【ZooKeeper高手实战】ZooKeeper 集群读写性能及生产环境参数配置
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送
发送 资料 可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁

ZooKeeper 集群读写性能及生产环境参数配置
zk 中的 Observer 节点在集群中到底发挥着什么作用?
zk 集群其实是适合 写少读多 场景的,因为整个集群只有 1 个 Leader 可以写,对于集群的读性能,可以通过 添加 Observer 节点来增强
Observer 节点Observer 是只读的、不参与 Leader 选举、也不参与 ZAB 协议同步时过半 Ack 的环节,只是单纯的接收数据,同步数据,达到数据顺序一致性的效果
Observer 的作用就是提供读服务,当读并发请求过高时,可以通过不断添加 Observer 节点来分散读请求的压力
那这里可能大家就会有问题了:既然想要增强读的性能,多添加点 Follower 节点不就可以了吗?
其实不行的,zk 是适合于 小集群部署 的,这是因为在集群中 Leader 完成写请求是需要经过半数以上的 Follower 都 Ack 之后,才可以成功写入的,如果集群中 Follower 过多,会大大增加 Leader 节点等待 Follower 节点发送 Ack 的时间,导致 zk 集群性能很差,因此 zk 集群部署一般都是 3 台或者 5 台机器
如下图,zk 集群部署为 1 主 2 从,通过添加 Observer 可以不断提升读性能:
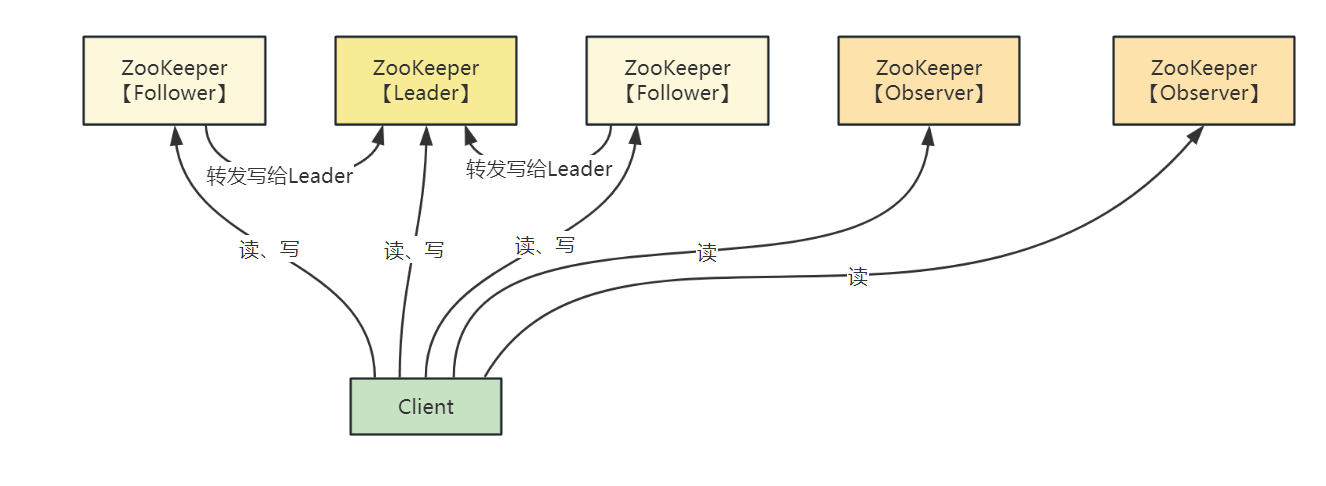
zk 集群的性能瓶颈在哪里呢?
