55、Flink之用于外部数据访问的异步 I/O介绍及示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
本文主要介绍Flink 用于外部数据访问的异步I/O的实现原理、应用场景以及相关说明,最后以redis作为数据源的异步读取使用示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文运行示例需要redis的环境。
一、用于外部数据访问的异步 I/O
1、介绍
在大多数情况下,I/O访问是一个耗时的过程,这使得单个operator的TPS比内存计算低得多,尤其是对于流式作业,当低延迟是用户的一大担忧时。启动多个线程可能是处理这个问题的一种选择,但缺点是显而易见的:最终用户的编程模型可能会变得更加复杂,因为他们必须在运算符中实现线程模型。此外,他们必须注意与checkpointing的协调。
- AsyncFunction: 异步I/O将在AsyncFunction中触发。
- AsyncWaitOperator: 一个将调用AsyncFunction的StreamOperator。
- AsyncCollector: 对于每个输入流记录,将创建一个AsyncCollector,并将其传递到用户的回调中,以获得异步i/o结果。
- AsyncCollectorBuffer: 用于保存所有AsyncCollecters的缓冲区。
- Emitter Thread: AsyncCollectorBuffer中的一个工作线程,在一些AsyncCollecters完成异步i/o时发出信号,并将结果发送到下游的operator。
2、相关细节介绍
1)、AsyncDataStream
通过AsyncDataStream帮助类,将执行异步i/o操作的AsyncFunction添加到FLINK流作业中的方法。其主要方法如下:
public class AsyncDataStream {
/**
* Add an AsyncWaitOperator. The order of output stream records may be reordered.
*
* @param in Input data stream
* @param func AsyncFunction
* @bufSize The max number of async i/o operation that can be triggered
* @return A new DataStream.
*/
public static DataStream<OUT> unorderedWait(DataStream<IN> in, AsyncFunction<IN, OUT> func, int bufSize);
public static DataStream<OUT> unorderedWait(DataStream<IN> in, AsyncFunction<IN, OUT> func);
/**
* Add an AsyncWaitOperator. The order of output stream records is guaranteed to be the same as input ones.
*
* @param func AsyncWaitFunction
* @param func AsyncFunction
* @bufSize The max number of async i/o operation that can be triggered
* @return A new DataStream.
*/
public static DataStream<OUT> orderedWait(DataStream<IN> in, AsyncFunction<IN, OUT> func, int bufSize);
