gpu显卡简介
一、目录
1.基本常用参数
2. nvidia 显卡基本了解(基本简介)
3. 显卡查看算力
4. 显卡算力、驱动版本(Driver Version)、CUDA Toolkit(CUDA Version)、PyTorch版本之间的关系
5. 显卡安装流程
6. NVIDIA显卡简介
二、实现
-
基本常用参数
1. 显存
2. 算力
3. 浮点性能(精度):代表显卡的浮点计算能力,越高算力越强。
4. 带宽:显存带宽直接决定显卡的性能,越高则性能越强。它受到显存类型和显存容量的共同影响。
5. CUDA 核心和Tensor 核心:Core的数量越多,并行运算的线程越大,计算的峰值越高。
6. 频率:核心频率越高,显卡性能越强。在挑选显卡时,应注意核心频率与显存类型和显存容量的搭配,以确保整体性能的平衡。 -
nvidia 显卡基本了解(基本简介)
https://www.nvidia.cn/data-center/tensor-cores/ -
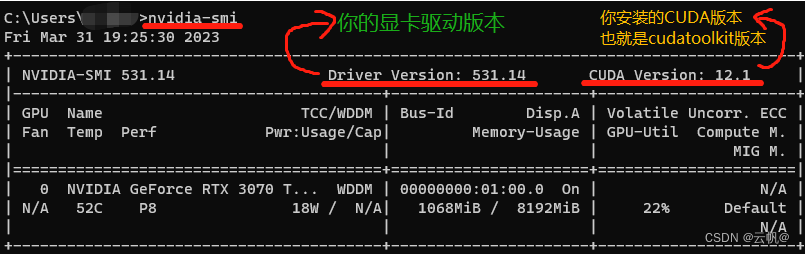
显卡算力、驱动版本(Driver Version)、CUDA Toolkit(CUDA Version)、PyTorch版本之间的关系
显卡算力:显卡本身的计算能力。
查看网址: https://developer.nvidia.com/cuda-gpus
驱动版本:根据显卡型号以及想要安装的cuda Toolkit 选择驱动版本,受系统版本影响。
网址:https://www.nvidia.cn/Download/index.aspx?lang=cn
cuda: 为程序提供一个开发环境。cuda 的选取由显卡驱动版本决定。
型号选取查看网址:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
下载网址:https://developer.nvidia.com/cuda-toolkit-archive
详情网址:https://developer.nvidia.com/cuda-toolkit
pytorch: 程序开发框架。pytorch 的选取由cuda 决定,同时受算力影响,也对python 版本有要求。
网址:https://pytorch.org/get-started/previous-versions/

-
显卡安装流程(详情安装见gpu显卡安装帖子)
- 安装显卡驱动
网址:https://www.nvidia.cn/Download/index.aspx?lang=cn
2. 安装CUDA Toolkit(cuda)
网址:https://developer.nvidia.com/cuda-toolkit-archive
3. 安装cudnn
cudnn是由NVIDIA开发的一个深度学习GPU加速库。旨在提供高效、标准化的原语来加速深度学习框架在NVIDIA GPU上的运算。
网址:https://developer.nvidia.com/rdp/cudnn-archive
4. 安装python
略
5. 安装pytorch
网址:https://pytorch.org/get-started/previous-versions/
- 安装显卡驱动
-
NVIDIA显卡简介
NVIDIA常见的三大产品线如下:
1. GeForce类型: GeForce系列是NVIDIA面向个人计算和游戏市场推出的产品线,适用于游戏、图形处理等,并且在深度学习上的表现也非常出色,很多人用来做推理、训练,性价比高。例如目前非常热门的4090、3090等型号。
2. Quadro类型:Quadro系列是NVIDIA专为专业工作站和专业图像应用开发的产品线,比如设计、建筑等,是图像处理专业显卡,满足专业用户对精确图形处理和计算的需求。
3. Tesla类型: Tesla系列显卡是NVIDIA针对高性能计算和人工智能领域推出的产品线,被广泛应用于科学计算、深度学习、大规模数据分析等领域。Tesla显卡采用GPU加速计算,具备强大的并行计算能力和高性能计算效率,我们常说的A100、A800、V100、T4、P40等都属于Tesla系列的显卡。显卡详情查看:https://www.nvidia.cn/data-center/tensor-cores/
https://www.nvidia.com/zh-tw/geforce/graphics-cards/compare/
如A100白皮书:https://www.nvidia.cn/data-center/a100/

1. Volta Tensor Core
第一代Tensor Core支持FP16和FP32下的混合精度矩阵乘法,可提供每秒超过100万亿次(TFLOPS)的深度学习性能,是Pascal架构的5倍以上。与Pascal相比,用于训练的峰值teraFLOPS(TFLOPS)性能提升了高达12倍,用于推理的峰值TFLOPS性能提升了高达6倍,训练和推理性能提升了3倍。
2. Turing Tensor Core
第二代Tensor Core提供了一系列用于深度学习训练和推理的精度(从FP32到FP16再到INT8和INT4),每秒可提供高达500万亿次的张量运算。
3. Ampere Tensor Core
第三代Tensor Core采用全新精度标准Tensor Float 32(TF32)与64位浮点(FP64),以加速并简化人工智能应用,可将人工智能速度提升至最高20倍。
4. Hopper Tensor Core
第四代Tensor Core使用新的8位浮点精度(FP8),可为万亿参数模型训练提供比FP16高6倍的性能。FP8用于 Transformer引擎,能够应用FP8和FP16的混合精度模式,大幅加速Transformer训练,同时兼顾准确性。FP8还可大幅提升大型语言模型推理的速度,性能较Ampere提升高达30倍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- idea中使用git提交代码报 Nothing To commit No changes detected
- Redis-集群
- 手把手教你学会接口自动化系列四-编写获取筛选场景
- 基于SSM的流浪动物救助网站的设计与实现-计算机毕业设计源码82131
- ChatGPT持续火热,OpenAI年收入突破16亿美元
- 论文阅读_CogTree_推理的认知树
- CSS Day10
- Git的基本使用
- Pytest框架 —— 用例标记和测试执行篇!
- 阿里云服务器2024年2核16G、4核32G、8核64G配置最新收费标准及活动价格