Golang协程池ants库的学习、使用及源码阅读,协程池与GMP模型关系的理解
前言
在工作时遇到了一个需要使用ants协程池的地方,因此顺带来学习一下他的原理。

协程池
Golang的资源还是偏少一些…因此先简单的参考学习了一下线程池。
类似于Java中的线程池,协程池也是为了减少协程频繁创建、销毁所带来资源消耗的问题。按默认每个goroutine 8kb内存来算,几十万个goroutine就会占满8Gb内存。同时,由于goroutine的结束需要等待自身运行结束才可以销毁,所以也可能出现goroutine泄露的问题。因此需要使用协程池,来进行管理。
本文是ants协程池的学习,其他优秀的协程池日后有机会再去学习。
ants库对性能的提升
直接引用作者的结论“用ants的吞吐性能相较于原生 goroutine 可以保持在 2-6 倍的性能压制,而内存消耗则可以达到 10-20 倍的节省优势。”
在goroutine越多时候,提升越明显。具体请参阅作者文档中给出的性能测试部分。——https://github.com/panjf2000/ants/blob/dev/README_ZH.md
ants库工作流程
这个是作者在文档中所给出的流程图。在原文档中还提供了动态图,但我的电脑上他们没动…所以我也就不搬运了。具体还是请参阅作者文档。
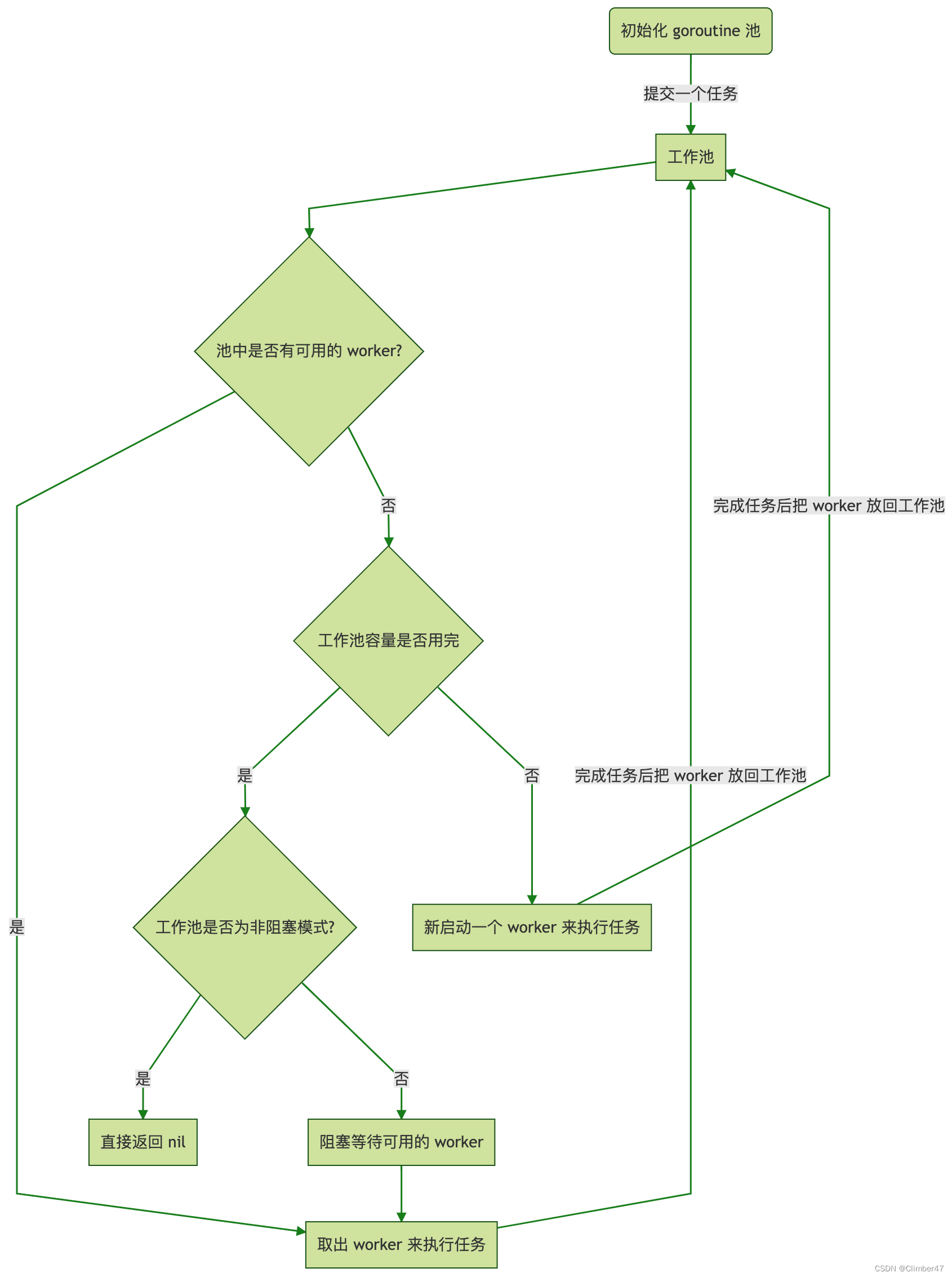
当一个任务被丢尽协程池后,大致分为以下几步:
1、判断是否有可用的worker。若有,分配任务到worker,并执行即可。
2、若无可用的worker,判断是否达到容量上限。若未达到上限,新增一个worker并分配执行即可。
3、若已达到上限,则判断是否允许阻塞。若不允许,则直接返回nil即可。
4、若允许阻塞,则阻塞至有可用worker,再分配执行即可。
5、对于一个执行完成任务的worker,再放回工作池。
ants库源码对照阅读
由于笔者学术不精且文笔欠佳,因此此部分仅是简单阅读记录,一篇详细且高质量的源码阅读请参阅Go 每日一库之 ants(源码赏析)。此文阅读、解析的十分详细。
新建Pool
Pool所用到的的数据结构如下。
type Pool struct {
// capacity of the pool, a negative value means that the capacity of pool is limitless, an infinite pool is used to
// avoid potential issue of endless blocking caused by nested usage of a pool: submitting a task to pool
// which submits a new task to the same pool.
capacity int32
// running is the number of the currently running goroutines.
running int32
// lock for protecting the worker queue.
lock sync.Locker
// workers is a slice that store the available workers.
workers workerQueue
// state is used to notice the pool to closed itself.
state int32
// cond for waiting to get an idle worker.
cond *sync.Cond
// workerCache speeds up the obtainment of a usable worker in function:retrieveWorker.
workerCache sync.Pool
// waiting is the number of goroutines already been blocked on pool.Submit(), protected by pool.lock
