【Apache Doris】自定义函数之 JAVA UDF 详解
【Apache Doris】自定义函数之 JAVA UDF 详解
一、背景说明
UDF 主要适用于,用户需要的分析能力 Doris 并不具备的场景。用户可以自行根据自己的需求,实现自定义的函数,并且通过 UDF 框架注册到 Doris 中,来扩展 Doris 的能力,并解决用户分析需求。
UDF 能满足的分析需求主要分为两种(本文中的 UDF 指的是二者的统称):
- UDF(User Defined Function): 用户自定义函数,这种函数会对单行进行操作,并且输出单行结果。当用户在查询时使用 UDF ,每行数据最终都会出现在结果集中。典型的 UDF 比如字符串操作 concat() 等。
- UDAF(User-Defined Aggregate Functions): 用户自定义的聚合函数,这种函数对多行进行操作,并且输出单行结果。当用户在查询时使用 UDAF,分组后的每组数据最后会计算出一个值并展结果集中。典型的 UDAF 比如集合操作 sum() 等。一般来说 UDAF 都会结合 group by 一起使用。
正式推出Java UDF 之前,Apache Doris提供了原生 UDF即C++ UDF 。由于是使用 C++ 来编写的,执行效率高、速度更快,但是在实际使用中也会存在一些问题:
- 跟 Doris 代码耦合度高,需要自己打包编译 Doris 源码
- 只支持 C++ 语言并且 UDF 代码出错会影响 Doris 集群稳定性
- 对于只熟悉 Hive和Spark 等大数据组件的用户有一定使用门槛
针对以上问题,Apache Doris 在1.2.0版本中正式推出全新的Java UDF ,让用户可以更便捷高效地开发和迁移UDF。

