【保姆级教程】PAI x EasyPhoto,节日氛围AI写真生成
活动地址:hi 2024!AI新年写真大挑战
教程简述
生成式AI技术批量产出真/像/美的个人写真应用非常受欢迎。近期上线的EasyPhoto 作为一款开源的 SD WebUI 插件,提供更灵活、易用的开发方式,受到大量开发者们的关注和好评,用户可通过上传若干张同一人的照片,即可快速训练 LoRA 模型,并结合用户自定义的模板图片,最终生成真、像、美的写真照片。
EasyPhoto 是一个Webui UI插件,用于生成AI肖像画。基于StableDiffusion + 人物定制Lora + ControlNet 的方式实现,支持低代码操作、自定义风格,内置丰富模版,让更多开发者可以灵活地开发自己的风格化的艺术照生成。 本次AIGC创作活动基于阿里云人工智能平台PAI,低代码高效率启动EasyPhoto,实现节日氛围美图的快速生成。
基于本教程可以体验:
👍 新用户可免费领取价值万元的人工智能平台PAI?试用资源
👍 基于交互式建模PAI-DSW 训练个人专属的 LoRA 模型
👍 节日AI写真新创作,体验生成圣诞/新年等节日氛围感满满的个性化 AI 写真
👍 提交作品Redmi Watch3、小米手环8等赢取精美好礼!
答疑交流群
如需技术支持,请在钉钉搜索群号「 52485000325」,加入群聊。
使用PAI 快速启动 EasyPhoto
1. 准备工作
1.1 领取交互式建模PAI-DSW免费试用权益
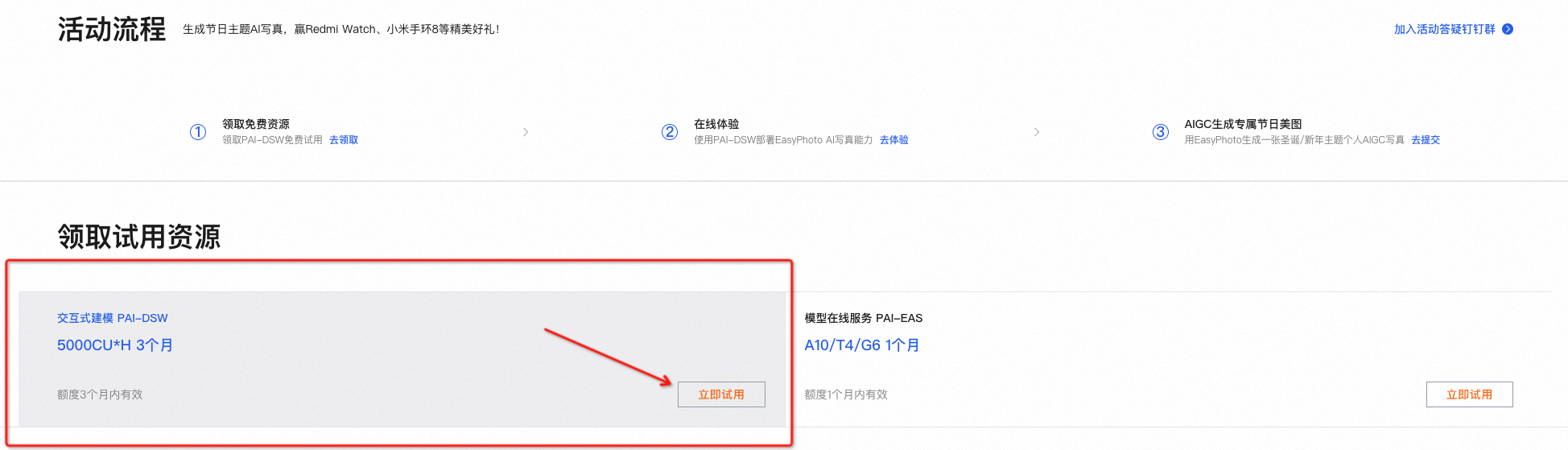
前往本次「hi 2024!AI新年写真大挑战」活动页面,领取交互式建模PAI-DSW产品免费试用资源包
-
