大模型核心技术原理: Transformer架构详解
在大模型发展历程中,有两个比较重要点:第一,Transformer 架构。它是模型的底座,但 Transformer 不等于大模型,但大模型的架构可以基于 Transformer;第二,GPT。严格意义上讲,GPT 可能不算是一个模型,更像是一种预训练范式,它本身模型架构是基于 Transformer,但 GPT 引入了“预测下一个词”的任务,即不断通过前文内容预测下一个词。之后,在大量的数据上进行学习才达到大模型的效果。
之所以说 Transformer 架构好,是因为 Transformer 能够解决之前自然语言处理中最常用的 RNN 的一些核心缺陷,具体来看:一是,难以并行化,反向传播过程中需要计算整个序列;二是,长时依赖关系建模能力不够强;三是,模型规模难以扩大。
那么,Transformer 具体是如何工作的?
首先,是对输入进行标识符化,基于单词形式,或字母,或字符子串,将输入文本切分成几个 token,对应到字典中的 ID 上,并对每个 ID 分配一个可学习的权重作为向量表示,之后就可以针对做训练,这是一个可学习的权重。
在输入 Transformer 结构之后,其核心的有自注意力模块和前向传播层。而在自注意力模块中,Transformer 自注意力机制建模能力优于 RNN 序列建模能力。因此,有了 Transformer 架构后,基本上就解决了运行效率和训练很大模型的问题。
基于 Transformer 架构的主流语言大模型主要有几种:
一是,自编码模型,如 BERT,简单讲就是给到一句话,然后把这句话的内容挖空,当问及挖空的内容时,就把内容填回去,这其实是典型地用来做一个自然语言理解的任务,但做生成任务是非常弱的;
二是,自回归模型,如 GPT,它是通过不断地预测下一个词,特点是只能从左到右生成,而看不到后面的内容。GPT-1 最后接了一个 Linear 层做分类或选题题等任务,到了 GPT-2 ,已经将一些选择任务或者分类任务全部都变成文本任务,统一了生成的范式;
三是,编码器-解码器模型,如 T5,它的输入和输出是分为比较明显的两块内容,或者是问答式,或者序列到序列的转换型的任务;
四是,通用语言模型,如 GLM,该模型结合了自回归和自编码两种形式的模型,举个例子,“123456”是一串输入的序列,现在把 “3”、“5”、“6” 挖空,让模型去学习,那么,挖空以后换成一个 “ mask token” 告诉模型这个地方遮掉了一些内容,现在需要去预测出来遮掉的内容。
与 BERT 不同的是,GLM 把自回归和自编码方式进行结合后,挖出来的内容直接拼到了文本的后面,然后加上一个 “ start token”,告诉模型现在是开始生成了,开始做填空任务了,然后把标准答案 “5”、“6” 放在 “ star token”后面让它去预测,直到预测到 “end token”,它就知道这个填空已经结束了。这个过程称为自回归填空式的任务,整个计算流程还是自回归式,但它不断预测下一个词,既实现了填空的功能,又能看到上下文内容。此外,相比于 GPT 模型,GLM 采用了一个双向注意力的机制。
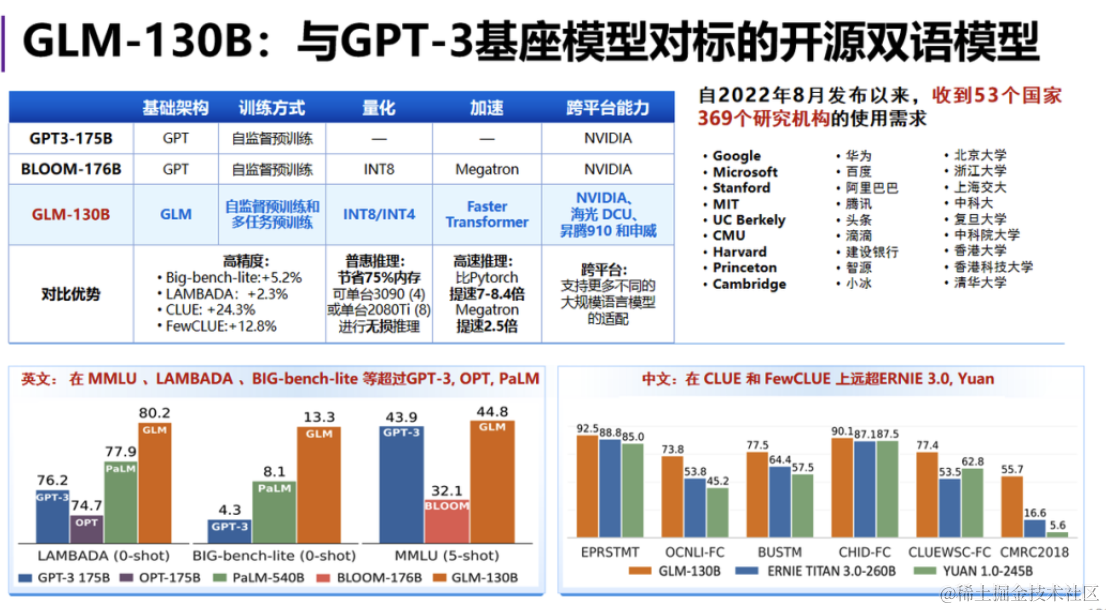
国产AI辅助编程工具CodeGeeX。
CodeGeeX 也是一个使用AI大模型为基座的辅助编程工具,帮助开发人员更快的编写代码。可以自动完成整个函数的编写,只需要根据注释或Tab按键即可。它已经在Java、JavaScript和Python等二十多种语言上进行了训练,并基于大量公开的开源代码、官方文档和公共论坛上的代码来优化自己的算法。CodeGeeX 作为一款中国原创的AI辅助编程工具,现在免费提供给所有开发者使用,同时完全开源,程序员使用普遍认为编写代码的效率提升2倍以上。
最近功能上新非常快,比如刚刚更新的“Ask CodeGeeX”功能,是将智能问答模式,融合到实际开发场景中,让开发者更专注和沉浸于编程,不用离开当前 IDE 的编程环境,就可以边写代码边和 AI 对话,实现针对编程问题的智能问答。无需waitlist,立刻就能尝鲜这个新功能!
