我的隐私计算学习——联邦学习(2)
笔记内容来自多本书籍、学术资料、白皮书及ChatGPT等工具,经由自己阅读后整理而成
(三)联邦学习的算子
------------------------ 算子是什么?---------------------------
? 从广义上讲,对任何函数进行某一项操作都可以认为是一个算子。于我们而言,我们所开发的算子是网络模型中涉及到的计算函数。深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称Op)。例如:卷积层(Convolution Layer)中的卷积算法,是一个算子;全连接层(Fully-connected Layer)中的权值求和过程,也是一个算子。
? 在网络模型中被用作激活函数的算子:Tanh Relu Sigmoid等。------------------------ 算子和算法的关系?---------------------------
算子(operator),简单说来就是进行某种操作或动作,与之对应的就是被操作的对象,称之为操作数。而算法(algorithm),是为了达到某个目标,实施的一系列指令的过程,而指令包含算子和操作数。
mov ax, 0x1000 inc ax上面这段汇编代码中,“mov”就是算子,而 ax, 0x1000 是操作数,是 mov 这个算子操作的对象。第一条语句意思是把 ax 寄存器赋值为 0x1000。同样,“inc”是算子,“ax”是操作数,“inc ax”就是把 ax 寄存器的数加 1。其实它实现了一个简单算法:
a = 0x1000 a = a+1
-
数据预处理算子
(1)样本对齐,样本对齐的方式有多种,例如基于映射的散列算法、比特承诺,基于 RSA 加密体系的茫然传输等。在对称的联邦学习中,隐私集合求交过程如下图所示。而在非对称的联邦学习中,参与训练的双方分强势方和弱势方,通过非对称 ID 对齐后,弱势方得到的是双方样本 ID 的交集,强势方得到的则是一个混淆集,真正的交集是这个混淆集的子集,且混淆集是强势方原有集合的子集。

(2)特征相似度分析,在纵向联邦学习中,当用户数据对齐后,特征之间的相似度计算有利于参与方筛选出重复特征,降低模型训练过程中过拟合的可能性;在横向联邦学习中,需要参与方用相同的数据特征进行联合建模,不同数据拥有者在记录数据和处理数据时,取名和分箱的逻辑都不一样,因此需要通过相似度分析来确定特征与特征之间的对应关系。
(3)特征对齐,可以对特征相似度设定阈值,将相似度超过阈值的特征视为同一特征。在模型训练中,需要对同一特征进行对齐处理,这里可以采用的对齐技术是对特征进行统一编码处理,将编码一致的特征视为同一特征。
(4)特征分箱,联邦学习参与方拥有的数据中不可避免有一些连续数值,连续数值在大数据模型训练时处理起来非常困难,可能会影响到模型的效果,因此在特定情况下会将连续数值转换成离散数值。传统机器学习中,通常依据证据权重(Weight of Evidence)和信息量(Information Value)来确定分箱策略。在纵向联邦学习框架下,一个特征只归属于一方;而在横向联邦学习框架下,同一个特征的数据分散在所有数据参与者手中,此时需要借鉴一些安全的手段来完成分箱策略。
