder 任务插入顺序
- timeInQueue 任务排队了多长时间
- priority 任务优先级
- source 任务源
cat plugins
cat plugins命令用于查看每一个节点所运行插件的信息
GET /_cat/plugins?v

cat recovery
cat recovery命令是一个索引分片恢复的视图,包括恢复中的先前已完成的。
GET /_cat/recovery?v

- index 索引名称
- shard 分片名称
- time 恢复时间
- type 恢复类型
- stage 恢复阶段
- source_host 源主机
- source_node 源节点名称
- target_host 目标主机
- target_node 目标节点名称
- repository 仓库
- snapshot 快照
- files 要恢复的文件数
- files_recovered 已恢复的文件数
- files_percent 恢复文件百分比
- files_total 文件总数
- bytes 要恢复的字节数
- bytes_recovered 已恢复的字节数
- bytes_percent 恢复字节百分比
- bytes_total 字节总数
- translog_ops 要恢复的translog操作数
- translog_ops_recovered 已恢复的translog操作数
- translog_ops_percent 恢复的translog操作的百分比
cat repositories
cat repositories 命令用于展示集群中注册的快照库
GET /_cat/repositories?v
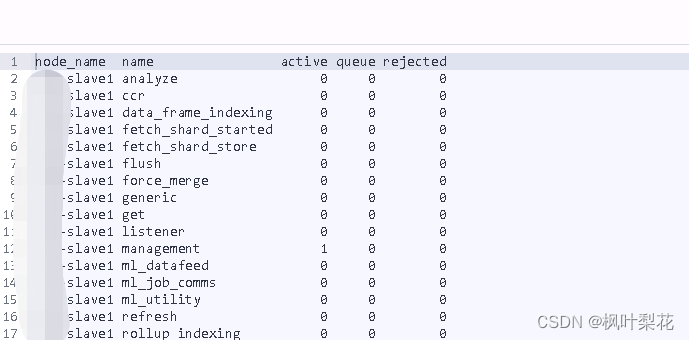
cat thread_pool
cat thread_pool命令用于展示集群中每一个节点线程池的统计信息。默认情况下返回所有线程池的active、queue和rejected的统计信息
GET /_cat/thread_pool?v
由结果发现有很多种类的线程池,询问了一下AI
elasticsearch的线程池很多种类吗?
是的,Elasticsearch的线程池名字有很多个。每个线程池都有自己的名称,用于标识和区分不同的线程池。以下是一些常见的线程池名称:
- index:用于执行索引操作的线程池。
- search:用于执行搜索操作的线程池。
- bulk:用于执行批量操作的线程池。
- get:用于执行获取操作的线程池。
- suggest:用于执行自动补全操作的线程池。
- snapshot:用于执行快照和恢复操作的线程池。
此外,Elasticsearch还支持自定义线程池,可以根据需要创建自己的线程池并提供相应的名称。可以通过Elasticsearch的管理接口查看和监控线程池的状态和性能指标。
