AI语音识别模块--whisper模块
1.下载 ffmpeg,挑一个自己电脑系统的版本,下载,如我win64:
地址:
Releases · BtbN/FFmpeg-Builds · GitHub
下载压缩包zip,到·本地
解压安装,其实无需安装,只需把对应的目录下的bin,
编辑环境变量的path,添加到环境变量即可!!!
不能科学的同学,可以到网盘地址,下载压缩包zip
链接:https://pan.baidu.com/s/1yBQBs-pUKOpUPeIJpPsURA?pwd=6543?
提取码:6543?
2.下载whisper:
查看模型的地址:? ? ? ? ? ? ? https://github.com/openai/whisper/blob/main/whisper/__init__.py? ? ??
查看初始化文件: __init__,内含各个模型的地址,就省得取hugging-face里下载了...
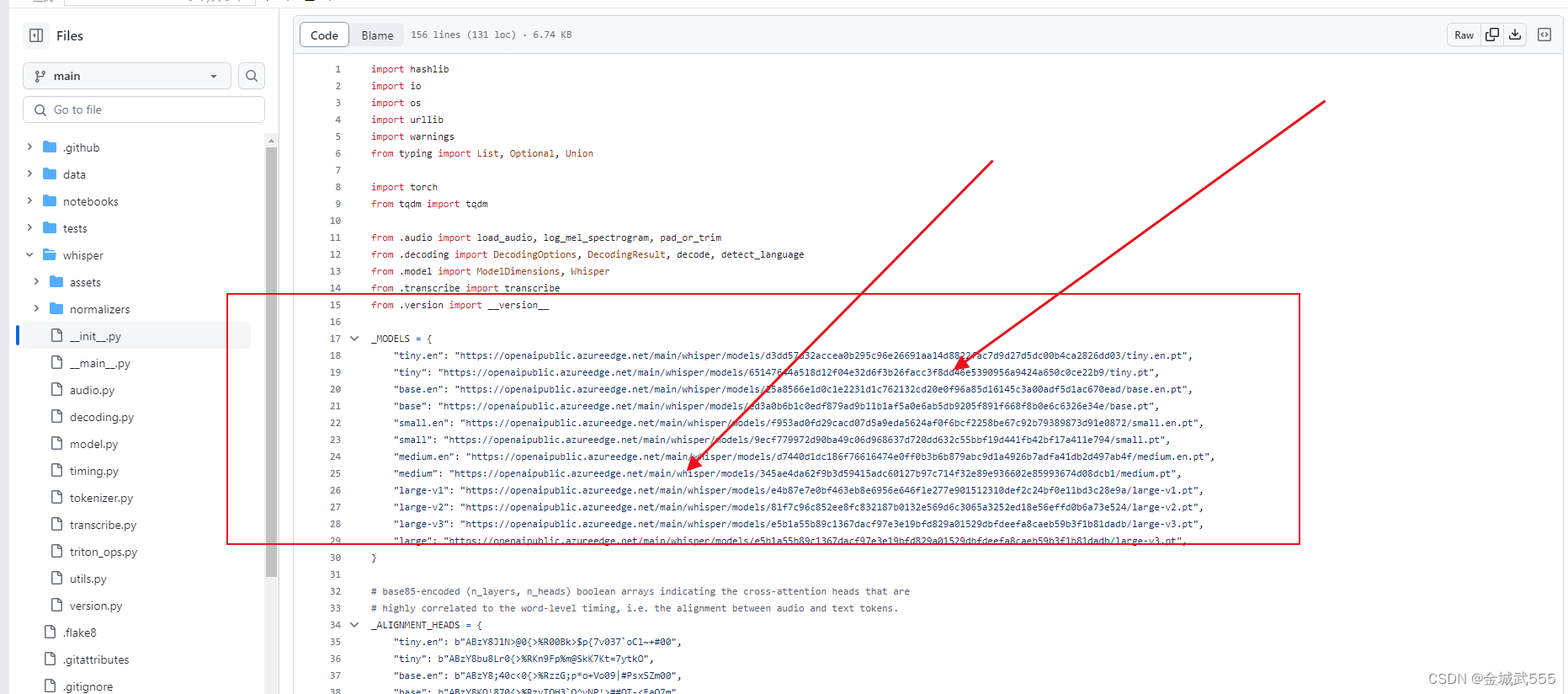
例如,依次从小到大...配置要求如下:
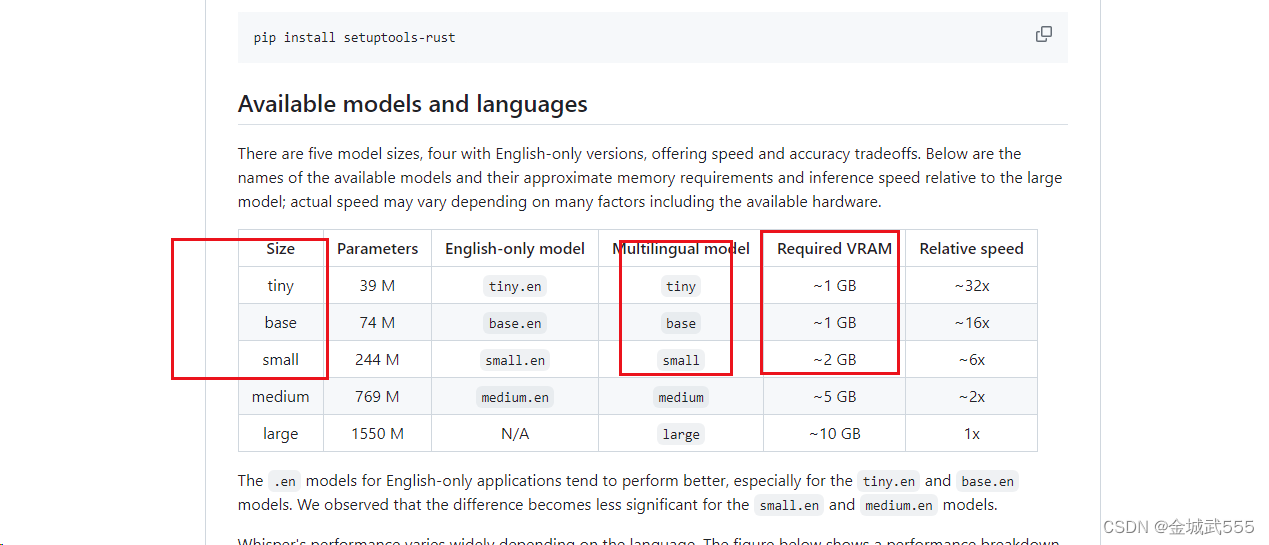
地址:::
?"tiny"最小化模型: "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base"基础款模型: "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