(5)特征缺失值填充,需要依据特定的场景选择合理的缺失值填充方式,常见的填充方式有中位数填充、众数填充、平均数填充和 0 值填充等。在纵向联邦学习中,各方参与者所拥有的特征并不相同,因此其缺失值填充的方式与传统机器学习并无差异,在此不再赘述。在横向联邦学习中,两方拥有的特征相同,0 值填充比较简单,直接补 0 操作即可,而中位数、众数和平均数的计算均需结合所有参与方的数据一起计算,这时就需要引入加密算法。需要强调的是,我们应当明确缺失样本和缺失值为 0 的样本的区别,有时候通过独热编码来表明哪些是缺失样本,哪些是缺失值为 0 的样本是非常重要的。
(6)数据指标分析,在联合建模开始前,对参与方的数据指标分析有助于联邦学习参与者对建模合作进行预判,常见的数据指标有样本数量、特征数量、特征分布情况(中位数、众数、平均值、最大值、最小值、离散程度等)、特征缺失情况等。
以下补充一些常用的特征工程方法:
- 独热编码:是一种对无序分类特征进行预处理的技巧,它将分类特征变成长度相同的向量。如果类别取值不多,那么通常就可以采用独热编码。
- 特征哈希:又称哈希技巧,在分类特征取值很多的时候使用,流程很简单,将分类特征的取值使用哈希函数转换成指定范围内的哈希值,通过取余操作,可以将原类别数量减少到可用的数量,之后再使用独热编码即可。
- 嵌入法:也就是 Embedding 算法,是使用神经网络将原始分裂数据转换成新特征的方法。其本质是为分类型变量的每一个类别取值生成一个高维向量,通过高维向量的距离来度量类别之间的距离。这个方法最经典的案例就是对文本中的单次进行编码,即 word embedding,就是将单个单词映射成维度是几百维甚至几千维的向量,再进行文档分类等应用。
- 取对数法:就是指对数值特征做对数转换处理,这样的处理可以改善特征的取值分布,将极端值转换到较小范围内。具体来说,对数转换将减少右偏,使得最后的分布更加对称。但这一转换不适用于取值中有零值或负值的特征。
- 特征标准化:是一种通过缩放来标准化特征的取值范围、取值波动性、取值均值等特征的特征工程方法。特征缩放可以将很大范围的数据限定在指定范围内。常见的标准化有最小最大缩放(Min-max Scaling)和标准化缩放(Standard Scaling)。具体来说,最小最大缩放使用特征取值减去特征的最小值,得到的差除以特征的最大值与最小值之差,标准化缩放则使用特征取值减去特征均值,得到的差除以特征的标准差。
- 特征交互:这是特征增广的重要方法之一,我们有时会根据特征的含义,采用特征的加和/之差/乘积/除商来产生新特征。在回归模型中加入交互项通常是一种常见的处理方式,可以极大地拓展回归模型对变量之间的依赖的解释。
- 特征降维:即同时减少特征数量及创造新的特征,最基本的手段是采用缺失值比率作为阈值,预先卡掉一部分有用信息较少的特征。完成缺失值比率筛选之后就可以对特征的内部特征进行观察,比较典型的两种手法就是低方差滤波处理和高相关滤波处理。前者指的是去除数据内部变化不大的数据,因为方差较小,我们可以认为它内部含有的信息较少。后者是针对数据中特征的两两关系进行分析处理,如果它们本身高度相关,就可以认为它们的信息是类似的,是重复的。完成缺失值比率筛选、低方差滤波处理和高相关滤波处理之后,就可以采用因子分析(FA)、PCA和独立成分分析(ICA)等方法进一步减少特征的维数。这三种方法的相同之处是利用某种理论提取已有特征中的线性相关的共性来达到减少总特征数、保留特征信息的效果。
-
模型训练算子
(1)损失函数计算,损失函数的输出值越小,代表真实值和预测值的偏离程度越小,模型预测的效果也越好。损失函数主要包含 0-1 损失函数、绝对值损失函数、对数损失函数等。
(2)梯度计算,梯度在数学意义上是损失函数对目标的导数。
(3)正则化,正则化通常被用于处理过拟合的问题,以保留一些偏差值的代价来降低模型复杂度,但有时可能导致拟合度不够的问题。一般有 L1 正则化和 L2 正则化。
