Apache StreamPark:让数据流处理更简单、更高效
随着数据量的持续增长,我们正面临着前所未有的挑战。在这个充满数据的时代,如何有效、高效地处理这些数据,使其变为有价值的信息,是许多个人和组织所关心的问题。
作为一名数据分析师,我深知数据处理的复杂性。过去,我们使用传统的数据处理方法,但随着数据量的增大,这种方法已经无法满足我们的需求。我们急需一种能够实时、高效处理数据的新工具。
我相信在这个社会中也会有很多人跟我一样遇到这种问题,也相信肯定会有人针对这个问题发明一款解决的工具,于是我到Github搜索栏输入:Data analysis。出现的第一个就是Apache StreamPark,我就决定试一下。
使用StreamPark的过程非常简单,它能够实时接收、处理和存储数据,而且无需事先将数据存储在磁盘上,主要有几个特点。
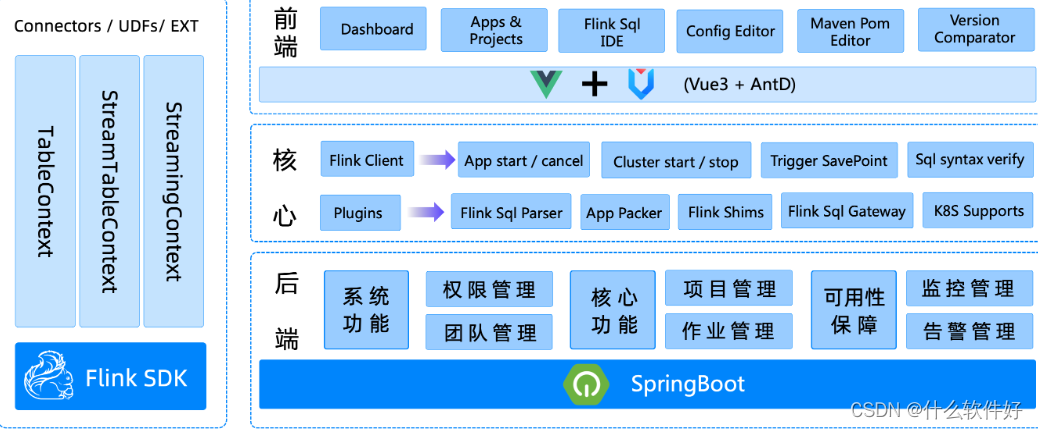
1.简单易用:StreamPark提供使用 Apache Flink 和 Apache Spark 编写流处理应用程序的开发框架,并抽象出一些共用的编程模型、启动配置和运维管理经验,规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式。
编辑 SQL

上传依赖包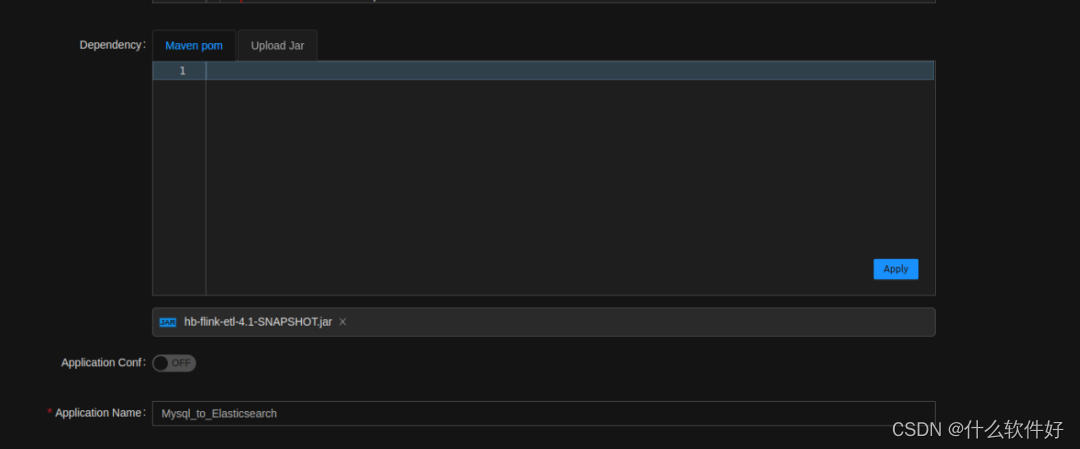
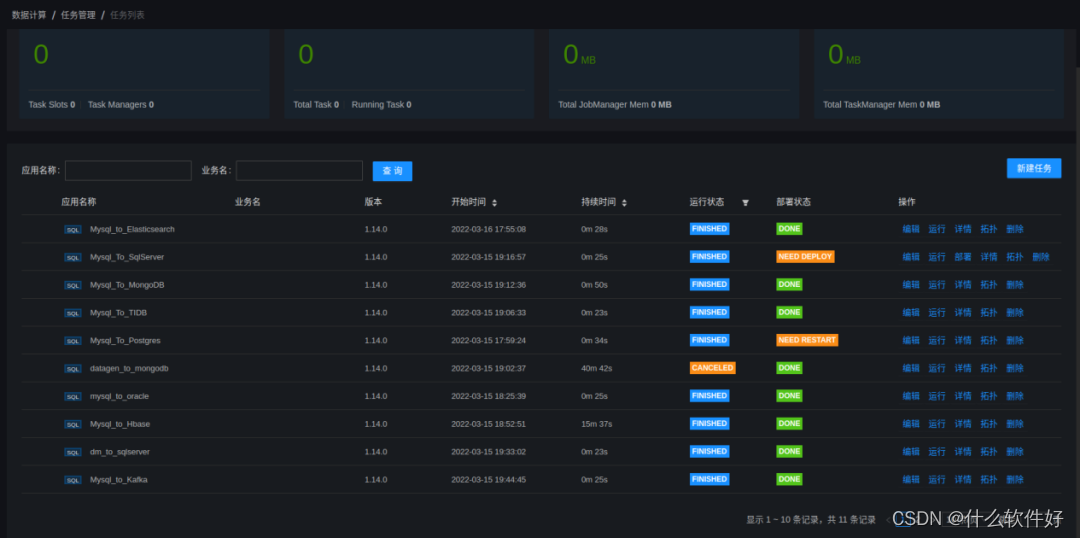
部署运行
2.流批一体、湖仓一体:StreamPark打造一个一站式大数据平台,支持流批一体、湖仓一体的解决方案,可以极大降低学习成本和开发门槛,让开发者只用关心最核心的业务。