?"small"小型化模型: "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
3.根据 tree/main分支下,进行环境的配置::
地址:
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
下滑到底下,即可看到
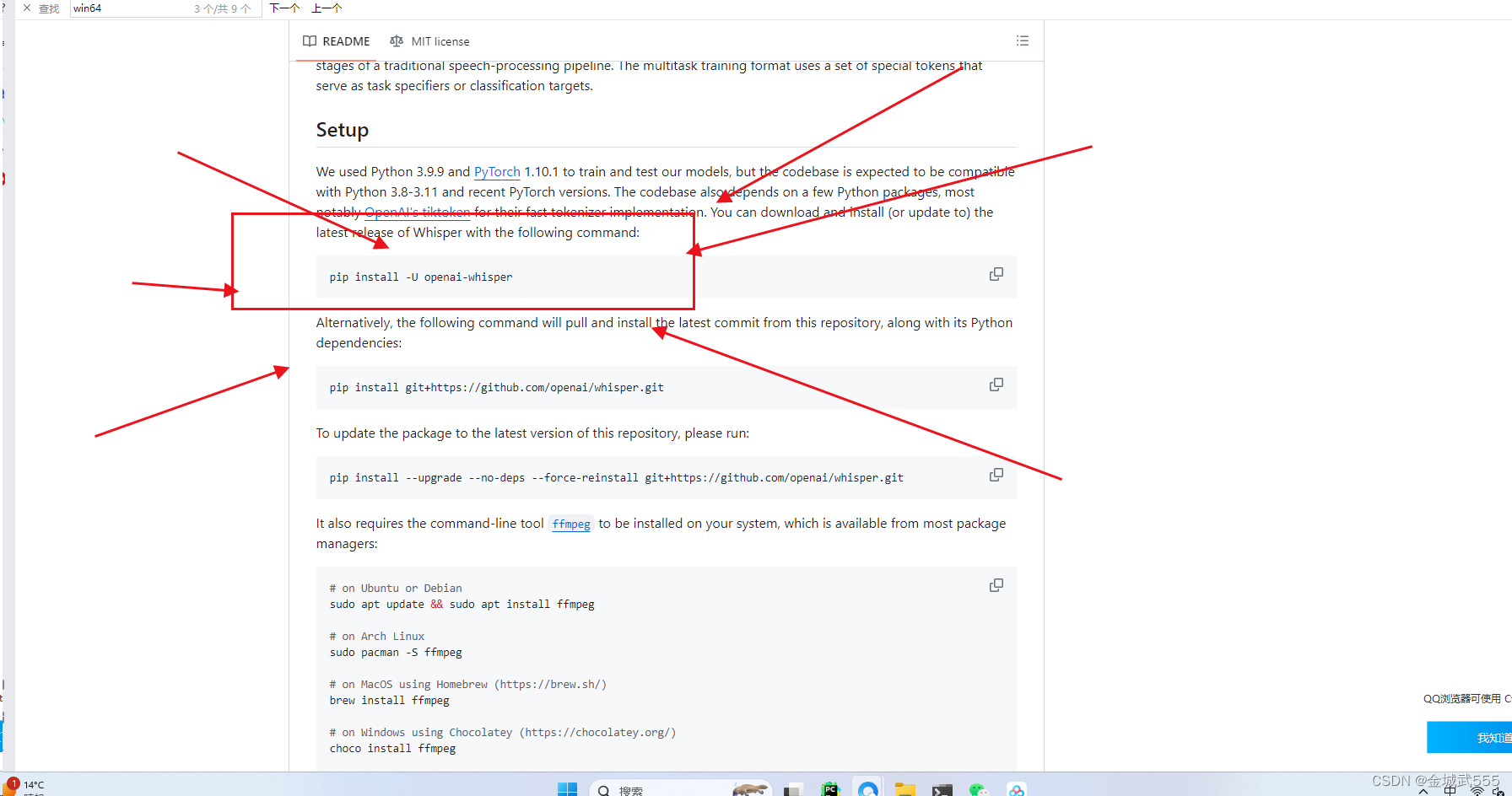
安装好后,直接是cpu版本的pytorch,如若需要gpu版本,可自行安装....
pip uninstall torch,再 pip install 自己gpu版本的torch即可!!!...
4.运用命令:
whisper test.mp3 --model small --model_dir?D:\qbroDownload\whisper-model --language Chinese
#?whisper 音频文件?
--model 模型规格?
--model_dir?模型路径
--language 语言选择/可不选....提前选好可加速..
产生报错:::
transcribe.py:115: UserWarning: FP16 is not supported on CPU; using FP32 instead
5.详情代码::
可作为参考....
import whisper
# 有下载到本地,直接加载 base.pt也可以,不然会直接网络下载
model = whisper.load_model('base')
# 1.传入音频、fp16-cpu版本,gpu版本可以忽略,语言可选项...默认繁体字,用base模型,输出简体字...
result = model.transcribe('./op.wav',fp16=False,language='Chinese')
print(result['text'])
# 2.传入视频也可以...
result1 = model.result = model.transcribe('./video.mp4',fp16=False,language='Chinese')
print(result1['text'])本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Elasticsearch查询多个条件组合
- 项目成本管理
- 理解Go中的指针
- Redis 分布式锁有什么缺陷?
- 【稳定检索、投稿优惠】2024年区域经济与社会科学管理国际会议(ICRESSM 2024)
- 【算法】斐波那契数列 [递推,矩阵快速幂]
- 【蓝桥杯选拔赛真题36】C++业务办理时间 第十四届蓝桥杯青少年创意编程大赛C++编程选拔赛真题解析
- iPhone 与三星手机:哪一款最好?
- NLP任务中常用的损失函数
- 【AI算力棒】瑞芯微算力棒RK1808和RV1126参数对比