public static DataStream<OUT> orderedWait(DataStream<IN> in, AsyncFunction<IN, OUT> func);
}
2)、Proposed Changes
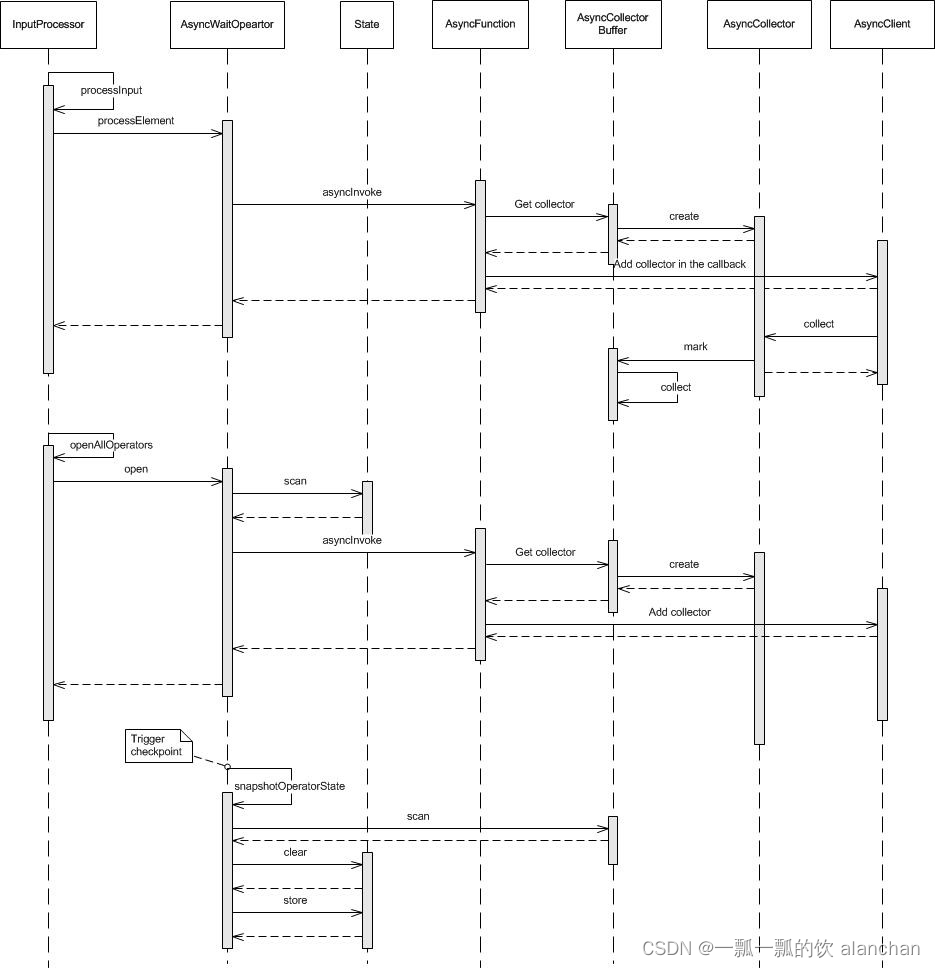
下图说明了在下面四种情况下流数据是如何被处理的
- AsyncWaitOperator到达时
- 任务容错恢复时
- 状态快照时
- 通过Emitter Thread 开始emit时
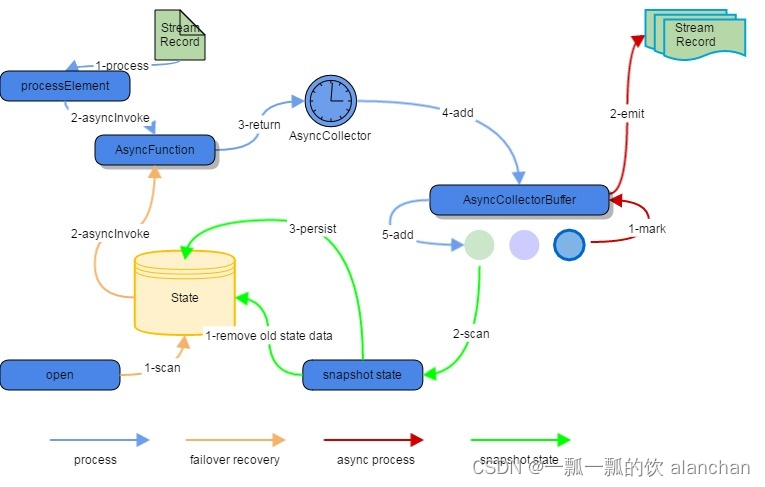
序列图
3)、AsyncFunction
AsyncFunction在AsyncWaitOperator中作为用户函数工作,它看起来像StreamFlatMap运算符,具有open()/processElement(StreamRecord record)/processWatermark(Watermark mark)。
对于用户的具体AsyncFunction,必须覆盖asyncInvoke(IN input, AsyncCollector collector) 以提供启动异步操作的代码。
public interface AsyncFunction<IN, OUT> extends Function, Serializable {
/**
* Trigger async operation for each stream input.
* The AsyncCollector should be registered into async client.
*
* @param input Stream Input
* @param collector AsyncCollector
*/
void asyncInvoke(IN input, AsyncCollector<OUT> collector) throws Exception;
}
public abstract class RichAsyncFunction<IN, OUT> extends AbstractRichFunction
implements AsyncFunction<IN, OUT> {
@Override
public abstract void asyncInvoke(IN input, AsyncCollector<OUT> collector) throws Exception;
}
对于AsyncWaitOperator的每个输入流记录,它们将由AsyncFunction.asyncInvoke(IN input, AsyncCollector cb)处理。然后,AsyncCollector将被追加到AsyncCollectorBuffer中。我们稍后将介绍AsyncCollector和AsyncCollectorBuffer。
4)、AsyncCollector
AsyncCollector由AsyncWaitOperator创建,并传递到AsyncFunction,在那里它应该被添加到用户的回调中。它充当从用户代码中获取结果或错误并通知AsyncCollectorBuffer发出结果的角色。
特定于用户的函数是collect,当异步操作完成或抛出错误时,应该调用它们。
public class AsyncCollector<OUT> {
private List<OUT> result;
private Throwable error;
private AsyncCollectorBuffer<OUT> buffer;
/**
* Set result
* @param result A list of results.
