Prompt Engineering 可能会是 2024 年最热门的“编程语言”?
编者按:“Prompt Engineering”是否已经过时?模型本身的能力是否已经足够,不再需要特意设计 prompt?
我们今天为大家带来的文章,作者认为 Prompt Engineering 不会过时,相反随着模型能力的增强,编写高质量 prompt 的重要性也将继续增加。
文章详细论点归纳:
(1)大语言模型应被视为操作系统的内核,而 prompt 是调用其的程序;
(2)Prompt Engineering 使自然语言编程拥有更广阔的应用空间;
(3)更强大的模型需要更精细的 prompt 来发挥其能力,微软和 Anthropic 的案例佐证了这一点;
(4)目前个人用户可以将 Prompt Engineering 与其他程序结合,构建新的应用;
(5)持续学习、实践和深入理解技术,是成为 Prompt Engineering 高手的捷径。
Prompt Engineering 不会被大语言模型本身的进步所淘汰,相反会被赋予更重要的意义。掌握这项技能,就有很大几率在 AI 革命中站在潮头。
作者 | Nabil Alouani
编译 | 岳扬
“我认为将大语言模型视为 chatbots 或某种文字生成器是不准确的, ” OpenAI的创始成员之一Andrej Karpathy[1]表示。“更准确的描述是将它们视为操作系统的内核进程(kernel process)。 ”
等等,这到底是什么意思呢?
大语言模型(LLMs)将逐渐成为用户和计算机系统之间的桥梁。
当前,您所使用的设备虽然具备一定的计算能力,但却无法直接访问这种能力。操作系统(如 Windows、Mac OS 和安卓系统)通过将芯片和电路的集合转化为用户友好的界面,实现了与用户的交互。
操作系统(OS)通过在其上运行的各种应用程序执行各种任务(比如阅读某个秃头小伙的文章)。每个应用程序都有自己的用户界面(UI)和可以完成的一系列任务。您可以根据需要从一个应用程序跳转到另一个应用程序,从一个UI切换到另一个UI。

不久之后,用户将能够通过一个界面进行各种不同的工作(完成从撰写年度业务报告到从零开始构建新应用的各种任务),而无需在不同的应用程序或环境之间切换。所说的用户界面将是一个聊天框或一个“上下文窗口(context window)”,您可以通过自然语言在其中提交指令 —— 这正是Prompt Engineering发挥作用的地方。
Prompt Engineering是一种较为花俏的说法,指的是“通过不断改进为AI模型编写的指令,直至实现完全按照用户要求执行”。不过,这不仅仅是文字游戏,而是未来编程的蓝图。
01 编程是一种(“廉价”)商品
“编程是指告诉计算机执行哪些任务以解决问题的技术过程,”Coursera在其网站写道[2]。“我们可以将编程看作是人类和计算机之间的合作,在这种合作中,人类主要制定计算机能够理解的指令(代码)。”
换句话说,编程将计算能力转化为一种商品:一种人们可以用来实现目标的资源。Prompt Engineering是一个将编程过程本身转化为商品的工具。 我们向大语言模型提交一条自然语言指令,它就会为我们编写代码。
假设您想要分析工作中的某个小数据集。通常情况下,您会先开始收集分散在公司云端的数百个CSV文件。然后双击某个Jupyter Notebook,输入几行Python代码,将这些数据编译成一个 data frame。
在此基础上,再施展数据科学的魔力,进行十余次迭代,然后恭喜您:您得到了一系列精美的表格、花哨的图表和基于数据的预测。最后一步是将您六周的工作压缩成 42 张精美的幻灯片,然后在另一款名为 Microsoft PowerPoint 的应用程序上展示出来。
你只需将现成的应用程序与自己编写的代码相结合,就能构建一个运行特定数据分析任务的程序。但如果你要做的只是用简单的自然语言写几条指令呢?
“嘿,AI兄弟,”您可能会这样说。“这里有一个混乱的数据集,是关于我们公司过去五年在巴黎的送货情况。请清理这些混乱数据并运行聚类算法。显示出热力图(heat map)并放大高密度区域。再进行未来两年的预测,利用预测结果优化我们送货车队的每日行程。计算完成后,请生成一份包含清晰图表和简洁注释的报告。请慢慢来!我至少需要离开六个小时。
每当你写下这样的 prompt 时,实际上是在为解决特定问题设计一个应用程序。
这几乎与 Coursera 的描述一致——您与计算机合作以实现目标。唯一的区别是,你使用的不是代码,而是普通的自然语言。好吧,这个 prompt 可能还不够完善,但原则上,这就是您未来与大语言模型互动的样子。
以更具体的例子为例,请看下面这个著名的演示,GPT-4 将一幅手绘草图转化为功能性的HTML代码。

