156 读写分离案例
1 读写分离案例
1.1 背景介绍
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
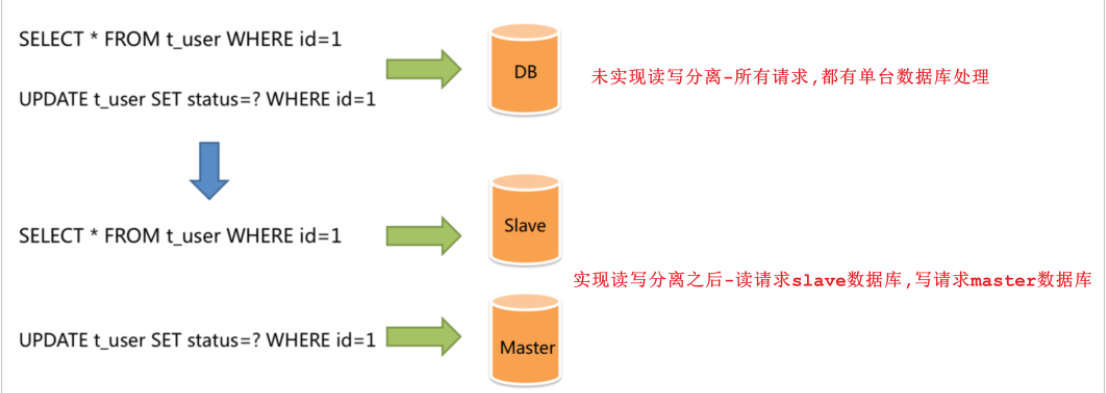
通过读写分离,就可以降低单台数据库的访问压力, 提高访问效率,也可以避免单机故障。
主从复制的结构,我们在第一节已经完成了,那么我们在项目中,如何通过java代码来完成读写分离呢,如何在执行select的时候查询从库,而在执行insert、update、delete的时候,操作主库呢?这个时候,我们就需要介绍一个新的技术 ShardingJDBC。
1.2 ShardingJDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
Sharding-JDBC具有以下几个特点:
1). 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2). 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3). 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
1.3 数据库环境
在主库中创建一个数据库rw, 并且创建一张表, 该数据库及表结构创建完毕后会自动同步至从数据库,SQL语句如下:
create database rw default charset utf8mb4;
use rw;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1.4 初始工准备
主要是演示一下读写分离操作,对于基本的增删改查的业务操作,就不再去编写了,,在demo工程中,我们已经完成了user的增删改查操作,具体的工程结构如下:
1.5 读写分离配置
1). 在pom.xml中增加shardingJdbc的maven坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2). 在application.yml中增加数据源的配置
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.200:3306/rw?characterEncoding=utf-8
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.201:3306/rw?characterEncoding=utf-8
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
配置解析:

3). 在application.yml中增加配置
spring:
main:
allow-bean-definition-overriding: true
该配置项的目的,就是如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的。
如果不配置该项,项目启动之后将会报错:
报错信息表明,在声明 org.apache.shardingsphere.shardingjdbc.spring.boot 包下的SpringBootConfiguration中的dataSource这个bean时出错, 原因是有一个同名的 dataSource 的bean在com.alibaba.druid.spring.boot.autoconfigure包下的DruidDataSourceAutoConfigure类加载时已经声明了。
而我们需要用到的是 shardingjdbc包下的dataSource,所以我们需要配置上述属性,让后加载的覆盖先加载的。
1.6 测试
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。配置完毕之后,我们就可以重启服务,通过postman来访问controller的方法,来完成用户信息的增删改查,我们可以通过debug及日志的方式来查看每一次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库。
控制台输出日志,可以看到操作master主库:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STM32 freertos 使用软件模拟串口uart
- 如何给新华网投稿发稿?新华网的媒体发稿方法步骤
- Docker 常用命令
- echarts地图marker自定义图标并添加点击事件
- java架构师岗面试题——基础篇
- 2024如果创业适合干什么,普通人如何创业
- pyspark笔记:over
- 数组基础及相关例题
- 固定效应模型-以stata为工具
- 【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现