- 对于交互式建模 PAI-DSW 的新用户,阿里云提供了5000CU*H 的免费试用资源,可以在活动页面中直接领取(试用规则请参照阿里云免费试用:https://free.aliyun.com/);或可以购买交互式建模 PAI-DSW 资源包参与活动,购买链接:PAI-DSW 100CU*H资源包,价格 59 元起;如不购买资源包,PAI-DSW 会按量进行计费,计费标准详见阿里云产品定价。
1.2 创建PAI-DSW实例
- 前往人工智能平台PAI控制台,链接:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
- 开通人工智能PAI并创建默认工作空间。请参见开通并创建默认工作空间。
- 在人工智能平台PAI控制台内,选择交互式建模PAI-DSW
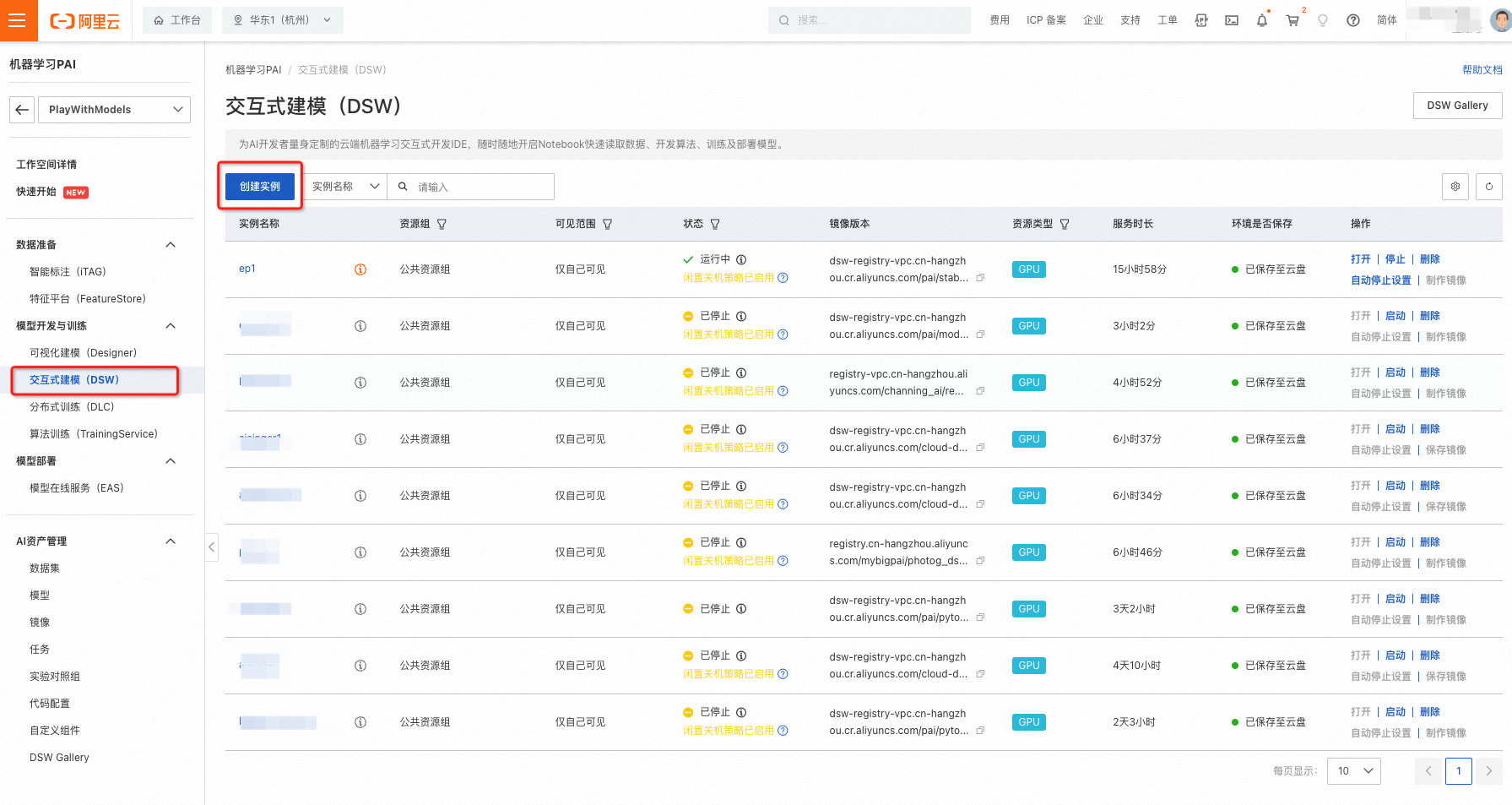
- 点击创建实例(如上图)
- 自定义输入实例名称,如“easyphoto”
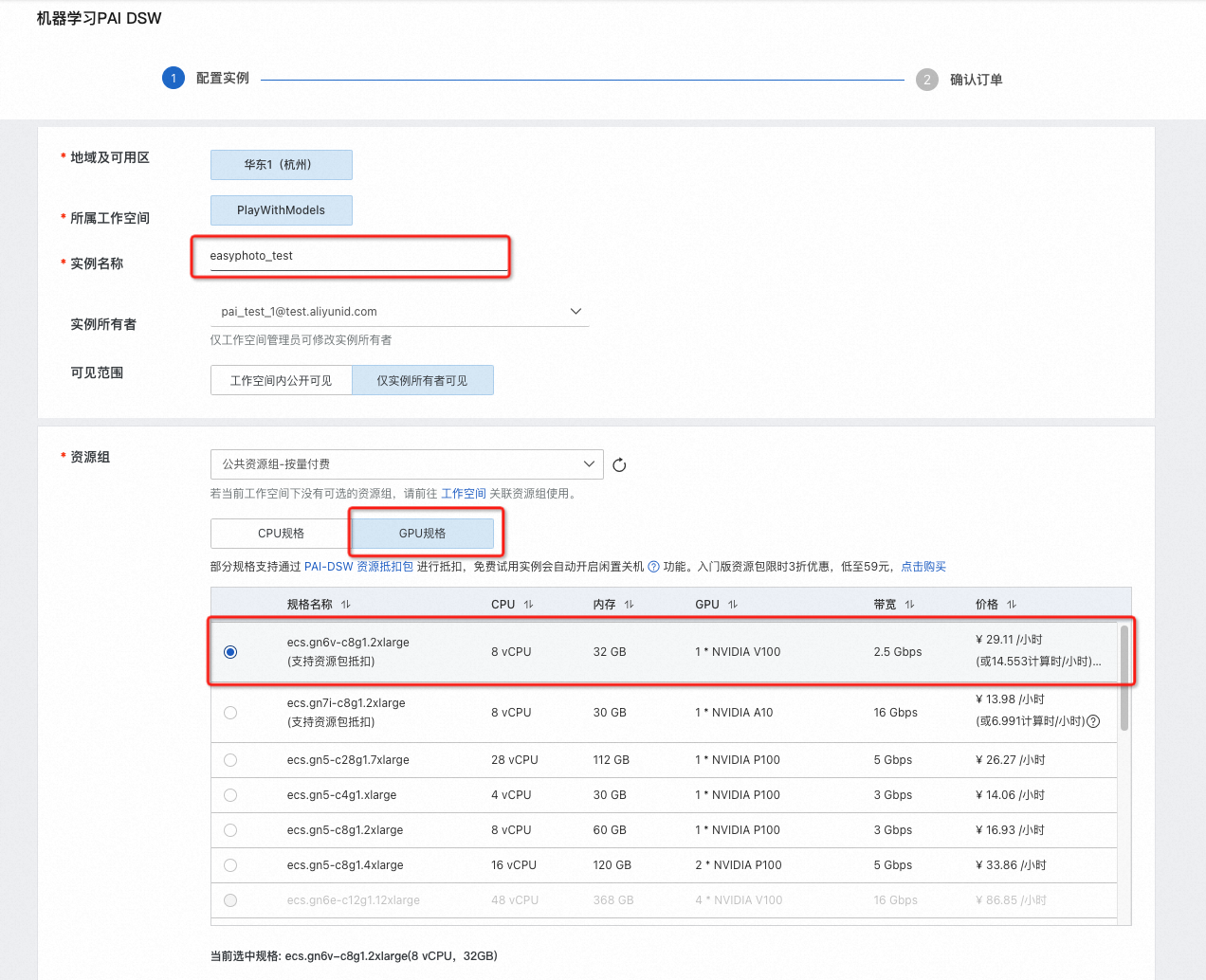
- 选择实例机型,GPU分类-ecs.gn6v-c8g1.2xlarge(支持资源包抵扣)或GPU分类-ecs.gn7i-c8g1.2xlarge
(支持资源包抵扣)。若这两个机型库存可更换地域尝试,或选择其他付费机型(不支持免费试用)。
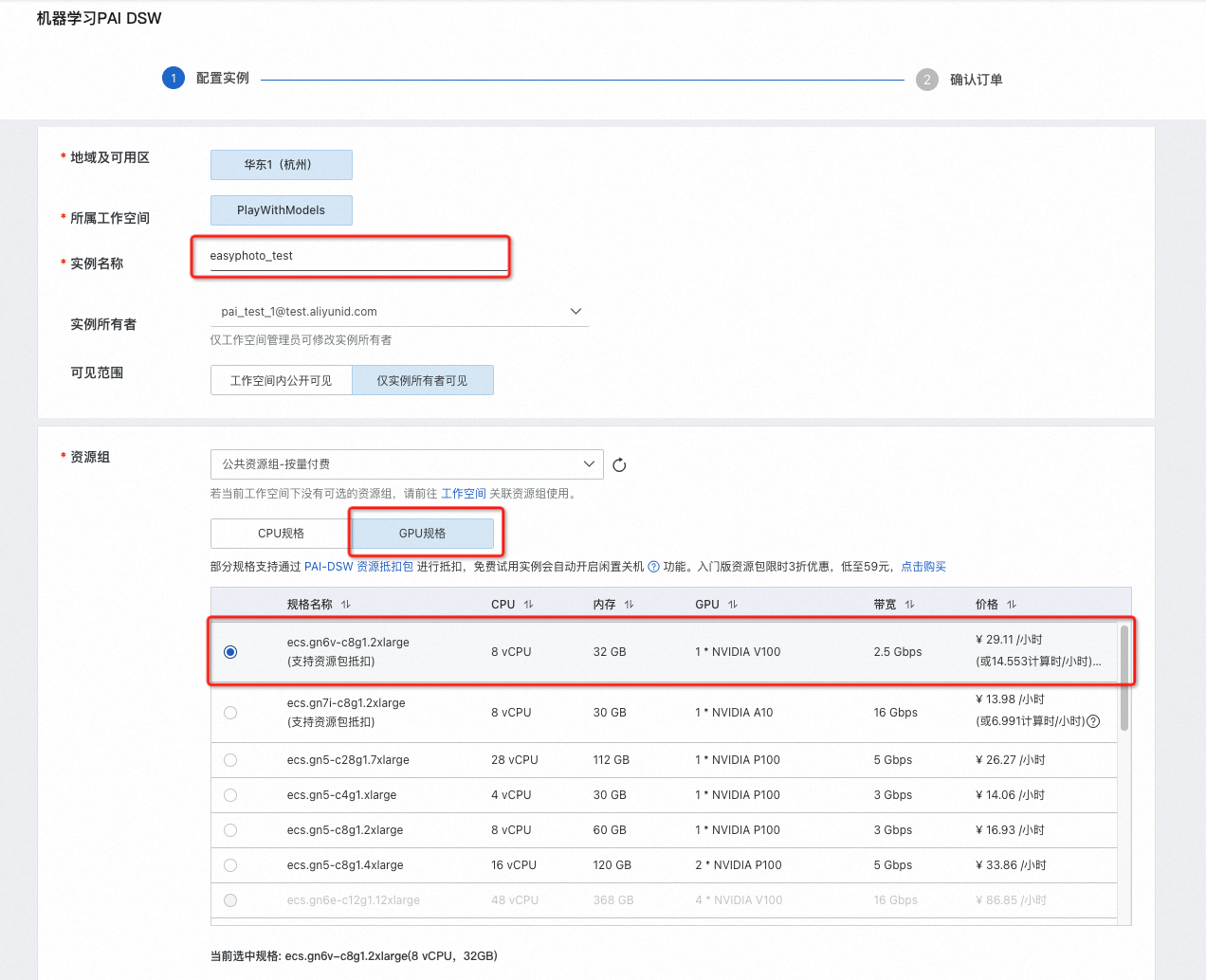
- 选择镜像,stable-diffusion-webui-develop:1.0.0-pytorch2.01-gpu-py310-cu117-ubuntu22.04
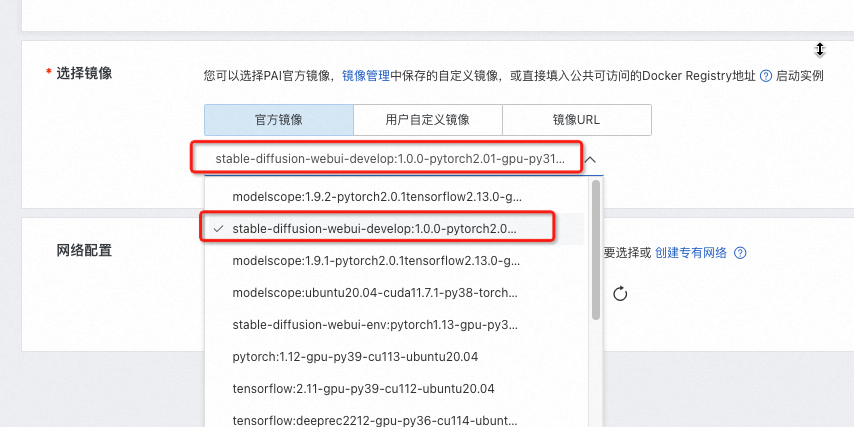
