基于电商场景的高并发RocketMQ实战-Broker写入读取流程性能优化总结、Broker基于Pull模式的主从复制原理
发布时间:2023年12月25日
🌈🌈🌈🌈🌈🌈🌈🌈
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
Broker 写入读取流程性能优化总结
Broker 的物理存储结构主要是为了优化三个方面:写入、存储、读取
写入优化:
- 将消息数据写入到 Commitlog 中默认就是写入到了操作系统的
page cache中,通过mapped file机制来实现,将磁盘文件 Commitlog 映射成一块内存区域,将数据写入到内存的 page cache 中就算写入完成了,等待后台线程将内存数据异步刷入磁盘即可,这种情况下只有 Broker 所在的机器宕机了,才会导致几百毫秒内的内存数据丢失,这种概率是很小的 - Broker 存储数据是主要有三个结构的:Commitlog、ConsumeQueue、IndexFile,可参考文章,数据写入到 Commitlog 中的速度是很快的,再通过
异步将 Commitlog 中的数据建立成索引写入到 ConsumeQueue、IndexFile,这个过程是异步,对写消息流程没有性能影响,即使写入到 ConsumeQueue、IndexFile 的过程中宕机了,只要 Commitlog 文件还在,Broker 重启之后,就会继续向 ConsumeQueue、IndexFile 中写入索引
存储结构:
- ConsumeQueue 存储结构经过了极大的优化设计的。每个消息在 ConsumeQueue 中存储的都是
定长的 20B,每个 ConsumeQueue 文件可以存储 30w 个消息 - Commitlog 存储结构也是精心设计,每个文件
默认 1GB,满了之后就存下一个文件,避免了某个文件过大,并且每一条消息在所有的 Commitlog 中记录了有偏移量,Commielog 的文件名就是这个文件第一条消息的总物理偏移量
读取优化:
- 根据消息逻辑偏移量,来定位到 ConsumeQueue 的磁盘文件,在磁盘文件里就可以根据
逻辑偏移量计算出物理偏移量,可以直接定位到消息在 Commitlog 中的物理偏移量,通过两次定位就可以读取出数据 - 通过
transiendStorePoolEnabled 机制解决了高并发读写场景下的 Broker busy 问题,实现了读写分离
Broker 基于 Pull 模式的主从复制原理
Broker 主从复制基于 Pull 模式实现的,即生产者将数据写入到 Broker 主节点之后,等待 Slave 向 Master 发送请求,主动拉取数据
Broker 的从节点需要拉取数据时,会向主节点发送请求建立连接,当建立连接之后,在主节点会建立一个 HAConnection 的数据结构,用于将与从节点之间的连接抽象出来,而在从节点会创建两个 HAClient,一个是主从请求线程,另一个是主从响应线程,HAClient 是从节点的核心类,负责与主节点创建连接与数据交互
那么当从节点向主节点发送连接建立,建立好连接之后,Slave 会向 Master 发送一个最大偏移量 Max Offset,那么主节点根据这个 Offset 偏移量去磁盘文件中读取数据,并将数据发送到 Slave,Slave 进行数据的保存,总体流程如下图:
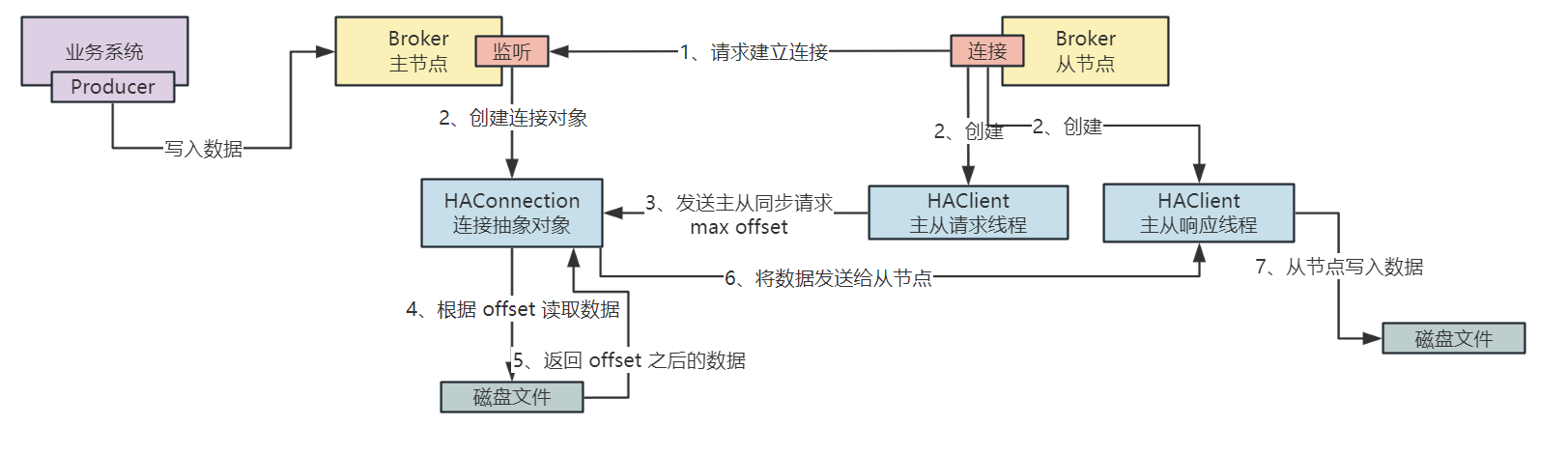
文章来源:https://blog.csdn.net/qq_45260619/article/details/135193366
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Spring-Securty】安全框架使用详解
- MySQL之视图&索引&执行计划
- 详解feature_importances_
- 设计模式-过滤器模式
- valgrind being installed on Arm platform
- JavaScripts笔记I(基础)
- vue3 实现关于 el-table 表格组件的封装以及调用
- Python数据挖掘与机器学习实践技术应用
- Java中泛型的擦除机制
- 【设计模式】责任链模式