Flink系列之:Checkpoints 与 Savepoints
一、概述
从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。
Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 Checkpoint 的生命周期 由 Flink 管理, 即 Flink 创建,管理和删除 checkpoint - 无需用户交互。 由于 checkpoint 被经常触发,且被用于作业恢复,所以 Checkpoint 的实现有两个设计目标:i)轻量级创建和 ii)尽可能快地恢复。 可能会利用某些特定的属性来达到这个目标,例如, 作业的代码在执行尝试时不会改变。
在用户终止作业后,会自动删除 Checkpoint(除非明确配置为保留的 Checkpoint)。
Checkpoint 以状态后端特定的(原生的)数据格式存储(有些状态后端可能是增量的)
尽管 savepoints 在内部使用与 checkpoints 相同的机制创建,但它们在概念上有所不同,并且生成和恢复的成本可能会更高一些。Savepoints的设计更侧重于可移植性和操作灵活性,尤其是在 job 变更方面。Savepoint 的用例是针对计划中的、手动的运维。例如,可能是更新你的 Flink 版本,更改你的作业图等等。
Savepoint 仅由用户创建、拥有和删除。这意味着 Flink 在作业终止后和恢复后都不会删除 savepoint。
Savepoint 以状态后端独立的(标准的)数据格式存储(注意:从 Flink 1.15 开始,savepoint 也可以以后端特定的原生格式存储,这种格式创建和恢复速度更快,但有一些限制)。
二、功能和限制
下表概述了各种类型的 savepoint 和 checkpoint 的功能和限制。
? - Flink 完全支持这种类型的快照
x - Flink 不支持这种类型的快照
! - 虽然这些操作目前有效,但 Flink 并未正式保证对它们的支持,因此它们存在一定程度的风险
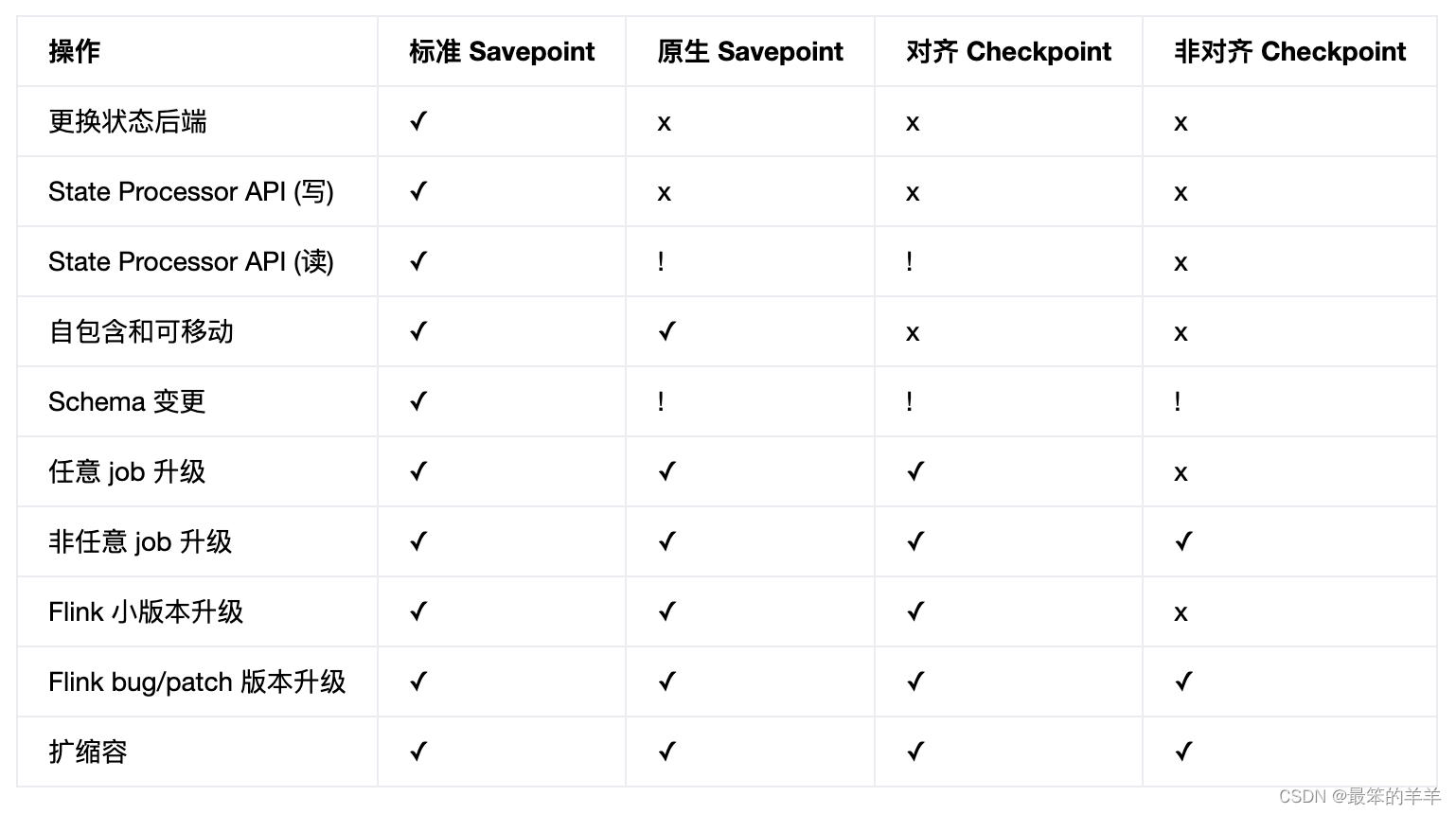
- 更换状态后端 - 配置与创建快照时使用的不同的状态后端。
- State Processor API (写) - 通过 State Processor API 创建这种类型的新快照的能力。
- State Processor API (读) - 通过 State Processor API 从该类型的现有快照中读取状态的能力。
- 自包含和可移动 - 快照目录包含从该快照恢复所需的所有内容,并且不依赖于其他快照,这意味着如果需要的话,它可以轻松移动到另一个地方。
- Schema 变更 - 如果使用支持 Schema 变更的序列化器(例如 POJO 和 Avro 类型),则可以更改状态数据类型。
- 任意 job 升级 - 即使现有算子的 partitioning 类型(rescale, rebalance, map, 等)或运行中数据类型已经更改,也可以从该快照恢复。
- 非任意 job 升级 - 如果作业图拓扑和运行中数据类型保持不变,则可以使用变更后的 operator 恢复快照。
- Flink 小版本升级 - 从更旧的 Flink 小版本创建的快照恢复(1.x → 1.y)。
- Flink bug/patch 版本升级 - 从更旧的 Flink 补丁版本创建的快照恢复(1.14.x → 1.14.y)。
- 扩缩容 - 使用与快照制作时不同的并发度从该快照恢复。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024第十一届亚洲(上海)国际工业锅炉与压力容器设备展览会
- 【OSG案例详细分析与讲解】之三:【3D场景优化与分页加载】
- Android开发之NDK入门
- C++类与对象基础(8)
- 最常用的且没有之一的 ls
- JSTL中c标签和fmt标签
- Python武器库开发-武器库篇之上传本地仓库到Git(三十八)
- 所有学前教育专业,一定要刷到这篇啊
- 在当前bash(sh)中执行脚本和注册函数
- day16 DOM(2)——获取设置表单的值