*/
public void collect(List<OUT> result) {
this.result = result;
buffer.mark(this);
}
/**
* Set error
* @param error A Throwable object.
*/
public void collect(Throwable error) {
this.error = error;
buffer.mark(this);
}
/**
* Get result. Throw RuntimeException while encountering an error.
* @return A List of result.
* @throws RuntimeException RuntimeException wrapping errors from user codes.
*/
public List<OUT> getResult() throws RuntimeException { ... }
}
5)、如何使用
在调用AsyncFunction.asyncInvoke(IN input, AsyncCollector collector)之前,AsyncWaitOperator将尝试从AsyncCollectorBuffer获取AsyncCollector的实例。然后它将被带到用户的回调函数中。如果缓冲区已满,它将等待一些正在进行的回调完成。
异步操作完成后,AsyncCollector.collect()将获取结果或错误,并通知AsyncCollectorBuffer。
AsyncCollector由FLINK实现。
6)、AsyncCollectorBuffer
AsyncCollectorBuffer保留所有AsyncCollecters,并将结果发送到下一个节点。
当调用AsyncCollector.collect()时,将在AsyncCollectorBuffer中放置一个标记,指示已完成的AsyncCollecters。一旦AsyncCollector获得结果,一个名为Emitter的工作线程也将发出信号,然后根据有序或无序设置尝试发出结果。
为了简单起见,我们将在下面的文本中将任务引用到AsyncCollectorBuffer中的AsycnCollector。
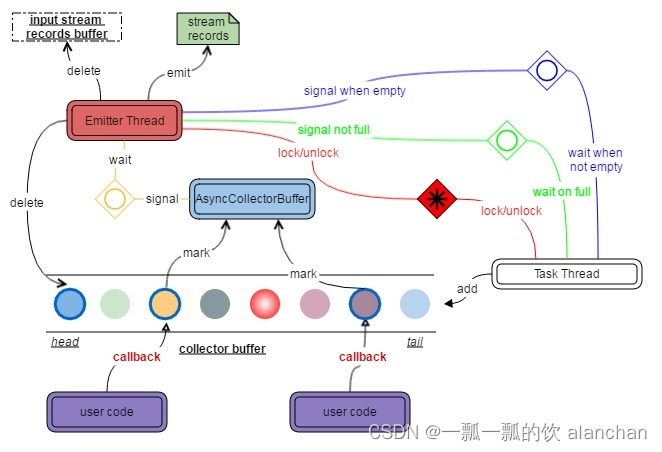
Ordered and Unordered
根据用户配置,输出元素的顺序将得到保证或不会得到保证。如果不能保证,稍后完成的AsyncCollectors将提前发出。
Emitter Thread
发射器线程将等待完成的AsyncCollectors。当发出信号时,它将按如下方式处理缓冲区中的任务:
- Ordered Mode
如果缓冲区中的第一个任务完成,则发射器将收集其结果,然后继续执行第二个任务。如果第一项任务还没有完成,就再等一次。 - Unordered Mode
检查缓冲区中所有已完成的任务,并从缓冲区中最旧水印之前的任务中收集结果。
Emitter Thread and Task Thread 将通过获取/释放锁进行独占访问。
当所有任务都完成时,向Task Thread发出信号,通知它所有数据都已处理,并且可以关闭operator。
从缓冲区中删除一些任务后,向Task Thread发送信号。
将异常传播到Task Thread。
Task Thread
仅针对Emitter Thread访问AsyncCollectorBuffer。
获取并向缓冲区添加一个新的AsyncCollector,等待直到缓冲区满。
Watermark
所有水印也将保存在AsyncCollectorBuffer中。当且仅当在当前水印之前的所有AsyncCollectors都已发出之后,才会发出水印。
7)、State, Failover and Checkpoint
State and Checkpoint
所有输入流记录将保持在state。AsyncWaitOperator不会在处理时将每个输入流记录逐个存储到state,而是在snapshotting operator state时将AsyncCollectorBuffer中的所有输入流记录都置于state。在保留这些记录之前,将清除state中的旧数据。
当所有barriers到达operator处时,可以立即进行检查。
Failover
在恢复operator’s state时,operator 将扫描该状态中的所有元素,获取AsyncCollectors,调用AsyncFunction.asyncInvoke()并将它们插入AsyncCollectorBuffer。
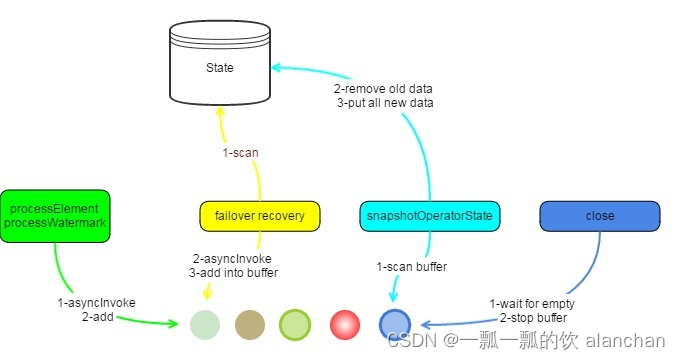
Async Resource Sharing
对于在同一TaskManager(也称为同一JVM)中的不同插槽(任务工作者)之间共享异步资源(如连接hbase、netty等)的情况,我们可以使连接为静态的,以便同一进程中的所有线程都可以共享同一实例。
当然,在使用这些资源时,请注意线程安全。
3、官方示例
1)、回调示例
public class HBaseAsyncFunction implements AsyncFunction<String, String> {
// initialize it while reading object
transient Connection connection;
@Override
public void asyncInvoke(String val, AsyncCollector<String> c) {
Get get = new Get(Bytes.toBytes(val));
Table ht = connection.getTable(TableName.valueOf(Bytes.toBytes("test")));
// UserCallback is from user’s async client.
((AsyncableHTableInterface) ht).asyncGet(get, new UserCallback(c));
}
}
// create data stream
public void createHBaseAsyncTestStream(StreamExecutionEnvironment env) {
DataStream<String> source = getDataStream(env);
DataStream<String> stream = AsyncDataStream.unorderedWait(source, new HBaseAsyncFunction());