- 点击“下一步”
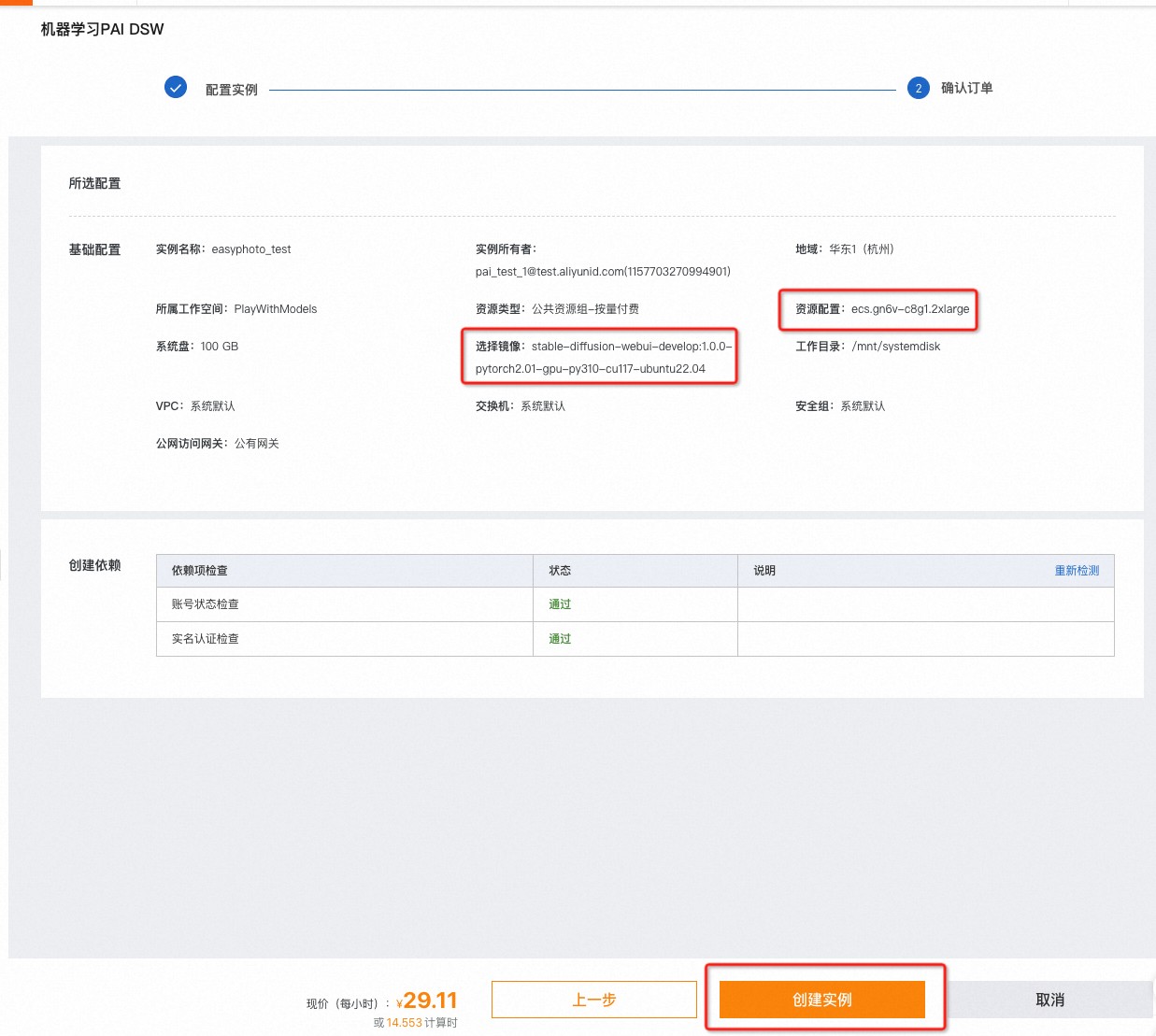
- 确认【资源配置】及【镜像】如图所示,点击创建实例;
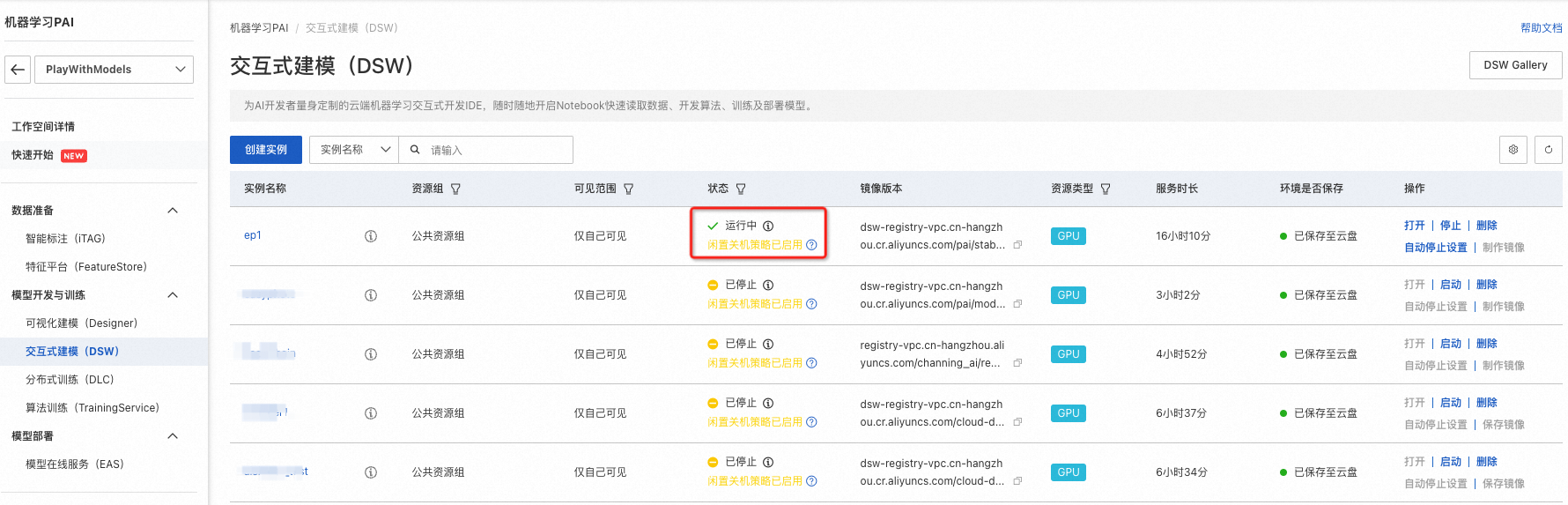
- 大约等到3-5分钟,实例状态变为「运行中」,实例创建完成;
1.4 在PAI-DSW中打开EasyPhoto教程,体验零代码完成AI开发
- 打开链接:基于EasyPhoto的AI新年-圣诞写真大挑战 (WebUI版),点击右上角「在阿里云DSW打开」
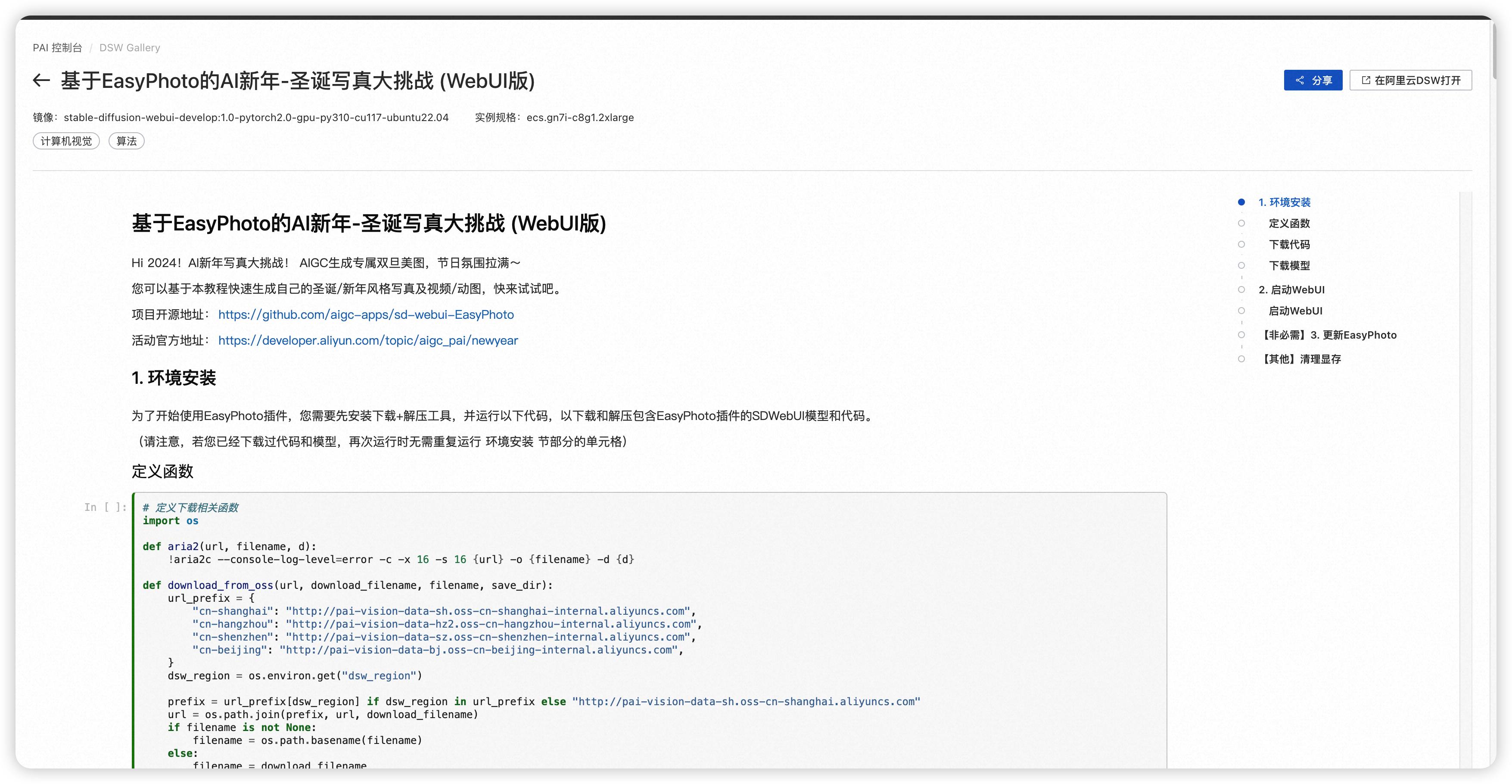
- 选择先前创建好的实例,点击实例名称
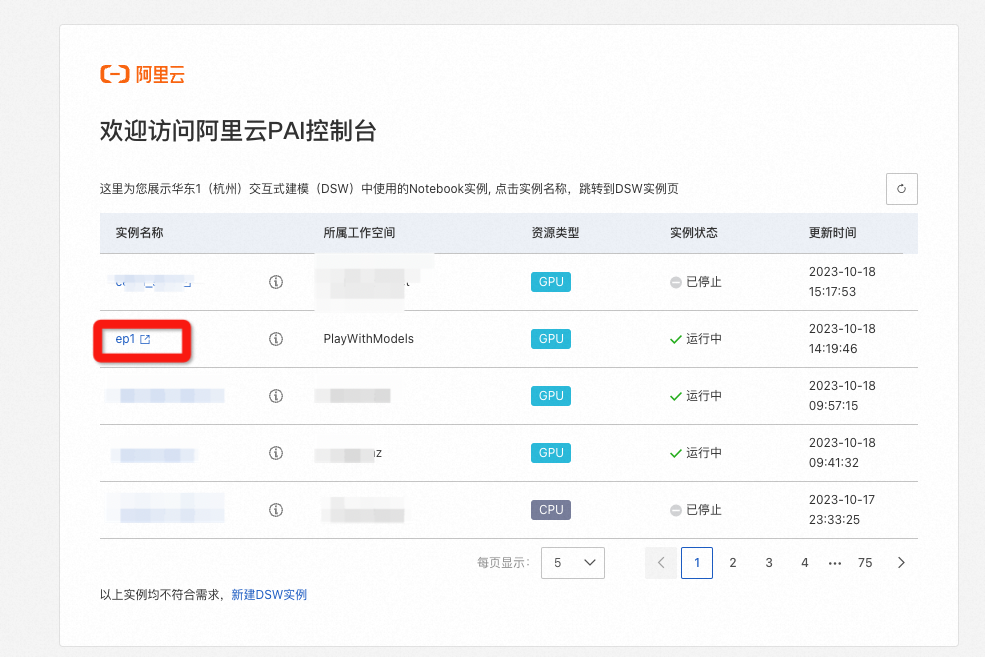
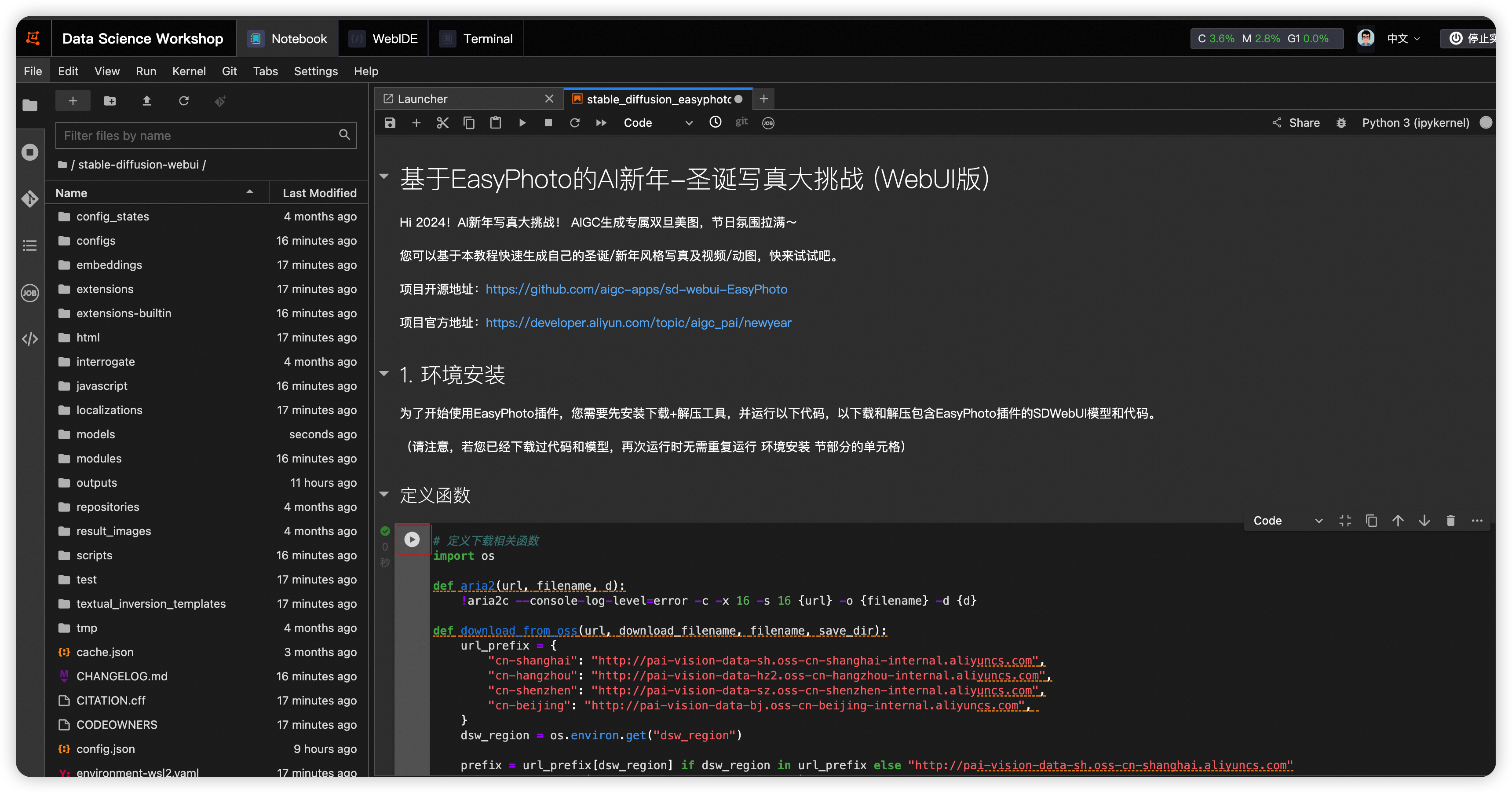
- 进入notebook开发界面,逐步点击运行按钮;依次运行 1.环境安装 节的单元格(3个 定义函数-下载代码-下载模型),可下载并安装预置的带有EasyPhoto插件的WebUI,即所依赖的模型。
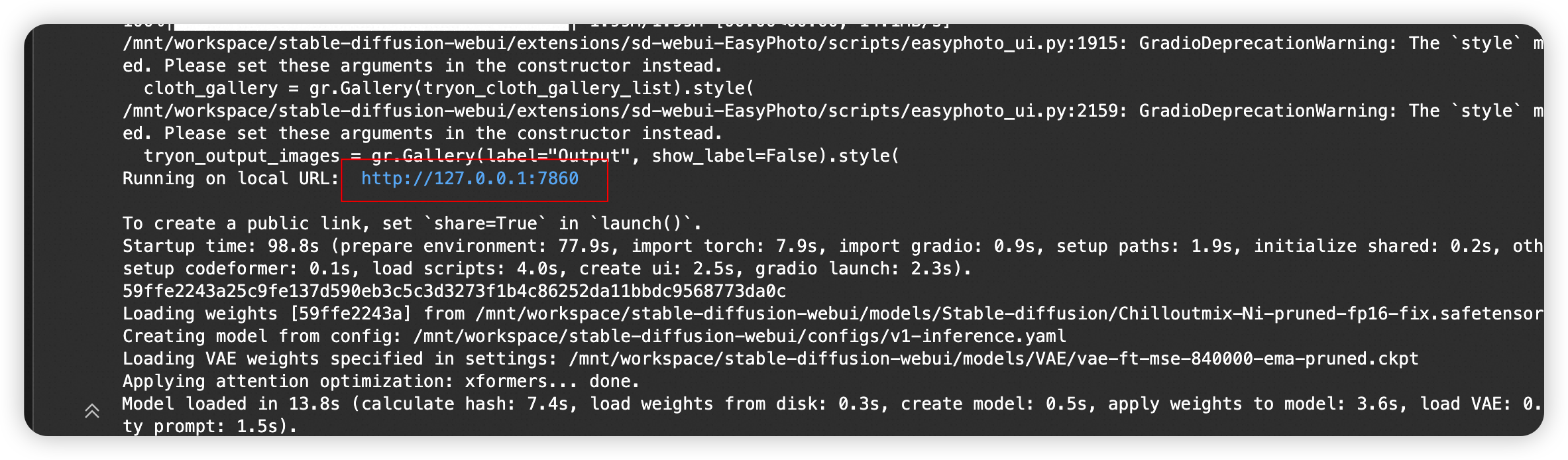
- 运行 2.启动WebUI 节的单元格,可打开WebUI。
- 单击生成的链接进入WebUI
- 打开WebUI,进入体验环节,在WebUI里运行EasyPhoto;
2. 开始体验
您可以使用本教程生成自己的节日写真/动图,我们提供了如下的功能:
- 人物写真(Photo Inference)
-
- 指定图片的人物写真 (Photo2Photo)
- 指定文本的人物写真 (Text2Photo)