(4)激活函数,在神经网络中,激活函数是将神经元中的输入进行非线性转化并传递给下一层的函数。由于线性函数进行叠加输出仍是线性函数,无法构成多层神经网络,因此激活函数必须为非线性函数。常见的激活函数有 Sigmoid、Tanh、ReLU 等。
(5)优化器,又称为优化算法,其本质是一种数学方法,主要作用是优化模型的训练过程,以更少的迭代次数、更小的计算量、更快的速度得到最优解。常见的优化器有梯度下降法、动量优化法和自适应学习率三大类。
(6)联邦影响因子,联邦学习中有两个及以上的数据拥有者参与建模,大家拥有的数据量和数据质量不同,因而每个参与者在建模中的影响也不同。通常引入影响因子(又称权重因子)来调整每个参与者训练数据在联合建模过程中的权重。确定影响因子的方式有很多种,比如数量、数据质量、模型指标等(准确率、精确度、F1值等)。
(7)激励机制,激励机制是确保联邦学习生态正常运转的重要基石,需要通过经济激励的方式,吸引拥有高质量数据的公司和个体加入联邦学习生态中。
(四)联邦学习的算法
? 联邦学习的算法主要可分为三个部分:中心联邦优化算法、联邦机器学习算法和联邦深度学习算法。
-
中心联邦优化算法
? 中心联邦优化算法作用于服务器,可以在服务器进行聚合计算时提升模型指标、收敛速度或达到其他特定目的。FedAvg(Federated Averaging)是目前最常用的联邦学习优化算法。与常规的优化算法不同,其本质思想是对数据持有方的局部随机梯度下降进行单机优化,并在中央服务器方进行聚合操作。FedAvg 的目标函数定义如下:
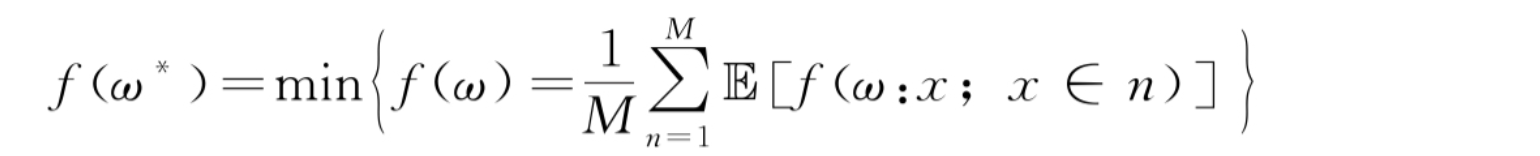
? 其中,M 表示参与联合建模的数据持有方数量,ω 表示模型当前的参数。FedAvg 是一种比较基础的联邦优化算法,部署相对简单,应用领域很广泛。FedAvg 的算法流程如下:

大部分联邦优化算法是在 FedAvg 的基础上发展而来的,例如 FedProx、FedPer 等。
-
联邦机器学习算法
? 联邦机器学习算法指在联邦学习框架下的经典机器学习算法。联邦机器学习,尤其是横向联邦学习,在整体模式上与分布式机器学习类似。但是由于联邦学习特有的迭代模式和特点,相较于传统的机器学习算法,联邦机器学习算法的实现显得更加复杂。下面介绍 3 种目前常见的联邦机器学习算法:
(1)联邦线性算法
? 联邦线性算法的种类很多,包括线性回归、逻辑回归、非广义线性回归等。以纵向逻辑回归为例,它是联邦学习框架下的一种非常典型的线性算法,其目标函数如下:

(2)联邦树
? 树模型是机器学习的重要分支,包括决策树、随机森林等。其中,联邦森林是一种基于中心纵向联邦学习框架的随机森林实现方法。在建模过程中,每棵树都实行联合建模,其结构被存储在中央服务器及各个数据持有方,但是每个数据持有方仅持有与己方特征匹配的分散节点信息,无法获得来自其他数据持有方的有效信息,这保障了数据的隐私性。最终整个随机森林模型的结构被打散存储,中央服务器中保留完整结构信息,节点信息被分散在各数据持有方。使用模型时,可以通过中央服务器对每个本地存储节点进行联调,这种方法降低了预测时每棵树的通信频率,对通信效率有一定的提升。
? SecureBoost 是一种基于梯度提升树(GBDT)的去中心化纵向联邦学习框架。它同样包含有标签数据持有方和无标签数据持有方。梯度提升树算法交互的参数与线性算法有很大区别,涉及二阶导数项。根据一般的梯度提升树算法,我们的目标函数如下:

? SecureBoost 采用一种既能保护数据隐私又能保证训练性能的联合建模方法。有标签数据持有方 α 首先计算 F(x) 并将结果加密后发送给无标签数据持有方 β。β 根据同态加密求和方法进行局部求和并将结果回传。收到计算结果后,α 将数据按照特征分桶并进行聚合操作,将加密结果发送给 β。最终由 α 将从 β 中收集的局部最优解聚合产生最优解,并下发回 β,完成联合建模。需要说明的是,SecureBoost 支持多方合作,即无标签数据持有方 β 表示所有无标签数据持有方的集合,但是有标签数据持有方仅为一方。SecureBoost 在保障了模型准确率的情况下,保护了数据隐私,成功将纵向 GBDT 应用在联邦学习的框架中。
(3)联邦支持向量机
? 联邦支持向量机主要通过特征散列、更新分块等方式来保障数据的隐私性。其目标函数如下:

? 在支持向量机中,其损失函数 L(ω,xi,yi) = max{ 0,1-ωTxiyi }。类似于 SimFL,这里也对特征值进行降维散列处理,隐藏实际的特征值。除此之外,由于在线性支持向量机中,中央服务器有一定概率根据更新梯度反推出数据标签,为了保护数据的隐私性,这里采用了次梯度法的更新方式。在实际表现中,这种支持向量机在联邦框架下的应用具有不亚于单机支持向量机的性能。
-
联邦深度学习算法
? 在联邦学习系统中,为了保障数据隐私安全,客户端在进行数据通信时,往往会对传输的信息进行编码和加密,同时由于原始用户数据对中央服务器不可见,所以训练样本在模型搭建时对中央服务器及模型设计人员不可观测。之前用于经典深度学习的相关模型在联邦学习系统中不一定是最优设计。为了避免网络模型的冗余,需要对经典深度学习模型 NN、CNN、LSTM 等进行相应的修改。
(1)神经网络
? H. Brendan 等人曾用联邦学习框架下的 NN 和 CNN 分别在 MNIST 数据集上进行测试。对于 NN,模型的具体结构为含有两个隐藏层的神经网络,每个隐藏层包含200个神经元,且隐藏层用 ReLU 激活函数进行激活。他们将 MNIST 数据集分配到两个计算节点,每个计算节点含有样本量大小为 600 且无交集的子数据集。在进行联邦训练时,为了验证模型参数初始化和聚合比例带来的影响,将实验分为具有不同初始化方式的两组:一组使用相同的随机种子初始化分配在两个计算节点的模型参数,另一组则使用不同的随机种子初始化模型参数。然后每组实验用不同的比例整合来自不同节点的模型参数,以获取最终的联邦共享模型,即:

(2)联邦 LSTM? LSTM(Long Short-Term Memory,长短期记忆网络)主要运用在联邦模型中,它可用于预测字符、情感分析等场景。在合适的超参数设置下,LSTM 模型在非独立同步分布(non-IID)数据集下可达到常规情况下的模型精度。由于 LSTM 在模型训练过程中产生的参数量较大,容易造成通信堵塞,有研究者在卷积网络的基础上研究优化模型参数压缩在 non-IID 数据集下的应用。在客户端与中央服务器通信时,相较于无压缩 Baseline 的 2422 MB网络参数量,使用基于 STC 编码的通信协议的联邦学习系统可以在保证模型收敛效果的同时,将上行通信参数量压缩至 10 MB左右,将下行通信参数量压缩至100 MB左右。
2023年10月份新开了一个GitHub账号,里面已放了一些密码学,隐私计算电子书资料了,之后会整理一些我做过的、或是我觉得不错的论文复现、代码项目也放上去,欢迎一起交流!Ataraxia-github
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!