那么就先给大家快速看看,在CodeGeeX上的体验是怎样的:
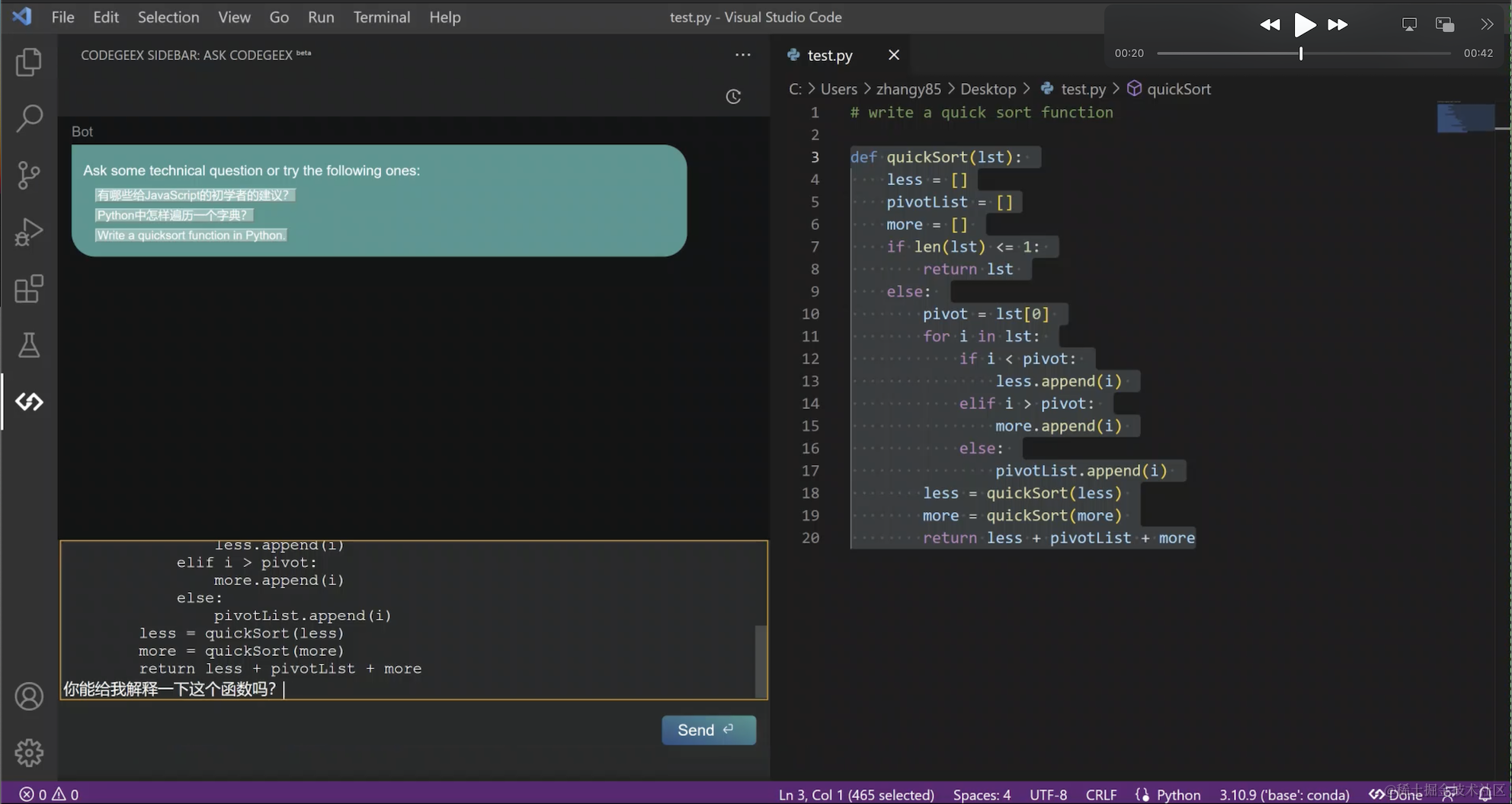
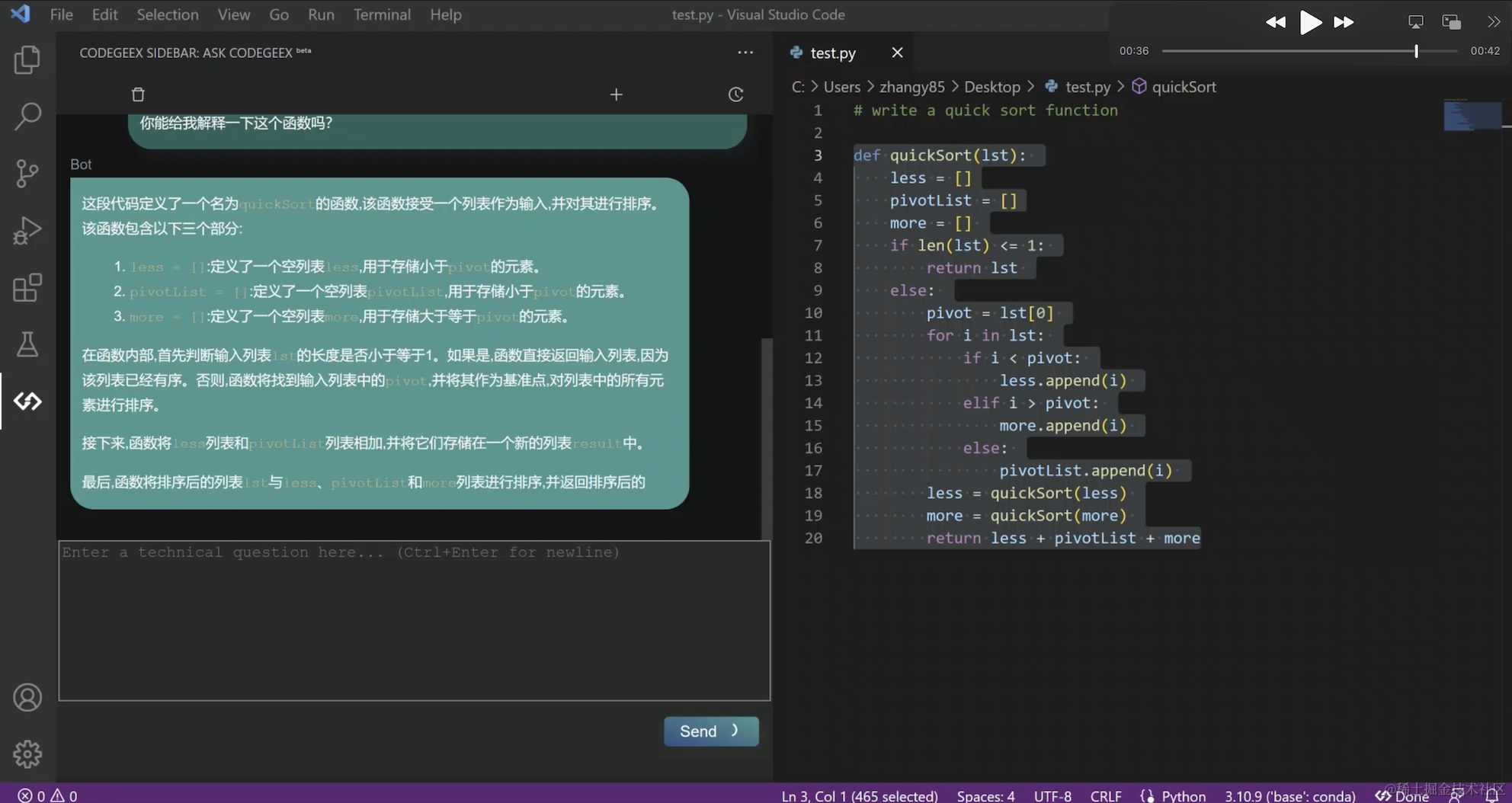
在大模型时代,编程推荐各位下载使用AI辅助编程工具 CodeGeeX。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mac电脑配置本地连接开发机器一键打包部署
- 【Linux学习】进程信号
- 你应该知道的锂电池起火应对常识,自动灭火贴有用吗?
- 【语音去噪】IIR(巴特沃斯、切比雪夫)滤波器语音去噪【含GUI Matlab源码 3716期】
- 如何公网远程访问Linux AMH服务器管理面板【内网穿透】
- 如何压缩照片大小?快速解决照片文件过大的问题!
- 探索数字隔离器π160M60 代替TLP2745 :主要特性与应用
- 基于SSM的医学生在线学习交流平台
- 发掘最佳 WebAPI 调试工具:大揭秘
- 缺失api-ms-win-crt-runtime-l1-1-0.dll要怎么解决