kafka 的零拷贝原理
文章目录
今天来跟大家聊聊kafka的零拷贝原理是什么?
kafka 的零拷贝原理
??零拷贝是一种减少数据拷贝的机制,能够有效提升数据的效率;
??在实际应用中,如果我们需要把磁盘中的某个文件内容发送到远程服务器上, 那么它必须要经过几个拷贝的过程。
??从磁盘中读取目标文件内容拷贝到内核缓冲区;
??CPU 控制器再把内核缓冲区的数据赋值到用户空间的缓冲区中接着在应用程序中,调用 write() 方法,把用户空间缓冲区中的数据拷贝到内核下的 Socket Buffer 中。
??最后,把在内核模式下的 SocketBuffer 中的数据赋值到网卡缓冲区(NIC Buffer)
网卡缓冲区再把数据传输到目标服务器上。

??在这个过程中我们可以发现,数据从磁盘到最终发送出去,要经历 4 次拷贝,而在这四次拷贝过程中,有两次拷贝是浪费的,分别是:
??从内核空间赋值到用户空间
??从用户空间再次复制到内核空间,除此之外,由于用户空间和内核空间的切换会带来CPU 的上线文切换,对于CPU 性能也会造成性能影响。
??而零拷贝,就是把这两次多于的拷贝省略掉,应用程序可以直接把磁盘中的数据从内核中直接传输给 Socket,而不需要再经过应用程序所在的用户空间,如下图所示。
??零拷贝通过 DMA(Direct Memory Access)技术把文件内容复制到内核空间中的 Read Buffer,接着把包含数据位置和长度信息的文件描述符加载到 Socket Buffer 中,DMA 引擎直接可以把数据从内核空间中传递给网卡设备。
??在这个流程中,数据只经历了两次拷贝就发送到了网卡中,并且减少了 2 次 cpu
的上下文切换,对于效率有非常大的提高。
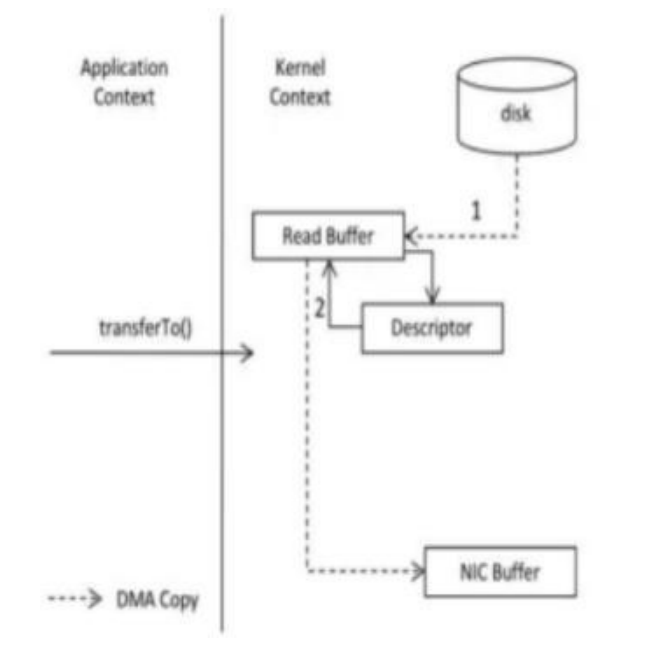
所以,所谓零拷贝,并不是完全没有数据赋值,只是相对于用户空间来说,不再需要进行数据拷贝。对于前面说的整个流程来说,零拷贝只是减少了不必要的拷贝次数而已。
在程序中如何实现零拷贝呢?
在 Linux 中,零拷贝技术依赖于底层的 sendfile()方法实现;
在 Java 中,FileChannal.transferTo()方法的底层实现就是 sendfile()方法。
除此之外,还有一个 mmap 的文件映射机制,它的原理是:将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
以上就是我个人对于 Kafka 中零拷贝原理的理解,感谢各位捧场!!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker本地部署开源浏览器Firefox并远程访问进行测试
- 安全基础~实战应用
- CComboBox重载在CListCtrl中使用
- 机器学习中的过采样和欠采样
- 游泳耳机怎么用?游泳耳机的正确使用方法
- vue-实现pc端点击滚动-左右箭头滑动
- 第三部分使用脚手架:vue学习(61-65)
- 【图神经网络 · 科研思考4】动态图数据集相关 wikipedia.csv;跨域节点表示学习;跨域&自监督;动态时空图&跨域;无监督领域适应方法?
- 【linux】Linux云主机搭建LNMP环境
- 【办公类-21-02】20240118育婴员操作题word打印2.0