利用 OpenAI GPT、LangChain 和 Streamlit 创建自己的 PDF 问答系统

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号

原文标题:Create Your Own PDF Question Answering System with OpenAI GPT, LangChain, and Streamlit
原文地址:https://medium.com/python-in-plain-english/create-your-own-chatbot-for-pdf-documents-with-openai-gpt-and-streamlit-e5b35826bc1e
Github:https://github.com/liviaellen/ask_pdf

您是否有兴趣创建一个能阅读 PDF 文档并回答与文档内容相关问题的聊天机器人?在本教程中,我将向您展示如何使用 OpenAI 的 GPT 语言模型和 Python 的 Streamlit 库创建聊天机器人。我们还将使用 LangChain 库来完成自然语言处理任务。
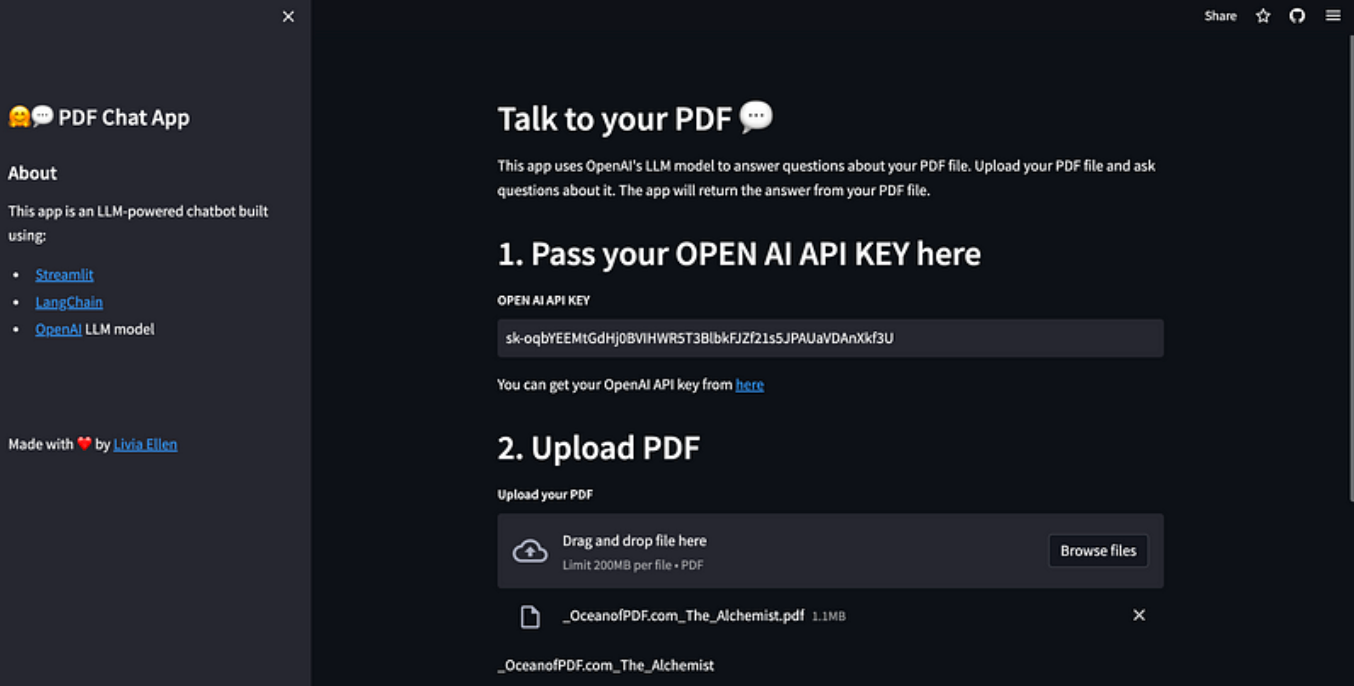
下面是创建 chatpdf.com 中聊天机器人的分步指南,它可以回答与您上传的 PDF 文件相关的问题。
这就是我们要创建的网站: https://ask-gpt-pdf.streamlit.app/
最棒的是,用户可以使用自己的 OpenAI API 密钥来使用它。用户可以从这里获取 OpenAI API 密钥。
无论你需要从报告、学术论文或任何其他 PDF 文档中提取信息,这款工具都能为你省时省力。