Elasticsearch中的线程池是用于处理各种任务的线程池。线程池是一种管理和复用线程的机制,可以提高系统的效率和性能。
Elasticsearch中有几种不同类型的线程池,每种类型都用于处理特定类型的任务。以下是一些常见的线程池类型:
线程池类型:用于处理索引操作。这种线程池用于执行索引操作,如文档的索引、更新和删除。它的线程数通常会根据可用的处理器核心数自动调整。
- 搜索线程池:用于处理搜索请求。这种线程池用于执行搜索操作,包括查询、聚合和排序。它的线程数也会根据可用的处理器核心数自动调整。
- 获取线程池:用于处理获取请求。这种线程池用于执行获取操作,如根据ID获取文档或检索文档的字段。类似于搜索线程池,其线程数也会根据可用的处理器核心数自动调整。
- 刷新线程池:用于处理刷新请求。这种线程池用于处理刷新操作,该操作用于将内存中的索引数据写入磁盘。
除了以上列出的线程池类型,Elasticsearch还有其他一些专用的线程池,用于处理一些特殊的任务,如批量操作线程池、监听器线程池和管理任务线程池等。
总的来说,线程池在Elasticsearch中是非常重要的,它可以高效地管理系统的资源,并提供并发处理能力,从而提高系统的性能和吞吐量。
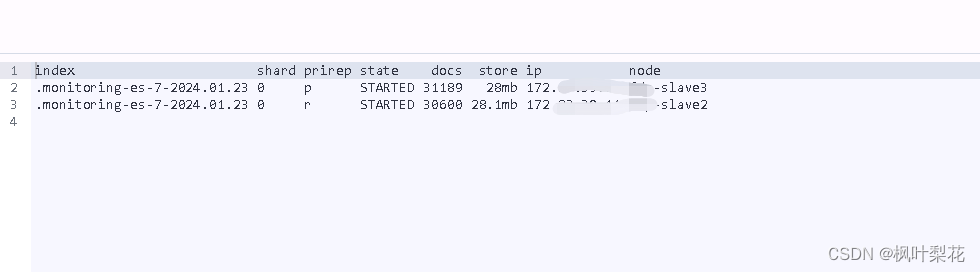
cat shards
cat shards 命令用于查看节点包含的分片信息,包括一个分片是主分片还是一个副本分片、文档的数量、硬盘上占用的字节数、节点所在的位置等信息。
GET /_cat/shards/.monitoring-es-7-2024.01.23?v
- index 索引名称
- shard 分片序号
- prirep 分片类型 p 表示是主分片 r 表示是复制分片
- state 分片状态
- docs 该分片存放的文档数量
- store 该分片占用的存储空间大小
- ip 该分片所在的服务器ip
- node 该分片所在的节点名称
cat segments
cat segments 命令用于查看索引的段信息
GET /_cat/segments/.monitoring-es-7-2024.01.23?v
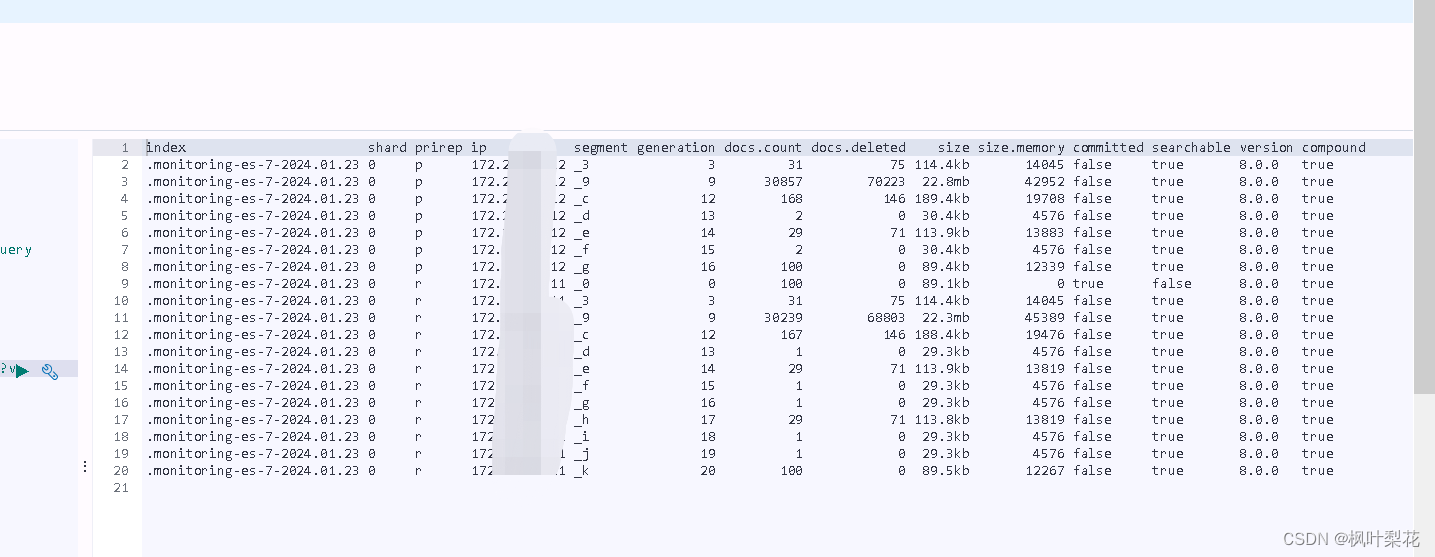
- index 索引名称
- shard 分片名称
- prirep 主分片还是副本分片
- ip 所在节点ip
- segment segments段名
- generation 分段生成
- docs.count 段中的文档数
- docs.deleted 段中删除的文档数
- size 段大小,以字节为单位
