语义分割发展现状
-
语义分割是对图像中的每一个像素进行分类,目前广泛应用于医学图像与无人驾驶等。从这几年的论文来看,这一领域主要分为有监督语义分割、无监督语义分割、视频语义分割等。
语意分割究竟有什么用呢?似乎看起来没有目标检测/跟踪等应用范围广。
- 数据问题:分割不像检测等任务,只需要标注一个bbs就可以拿来使用,分割需要精确的像素级标注,包括每一个目标的轮廓等信息;
- 计算资源问题:个人觉得太吃backbone,这就说明了如果要想得到较高的精度就需要使用类似于ResNet101等深网络。同时,分割预测了每一个像素,这就要求feature map的分辨率尽可能的高,这都说明了计算资源的问题,加GPUGPUGPU.....,虽然也有一些轻量级的网络,但精度还是太低了,期待类似于YOLO/SSD这样的工作能在分割中出现;
- 精细分割:查看cityscape结果可以看出,很多算法的像道路、建筑物等类别,分割精度很高,能达到98%,而对于细小的类别,像行人、交通等等,由于其轮廓太小,而无法精确的定位轮廓,造成精度较低;
- 上下文信息:分割中上下文信息很重要,否则会造成一个目标被分成多个part,或者不同类别目标分类成相同类别;
- 非深度学习方法:经典的特征+forst/boost+CRF的分割pipline,但是每一个分类器一般只针对单一的类别设计,如果分割类别数很多,会造成计算复杂,训练难度大的问题。并且非深度学习方法受特征的限制较大,精度一直没有增加很多。
- 深度学习方法:自2014年的FCN与Deeplabv1的提出,近几年深度学习语义分割方法进步明显,并且深度学习方法可以直接预测多类别目标,这克服了非深度学习方法的单类别的限制,但对于但类别问题,仍然是深度学习方法好,如道路分割等。
- encoder-decoder方法:与经典的FCN中的skip-connection思想类似,encoder为分类网络,用于提取特征,而decoder则是将encoder的先前丢失的空间信息逐渐恢复,decoder的典型结构有U-Net/segnet/refineNet,该类方法虽然有一定的效果,能恢复部分信息,但毕竟信息已经丢失了,不可能完全恢复。
- dialed FCN方法:deeplabv1提出的方法,将vgg的最后的两个pool层步长置为1,这样网络的输出分辨率从1/32变为1/8。可以保留更多的细节信息,同时也丢掉了复杂的decoder结构,但这种方法计算量大。
- 二分支轻量化分割方法:2020年提出BiseNet,三分支网络
- mIoU:这个指标是应用最多的,也是目前排名分割算法的依据。IoU就是每一个类别的交集与并集之比,而mIoU则是所有类别的平均IoU。论文均使用这一指标比较。
- speed:由于有些分割算法是针对实时语义分割设计的,所以速度也是一个很重要的评价指标,当然评价速度需要公平比较,包括使用的图像大小、电脑配置一致。
- 当然还有其他指标,如pixel accuracy、mean accuraccy等。

其中(k+1)为类别数,pii表示TP,pij表示FN,pji表示FP(i表示真实类别,j表示其他类别),则每一个类别的IoU可以看作,IoU=TP/(TP+FN+FP).
以三个类别为例,如下是一个混淆矩阵:

对于类别1:TP=43,FN=7,FP=2;类别2:TP=45,FN=5,FP=6;类别3:TP=49,FN=1,FP=5.因此:IoU1=43/(43+2+7)=82.69%,IoU2=45/(45+5+6)=80.36%,IoU=49/(49+1+5)=89.09%,因此mIoU=84.05%.其实就是矩阵的每一行加每一列,再减去重复的TP。
常用数据集
目前语义分割领域使用的数据集较多,这里主要介绍3个数据集,VOC2012/Cityscape/CamVid,所有数据集均没有达到饱和,仍有很大发展空间,无论在准确性还是实时性。
忽视标签(ignore label)
在介绍数据集之前,先来了解一下忽视标签的概念与作用。忽视标签从字面上理解,就是该标签不用于计算损失,也不用于计算精度。以一个三个类别的例子为例。
该例子,包含3个目标类别,1个背景类别,1个忽视类别。
标签可以设置为:0,1,2,3,4
其中,0代表背景,1-3代表目标类别,4代表忽视目标。
那么,目标类别数到底该设为多少呢?4还是5。
这里我看了很多地方,最简单的方式就是设置为4,这样训练过程中,4这个类别将不计算损失,同时我们也不需要进行预测argmax。
VOC2012
第1个数据集介绍VOC,相信做视觉的人都知道这个数据集,里面包括很多任务,包括目标检测、语义分割等。VOC:Main.
原始VOC2012数据集:1464训练集,1449验证集,1456测试集。经过加强的数据集,包含10582训练集,1449验证集,1456测试集。目前论文结果均使用后者进行训练。该数据集特点包括:
- 数据集包含21类别目标,20类目标+1类背景,分辨率大小不完全相同,为此训练过程为了能处理batch图像,因此需要将图像固定到某一大小,deeplab里面使用321大小。
- 该数据集中,label处理时发现并没有忽视标签,均在0-21之间,因此不需要设置忽视标签。在deeplab版本里作者将ignore_index设为255,标签里面本来就没有255,设不设置没关系.
- 每幅图像包含的目标类别很少,但每个目标的轮廓还是比较复杂,因此,该数据集的分割精度没有想象中那么高。
第3个数据集是2016提出的用于自动驾驶的数据集Cityscape:Main,
- M. Cordts, M. Omran,?et al.?The Cityscapes Dataset for Semantic Urban Scene Understanding.//CVPR?2016.