- 人物动图(Video Inference)
-
- 指定文本的人物动图 (Text2Video)
- 指定图片的人物动图 (Image2Video)
- 指定视频的人物动图 (Video2Video)
大体上,人物写真/动图的生成分为以下两个步骤:
- Step1: 训练属于人物的数字分身
- Step2: 基于数字分身进行图像/视频生成
生成图片请参考2.2板块,生成视频请参考2.3板块。
2.1 数字分身训练
- Step1: 点击EasyPhoto选项卡
- Step2: 点击Upload Photos 上传自己的训练图片 (5-20张清晰的人像,最好为半身/正面)
(若无10张个人清晰人像照片,可选择蒙娜丽莎照片作为测试,蒙娜丽莎照片下载链接:https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/mona.zip)
- Step3: 点击Start Training (在弹框中输入任意的user id (英文))
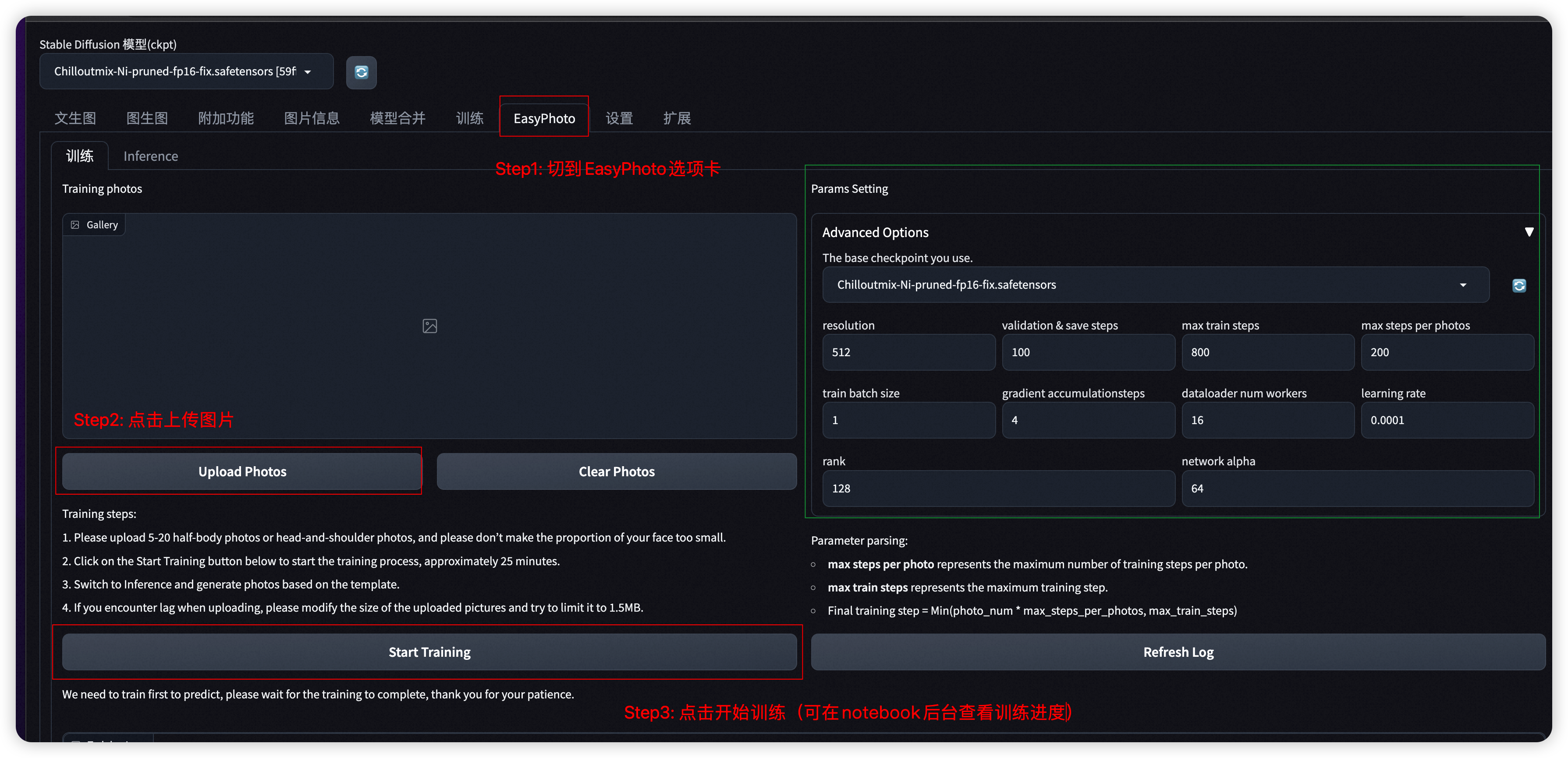
我们为您内置了写实/动漫风格的两种基模型供您选择,您也可以根据喜好选择自己的基模型。
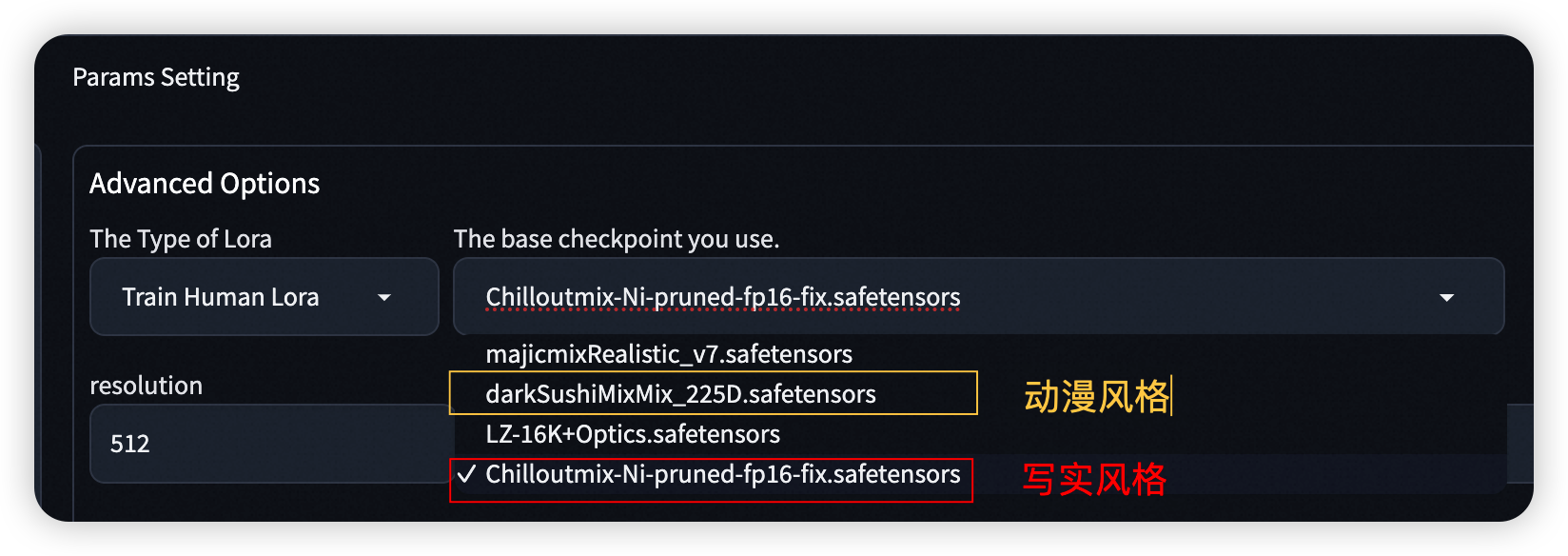
??请注意,如在训练过程中出现如图所示的前端断连,不用担心,您可在notebook后台看见训练进度。
待训练完成后刷新前端页面可以进行模型推理。
- 前端断连(连接超时 确保后台在训练即可):
- 训练完成提醒:
-
- SDWebUI 前端
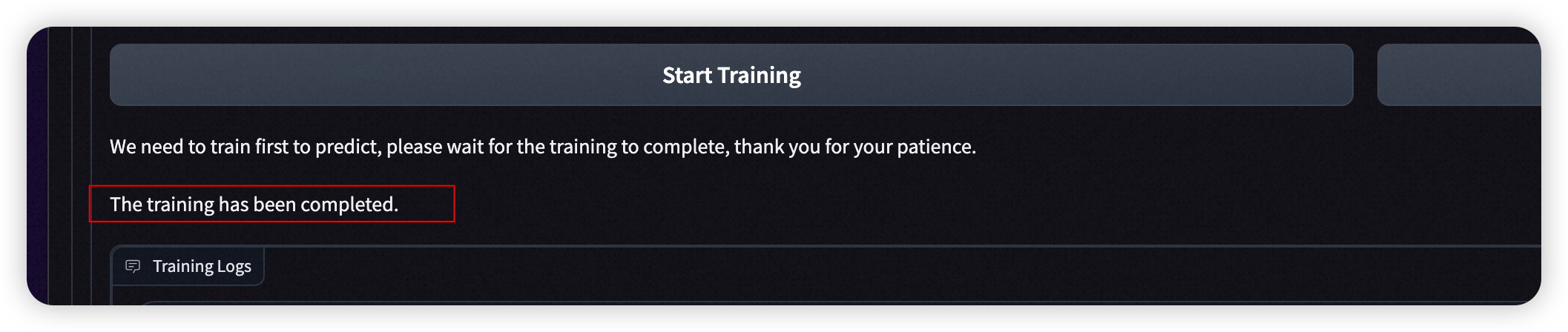
-
- notebook后端