waiting int32
purgeDone int32
stopPurge context.CancelFunc
ticktockDone int32
stopTicktock context.CancelFunc
now atomic.Value
options *Options
}
其中大致如下几个参数:
capacity:池容量,表示ants最多能创建的 goroutine 数量。负值意味着池的容量是无限的,使用无限池是为了避免由于嵌套使用池而导致的无限阻塞的潜在问题:提交一个任务到池,该池将一个新任务提交到相同的池。
running:是当前正在运行的goroutines的数量。
workers:存储可用worker的切片。works是一个workerQueue类型的接口,位于workerQueue.go这个文件中。
state:记录池子当前是否已关闭(CLOSED)。
waiting:已经被pool.Submit()阻塞的协程数量,由pool.lock保护。
lock:锁。
cond:条件变量。处理任务等待和唤醒。
blockingNum:阻塞等待的任务数量。
其他具体的见源码中
// NewPool instantiates a Pool with customized options.
func NewPool(size int, options ...Option) (*Pool, error) {
if size <= 0 {
size = -1
}
opts := loadOptions(options...)
if !opts.DisablePurge {
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
}
if opts.Logger == nil {
opts.Logger = defaultLogger
}
p := &Pool{
capacity: int32(size),
lock: syncx.NewSpinLock(),
options: opts,
}
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerQueue(queueTypeLoopQueue, size)
} else {
p.workers = newWorkerQueue(queueTypeStack, 0)
}
p.cond = sync.NewCond(p.lock)
p.goPurge()
p.goTicktock()
return p, nil
}
NewPool就是新建一个Pool,其接收的参数是(size int, options ...Option) ,第一个是容量,其他可选项。
通过Submit进行任务提交
此部分源码如下
func (p *Pool) Submit(task func()) error {
if p.IsClosed() {
return ErrPoolClosed
}
w, err := p.retrieveWorker()
if w != nil {
w.inputFunc(task)
}
return err
}
首先判断池子是否关闭,关闭则直接err。
接下来通过retrieveWorker来判断是否有空闲的worker。
若w!=nil 即有空闲worker,则通过w.inputFunc(task)新增一个任务。
w.inputFunc(task)部分如下
func (w *goWorker) inputFunc(fn func()) {
w.task <- fn
}
是把任务提交到了一个goWorker结构体中的task chan func()。这个goworker是worker接口的实现,他其中chan的任务会进行run。
通过retrieveWorker判断空闲worker
此部分源码如下,其所返回的是一个可用的worker
// retrieveWorker returns an available worker to run the tasks.