stream.print();
}
2)、监听示例
import com.google.common.util.concurrent.FutureCallback;
import com.google.common.util.concurrent.Futures;
import com.google.common.util.concurrent.MoreExecutors;
import com.google.common.util.concurrent.ListenableFuture;
public class HBaseAsyncFunction implements AsyncFunction<String, String> {
// initialize it while reading object
transient Connection connection;
@Override
public void asyncInvoke(String val, AsyncCollector<String> c) {
Get get = new Get(Bytes.toBytes(val));
Table ht = connection.getTable(TableName.valueOf(Bytes.toBytes("test")));
ListenableFuture<Result> future = ht.asyncGet(get);
Futures.addCallback(future,
new FutureCallback<Result>() {
@Override public void onSuccess(Result result) {
List ret = new ArrayList<String>();
ret.add(result.get(...));
c.collect(ret);
}
@Override public void onFailure(Throwable t) {
c.collect(t);
}
},
MoreExecutors.newDirectExecutorService()
);
}
}
// create data stream
public void createHBaseAsyncTestStream(StreamExecutionEnvironment env) {
DataStream<String> source = getDataStream(env);
DataStream<String> stream = AsyncDataStream.unorderedWait(source, new HBaseAsyncFunction());
stream.print();
}
二、对于异步 I/O 操作的需求
在与外部系统交互(用数据库中的数据扩充流数据)的时候,需要考虑与外部系统的通信延迟对整个流处理应用的影响。
简单地访问外部数据库的数据,比如使用 MapFunction,通常意味着同步交互: MapFunction 向数据库发送一个请求然后一直等待,直到收到响应。在许多情况下,等待占据了函数运行的大部分时间。
与数据库异步交互是指一个并行函数实例可以并发地处理多个请求和接收多个响应。这样,函数在等待的时间可以发送其他请求和接收其他响应。至少等待的时间可以被多个请求摊分。大多数情况下,异步交互可以大幅度提高流处理的吞吐量。
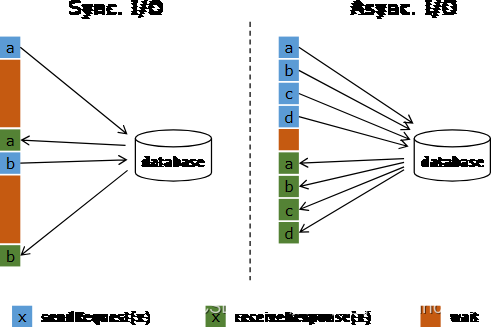
仅仅提高 MapFunction 的并行度(parallelism)在有些情况下也可以提升吞吐量,但是这样做通常会导致非常高的资源消耗:更多的并行 MapFunction 实例意味着更多的 Task、更多的线程、更多的 Flink 内部网络连接、 更多的与数据库的网络连接、更多的缓冲和更多程序内部协调的开销。
正确地实现数据库(或键/值存储)的异步 I/O 交互需要支持异步请求的数据库客户端。许多主流数据库都提供了这样的客户端。
如果没有这样的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端。然而,这种方法通常比正规的异步客户端效率低。
三、异步 I/O API
Flink 的异步 I/O API 允许用户在流处理中使用异步请求客户端。API 处理与数据流的集成,同时还能处理好顺序、事件时间和容错等。
在具备异步数据库客户端的基础上,实现数据流转换操作与数据库的异步 I/O 交互需要以下三部分:
- 实现分发请求的 AsyncFunction
- 获取数据库交互的结果并发送给 ResultFuture 的 回调 函数
- 将异步 I/O 操作应用于 DataStream 作为 DataStream 的一次转换操作, 启用或者不启用重试。
下面是基本的代码模板:
// 这个例子使用 Java 8 的 Future 接口(与 Flink 的 Future 相同)实现了异步请求和回调。
/**
* 实现 'AsyncFunction' 用于发送请求和设置回调。
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** 能够利用回调函数并发发送请求的数据库客户端 */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// 发送异步请求,接收 future 结果
final Future<String> result = client.query(key);
// 设置客户端完成请求后要执行的回调函数
// 回调函数只是简单地把结果发给 future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// 显示地处理异常。
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// 创建初始 DataStream
DataStream<String> stream = ...;
// 应用异步 I/O 转换操作,不启用重试
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
// 或 应用异步 I/O 转换操作并启用重试
// 通过工具类创建一个异步重试策略, 或用户实现自定义的策略
AsyncRetryStrategy asyncRetryStrategy =
new AsyncRetryStrategies.FixedDelayRetryStrategyBuilder(3, 100L) // maxAttempts=3, fixedDelay=100ms