二、原理简介
众所周知,Doris的FE主要由JAVA编写、而BE是由C++编写。因此,如果需要C++编写的BE与JAVA UDF联动,那么必然需要借助网络通信或JNI(Java Native Interface):
- 网络通信:可以跨语言交互,但是会带来网络传输等额外的性能开销,PASS。
- JNI:用于在Java程序中调用本地(C/C++)代码。通过JNI,可以将C++代码编译成动态链接库,然后在Java程序中加载该动态链接库,并通过JNI接口进行函数调用和数据传递。
JNI调用需要进行Java与本地代码之间的切换和数据转换,这也会带来一定的性能开销,如果频繁的JNI调用还可能会对应用的性能产生不利影响。那么Doris该如何设计 Java UDF 呢?
- 开发规范:制定一些开发规范让流程有序且容错率高,例如UDF 类必须具有 evaluate 方法,并且必须是 Public 和 Non-Static 的。
- 重用JVM:BE 会创建或重用一个 JVM 来调用真正的 Java UDF,保证效率的同时让资源利用率最大化。
- 向量化执行:执行时是向量化的,可以实现一次执行多行数据只调用一次 JNI,给用户带来更好的性能体验。
下面,就来一起体验下Apache Doris 的 Java UDF吧。
三、环境信息
3.1 硬件信息
- CPU:48C
- 内存:256G
3.2 软件信息
- 系统:CentOS
- JAVA版本:1.8
- Apache Doris版本:2.1 rc01
四、IDE准备
直接IntelliJ IDEA:
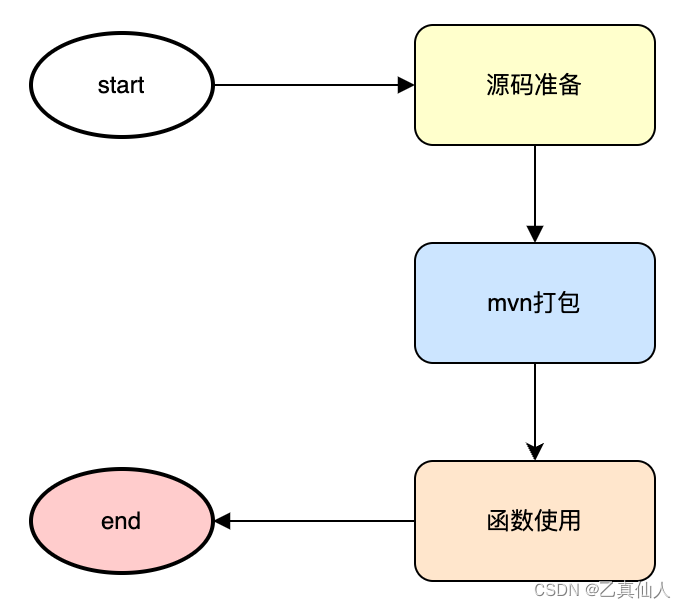
五、JAVA UDF开发流程