2.2 图像推理 (Photo Inference)
您可使用Photo Inference 进行图像推理,我们支持:
- 指定图像的人物写真(Photo2Photo)
- 指定文本的人物写真(Text2Photo)
2.2.1 指定图像的人物写真
- Step 1: 切到Photo inference选项卡
- Step 2: 选择一种合适的图片上传方式
-
- 从模版中选择(Template Gallery),需在Gallery中选择一张图片
- 自行上传单张(Single Image Upload)
- 批量上传模版(Batch Image Upload)
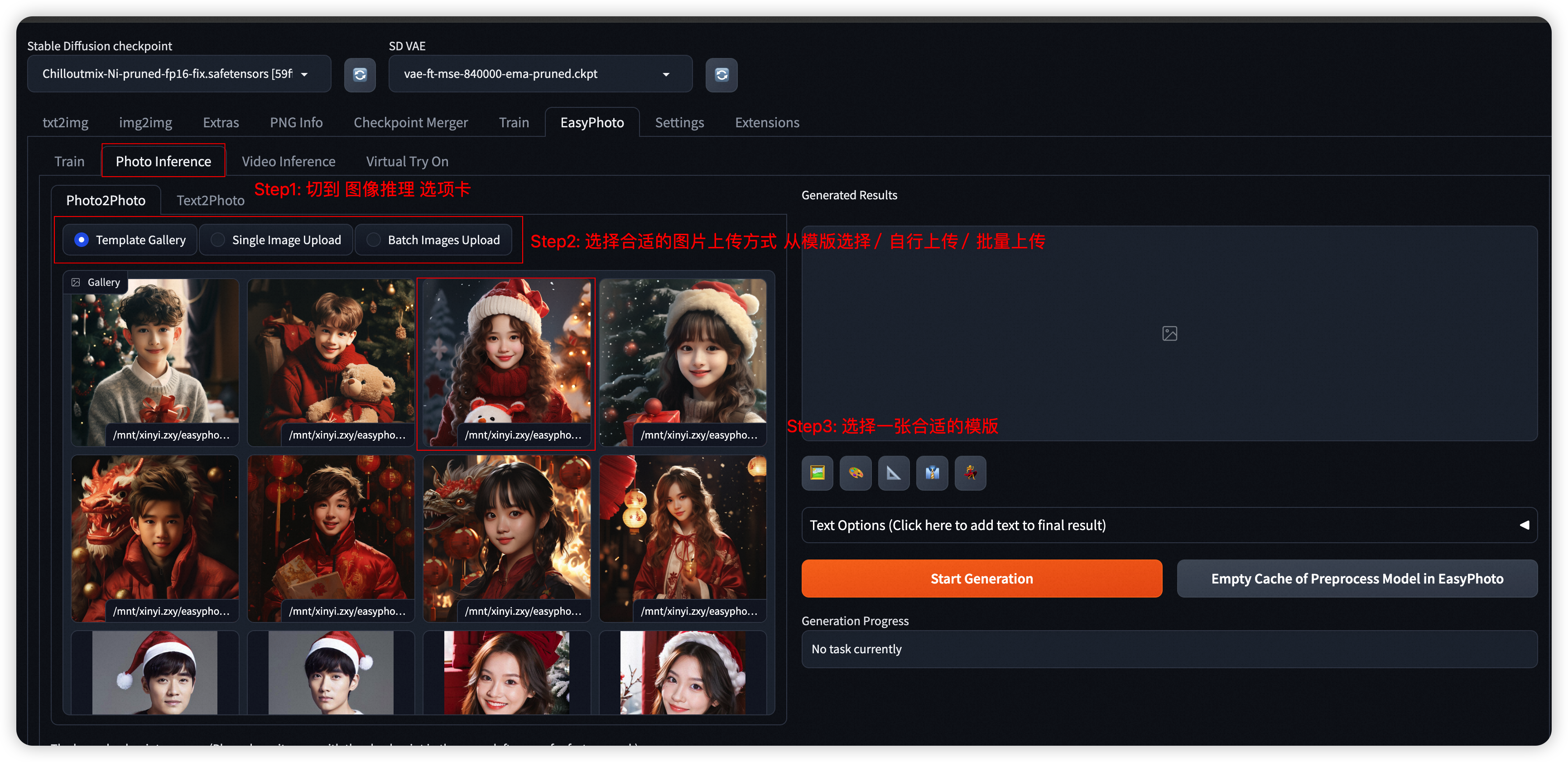
- Step 3: 选择基模型和UserId对应的LoRA模型 (可点击 刷新 图标 获得所有的UserID列表)
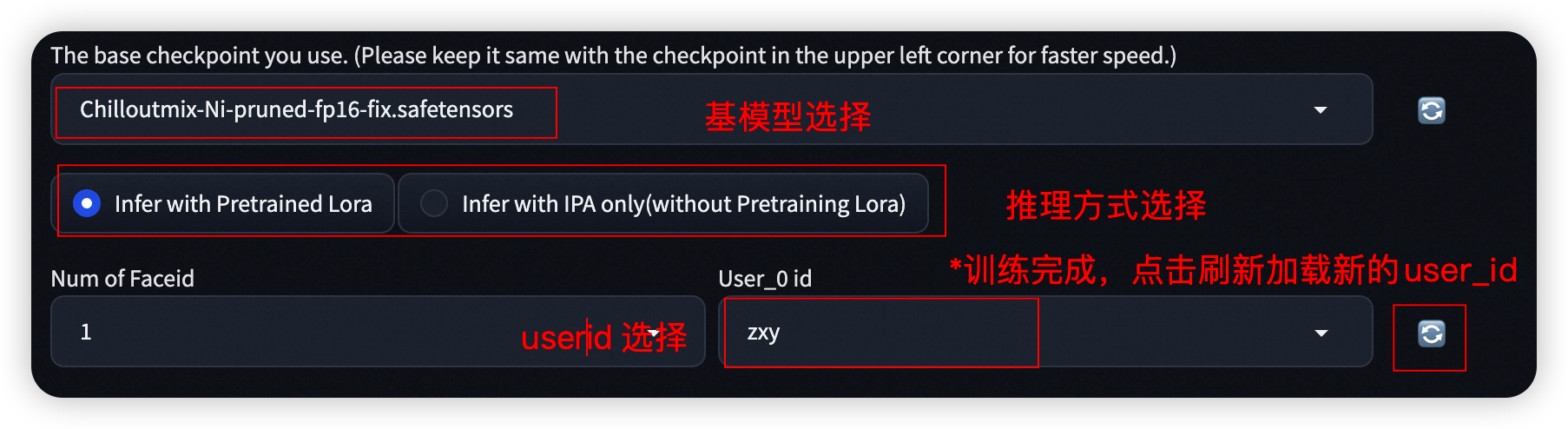
-
- 使用Infer With IPA时 无需训练自己的数字分身,直接在弹出的图片框中上传一张图进行生成。
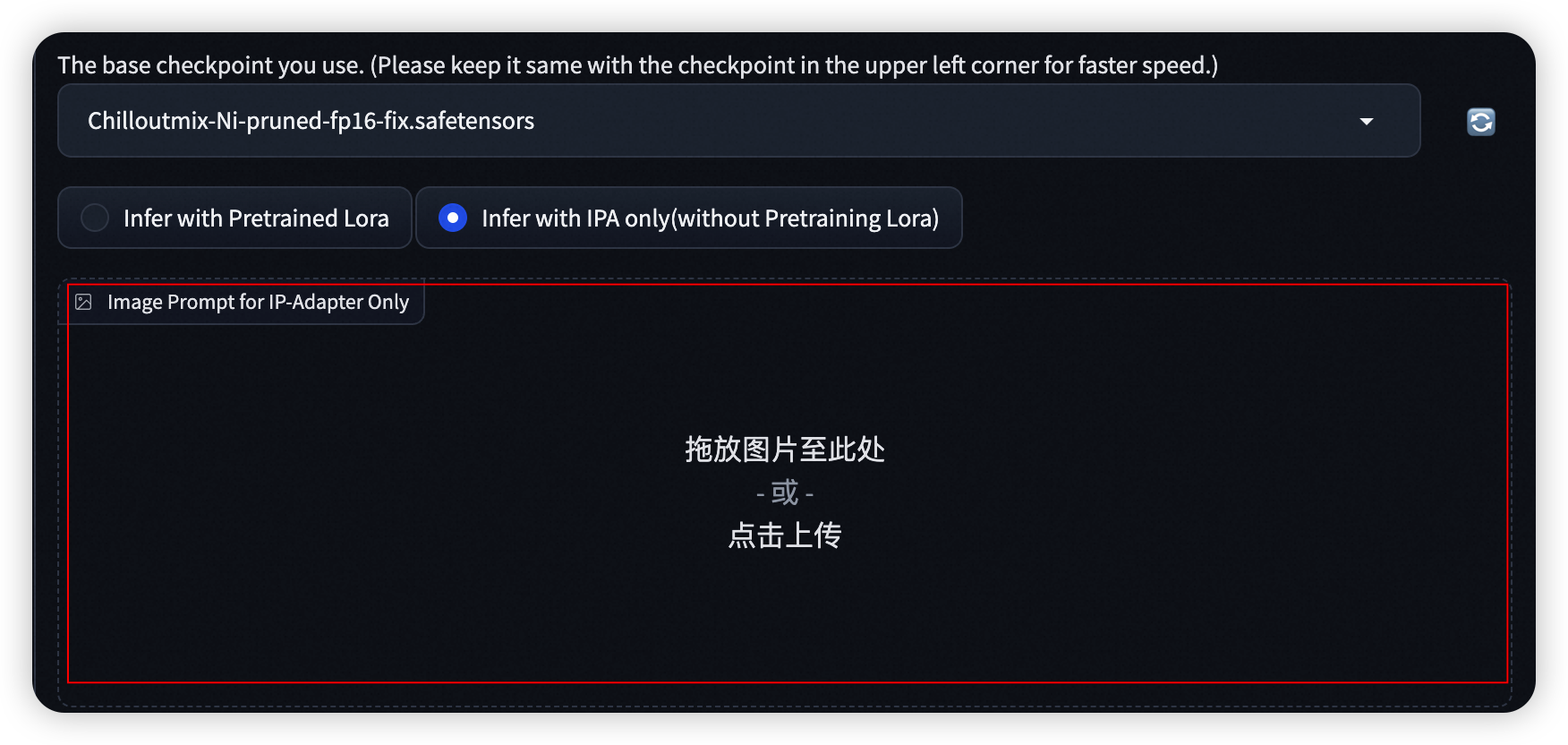
- Step 4: 可在Advanced Option选项卡中设置相关的参数
-
- 可打开background restore,并调整重绘幅度,对模版图片进行重绘来达到不同的生成效果。
- Step 5: 点击Start Generation 进行模型推理,生成专属于您的AI写真
-
- 稍等约1-2分钟后,图片生成完成,可下载存储图片;
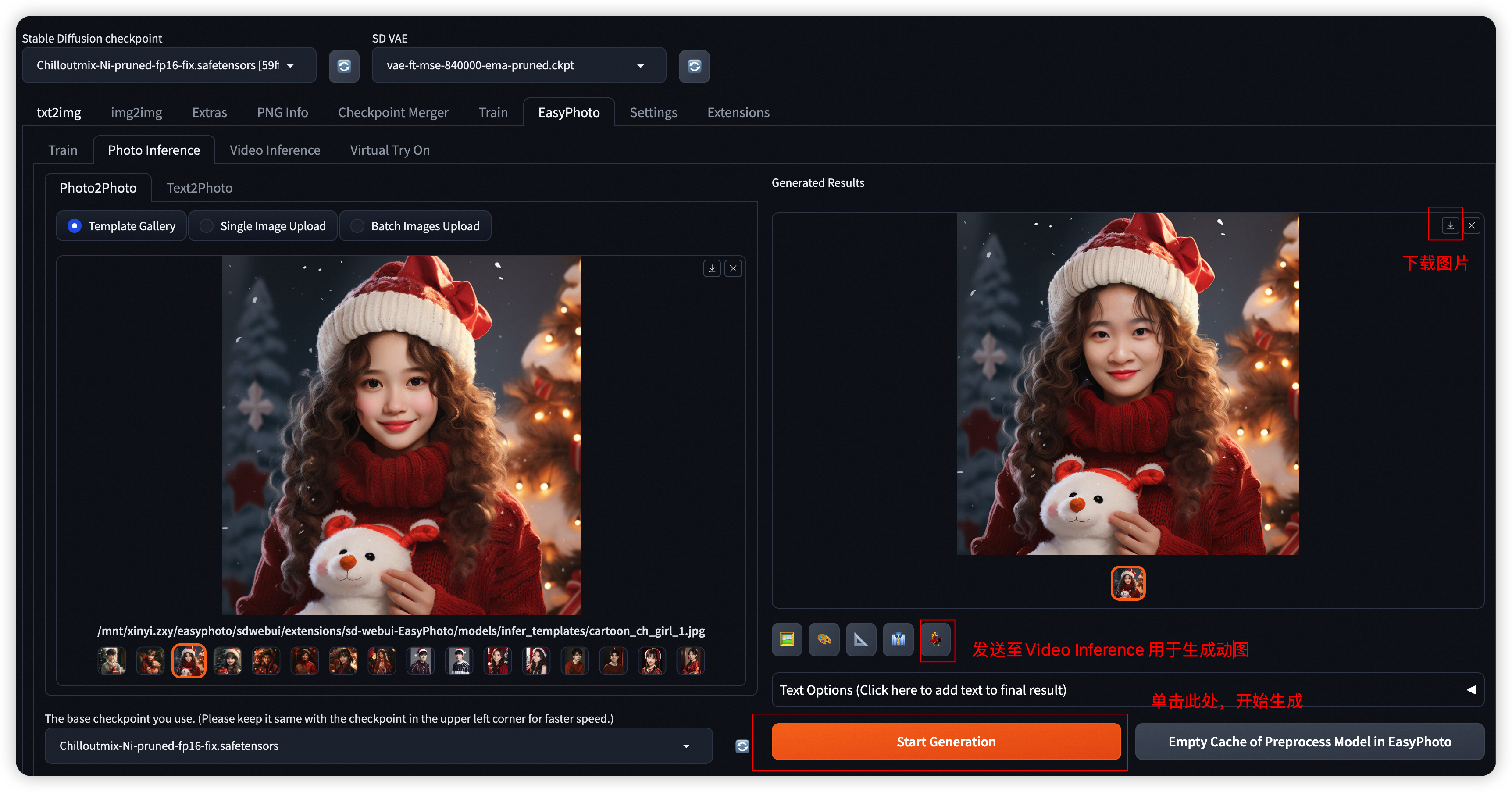