.ifResult(RetryPredicates.EMPTY_RESULT_PREDICATE)
.ifException(RetryPredicates.HAS_EXCEPTION_PREDICATE)
.build();
// 应用异步 I/O 转换操作并启用重试
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWaitWithRetry(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100, asyncRetryStrategy);
说明:
第一次调用 ResultFuture.complete 后 ResultFuture 就完成了。 后续的 complete 调用都将被忽略。
下面两个参数控制异步操作:
-
Timeout: 超时参数定义了异步操作执行多久未完成、最终认定为失败的时长,如果启用重试,则可能包括多个重试请求。 它可以防止一直等待得不到响应的请求。
-
Capacity: 容量参数定义了可以同时进行的异步请求数。 即使异步 I/O 通常带来更高的吞吐量,执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈。 限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压。
-
AsyncRetryStrategy: 重试策略参数定义了什么条件会触发延迟重试以及延迟的策略,例如,固定延迟、指数后退延迟、自定义实现等。
1、超时处理
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业。 如果你想处理超时,可以重写 AsyncFunction#timeout 方法。 重写 AsyncFunction#timeout 时别忘了调用 ResultFuture.complete() 或者 ResultFuture.completeExceptionally() 以便告诉Flink这条记录的处理已经完成。如果超时发生时你不想发出任何记录,你可以调用 ResultFuture.complete(Collections.emptyList()) 。
2、结果的顺序
AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序。 Flink 提供两种模式控制结果记录以何种顺序发出。
-
无序模式: 异步请求一结束就立刻发出结果记录。 流中记录的顺序在经过异步 I/O 算子之后发生了改变。 当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。 此模式使用 AsyncDataStream.unorderedWait(…) 方法。
-
有序模式: 这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。为了实现这一点,算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时)。由于记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来一些额外的延迟和 checkpoint 开销。此模式使用 AsyncDataStream.orderedWait(…) 方法。
3、事件时间
当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。对于两种顺序模式,这意味着以下内容:
- 无序模式: Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。 只有连续两个 watermark 之间的记录是无序发出的。 在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。 在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。
这意味着存在 watermark 的情况下,无序模式 会引入一些与有序模式 相同的延迟和管理开销。开销大小取决于 watermark 的频率。
- 有序模式: 连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间 相比,没有显著的差别。
摄入时间 是一种特殊的事件时间,它基于数据源的处理时间自动生成 watermark。
4、容错保证
异步 I/O 算子提供了完全的精确一次容错保证。它将在途的异步请求的记录保存在 checkpoint 中,在故障恢复时重新触发请求。
5、重试支持
重试支持为异步 I/O 操作引入了一个内置重试机制,它对用户的异步函数实现逻辑是透明的。
-
AsyncRetryStrategy: 异步重试策略包含了触发重试条件 AsyncRetryPredicate 定义,以及根据当前已尝试次数判断是否继续重试、下次重试间隔时长的接口方法。 需要注意,在满足触发重试条件后,有可能因为当前重试次数超过预设的上限放弃重试,或是在任务结束时被强制终止重试(这种情况下,系统以最后一次执行的结果或异常作为最终状态)。
-
AsyncRetryPredicate: 触发重试条件可以选择基于返回结果、 执行异常来定义条件,两种条件是或的关系,满足其一即会触发。
6、实现提示
在实现使用 Executor(或者 Scala 中的 ExecutionContext)和回调的 Futures 时,建议使用 DirectExecutor,因为通常回调的工作量很小,DirectExecutor 避免了额外的线程切换开销。回调通常只是把结果发送给 ResultFuture,也就是把它添加进输出缓冲。从这里开始,包括发送记录和与 chenkpoint 交互在内的繁重逻辑都将在专有的线程池中进行处理。
DirectExecutor 可以通过 org.apache.flink.util.concurrent.Executors.directExecutor() 或 com.google.common.util.concurrent.MoreExecutors.directExecutor() 获得。
7、警告
Flink 不以多线程方式调用 AsyncFunction
我们想在这里明确指出一个经常混淆的地方:AsyncFunction 不是以多线程方式调用的。 只有一个 AsyncFunction 实例,它被流中相应分区内的每个记录顺序地调用。除非 asyncInvoke(…) 方法快速返回并且依赖于(客户端的)回调, 否则无法实现正确的异步 I/O。