- size.memory 段内存大小,以字节为单位
- committed 段是否已提交
- searchable 段是否可搜索
- version 版本
- compound compound模式
cat templates
cat templates命令用于查看集群中的模板
GET /_cat/templates?v
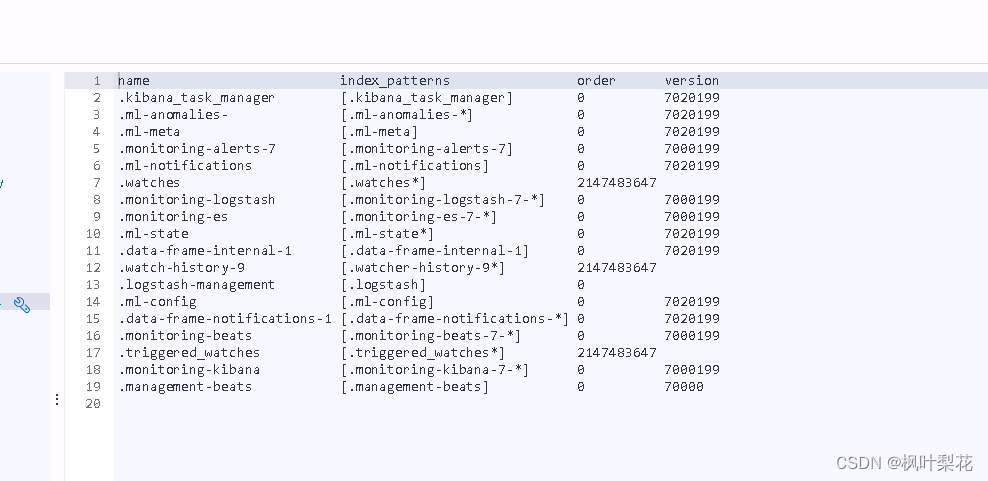
- name 模板名称
- index_patterns 模板匹配规则
- order 模板优先级
- version 模板版本
Cluster API
Cluster Health
利用ElasticSearch的集群健康API可以查看当前集群的健康信息
GET _cluster/health
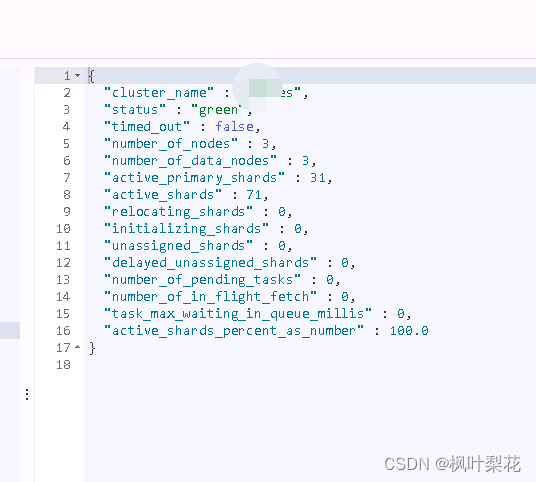
- cluster_name 集群名称
- status 集群的健康状态,green 所有主分片和从分片都可用,yellow 所有主分片可用,但存在不可用的从分片,red 存在不可用的主分片
- timed_out 是否超时
- number_of_nodes 节点数,包括master节点和data节点
- number_of_data_nodes data节点数
- active_primary_shards 活动的主分片
- active_shards 所有活动的分片数,包括主分片和副本
- relocating_shards 正在发生迁移的分片
- initializing_shards 正在初始化的分片
- unassigned_shards 没有被分配的分片
- delayed_unassigned_shards 延迟未被分配的分片
- number_of_pending_tasks master节点任务队列中的任务数
- number_of_in_flight_fetch 正在进行迁移的分片数量
- task_max_waiting_in_queue_millis 队列中任务最大等待时间
- active_shards_percent_as_number 活动分片的百分比
获取一个或多个索引的健康信息
GET /_cluster/health/.monitoring-es-7-2024.01.23
Cluster State
Cluster State(集群状态)API 可以对整个集群的信息进行一个全面的了解,包括集群信息、集群中每个节点的信息、元数据、路由表等。
GET /_cluster/state
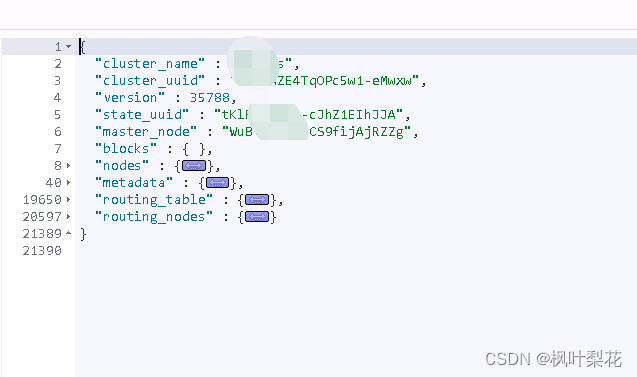
- version 返回集群状态版本信息
- master_node 只返回master节点的状态信息