Java UDF 使用起来非常简单。只需要按规范开发完并通过mvn打成jar包后,在 Apache Doris 内注册一下,即可调用 jar 包来实现 UDF 逻辑:
5.1 源码准备
5.1.1 pom.xml
仅补齐dependencies和build部分。
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.5</version>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<finalName>doris_java_udf</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.doris.udf.AddOne</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>org.apache.doris.udf.AddOne</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
5.1.2 JAVA代码
直接使用官方的demo:
https://github.com/apache/doris/blob/master/samples/doris-demo/java-udf-demo/src/main/java/org/apache/doris/udf/AddOne.java
package org.apache.doris.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class AddOne extends UDF {
public Integer evaluate(Integer value) {
return value == null? null: value + 1;
}
}
5.2 mvn打包
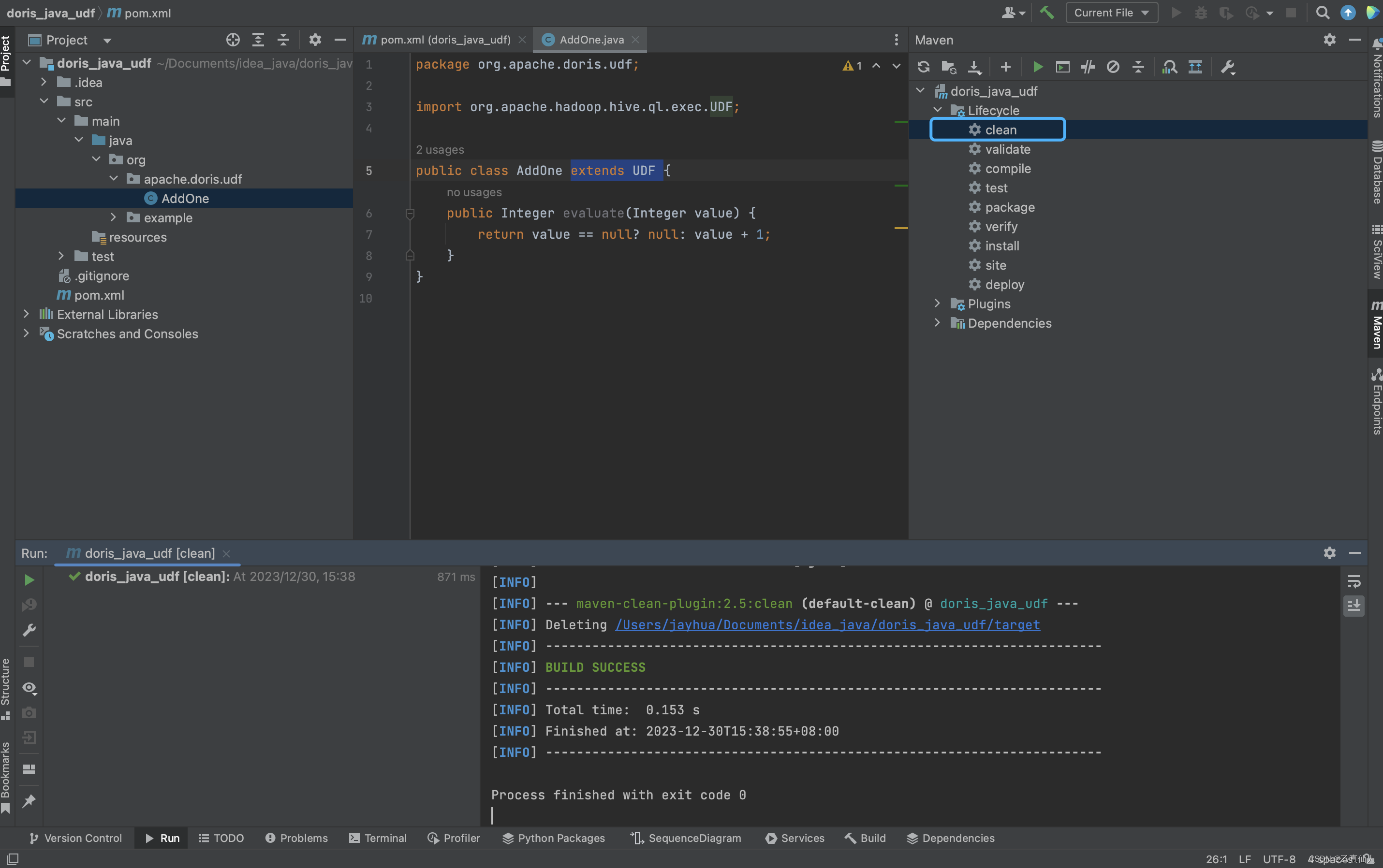
5.2.1 clean
先clean清理target。
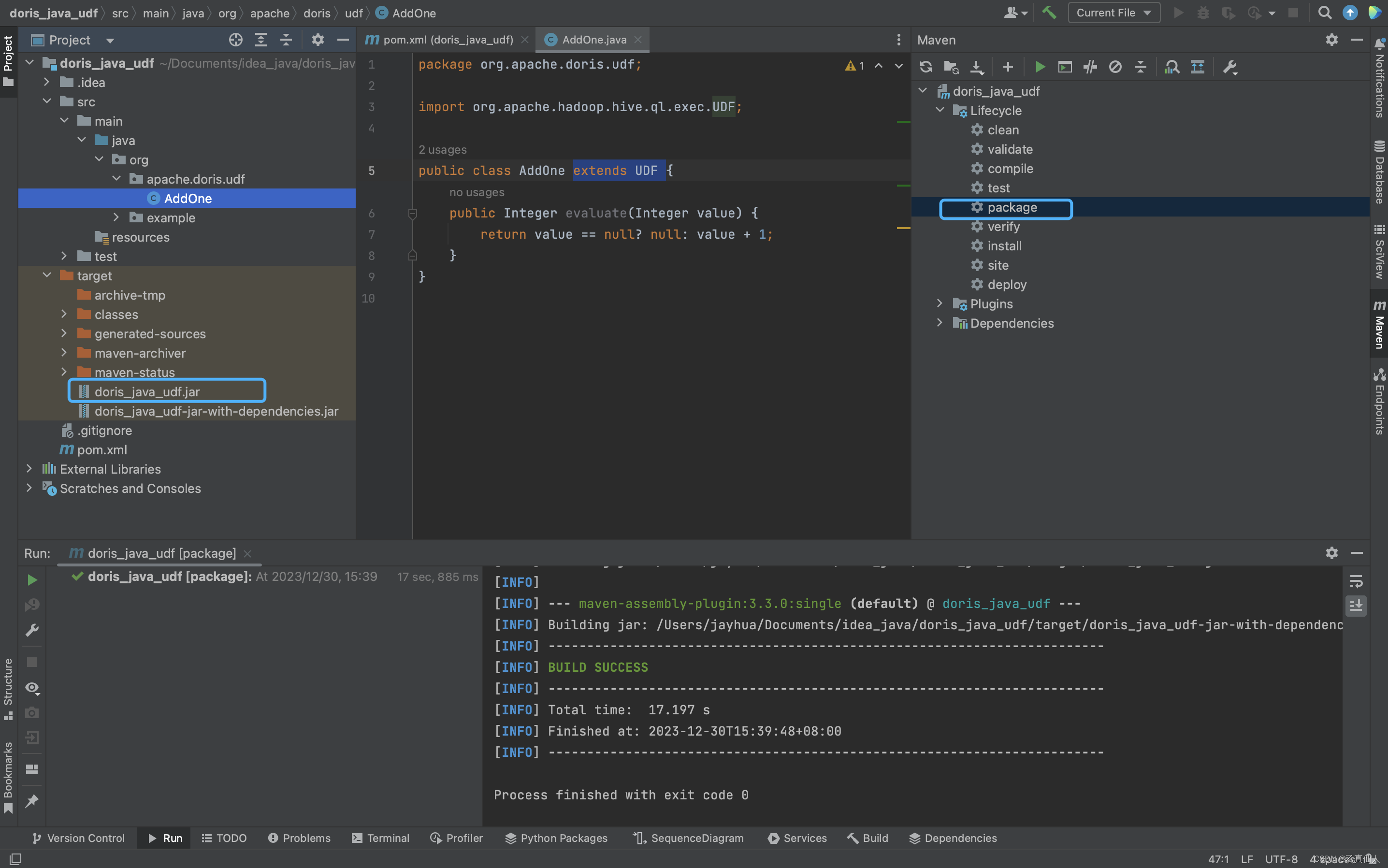
5.2.2 package
再package打新包。
5.3 函数使用
5.3.1 upload
打好的jar包(即doris_java_udf.jar,不需要传依赖jar包),可以以两种方式存放:
- 服务化:多机环境时,也可以使用http的方式下载jar包
- 本地路径:FE、BE节点都要放置,并且都有权限访问的路径。
本文选择本地路径的方式演练:

5.3.2 使用
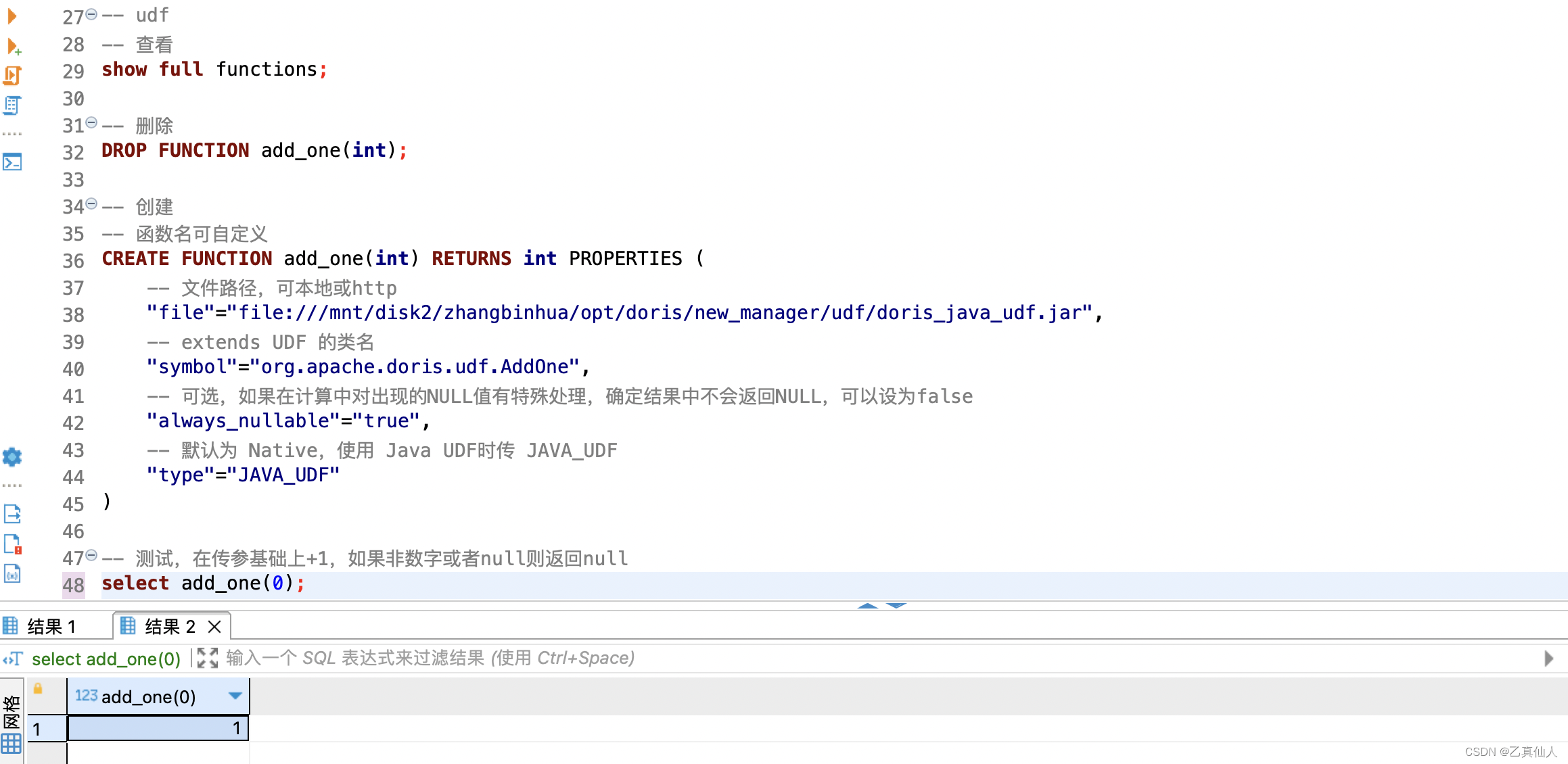
-- udf
-- 查看
show full functions;
-- 删除
DROP FUNCTION add_one(int);
-- 创建
-- 函数名可自定义
CREATE FUNCTION add_one(int) RETURNS int PROPERTIES (
-- 文件路径,可本地或http
"file"="file:///udf/doris_java_udf.jar",
-- extends UDF 的类名
"symbol"="org.apache.doris.udf.AddOne",
-- 可选,如果在计算中对出现的NULL值有特殊处理,确定结果中不会返回NULL,可以设为false
"always_nullable"="true",
-- 默认为 Native,使用 Java UDF时传 JAVA_UDF