例如,以下情况导致阻塞的 asyncInvoke(…) 函数,从而使异步行为无效:
- 使用同步数据库客户端,它的查询方法调用在返回结果前一直被阻塞。
- 在 asyncInvoke(…) 方法内阻塞等待异步客户端返回的 future 类型对象
默认情况下,AsyncFunction 的算子(异步等待算子)可以在作业图的任意处使用,但它不能与SourceFunction/SourceStreamTask组成算子链
启用重试后可能需要更大的缓冲队列容量
新的重试功能可能会导致更大的队列容量要求,最大数量可以近似地评估如下。
inputRate * retryRate * avgRetryDuration
例如,对于一个输入率=100条记录/秒的任务,其中1%的元素将平均触发1次重试,平均重试时间为60秒,额外的队列容量要求为:
100条记录/秒 * 1% * 60s = 60
也就是说,
在无序输出模式下,给工作队列增加 60 个容量可能不会影响吞吐量;
而在有序模式下,头部元素是关键点,它未完成的时间越长,算子提供的处理延迟就越长, 在相同的超时约束下,如果头元素事实上获得了更多的重试, 那重试功能可能会增加头部元素的处理时间即未完成时间,也就是说在有序模式下,增大队列容量并不是总能提升吞吐。
当队列容量增长时( 这是缓解背压的常用方法),OOM 的风险会随之增加。对于 ListState 存储来说,理论的上限是 Integer.MAX_VALUE, 所以, 虽然事实上队列容量的限制是一样的,但我们在生产中不能把队列容量增加到太大,这种情况下增加任务的并行性也许更可行。
四、示例:异步读取用户信息
本示例是模拟根据外部数据用户姓名查询redis中用户的个人信息。
本示例外部数据就以flink的集合作为示例,redis数据中存储的为hash表,下面验证中会有具体展示。
1、maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.12</artifactId>
<version>1.1.0</version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_2.12</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-runtime_2.12</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-core</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-java</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
2、redis异步交互数据实现
1)、读取redis数据时以string进行输出
package org.datastreamapi.source.custom.redis;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Supplier;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import com.sun.jdi.IntegerValue;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author alanchan
*
*/
public class CustomRedisSource extends RichAsyncFunction<String, String> {
private JedisPoolConfig config = null;
private static String ADDR = "192.168.10.41";
private static int PORT = 6379;
// 等待可用连接的最大时间,单位是毫秒,默认是-1,表示永不超时
private static int TIMEOUT = 10000;
private JedisPool jedisPool = null;
private Jedis jedis = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
config = new JedisPoolConfig();
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT);
jedis = jedisPool.getResource();
}
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
// 文件中读取的内容
System.out.println("输入参数input----:" + input);
// 发起一个异步请求,返回结果
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
String[] arrayData = input.split(",");
String name = arrayData[1];
String value = jedis.hget("AsyncReadUser_Redis", name);
System.out.println("查询结果output----:" + value);
return value;
}
}).thenAccept((String dbResult) -> {
// 设置请求完成时的回调,将结果返回
resultFuture.complete(Collections.singleton(dbResult));
});
}
// 连接超时的时候调用的方法
@Override
public void timeout(String input, ResultFuture<String> resultFuture) throws Exception {
System.out.println("redis connect timeout!");
}
@Override
public void close() throws Exception {
super.close();
if (jedis.isConnected()) {
jedis.close();
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class User {
private int id;
