MySQL夯实之路-索引深入浅出
索引的类型
从数据结构的角度来说,分为B-Tree索引、hash索引(memory引擎支持)、R-Tree索引(空间数据索引,MyISAM支持,用作地理数据存储)、FULLTEXT(全文)索引(MyISAM、InnoDB支持)
从物理存储角度:聚集索引、非聚集索引
从逻辑角度:普通索引、唯一索引、主键索引、空间索引(只有MyISAM支持且支持的不好)
B-tree索引
通常意味着所有的值都是按顺序存储的,适合查找范围数据。
适用于全键值,键值范围或者键前缀查找(只适合最左前缀查找)

叶子节点指向的是被索引的数据

限制:必须按索引的最左列开始查找;不能跳过索引中的列,如果有范围查找,则右边所有列无法使用索引优化查找
哈希索引
哈希索引基于哈希表实现,必须精准匹配索引所有列。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,不同键值的行哈希码不一样。哈希码存储在索引中,哈希表中保存每个数据行的指针。
Mysql中只有memory引擎支持哈希索引,并且是支持非唯一哈希的,同时也支持B-tree索引,如果哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希目录

缺点:


哈希索引只适用于特定的场合。Ndb集群引擎也支持唯一哈希索引,并且作用特殊
 ‘也可以创建自适应哈希索引。缺点是需要维护哈希值,可以手动维护,也可以使用触发器实现
‘也可以创建自适应哈希索引。缺点是需要维护哈希值,可以手动维护,也可以使用触发器实现

空间数据索引(R-tree)
Myisam支持空间索引,可以用作地理数据存储。这类索引无需前缀查询,空间索引会从所有维度来索引数据。可以使用任意维度来组合查询

全文索引
全文索引是查找文本中的关键词,而不是直接比较索引中的值。(类似于搜索引擎,而不是简单的where条件匹配)

索引的优点


非常小的表,通常全表扫描更高效。对于中型到大型表,索引非常高效
高性能索引策略
独立的列
指索引列不能是表达式的一部分,也不能是函数的参数


前缀索引和索引选择性
前缀索引:使用列的前面的部分字符作为索引
索引选择性:不重复索引数(基数
)和总记录的比值


多列索引
Where条件里面的列都建立索引是错误的

Mysql5.0及以后,引入了“索引合并”的策略

 ?
?
选择合适的索引列顺序
 ?
? ?
? ?
?
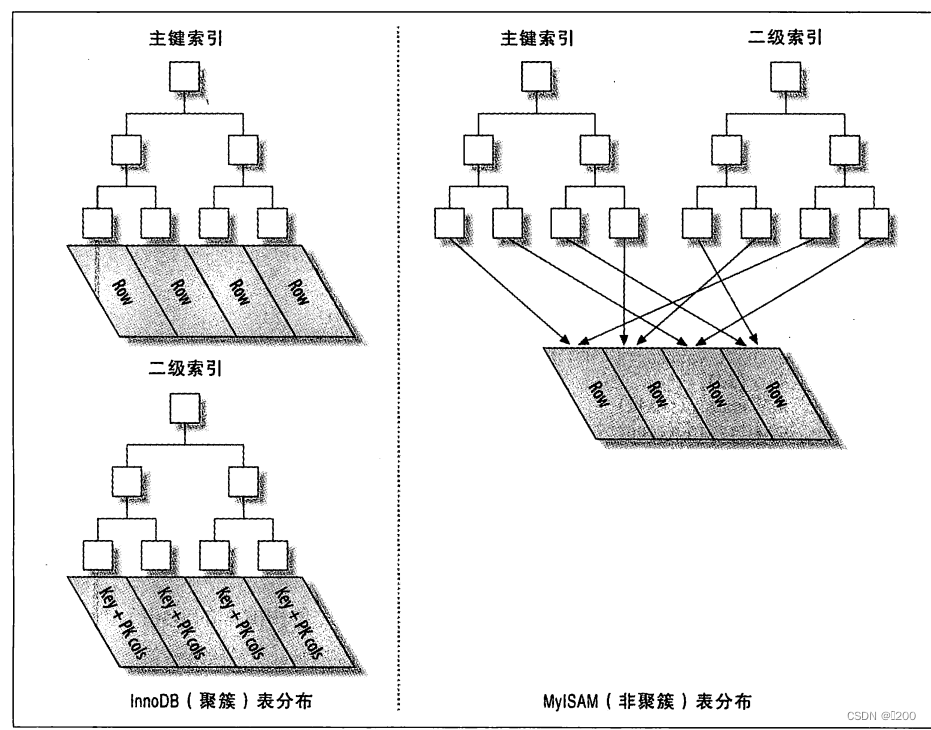
聚簇索引
是一种数据存储方式,数据和索引存储在一起

innoDB通过主键聚集数据


 ?
?
二级索引需要两次b-tree查找。innoDB中自适应哈希索引能减少这样重复的操作



可以使用代理键作为主键(代理键与业务无关),如自增整数id

如果插入的主键不一定比之前大,就不能简单地插入到索引的最后,有许多缺点。尽可能按主键顺序插入数据,尽可能使用单调增加的聚簇键的值来插入新行

覆盖索引
二次索引(普通索引,辅助索引)只需要扫描索引而无需回表
好处:



使用索引扫描来做排序


只有当索引的列顺序和order by字句顺序完全一致,并且所有列的排序方向都一样时,mysql才能使用索引进行排序




压缩(前缀压缩)索引


冗余和重复索引
应该避免冗余和重复索引


未使用的索引

索引和锁

支持多种过滤条件

 ?
?
避免多个范围条件
In不是范围查询,是多个等值查询

优化排序
 ?
?
维护索引和表

 ?
?
减少索引和数据的碎片
 ?
?
![]()
总结

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Spring 篇】MyBatis DAO层实现:数据之舞的精灵
- Java网络编程——UDP通信原理
- Pytest自动化测试用例中的断言详解
- 三角形制作
- 力扣刷题记录(28)LeetCode:797、200、463
- 安装pygraphviz步骤
- 利用堆来解决数组的topK问题
- 体验升级!掌握详情页设计技巧,吸引用户深度互动!
- Acrel-1000安科瑞变电站综合自动化系统选型与应用
- 最长子字符串的长度(二) - 华为OD统一考试