- Step6: 您可进一步选择生成图片,单击Text Options,选择一个合适的模版添加艺术字效果,生成的结果将出现在Results 的右侧。
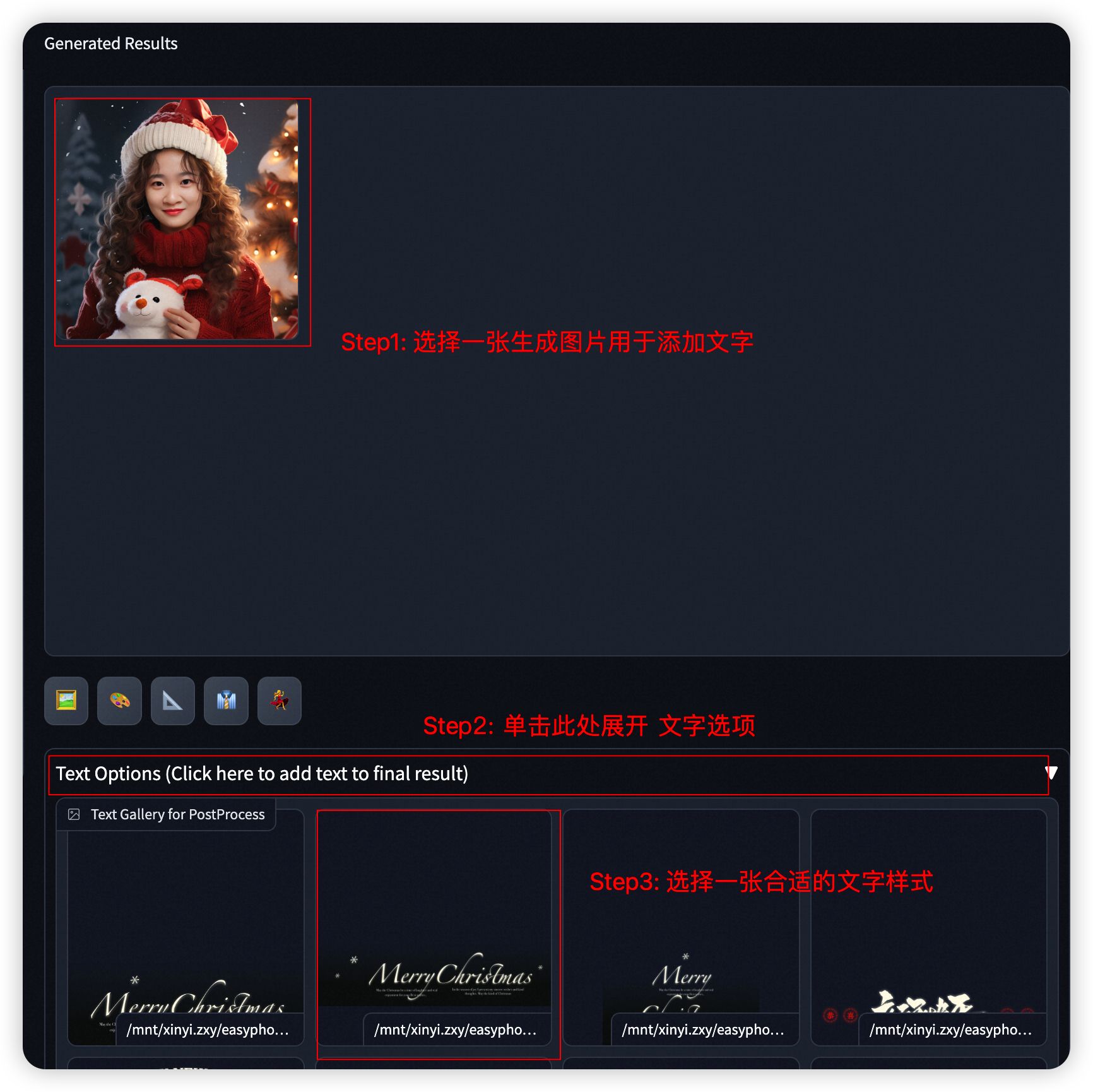
- 将图片提交至活动页,参与评奖活动;
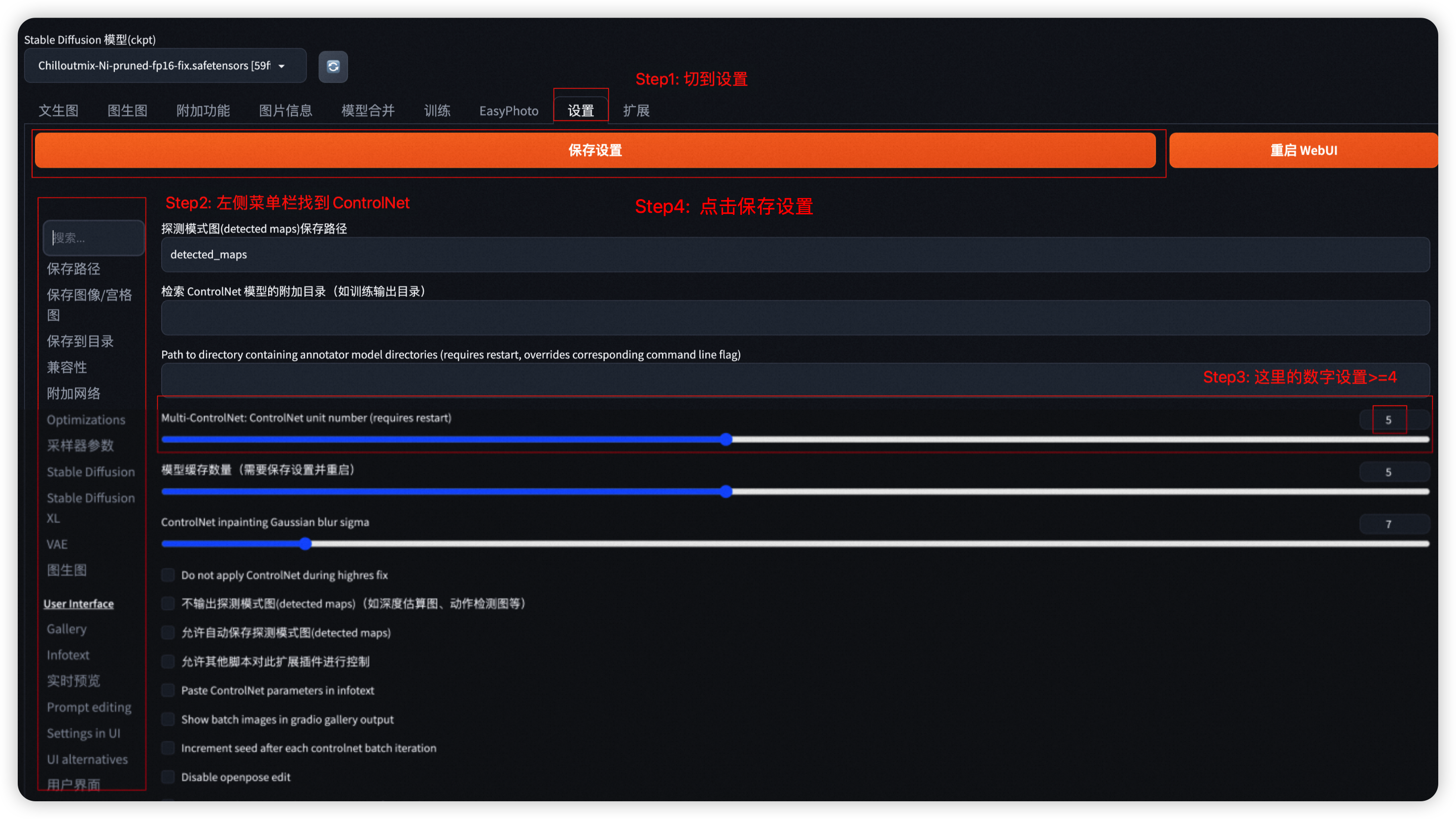
?? 若出现如下提示,请设置ControlNet 数目>=4。在控制台退出并重启WebUI进行设置。
- Step1: 选择 设置 菜单
- Step2: 在左侧菜单栏中找到ControlNet
- Step3: 将Multi-ControlNet数目设置>=4
- Step4: 点击保存设置
- Step5: 回到notebook页面,停止并重新启动SDWebUI

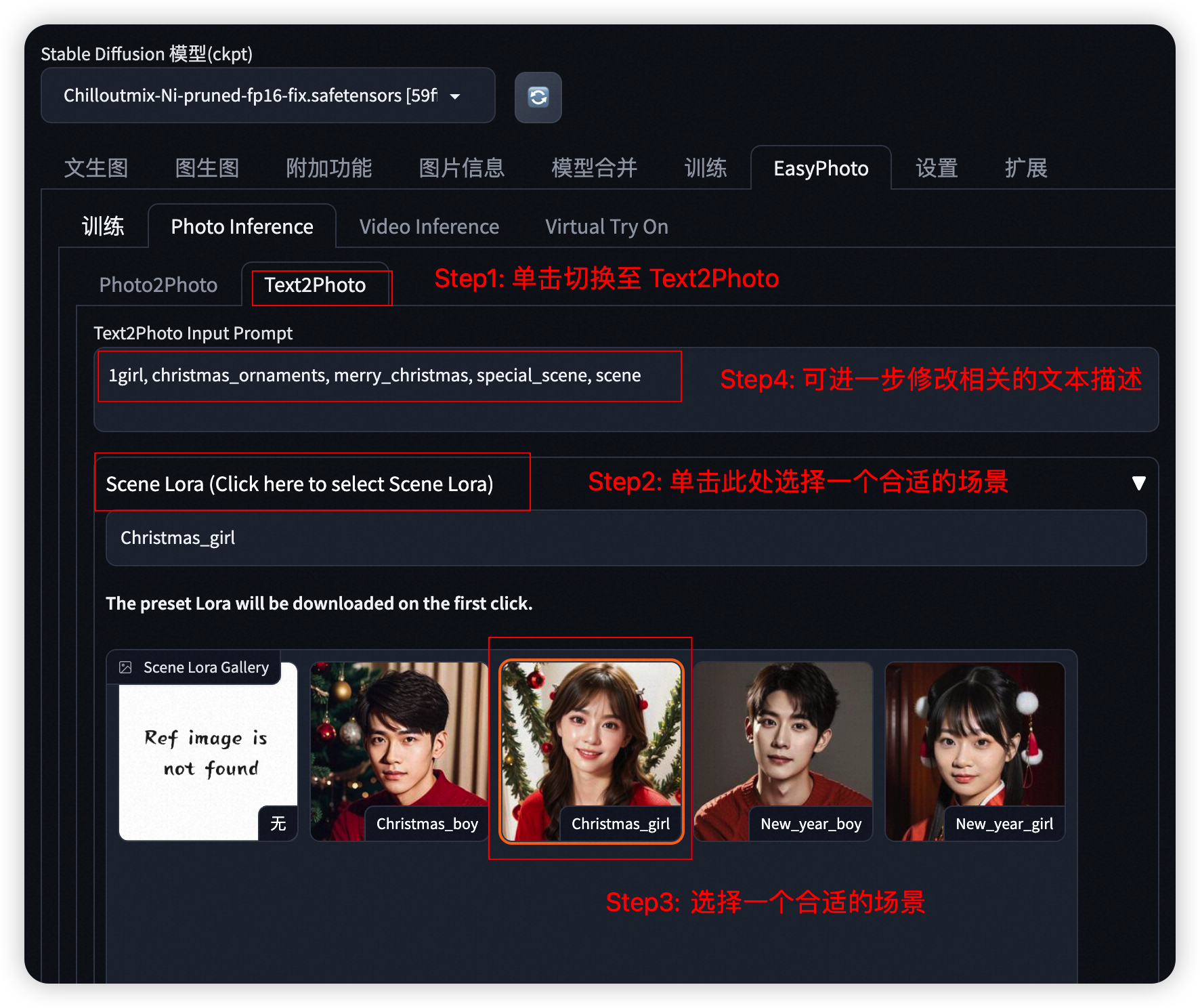
2.2.2 指定文本的人物写真
- Step 1: 切到Text2Photo选项卡
- Step 2: 选择一种合适的场景
- Step 3: 修改相关的文本描述
- Step4: 设置生成图像分辨率
- Step5: 进一步选择/上传 控制图像(姿态控制 OpenPose)
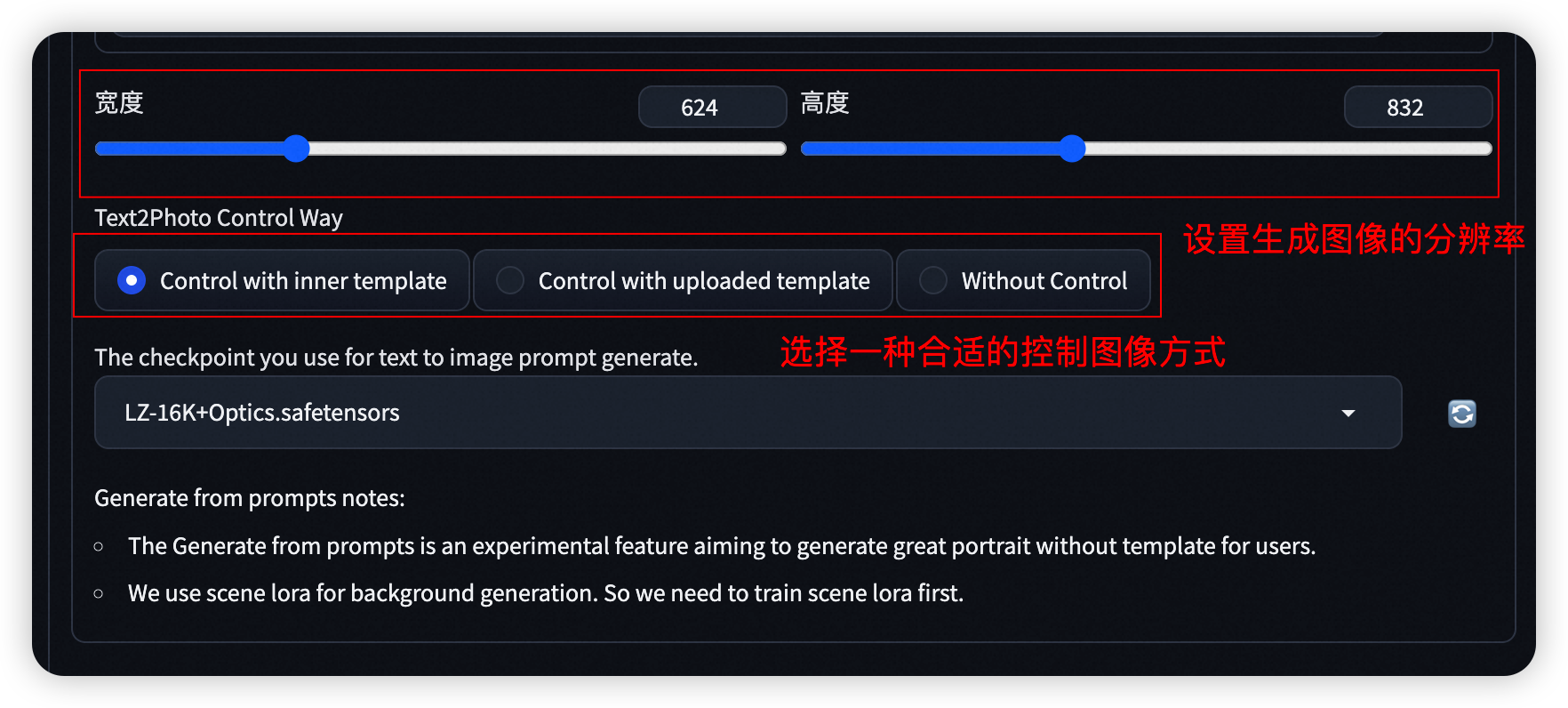
- Step6: 与图生图一致的设置 基模型/User_id 及其他参数,进行图像生成,并在生成完成后自行添加艺术字效果。
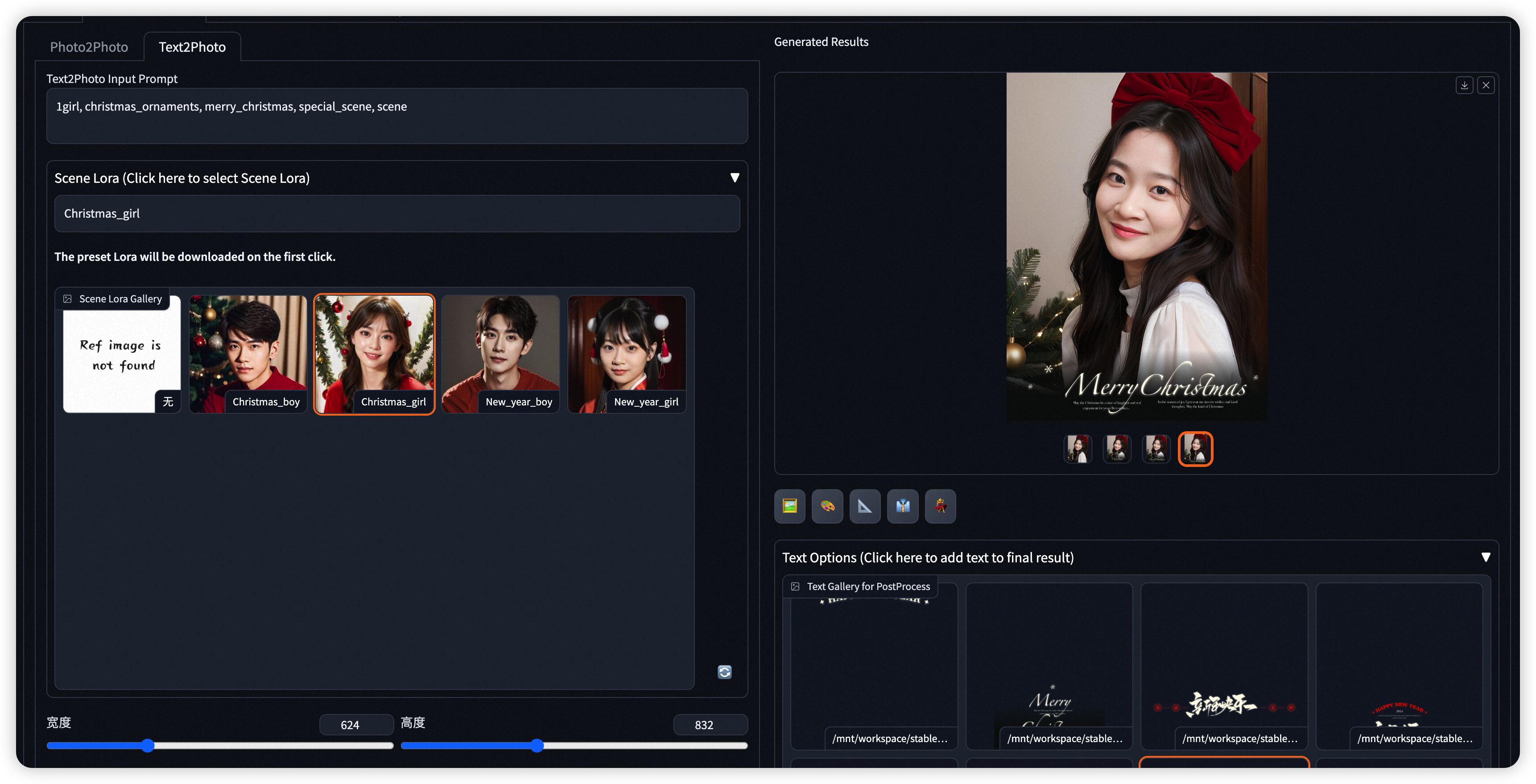
* 您可以参考这里的使用方式来进一步训练自己的节日场景,多样化的生成人像写真~
2.3 视频推理 (Video Inference)
您可使用Video Inference 进行视频推理,我们支持:
- 指定文本的人物动图(Text2Video)
- 指定图像的人物动图(Image2Video)
- 指定视频的人物动图(Video2Video)
2.3.1 指定文本的人物动图
- Step 1: 切到Video inference选项卡
- Step 2: 选择一个合适的场景,并修改相应的prompy(与 指定文本的人物写真 操作相同)
- Step 3: 设置图像大小,或上传一个用于控制的视频,并选择合适的控制方式。
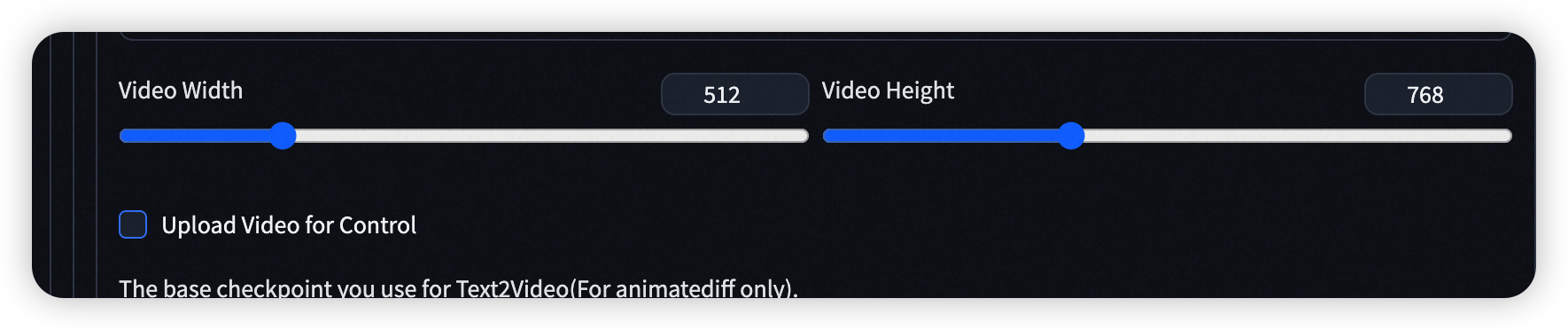
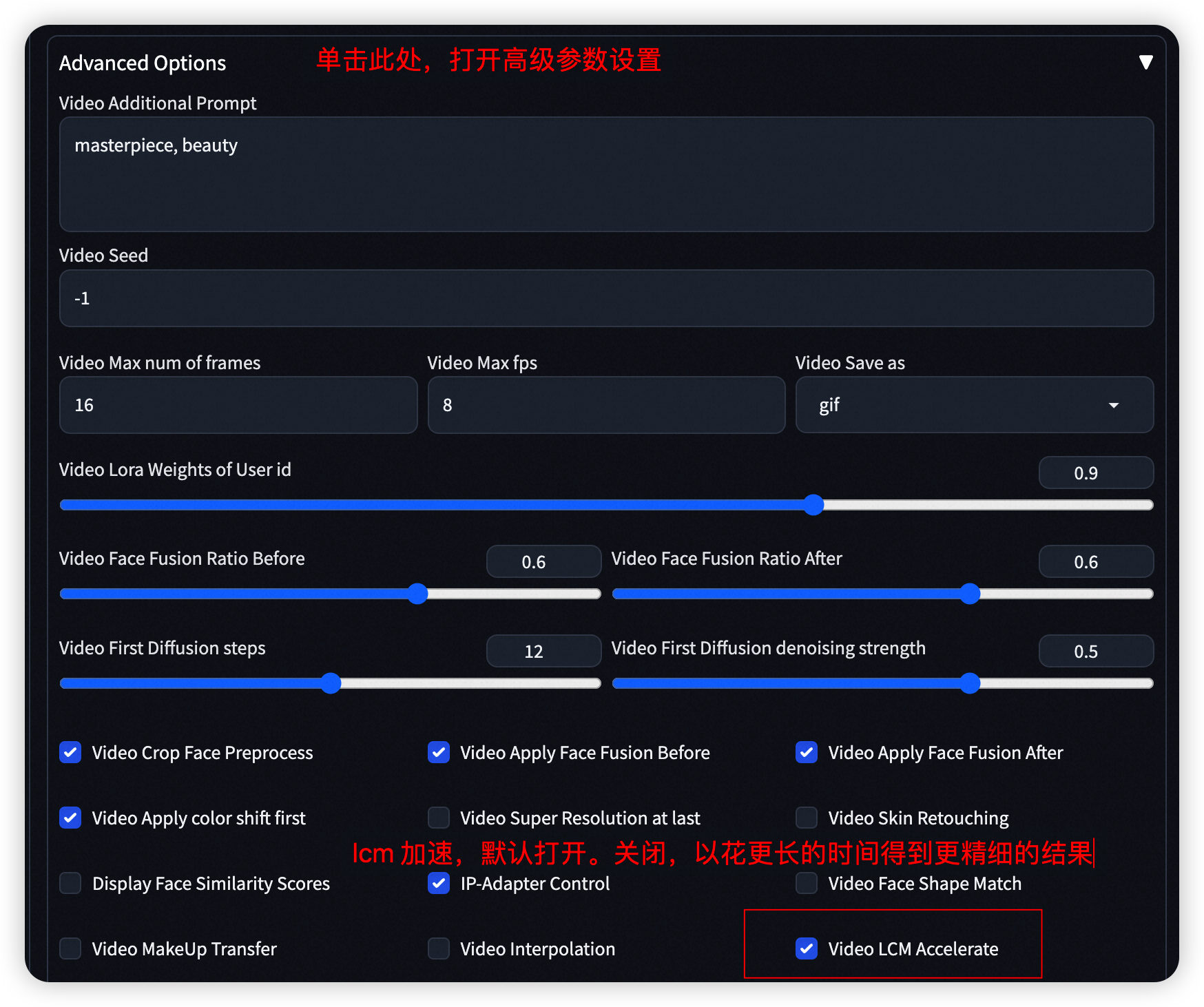
- Step 4: 设置基模型、user_id 以及相关的参数。
?? 我们默认打开了lcm 用于视频生成的加速,您可关闭该选项用更多的生成步数来生成更细节的视频结果。
- Step 5: 点击 Start Generation 来生成视频
-
- 如前端错误,后台显示生成完成,您可单击 List Recent Conversion Results 来下载/查看 生成的历史视频。(无需刷新)
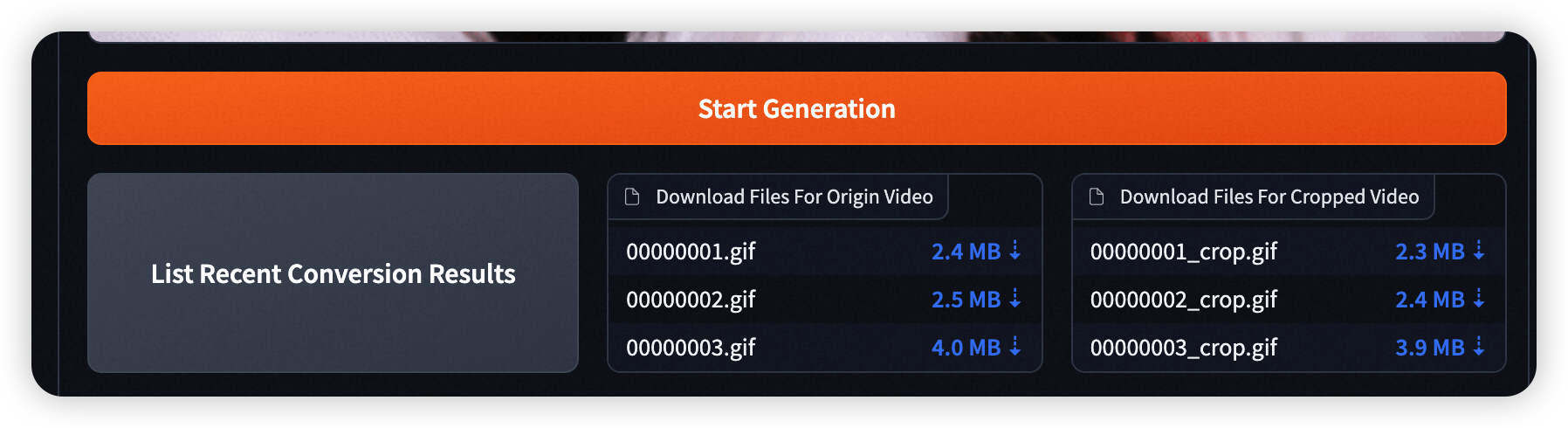
- Step 6: 点击 Text Option 来对生成视频添加艺术字效果。您可以选择某一帧,或将艺术字效果应用于整段视频。

2.3.2 指定图像的人物动图
- Step1: 上传一张 人物图 (可通过 💃 按钮 将生成的人物写真发送至此)/ 上传首、尾图
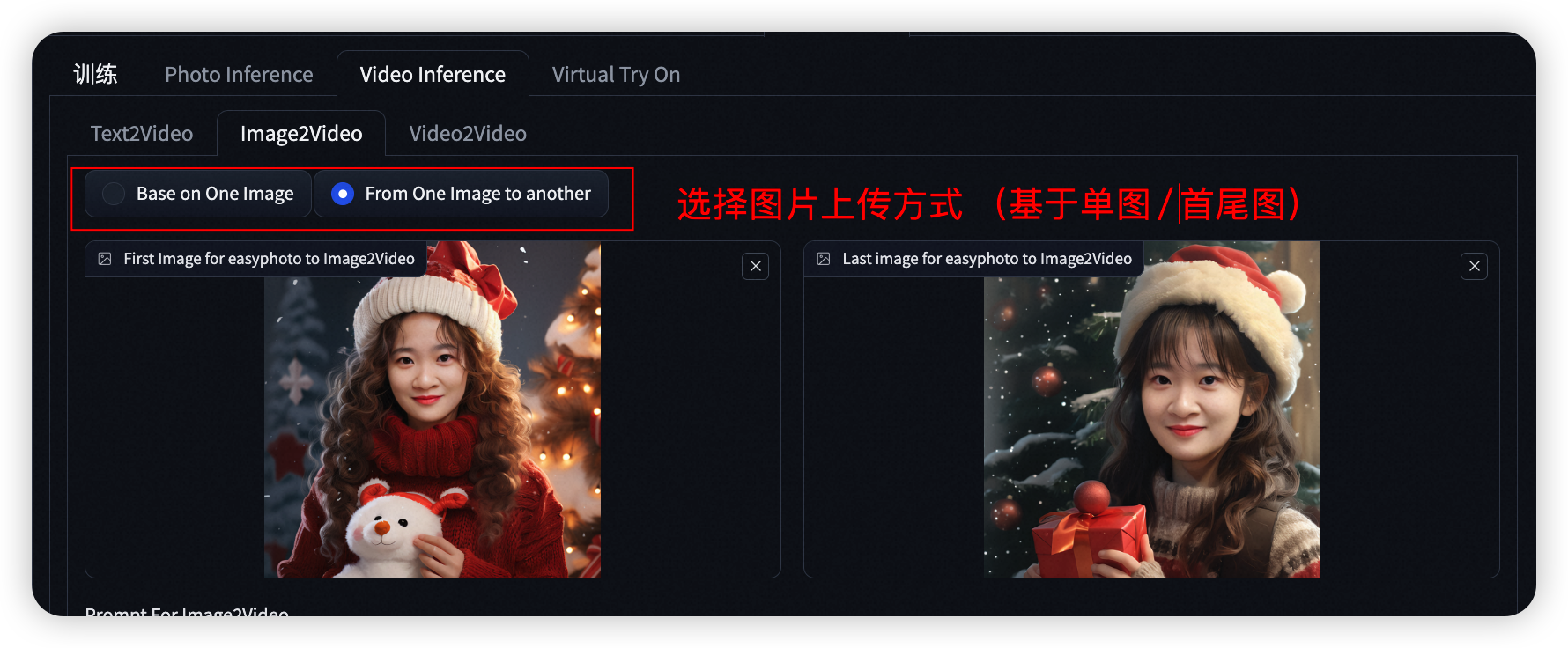