02 Prompt 就是您所需的一切
我们还需要一段时间,才能用一堆巧妙的 prompt 取代数据科学家、和软件工程师。 在此期间,他们可以通过人工智能助手来提高工作效率 —— 而每一个这样的AI助手都将用自然语言进行编程。
与使用Google Workspace、Jupyter Notebook和Microsoft PowerPoint等配套应用程序的捆绑包不同,您将组建一个名为“StatSniffer:您的个人数据科学专家”的助手。
就像当前的ChatGPT PLUS一样,StatSniffer将是一个连接到一系列工具的大语言模型,使其具备浏览文件、运行代码和生成图表等额外功能。我们还可以通过让 StatSniffer 访问研究论文、案例研究和学术教材,为其注入表现顶尖的方法论(top-performing methodologies)。

OpenAI已经在通过GPT store进行自定义AI助手的实验,在这我们可以构建名为GPTs的AI助手。然而,当前的GPTs还比较笨拙。例如,它们容易受到简单越狱攻击(simple jailbreaks)的影响,从而泄漏其“核心指令”。GPTs在与用户进行几次交流后也有恢复到默认模式(GPT-4)的倾向。
这并不令人意外,因为这项技术仍处于起步阶段。随着人工智能研究的不断进步,开源模型的日臻完善,AI助手的生态系统将不断演变,覆盖更多的功能,并提高可靠性。说到这一点,还有很长的路要走。
像规划(planning)和多步推理(multi-step reasoning)等问题仍未得到解决,部分原因是因为在理解物理现实(physical reality)方面,LLMs仍然落后于人类[3] (甚至是猫)。

人们不会过分期望或等待那种能够深入了解量子引力等复杂领域的全自动AI助手,而是更注重对现有AI模型的应用和不断改进。即使是所谓的“愚蠢”LLMs,也能够将我们的效率提高一倍。以下是麦肯锡[4]一项研究的摘录,内容涉及开发人员如何利用 LLMs 加快工作进度。
“我们最新的实证研究发现,基于生成式AI的工具为许多常见的开发任务带来了极大的速度提升。为了可维护性而记录代码功能(考虑代码如何轻松改进)可以在一半的时间内完成,编写新代码只需将近一半的时间,优化现有代码(称为代码重构)只需将近三分之二的时间"。[作者强调]。

这不仅适用于与软件开发相关的任务,同样的模式也适用于大量广泛的企业活动。例如,哈佛商学院(HBS)的研究人员进行了一项研究,评估了为波士顿咨询集团(BCG)的员工配备生成式AI工具的影响。
“对于一组人工智能能力范围内的18个现实中常见的咨询任务,使用人工智能的顾问在生产效率上的表现明显更高(平均完成任务数量增加了12.2%,并且完成任务的速度提高了25.1%),所产生的结果质量也显著提高(与对照组相比,质量提高了 40% 以上),” HBS的研究人员写道。
这些研究为 "人工智能不会取代你,但使用人工智能的人会 "这一陈词滥调提供了新的支持材料。或许一个更高明的说法:“AI不会取代你,但Prompt Engineer会。”
“AI的边界”越大(意味着AI模型可以以高精度执行的任务越多),我们将能够使用 prompt 解决更多问题。这就引出了一个普遍存在的谬论——即能力更强的AI模型需要更少的Prompt Engineering。
03 “Prompt Engineering已死?” 不,它是最新技术
理解大语言模型(LLM)和Prompt Engineering之间关系的一种方式是,将前者想象成一个多元宇宙,而将后者看成一个指针——是的,就像激光指针一样。
当我们向LLM提问时,它会在由大量文档组成的多元宇宙中寻找答案。在每个文档中,都存在一系列可能的答案,LLM会评估每个答案的概率。
Prompt Engineering的目的是指引模型朝着最有可能包含所需答案的宇宙前进,模型会根据 prompt 的指引逐步逼近所需答案,逐步生成符合要求的词语,直到得到最终的答案。
当模型预测每一个 token 时,都会排除数百条不合适的路径,并会逐步缩小范围,直到最终确定出构成最终答案(到达目的地)的一系列词语。

