MySql 中的 B+树索引和哈希索引
目录
一. 前言
? ? 索引是存储引擎用于快速找到记录的一种数据结构。索引对于数据库良好的性能十分关键,尤其是表中的数据量越来越大时,索引对性能的影响十分明显。
? ? 《高性能MySQL》中对索引的评价是:索引优化应该是对查询性能优化最有效的手段了,索引能够轻而易举将查询性能提高几个数量级。
? ? 以 innodb 为例,innodb 中存储数据的基本元素是页,页里面保存了许多数据记录,各个记录通过链表串联起来。一个 innodb 页的结构为:

innodb 给每个页分配了?16KB?的大小,除了存储用户记录以外还有一些额外的字段没有展示出来。用户记录并不是一定装满了整个页,因此除了用户记录以外还有一部分未使用的空间,后续的新纪录可以继续插入到未使用空间中。
注:在 MySql 中,单条记录的大小不能超过 16K(text、blob 等类型除外)。
除了页内的记录用链表串起来了之外,每个页面也是通过链表连接起来的:
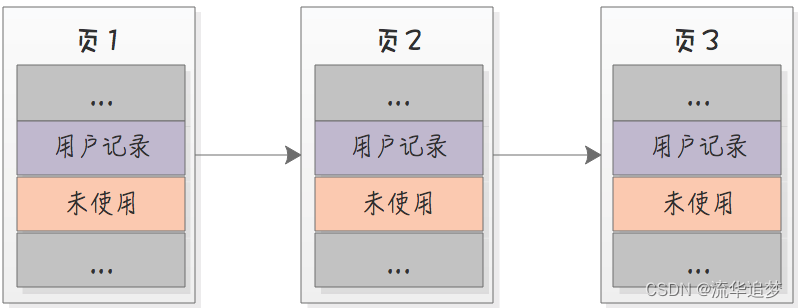
试想正常情况下,如果想要找到一条记录应该怎么找呢?首先要遍历所有的页面,然后遍历页面里面的记录,一条条记录对比,找到需要查询的记录。这样的话时间复杂度是 O(N),N 代表总的记录条数。
如果数据库中只有几条或者几十条记录,查起来或许还行。但是如果数据库有几千万甚至上亿条记录,这么查起来是什么样子?MySql 数据是写在磁盘上的,一次磁盘寻址所需要的时间是10ms,如果有1亿条记录,那么执行一次查询需要10亿毫秒,也就是1百万秒,算下来需要11.5天。这种级别的耗时是任何一个业务系统都无法忍受的。
而索引存在的意义就在于此,通过特定的结构来排布整个数据库,使得系统能在较快的时间内查询到记录。索引就像是一本书的目录,告诉你哪一章在哪一页,想看对应的章节直接放到对应页数就可以了。
一个最简单的索引思路是:把所有的记录排序,通过二分查找的方式来查找元素,查询的时间复杂度是 O(logN)。这样的话1亿条记录,只需要20多次查询就可以了,算下来时间不到1秒,相比之前的11天已经不是一个数量级了。当然,实际的索引实现也不仅仅是二分查找这么简单。
最常用的索引有两种:
- B-Tree 索引,基于 B+树结构的索引。
- 哈希索引,基于哈希表实现的索引。
大部分时候,使用的都是 B-Tree 索引。关于 B+树结构可以参见《详解B-Tree和B+Tree》。
二.?B-Tree 索引
B-Tree 索引是一种基于 B+树结构的索引,B+树因为其独特的结构优势所以被广泛应用于索引中:
- 一个节点包含了多个数据域,适应于操作系统成块访问磁盘的特性,可以一次读取多个节点的数据。
- 相对于 B树来说,B+树非叶子节点不包含任何数据,只包含子节点指针 ,因此一个节点所能指向的子节点个数更多,这样的话 B+树会更矮,查询起来更高效。
一个 B-Tree 索引的结构为(橙色是数据域,绿色是子节点指针):

如果想要找到 id 等于32的记录,首先通过页1定位到子页10,然后继续查找页10,定位到页31,最终找到32。
可以看出,查找的效率是与 B+树的层数相关的,树越高,查找效率越慢,树越低,查找效率越快。实际的应用中,一个页远远不止上面展示的3个记录项,按照一行记录100字节来算,一页数据(16K)至少可容纳1500个记录,那么1亿条记录只需要三层树(?< 1500*1500*1500)。也就是说,1亿条数据最多执行三次 IO 就能定位到,可见其效率之高。
索引除了可以按值查找以外,还支持对 ORDER BY 子句的排序,只要排序字段也正确匹配上了索引就可以。
B-Tree 支持的索引匹配条件:
- 全部匹配:支持同时匹配多个索引。
- 部分匹配:支持同时匹配多个索引中的部分索引。
- 匹配列前缀:对添加了索引的列,可以匹配其左前缀。例如匹配 maqian 中的前缀 ma。
- 匹配范围:支持对索引列去范围值。
三. 哈希索引
哈希索引是一种基于哈希表的索引结构,它是一种需要精确匹配才生效的索引结构。
3.1.?哈希索引的实现原理
实现原理:对索引列计算哈希值把记录映射到哈希槽中,然后指向对应记录行的地址。因此,在查询的时候只要正确匹配到索引列,就能在 O(1) 的时间复杂度内查到记录。
以下是一个哈希索引的示例,左边是哈希槽,右边是对应的数据列:

相比于 B-Tree 索引而言,哈希索引有不少的局限性:
- 哈希索引不支持排序;
- 哈希索引不支持部分列索引查找;
- 哈希索引只支持等值查询,无法提供范围查询功能。
哈希索引的查找效率是非常高的,大多数时候都能在 O(1) 的时间内找到记录,除非哈希冲突很高。
innodb 中有一个内建功能叫自适应哈希,当存储引擎注意到有列频繁访问的时候,就会建立对应的哈希索引。这样,引擎就同时拥有了 B-Tree 索引和哈希索引,就能使用更加快速的查找。这是一个无需人工干预的自动行为。
3.2.?哈希索引的使用场景
? ? 哈希索引常见的一种场景是针对长字符串查询的优化,例如数据库中保存了大量的 URL 信息,查询 URL 中不可能一个字符一个字符去搜索,这样效率太低。
? ? 这种情况就可以使用哈希索引:给所有的 URL 计算一个 crc 保存起来,然后对 crc 做哈希索引。查询的时候指定 crc 和 url 就能快速定位到记录了。如:
SELECT * FROM url_info WHERE crc = xxxx AND url = 'http://www.baidu.com'执行这条语句的时候,会先针对 crc 查找哈希索引,找出所有 crc 值等于xxxx的记录,过滤掉大多数不符合条件的记录。然后再根据后面的 url 信息详细匹配,这样查询效率就很高了。
四. 索引的缺点
所有的优点是查询速率很快,但同时也有缺点。
索引的主要缺点是会导致插入和更新语句变慢,因为每次更新数据都要重新维护索引,索引越多,耗时越长。
同时,如果建立了不恰当的索引可能还会导致数据库性能更低,这个就依赖人工的操作了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python中的组合数据类型
- 祝贺!我的同事丁宇获“2023 年度云原生产业领军人物”荣誉称号
- 复制Ubuntu遇到的问题及解决办法、Ubuntu上git命令更改和查看账户、实现Ubuntu与Windows之间的文件共享
- 微信小程序:发送小程序订阅消息
- vue3-响应式基础之reactive
- LINUX基础培训九之网络管理
- Java面试题(1)
- 深拷贝和浅拷贝(js的问题)
- K8S(一)—安装部署
- 在C++类声明中为什么既包含接口又包含实现