- nodes 返回集群中的节点的配置信息,主要包括节点名称、IP、是否是master节点
- routing_table 返回每个节点的路由信息
- metadata 返回元数据信息,包括每个索引的mapping、setting等信息
- blocks 返回集群中的块数据信息
Cluster Stats
Cluster Stats (集群统计)API用于从集群中获取各种统计数据。该API的返回信息主要有两部分,一部分是索引层面,包括分片数、存储大小、内存使用情况等指标,另一部分是节点层面,包括节点数量、节点角色、操作系统、jvm版本、内存、CPU、安装的插件等指标。
GET /_cluster/stats

- _nodes 节点信息
- cluster_name 集群名称
- cluster_uuid 集群ID
- timestamp 时间戳
- status 集群状态
- indices
- count 索引数
- shards 分片信息:总数、主分片数、副本分片数、以及最大、最小、均值
- docs 文档信息:文档数、删除的文档数
- store 存储大小
- fielddata 字段缓存信息
- query_cache 查询缓存信息
- completion 自动补全信息
- segments 段信息
- nodes
- count 节点总数、以及各角色节点数
- versions 版本
- os 操作系统信息:处理器数量、系统名称、内存
- process 进程信息
- jvm java虚拟机信息:版本、内存、线程
- fs 文件系统信息
- plugins 插件信息
- network_types 网络信息
- discovery_types 自动发现信息
- packaging_types 发布包信息
Pending Cluster Tasks
Pending Cluster Tasks API 用于返回一个正在添加到更新集群状态的任务列表。集群中的变化通常是很快的,通常这个操作会返回一个空的列表
GET /_cluster/pending_tasks

Cluster Reroute
reroute命令可以明确地执行集群重新路由分配命令。例如,把一个分片从一个节点移动到另一个节点,把未分配的分片移动到一个指定的节点
POST /_cluster/reroute
{
"commands":[
{
"move":{
"index":"test",
"shard":0,
"from_node":"node1",
"to_node":"node2"
}
},
{
"allocate_replica":{
"index":"test",
"shard":1,
"node":"node3"
}
}
]
}
Cluster Update Settings