瓶颈在于 Leader 的 写性能,如果 zk 集群挂掉的话,那么很有可能就是 Leader 的写入压力过大,这对一个公司的技术平台打击是巨大的,因为像 kafka 之类的技术都是强依赖 zk 的,dubbo + zk 去做服务框架的话,当服务实例达到上万甚至几十万时,大量服务的上线、注册、心跳的压力达到了每秒几万甚至十万,单个 Leader 抗几万的请求还行,十几万的话 zk 单个 Leader 是扛不住这么多的写请求的
想要提升 Leader 的 写性能,目前来说也就是提升部署 zk 的机器性能了,还有一种方式也就是将 dataLogDir 目录挂载的机器上配置 SSD 固态硬盘,以此来提升事务日志 写速度 来提升写性能(这个在后边将 zk 核心参数 dataLogDir 时会讲到)!
zk 集群推荐机器配置:
zk 作为 基础架构类别 的系统,对于部署的机器要求还是比较高的
推荐配置:3 台机器,8 核 16G 或者 16 核 32G,三台机器的小集群每秒抗十几万的并发读是没有问题的
zk 版本选择一般使用 3.4.5 版本
不同机器配置所能承载的并发量都是不同的:
在 3 台机器组成的 zk 集群中,1 个 Leader 抗几万 并发写 是可以的,每秒抗 5~10 万的 并发读 是没有问题的
zk 集群中,写性能无法提升,读性能提升可以通过添加 Observer 节点来实现
如何合理设置 ZooKeeper 的 JVM 参数以及内存大小?
JVM 参数设置的话,主要设置三个方面:堆内存、栈内存、Metaspace 区域的内存
机器如果有 16G 的内存:
- 堆内存可以分配 10G
- 栈内存可以分配每个线程的栈大小为 1MB
- Metaspace 区域可以分配个 512MB
垃圾回收器的话,如果是大内存机器,建议使用 G1,并且记得设置 G1 的参数(生产环境参数配置),G1 参数的设置是很重要的,包括对于 GC 日志写入位置以及 OOM 内存快照存储位置,这都是事故后分析所需要的,必须要设置:
Region 的大小预期的 GC 停顿时间设置 GC 日志写入哪里:方便可以监控 GC 情况如果发生 OOM,将 dump 出来的内存快照放到哪个目录:可以在发生 OOM 时,通过分析堆内存快照迅速找出来问题
建议在 zk 启动之后,在运行高峰期时,使用
jstat观察一下 jvm 运行的情况:新生代对象增长速率、Young GC 频率、老年代增长速率、Full GC 频率
这里简单说一下,怎么使用 jstat 来查到 zk 中 jvm 的运行情况
首先,要通过 ps -ef | grep zookeeper 来查出来 zk 的进程 id
再去使用 jstat -gc <进程id> 250 100 来查看 jvm 运行情况,250 100 表示采样间隔为 250 ms,采样数为 100,输出如下:

这些参数的含义为:
- S0C:年轻代中第一个survivor(幸存区)的容量 (单位kb)
- S1C:年轻代中第二个survivor(幸存区)的容量 (单位kb)
- S0U :年轻代中第一个survivor(幸存区)目前已使用空间 (单位kb)
- S1U :年轻代中第二个survivor(幸存区)目前已使用空间 (单位kb)
- EC :年轻代中Eden的容量 (单位kb)
- EU :年轻代中Eden目前已使用空间 (单位kb)
- OC :Old代的容量 (单位kb)
- OU :Old代目前已使用空间 (单位kb)
- MC:metaspace的容量 (单位kb)
- MU:metaspace目前已使用空间 (单位kb)
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC :从应用程序启动到采样时年轻代中gc次数
- YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
- FGC :从应用程序启动到采样时old代(全gc)gc次数
- FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux IO调度器介绍
- linux磁盘,分区,挂载等等
- python每日一题:连续子数组的最大和
- 【Git】fatal: bad boolean config value ‘true~‘ for ‘core.longpaths‘
- 你的毕业论文开始写了吗?
- 不藏了!6个你不能错过的Twitter数据分析工具
- odoo17 | 基本视图
- 分布式光伏与储能如何选mos
- Python学习9
- 线性回归中的似然函数、最大似然估计、最小二乘法怎么来的(让你彻底懂原理)收官之篇