(超详细)8-YOLOV5改进-添加EMA意力机制
发布时间:2024年01月21日
1、在yolov5/models下面新建一个EMA.py文件,在里面放入下面的代码

代码如下:
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, factor=8):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
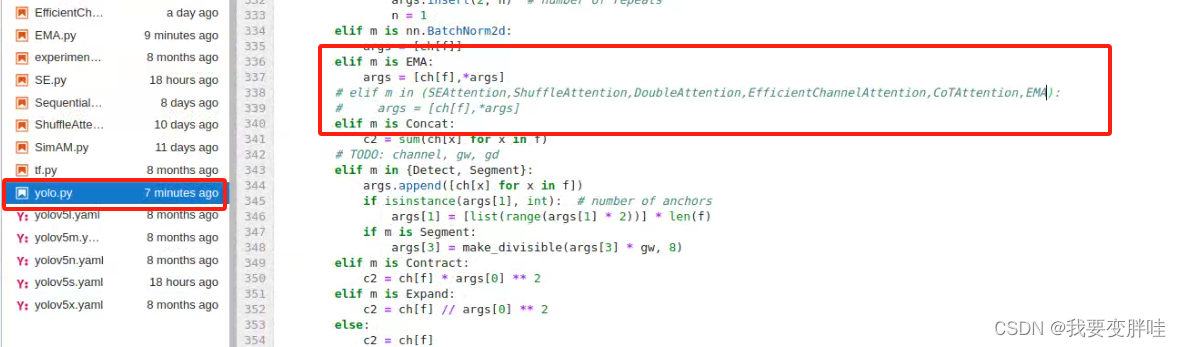
2、找到yolo.py文件,进行更改内容
在29行加一个from models.EMA import EMA, 保存即可

3、找到自己想要更改的yaml文件,我选择的yolov5s.yaml文件(你可以根据自己需求进行选择),将刚刚写好的模块EMA加入到yolov5s.yaml里面,并更改一些内容。更改如下

4、在yolo.py里面加入两行代码(335-337)
保存即可!
运行

文章来源:https://blog.csdn.net/qq_44421796/article/details/135725889
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Mars3d】关于locationBar等控件的css样式冲突处理问题
- 大型语言模型与知识图谱的完美结合:从LLMs到RAG,探索知识图谱构建的全新篇章
- 最新AI系统ChatGPT网站系统源码,Midjourney绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图+思维导图一站式解决方案
- JSON在API设计中的作用:如何构建高效、可扩展的接口
- ssl解码
- 2.1-学成在线内容管理之课程查询
- 【无标题】
- 【中位数问题】两个已升序数组确定其中位数
- MOS管和IGBT管的定义与辨别
- 机器学习入门:预测房价