private String name;
private int age;
private double balance;
User(String value) {
String[] str = value.split(",");
this.setId(Integer.valueOf(str[0]));
this.setName(str[1]);
this.setAge(Integer.valueOf(str[2]));
this.setBalance(Double.valueOf(str[3]));
}
}
}
2)、读取redis数据时以pojo进行输出
package org.datastreamapi.source.custom.redis;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Supplier;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.datastreamapi.source.custom.redis.CustomRedisSource.User;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author alanchan
*
*/
public class CustomRedisSource2 extends RichAsyncFunction<String, User> {
private JedisPoolConfig config = null;
private static String ADDR = "192.168.10.41";
private static int PORT = 6379;
// 等待可用连接的最大时间,单位是毫秒,默认是-1,表示永不超时
private static int TIMEOUT = 10000;
private JedisPool jedisPool = null;
private Jedis jedis = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
config = new JedisPoolConfig();
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT);
jedis = jedisPool.getResource();
}
@Override
public void asyncInvoke(String input, ResultFuture<User> resultFuture) throws Exception {
System.out.println("输入查询条件:" + input);
CompletableFuture.supplyAsync(new Supplier<User>() {
@Override
public User get() {
String[] arrayData = input.split(",");
String name = arrayData[1];
String value = jedis.hget("AsyncReadUser_Redis", name);
System.out.println("查询redis结果:" + value);
return new User(value);
}
}).thenAccept((User dbResult) -> {
// 设置请求完成时的回调,将结果返回
resultFuture.complete(Collections.singleton(dbResult));
});
}
// 连接超时的时候调用的方法
@Override
public void timeout(String input, ResultFuture<User> resultFuture) throws Exception {
System.out.println("redis connect timeout!");
}
@Override
public void close() throws Exception {
super.close();
if (jedis.isConnected()) {
jedis.close();
}
}
}
3、使用示例
package org.datastreamapi.source.custom.redis;
import java.util.concurrent.TimeUnit;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.redis.CustomRedisSource.User;
/**
* @author alanchan
*
*/
public class TestCustomRedisSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// id,name
DataStreamSource<String> lines = env.fromElements("1,alan", "2,alanchan", "3,alanchanchn", "4,alan_chan", "5,alan_chan_chn");
SingleOutputStreamOperator<String> result = AsyncDataStream.orderedWait(lines, new CustomRedisSource(), 10, TimeUnit.SECONDS, 1);
SingleOutputStreamOperator<User> result2 = AsyncDataStream.orderedWait(lines, new CustomRedisSource2(), 10, TimeUnit.SECONDS, 1);
result.print("result-->").setParallelism(1);
result2.print("result2-->").setParallelism(1);
env.execute();
}
}
4、验证
1)、准备redis环境数据
hset AsyncReadUser_Redis alan '1,alan,18,20,alan.chan.chn@163.com'
hset AsyncReadUser_Redis alanchan '2,alanchan,19,25,alan.chan.chn@163.com'