- Step2: 设置基模型、user_id 及相关参数。点击Start Generation 可进行视频的生成。并使用Text Options进行艺术字的添加。

2.3.3 指定视频的人物动图
- Step1: 上传一段人物视频
- Step2: 设置基模型、user_id 及相关参数。点击Start Generation 可进行视频的生成。并使用Text Options进行艺术字的添加。
3. 资源清理及后续
3.1 清理
- 在实验完成后,可前往对应产品控制台,停止或删除实例(两个操作均可),避免实例持续处于运行中,在超出免费试用额度后,带来额外的扣费;
- 后续仍考虑使用该实例>>停止;后续不再使用该实例>>删除,成功停止后即停止资源消耗。
3.2 后续
在试用有效期期间,您还可以继续使用DSW实例进行模型训练和推理验证。
附:
欢迎共建 EasyPhoto, Github地址:https://github.com/aigc-apps/sd-webui-EasyPhoto
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [仅界面]小白学习之python—界面化获取设置温湿度、控制图片风扇转动
- 解决 POST http://x.x.x.x:8000/aaa/ net::ERR_CONNECTION_TIMED_OUT
- 快乐学Python,数据分析之使用爬虫获取网页内容
- 小型内衣洗衣机什么牌子好?家用小型洗衣机推荐
- JDK8安装教程分享
- 《代码随想录》笔记
- 分析若依的文件上传处理逻辑
- MySQL的Explain详解(查询计划)
- 模块二——滑动窗口:438.找到字符串中所有字母异位词
- 【网站项目】基于springboot的医院信息管理系统