func (p *Pool) retrieveWorker() (w worker, err error) {
p.lock.Lock()
retry:
// First try to fetch the worker from the queue.
if w = p.workers.detach(); w != nil {
p.lock.Unlock()
return
}
// If the worker queue is empty, and we don't run out of the pool capacity,
// then just spawn a new worker goroutine.
if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
w = p.workerCache.Get().(*goWorker)
w.run()
return
}
// Bail out early if it's in nonblocking mode or the number of pending callers reaches the maximum limit value.
if p.options.Nonblocking || (p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks) {
p.lock.Unlock()
return nil, ErrPoolOverload
}
// Otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
p.addWaiting(1)
p.cond.Wait() // block and wait for an available worker
p.addWaiting(-1)
if p.IsClosed() {
p.lock.Unlock()
return nil, ErrPoolClosed
}
goto retry
}
首先通过p.workers.detach()判断是否有空闲的worker。若有,则直接返回可用的worker。
若无,通过
if capacity := p.Cap(); capacity == -1 || capacity > p.Running()
这一个判断来判断是否耗尽了池容量。若没有耗尽,则通过p.workerCache.Get().(*goWorker)生成一个新的工作goroutine,并返回workers。
继续执行则是“没有空闲worker且池容量已满”的情况。便通过
if p.options.Nonblocking || (p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks)
判断,是否处于非阻塞模式,或者待处理的呼叫者数量达到最大值,若是,则退出返回nil。
反之,通过
p.addWaiting(1)
p.cond.Wait() // block and wait for an available worker
p.addWaiting(-1)
进行阻塞等待可用的即可。
此部分整体通过一个retry:标签和goto retry来进行控制,通过一个lock保证了安全。具体看作者源码部分,此处不搬运描述。
run部分
在chan中的任务会依次去run,run的源码部分如下:
// run starts a goroutine to repeat the process
// that performs the function calls.
func (w *goWorker) run() {
w.pool.addRunning(1)
go func() {
defer func() {
w.pool.addRunning(-1)
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from panic: %v\n%s\n", p, debug.Stack())
}
}
// Call Signal() here in case there are goroutines waiting for available workers.
w.pool.cond.Signal()
}()
for f := range w.task {
if f == nil {
return
}
f()
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
简单来说,这部分是开协程,并在其中:增减相关计数、运行函数。相当于是把goroutine又交给了底层GMP模型去进行处理。
ants库的使用
根据作者文档的描述,主要提供了下述几种功能“任务提交、获取运行中的 goroutine 数量、动态调整 Pool 大小、释放 Pool、重启 Pool”。
下面是我一次使用ants库记录。
https://blog.csdn.net/Ws_Te47/article/details/135484767
此次使用只是用到了最基础的功能,新建Pool、任务提交、释放Pool。
一个更详细的使用demo请见——https://darjun.github.io/2021/06/03/godailylib/ants/
关于GMP模型和协程池
在昨天的初步学习中,曾出现过一个疑惑,GMP模型和协程池,到底是什么关联?我疑惑在他们都是用于协程的分配与控制。协程池通过一系列的判断来判断是否运行,但GMP不也有队列去分配吗?
今天突然恍然大悟,在学习完源码后也进一步清晰了他。
GMP模型是用于协程分配给线程这一个过程的,他的起点是“一个新建好的协程”,并将这个协程去进行一系列的排队、抢占调度等 操作,最终终点是分配到线程,并最终经CPU进行执行。
但协程池的主要目的是goroutine的复用,减少因频繁新建、销毁goroutine所带来的性能损耗。他的起点是“一个需要通过goroutine执行的方法”,通过一系列的判断、分配,最终的终点是在run方法中去启用一个goroutine。
所以可以说,协程池的终点是GMP的起点。一个任务先通过协程池去挑选合适的时机,分配到对应的goroutine;再通过GMP模型,去分配给对应的线程,最终分配到CPU进行执行。
参考资源
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android Studio 之 菜单 Menu
- ZYNQ 调用AXI WR RD ip及其代码
- [鹏城杯 2022]简单包含
- ChatGPT 和文心一言,各有优劣
- Wayfair 开启2024年的裁员模式
- Linux vgchange命令
- 4-6 zust-sy7-8求圆的面积——python
- 操作无法完成错误0x00000bc4的修复方法,以及出现0x00000bc4的原因
- LINUX常用工具之性能分析工具推荐
- Easyexcel 将指定单元格的文字设置成指定的颜色