P71自监督式学习
发布时间:2023年12月20日
命名都以芝麻街的角色命名
- x 分为x’ 和 x’’ ,自己跟自己学
- bert 架构跟 transformer Encoder 一样,输入一排向量,输出一排向量,一般用在自然语言处理上

模型大小:



- x 分为 x’ x’’ 自学习

- bert 可以做输入一排向量,输出一排向量,输入和输出一样长。 一般用在自然语言处理
- bert 架构与 transformer encoder 一样
- randomly masking some tokens ,随机盖住一些token
* 使用 特殊 token 覆盖
* 或者 随机数 覆盖
*
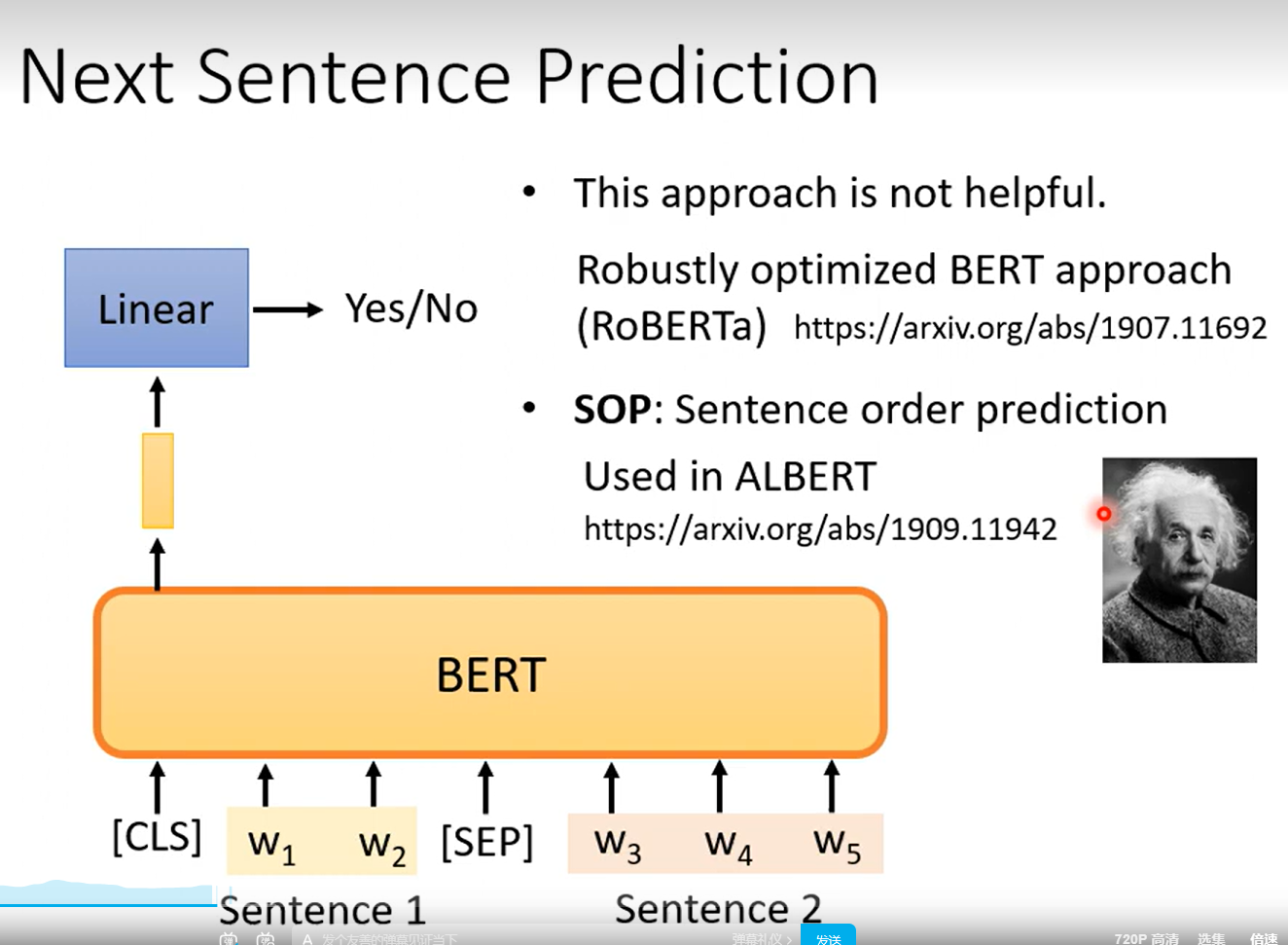
- 预测两个句子是不是连接的

bert 可用来完成各种各样的任务
bert 分化成各种各样的任务 (fine-tune)
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135090499
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- npm配置文件 .npmrc 加载优先级和使用示例
- 基于ASF-YOLO融合空间特征和尺度特征的新型注意力尺度序列融合模型开发构建涵洞隧道场景下墙壁建筑缺陷分割检测系统
- stl中set、map的用法
- 【无标题】
- Python 与 PySpark数据分析实战指南:解锁数据洞见
- 使用Python绘制二元函数图像详解
- 一篇文章了解Flutter Json系列化和反序列化
- laravel api资源的问题记录
- k8s的集群调度
- 数据库-MySQL 实战项目——车库停车收费管理系统数据库设计与实现(附源码)