Update Settings命令可以更新集群中的配置,如果是永久配置,就需要重启集群;如果是瞬时配置,就不需要重启集群。例如,更新最小master节点数
PUT /_cluster/settings
{
"persistent":{
"discovery.zen.minimum_master_nodes": 1
}
}
Nodes Stats
Cluster Nodes Stats(集群节点统计信息) API可以获取集群中一个或者多个节点的统计信息。
GET /_nodes/stats
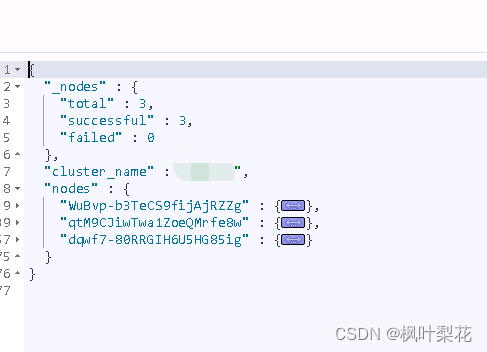
获取nodeId1 和 nodeId2节点的统计信息
GET /_nodes/nodeId1,nodeId2/stats
Nodes Info
Cluster Nodes Info API 可以获取集群中一个或多个节点的信息,包括设置、操作系统、虚拟机、线程池等信息。
GET /_nodes
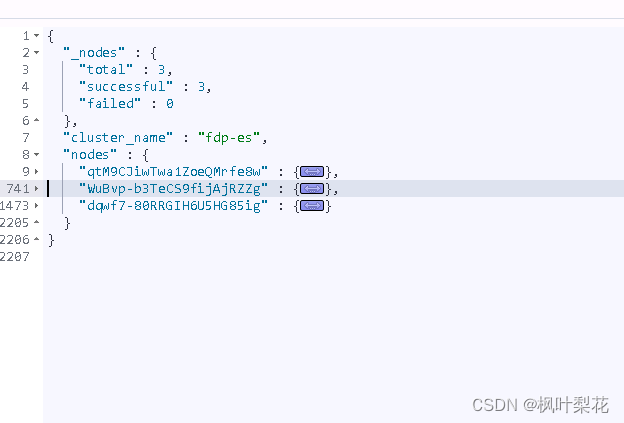
GET /_nodes/os,jvm

Task Management API
Task Management API 可用于获取ElasticSearch集群中一个或多个节点正在执行中的任务信息。
GET /_tasks

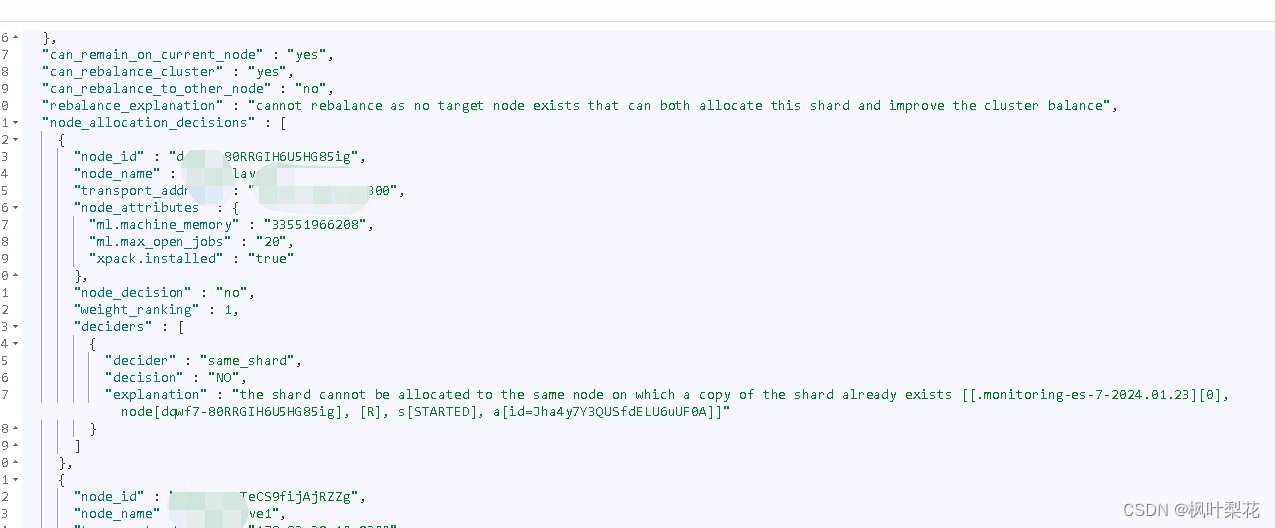
Cluster Allocation Explain API
Cluster Allocation Explain API 用于解释分片没有被分配的原因。
GET /_cluster/allocation/explain
{
"index":".monitoring-es-7-2024.01.23",
"shard":0,
"primary":true
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Waves14 Complete Mac/win功能强大、效果出色的专业级插件集合
- JS常见正则表达式写法(附案例)
- 软件架构师的主要职责说明文(合集)
- 10分钟快速上手LLM大模型Python前端开发(三)之显示模块(二)
- 计算每个月的天数
- STM32学习笔记十七:WS2812制作像素游戏屏-飞行射击游戏(7)探索动画之故事板,复杂动画
- Pyside6/PyQt6图标设置必备:窗口图标、软件图标、任务栏图标与系统托盘图标设置详解(含示例源码)
- Redis设计与实现之字符串&哈希表&列表
- 美国化妆品FDA认证被强制要求,出口企业该这么办!!!
- 3D模型格式转换工具HOOPS Exchange的层次结构遍历