此外,该工具还能为您提供所回答的每个问题的成本信息。通过这一功能,您可以跟踪 API 的使用情况和费用。
在本教程中,我们将向您展示如何使用 OpenAI 的 GPT 语言模型、Streamlit 和 LangChain 创建这个聊天 PDF 工具。聊天 PDF 工具将回答有关任何上传 PDF 文件内容的问题。
先决条件
确保计算机上安装了 Python 3.10.6。
本项目需要两个文件:requirements.txt 和 app.py。
您还需要以下 Python 库,请将它们添加到 requirements.txt 中,但不包括圆点/破折号。
- langchain==0.0.154
- PyPDF2==3.0.1
- python-dotenv==1.0.0
- streamlit==1.18.1
- faiss-cpu==1.7.4
- streamlit-extras
- altair==4.1.0
- openai
- tiktoken
您可以使用以下命令安装它们:
pip install -r requirements.txt
创建 app.py 的分步指南
1.设置 Streamlit
首先,用所需的页面标题初始化 Streamlit,并创建一个包含相关信息的侧边栏:
st.set_page_config(page_title=’🤗💬 PDF Chat App — GPT’)
with st.sidebar:
st.title('🤗💬 PDF Chat App')
st.markdown('## About')
st.markdown('This app is an LLM-powered chatbot built using:')
st.markdown('- [Streamlit](https://streamlit.io/)')
st.markdown('- [LangChain](https://python.langchain.com/)')
st.markdown('- [OpenAI](https://platform.openai.com/docs/models) LLM model')
add_vertical_space(5)
st.write('Made with ?? by [Livia Ellen](https://liviaellen.com/portfolio)')
2.创建主要功能
接下来,定义应用程序的主要功能,以处理用户交互:
def main():
#…
3.收集用户输入
提示用户提供 OpenAI API 密钥,让他们上传 PDF 文件并输入问题:
st.header("1. Pass your OPEN AI API KEY here")
openai_key = st.text_input("**OPEN AI API KEY**")
st.write("You can get your OpenAI API key from [here](https://beta.openai.com/account/api-keys)")
os.environ["OPENAI_API_KEY"] = openai_key
st.header("2. Upload PDF")
pdf = st.file_uploader("**Upload your PDF**", type='pdf')
st.header("3. Ask questions about your PDF file:")
query = st.text_input("Questions", value="Tell me about the content of the PDF")
4.处理 PDF 文件
用户上传 PDF 文件后,从 PDF 文件中提取文本并将其分割成易于管理的部分:
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text=text)
5.创建嵌入
现在,使用 LangChain 的 OpenAIEmbeddings 类为文本块创建嵌入:
file_name = pdf.name[:-4]
if os.path.exists(f"{file_name}.pkl"):
with open(f"{file_name}.pkl", "rb") as f:
VectorStore = pickle.load(f)
else:
embeddings = OpenAIEmbeddings()
VectorStore = FAISS.from_texts(chunks, embedding=embeddings)
with open(f"{file_name}.pkl", "wb") as f:
pickle.dump(VectorStore, f)
6.问答
使用 LangChain 库和 OpenAI 模型,根据 PDF 内容回答用户的问题:
if st.button("Ask"):
if openai_key == '':
st.write('Warning: Please pass your OPEN AI API KEY on Step 1')
else:
docs = VectorStore.similarity_search(query=query, k=3)
llm = OpenAI()
chain = load_qa_chain(llm=llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=query)
st.header("Answer:")
st.write(response)
st.write('--')
st.header("OpenAI API Usage:")
st.text(cb)
7.运行 Streamlit 应用程序
最后,添加以下几行以运行 Streamlit 应用程序:
if __name__ == '__main__':
main()
在终端中使用以下命令启动应用程序:
streamlit run app.py
完成后,您可以将其上传到 github 并免费托管到 share.streamlit.io。
结论
在本教程中,我们创建了一个聊天机器人,它可以使用 OpenAI GPT 语言模型、Streamlit 和 LangChain 回答有关 PDF 内容的问题。这个聊天机器人可以帮助您从 PDF 中提取信息,而无需阅读整个文档。试试吧,看看它能如何帮助你更高效地浏览和理解 PDF 文件。
总结
- streamlit可视化
- PyPDF2.PdfReader读取PDF
- langchain.text_splitter.RecursiveCharacterTextSplitter 分块
- langchain.embeddings.openai.OpenAIEmbeddings 向量嵌入
- Faiss检索
- openai 调用模型
- langchain.chains.question_answering.load_qa_chain 问答
往期相关
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python3.x编码解码unicode字符串
- python遍历JSON LIST列表,分组存储某一字段相同的数据
- 怎么制作一款简单的小游戏?
- 如何在Go中使用JSON
- 摸底谷歌Gemini:CMU全面测评,Gemini Pro不敌GPT 3.5 Turbo
- 【QT】MDI应用程序设计
- Python3.12 新版本之f-string的几个新特性
- MP4转gif图片怎么操作?一个网站帮你搞定
- 视频剪辑方法:批量剪辑新思路,AI智剪来助阵
- Leetcode 45 跳跃游戏 II