训练集2975,验证集500,测试集1525。训练集与验证集包括Fine annotations以及额外的19998个coarse annotations,可以于训练集一起训练。测试集标注没有公开。数据集主要特点包括:
- 标签包括:'name'/'id'/'trainId'/'category'/'catId'/'hasInstances'/'ignoreInEval'/'color '等,'id'是原始的标注id,而'trainId'是用于训练的Id,'ignoreInEval'为忽视对象。
- 原始的标注包括35类,其中有16类为在评测中忽视的类别,因此训练时候只有19类,因此标签可以设置为0-18,验证的时候也可以使用0-18。如果要测试,则需要将0-18反变化回原始标签。
- 原始标注文件包括:color.png/instanceIds.png/labelIds.png/polygons.json四个文件,其中,labelIds.png文件为原始标注,因此需要将该文件转换为trainIds,可以参考labels.py和preparation,转换后忽视标签为255,而其他标签为0-18,这样训练过程使用19类目标,忽视255。在处理过程中,可以将mask[index==255] = -1,这样损失函数不会计算。或者计算softmax损失的时候设置ignore_index=255。
- 图像分辨率较大,1024*2048,如果使用原图训练,计算量太大,一般会crop一定的大小,但也不能太小,太小效果很差,猜想:这也是这个数据集精度很难提升的一个原因。
- 从提交的评测结果可以看出,基本都是深度学习方法(没有全部过一遍)。传统算法在这种环境复杂的交通场景做分割难度还是太大了。
- 每幅图像涵盖的目标类别较多,同时,存在很多细小目标,使得分割难度进一步增大。
CamVid发展状况:由于CamVid这个数据集使用的人不多,也没有专门管理,以下是我收集的几个算法的结果:
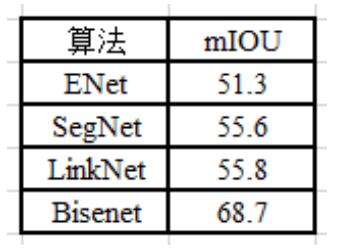
- Arxiv 2016?ENet?51.3%,Titan X上640×360分辨率可以达到135.4fps,有望上ARM,但精度的确很低;
- PAMI 2017?SegNet?55.6%,Titan X上640×360分辨率可以达到14.6fps,精度仍然很低;
- Arxiv 2017?LinkNet?55.8%,encoder-decoder结构,ResNet18+反卷积;
- ECCV 2018?BiseNet?68.7%, 精度有较高提升,Titan X上640×360分辨率可以达到129.4fps,实时性与ENet接近,但精度提升了很多;
- VOC2012发展状况:VOC提交的结果较多,以下总结近几年的STOA:

- 现在的VOC语义分割也基本上被深度学习霸版,当然还有其他很多算法,这里只列了部分;
- 目前最好的结果基于Deeplabv3+,在JFT上预训练,89.0%;
- 2015年的FCN 62.2%,在视觉领域占有很高的地位,CVPR论文引用量排第二;
- 2015年STOA为Deeplabv1,71.6%,CRF+FCN;
- 2016年STOA是Deeplabv1的延伸Deeplabv2,79.7%,Resnet101+Aspp;
- 2017年STOA,PSPNet 85.4%/RefineNet 84.2%/Deeplabv3?85.7,三个算法有了进一步突破;
- 2018年STOA是Deeplabv3+,87.8% ,Dailed ConV+encoder-decoder;
- 语义分割,google(deeplab系列)和Face++(GCN/DFN/Exfuse),出力不少啊;
Cityscape发展状况:提交的结果较多,以下总结近几年的STOA:

- 同样基本上被深度学习霸版,目前最好结果科大讯飞83.6%;
- 由于Cityscape是2016年出的数据集,很多算法补上去的,FCN?65.5%/Deeplabv1 63.1%/deeplabv2?70.4%,其他实时语义分割算法,ENet 58.3%/Segnet 55.6%;
- 2017年的STOA是Deeplabv3?81.3%,PSPNet与RefineNet结果也挺好;
- 2018年的STOA是DRN?82.8%,RNN+FCN;
- 该数据集2017、2018提交结果逐渐增多,且上面很多结果都是匿名或者是公司提交,并没有发表论文等,因此很难考究;
- 今年精度提升不多,前几名差距很小,期待更有效地结构出现。
以上是截止2018/11/7自己看了大量论文后统计的结果,表格里面只是少数,是我个人觉得比较有代表性的算法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据结构与算法教程,数据结构C语言版教程!(第四部分、字符串,数据结构中的串存储结构)四
- 程序员必备的面试技巧
- 光伏发电在什么情况下不可以使用?安装后可以拆除吗?
- STM32F407-14.3.10-表73具有有断路功能的互补通道OCx和OCxN的输出控制位-1x111
- JAVA反射知识点总结
- spring常见漏洞(4)
- C语言—每日选择题—Day58
- smali语言详解之一般/构造方法(函数)的声明与返回值关键字
- 配置资源管理
- python的__doc__