"type"="JAVA_UDF"
)
-- 测试,在传参基础上+1,如果非数字或者null则返回null
select add_one('0');
六、注意事项
虽然JAVA UDF整起来非常顺畅方便,但实际生产使用中有如下一些官方提醒:
- 不支持复杂数据类型(HLL,Bitmap)。
- 当前允许用户自己指定JVM最大堆大小,BE配置项是jvm_max_heap_size。配置项在BE安装目录下的be.conf全局配置中,默认512M,如果需要聚合数据,建议调大一些,增加性能,减少内存溢出风险。
- char类型的udf在create function时需要使用String类型。
- 由于jvm加载同名类的问题,不要同时使用多个同名类作为udf实现,如果想更新某个同名类的udf,需要重启be重新加载classpath。
七、总结
Java UDF相对1.2之前的C++ UDF而言,使用起来会更加便捷高效,而且更利于Hive/Spark的UDF jar包迁移,并且Doris团队对其底层实现流程进行了一系列性能优化,面面俱到。各位看官大可放心使用!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据库原理】(26)数据库并发控制
- 面试必备!机器学习模型全面总结!
- 设计模式——原型模式
- 使用python爬取某专科学校官方信息
- 女性需要了解的健康知识
- 热点报告 | “尔滨”火出东北,本期热点带你盘活冬季营销
- 并发编程之ReentrantReadWriteLock详解
- 大厂痴迷DDD:从高德portal重构,看DDD的巨大价值
- LeetCode刷题--- 子集
- STM32TIM定时器PWM输出比较(适用于通用,高级定时器)