记录一个Insert姿势引起的MySQL从库上查不到数据的问题

转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。
问题描述:
某测试环境的MySQL用了两台节点,主从同步结构。忽然有研发同学反映说MySQL的主从不同步了。他在测试代码功能的时候,调用接口在主库insert了一条数据,然后发现在从库上查不到这条数据。于是开始排查。
原因排查:
1、查看主从同步状态
在主库和从库分别执行:show master status\G; 和 show slave status\G;
发现从库同步的binlog的Position跟主库查询到的不一致,以为是同步延迟了。然后手动在主库创建了一个测试database,发现从库立即同步了,主从同步的点也是一致的。
2、根据数据字段排查
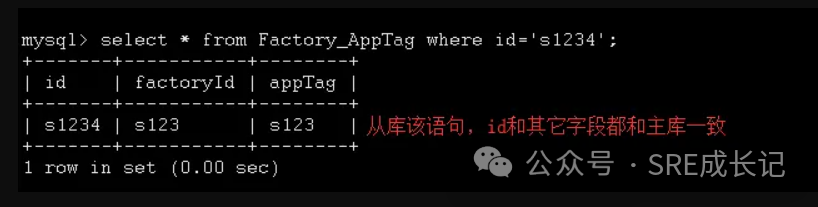
于是再次查看表数据,发现主从的这张表数据量是一样的,但是根据“id”这个字段去查,主库能找到数据,但是从库就是查不到。
然后换了个关键字“factoryId”去查询,发现主从库都有数据,但是两个库查询出来的数据id是不一致的:


将两条数据删掉,重新调用代码接口插入数据,结果还是一样的,两条数据的id就是不一样。
然后尝试手动insert一条语句,发现不存在这个问题:
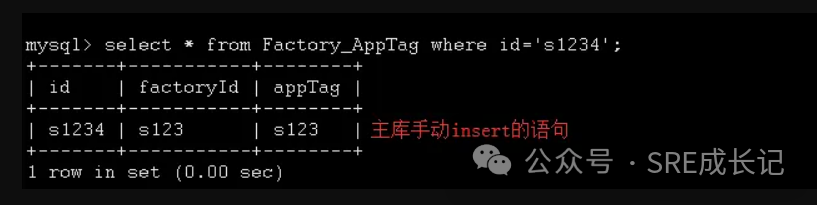
3、排查insert语句代码
最后,研发给出的结论是这样的:
这张表的数据包含id、factoryId和appTag三个字段。
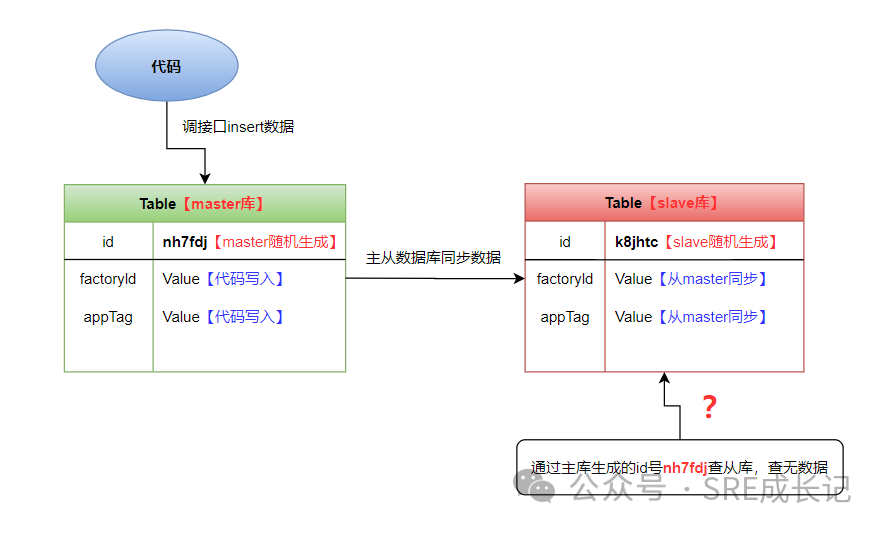
当使用代码调接口执行insert语句时,代码并没有生成id这个字段固定的id号,只有生成了factoryId和appTag这两个字段的内容。
所以写入数据的时候,只有factoryId和appTag这两个字段的内容的固定的,id号是在数据库里面自己随机生成的。而且在主库生成了id号之后,并没有让从库将主库生成的id直接inert到从库,而是在从库也随机生成一个自己的id。
所以就导致这样一种情况:同一条insert插入的数据,在主库insert的时候会随机生成一个id;在从库也会随机生成一个自己的id。当两个库都随机生成自己的id的时候,就会很高概率导致主从库上这条数据的id字段不一致,只有factoryId和appTag这两个字段是一致的。
因此,当根据id去查询数据,就会发现从库可能无法查询到该数据。因为之前很少用id这个关键字去进行数据库操作,因此没有注意到这个问题。
补充:
数据库随机生成id的两种方式:
1、随机生成uuid(uuid是根据时间戳来生成的)
2、auto_increment属性生成id
故障的大致情形如下图:
解决方法:
需要开发修改接口代码,修改insert语句的插入方式,将主库随机生成的id直接insert到从库,从库不再单独生成id。问题就解决了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!