hset AsyncReadUser_Redis alanchanchn '3,alanchanchn,20,30,alan.chan.chn@163.com'
hset AsyncReadUser_Redis alan_chan '4,alan_chan,27,20,alan.chan.chn@163.com'
hset AsyncReadUser_Redis alan_chan_chn '5,alan_chan_chn,36,10,alan.chan.chn@163.com'
127.0.0.1:6379> hset AsyncReadUser_Redis alan '1,alan,18,20,alan.chan.chn@163.com'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alanchan '2,alanchan,19,25,alan.chan.chn@163.com'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alanchanchn '3,alanchanchn,20,30,alan.chan.chn@163.com'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alan_chan '4,alan_chan,27,20,alan.chan.chn@163.com'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alan_chan_chn '5,alan_chan_chn,36,10,alan.chan.chn@163.com'
(integer) 1
127.0.0.1:6379> hgetall AsyncReadUser_Redis
1) "alan"
2) "1,alan,18,20,alan.chan.chn@163.com"
3) "alanchan"
4) "2,alanchan,19,25,alan.chan.chn@163.com"
5) "alanchanchn"
6) "3,alanchanchn,20,30,alan.chan.chn@163.com"
7) "alan_chan"
8) "4,alan_chan,27,20,alan.chan.chn@163.com"
9) "alan_chan_chn"
10) "5,alan_chan_chn,36,10,alan.chan.chn@163.com"
2)、启动应用程序,并观察控制台输出
输入查询条件:5,alan_chan_chn
输入参数input----:2,alanchan
输入参数input----:5,alan_chan_chn
输入查询条件:3,alanchanchn
输入查询条件:1,alan
输入参数input----:1,alan
输入查询条件:2,alanchan
输入查询条件:4,alan_chan
输入参数input----:4,alan_chan
输入参数input----:3,alanchanchn
查询结果output----:3,alanchanchn,20,30,alan.chan.chn@163.com
查询redis结果:1,alan,18,20,alan.chan.chn@163.com
查询结果output----:1,alan,18,20,alan.chan.chn@163.com
查询redis结果:4,alan_chan,27,20,alan.chan.chn@163.com
查询redis结果:2,alanchan,19,25,alan.chan.chn@163.com
查询结果output----:2,alanchan,19,25,alan.chan.chn@163.com
查询redis结果:3,alanchanchn,20,30,alan.chan.chn@163.com
查询结果output----:4,alan_chan,27,20,alan.chan.chn@163.com
查询结果output----:5,alan_chan_chn,36,10,alan.chan.chn@163.com
查询redis结果:5,alan_chan_chn,36,10,alan.chan.chn@163.com
result-->> 4,alan_chan,27,20,alan.chan.chn@163.com
result-->> 5,alan_chan_chn,36,10,alan.chan.chn@163.com
result-->> 3,alanchanchn,20,30,alan.chan.chn@163.com
result-->> 2,alanchan,19,25,alan.chan.chn@163.com
result-->> 1,alan,18,20,alan.chan.chn@163.com
result2-->> CustomRedisSource.User(id=4, name=alan_chan, age=27, balance=4.0)
result2-->> CustomRedisSource.User(id=1, name=alan, age=18, balance=1.0)
result2-->> CustomRedisSource.User(id=3, name=alanchanchn, age=20, balance=3.0)
result2-->> CustomRedisSource.User(id=5, name=alan_chan_chn, age=36, balance=5.0)
result2-->> CustomRedisSource.User(id=2, name=alanchan, age=19, balance=2.0)
以上,本文主要介绍Flink 用于外部数据访问的异步I/O的实现原理、应用场景以及相关说明,最后以redis作为数据源的异步读取使用示例。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 经典问题 | 线程打印ABA问题
- 梯度下降法
- [Angular] 笔记 15:模板驱动表单 - 表单验证
- 学计算机必参加的含金量赛事!但凡参加一个面试都要简单一倍
- 代码随想录算法训练营第53天|● 1143.最长公共子序列 ● 1035.不相交的线 ● 53. 最大子序和 动态规划
- 某汽车塑料制品有限公司:采用监控易管理平台提升IT运营效率
- Hive数据库:嵌入、本地、远程全攻略(上)
- sublim安装Autoprefixer插件
- 【Qt-QFile-QDir】
- pytorch08:学习率调整策略