ES索引原理
发布时间:2024年01月13日
ES在检索时底层使用的就是倒排索引,正向索引是通过key找value,反向索引则是通过value找key。
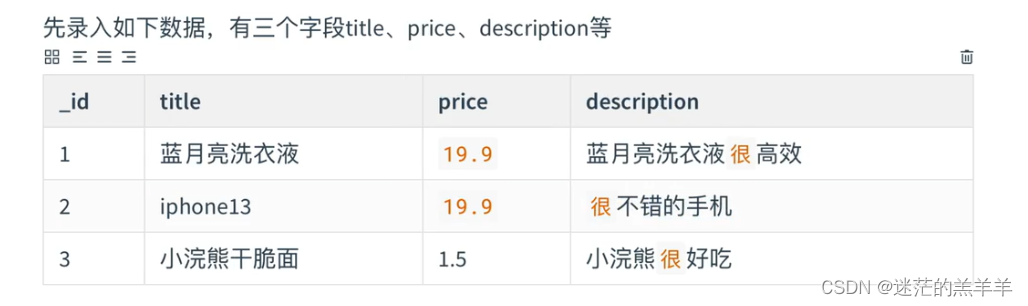
索引会分为两个区域:索引区和元数据区。数据是这样存储在里面的:
 ?
?
简单理解就是:当要录入一条数据时,首先会将完整的数据插入到元数据区中,就算没有指定id,底层也会自动生成uuid。然后将一个个的字段根据其类型放到索引区存储,如果是非text类型的,需要记录其值和对应这一条数据的id,如果为text类型的,则需要先进行分词,然后将每个词进行一个个存储,顺便记录词出现次数和数据的id,如果这个词已经在索引区存在了,直接将id加入到对应数据id的列表即可
查找的过程:根据字段的值先去索引区中根据值去找到对应的key(数据id),也就是倒排索引,拿到对应的数据id后,再去元数据区直接取整条数据记录,所以效率也就很高。
如下是更细节的存储:

?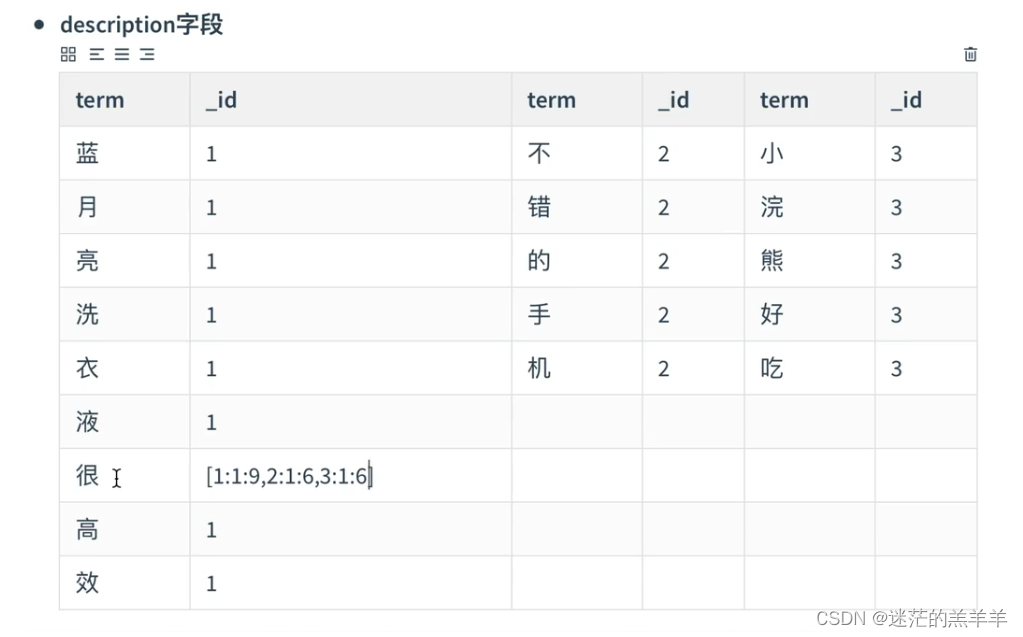
注意:ES分别为每个字段都建立了一个倒排索引。因此查询时查询字段的term,就能知道文档ID,就能快速找到文档。 ?
文章来源:https://blog.csdn.net/m0_62565675/article/details/135562789
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!