3.支持多语言:StreamPark提供了scala和java两套api,方便不同语言的开发者使用。
StreamPark的出现,为我们数据分析师带来了许多好处。
首先,它能够实时处理数据,这意味着我们可以在第一时间获取到数据中的价值。其次,由于StreamPark的分布式架构,它可以处理大量数据,而无需担心性能问题。最后,StreamPark提供了丰富的数据处理功能,使得我们可以更方便地进行数据分析工作。
总的来说,StreamPark是一款非常出色的数据流处理工具。它改变了我们对数据处理的认识,使我们可以更轻松、更高效地处理数据。无论你是数据分析师、数据工程师,还是数据科学家,StreamPark都值得你尝试一下。我相信,它会给你带来全新的数据处理体验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编写时间类的工具类
- CAN记录仪汽车电子冬测神器
- (Java企业 / 公司项目)注册,配置中心Nacos的怎么使用?(含相关面试题)(一)
- ce从初阶到大牛--grep篇
- 人工智能-机器学习-深度学习-分类与算法梳理
- 三、计算机理论-计算机网络-物理层,数据通信的理论基础,物理传输媒体、编码与传输技术及传输系统
- vue3防抖函数封装与使用,以指令的形式使用
- 【Python进阶编程】python编程高手常用的设计模式(持续更新中)
- 智能优化算法应用:基于厨师算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- C++药房管理系统设计模块代码分析