Pytest接口自动化测试框架搭建的全过程
一. 背景
Pytest目前已经成为Python系自动化测试必学必备的一个框架,网上也有很多的文章讲述相关的知识。最近自己也抽时间梳理了一份pytest接口自动化测试框架,因此准备写文章记录一下,做到尽量简单通俗易懂,当然前提是基本的python基础已经掌握了。如果能够对新学习这个框架的同学起到一些帮助,那就更好了~
二. 基础环境
语言:python 3.8
编译器:pycharm
基础:具备python编程基础
框架:pytest+requests+allure
三. 项目结构
项目结构图如下:
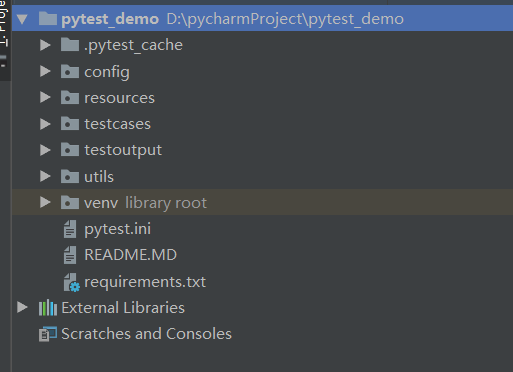
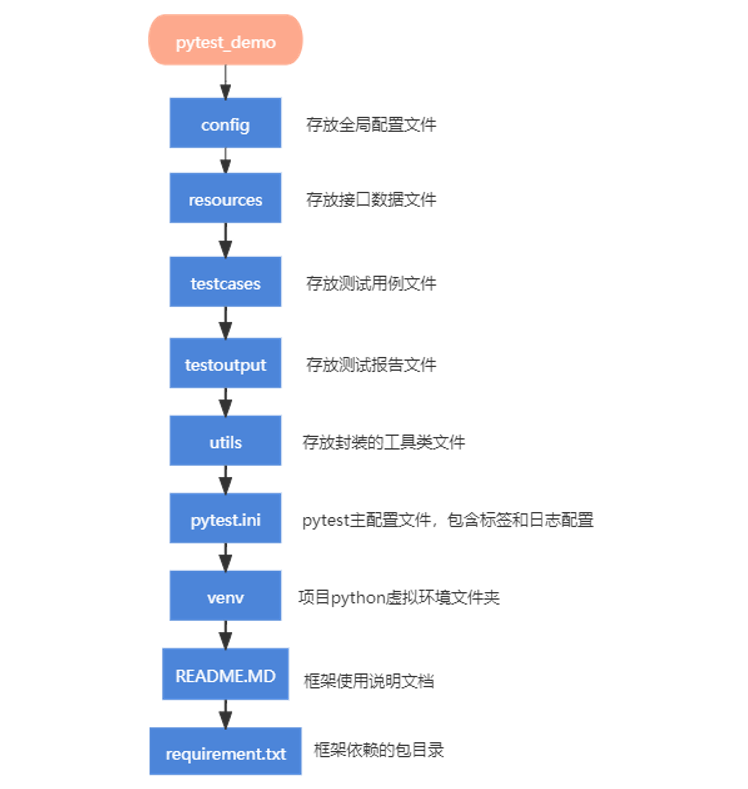
每一层具体的含义如下图:
测试报告如下图:

四、框架解析
4.1 接口数据文件处理

框架中使用草料二维码的get和post接口用于demo测试,比如:
get接口:https://cli.im/qrcode/getDefaultComponentMsg
返回值:{“code”:1,“msg”:"",“data”:{xxxxx}}
数据文件这里选择使用Json格式,文件内容格式如下,test_http_get_data.json:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
表示dataitem下有两条case,每条case里面声明了id, name, header, url, method, expectdata。如果是post请求的话,case中会多一个parameters表示入参,如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
为了方便一套脚本用于不同的环境运行,不用换了环境后挨个儿去改数据文件,比如
测试环境URL为:https://testcli.im/qrcode/getDefaultComponentMsg
生产环境URL为:https://cli.im/qrcode/getDefaultComponentMsg
因此数据文件中url只填写后半段,不填域名。然后config》global_config.py下设置全局变量来定义域名:
| 1 2 3 |
|
utils文件夹下,创建工具类文件:read_jsonfile_utils.py, 用于读取json文件内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
运行结果如下:

4.2 封装测试工具类
utils文件夹下,除了上面提到的读取Json文件工具类:read_jsonfile_utils.py,还有封装request 请求的工具类:http_utils.py
从Excel文件中读取数据的工具类:get_excel_data_utils.py(虽然本次框架中暂时未采用存放接口数据到Excel中,但也写了个工具类,需要的时候可以用)
http_utils.py内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
get_excel_data_utils.py内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
4.3 测试用例代码编写
testcases文件夹下编写测试用例:
test_caoliao_http_get_interface.py内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
test_caoliao_http_post_interface.py内容:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
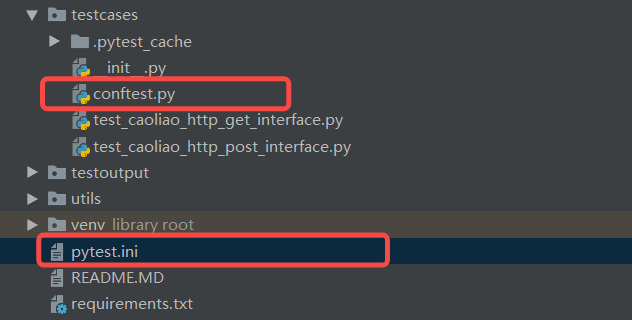
企业中的系统接口,通常都有认证,需要先登录获取token,后续接口调用时都需要认证token。因此框架需要能处理在运行用例前置和后置做一些动作,所以这里用到了conftest.py文件,内容如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|
由于用例中用到了@pytest.mark.httptest给用例打标,因此需要创建pytest.ini文件,并在里面添加markers = httptest,不然会有warning,说这个Mark有问题。并且用例中用到的日志打印logging模板也需要在pytest.ini文件中增加日志配置。pytest.ini文件内容如下:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
4.4 测试用例运行生成报告
运行方式:
Terminal窗口,进入到testcases目录下,执行命令:
运行某一条case:pytest test_caoliao_http_post_interface.py
运行所有case: pytest
运行指定标签的case:pytest -m httptest
运行并打印过程中的详细信息:pytest -s test_caoliao_http_post_interface.py
运行并生成pytest-html报告:pytest test_caoliao_http_post_interface.py --html=../testoutput/report.html
运行并生成allure测试报告:
1. 先清除掉testoutput/result文件夹下的所有文件
2. 运行case,生成allure文件:pytest --alluredir ../testoutput/result
3. 根据文件生成allure报告:allure generate ../testoutput/result/ -o ../testoutput/report/ --clean
4. 如果不是在pycharm中打开,而是直接到report目录下打开index.html文件打开的报告无法展示数据,需要双击generateAllureReport.bat生成allure报告;
pytest-html报告:

generateAllureReport.bat文件位置:
文件内容:
| 1 |
|
Allure报告:

框架中用到的一些细节知识点和问题,如:
conftest.py和@pytest.fixture()结合使用
pytest中使用logging打印日志
python中获取文件相对路径的方式
python虚拟环境
pytest框架下Allure的使用
我会在后续写文章再介绍。另外框架同样适用于dubbo接口的自动化测试,只需要添加python调用dubbo的工具类即可,后续也会写文章专门介绍。
?现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!?希望能帮助到你!【100%无套路免费领取】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java 新闻发布系统 新闻管理系统 在线新闻系统 jsp ssm
- 概述:利用大模型 (LLMs) 解决信息抽取任务
- 【面试】基础知识点回顾
- 如何优化测试用例设计,节约时间?
- windows任意APP注册成服务(以nginx服务为例)
- 如何实现远程公共网络下访问Windows Node.js服务端
- 华为OD机试 - 书籍叠放 - 逻辑分析(Java 2023 B卷 200分)
- 【CAN】在linux中读取监听控制器局域网CAN数据帧操作 (二) 之 C++代码实现
- 面试题:40亿个QQ号,限制1G内存,如何去重?
- Linux搭建和使用redis