LLM在多元宇宙中航行
然而,这个目的地永远不会相同。即使使用完全相同的 prompt,也几乎永远不会到达完全相同的地方。相反,会落在最相关答案的“邻近区域”。
以下是软件工程师和人工智能研究员弗朗索瓦-乔莱(Fran?ois Chollet,目前在谷歌工作)对此所做的更专业的描述:
如果说 LLM 就像是一个由数百万向量程序(vector programs)组成的数据库,那么 prompt 就像是该数据库中的一个搜索查询(search query)。这个“程序数据库”是连续且可以在不同程序之间进行插值,根据input prompt产生变化——不是由一系列不相关的、分立的程序组成,而是由连续的、相互关联的程序构成。
这就意味着,一个略有不同的 prompt,比如“以x的风格重新表达这段文字”,仍然会指向程序空间(program space)中非常相似的位置,从而导致生成的程序行为上非常接近但并非完全相同。
Prompt Engineering 是在程序空间(program space)中进行的搜索过程,其目的是找到在目标任务中表现最佳的程序。
正如 Chollet 所介绍的,prompt 的目标是为你想要完成的任务调用正确的程序。 很多人陷入的推理陷阱是认为未来的LLM应该能够预测我们希望它们运行哪个程序,即使我们给出的任务不明确。
然而,就像人类一样,即便你雇佣了技术能力最强的工程师,她也无法读懂你的想法。你必须准确地解释你想要什么,否则,你就是在浪费时间和精力。
比方说,你指示一名能力很强的工程师制造一款产品,但你不喜欢她完成的成品。你可以选择更换工程师,也可以修改指令。既然你知道这名工程师能力很强,常识告诉你应该选择第二种方案。
同样,如果能力瞩目的语言模型没有给出你想要的答案,你也不会将其抛弃。不能坐等下一个模型能够读懂你的心思。最合理、最经济有效的方法就是改进你的 prompt。
这就是微软的一个研究团队对 GPT-4 所做的工作。他们没有针对特定使用场景对模型进行微调,而是采用了 Prompt Engineering 技术来提高其性能[5]。
在九个不同的医学场景 benchmarks 中,GPT-4 的准确率提高了最多 9%。因此,该模型的准确率超过了 90%,超过了专门针对医疗领域进行微调的模型。

需要注意的是,微调需要耗费一些额外的资源,比如聘请专家来生产高质量的训练数据,以及重新训练模型所需的计算资源。当然,与预训练(pre-training)相比,微调(fine-tuning)所需的计算资源只是其一小部分,但这仍然是一项额外的成本。
此外,每次对模型进行针对新的专业领域的微调时,都需要投入相同的资源。相比之下,微软开发了一种 prompting 技术,可以提高大语言模型在不同领域的性能:包括电气工程、机器学习、哲学、会计、法律、护理和临床心理学。
另一个能够展现 Prompt Engineering 威力的例子来自Anthropic[6]。他们团队通过在 prompt 中添加一句话,将Claude 2.1模型在信息检索评估(information-retrieval evaluation)中的性能提升到了98%。仅仅是一句话的改变。
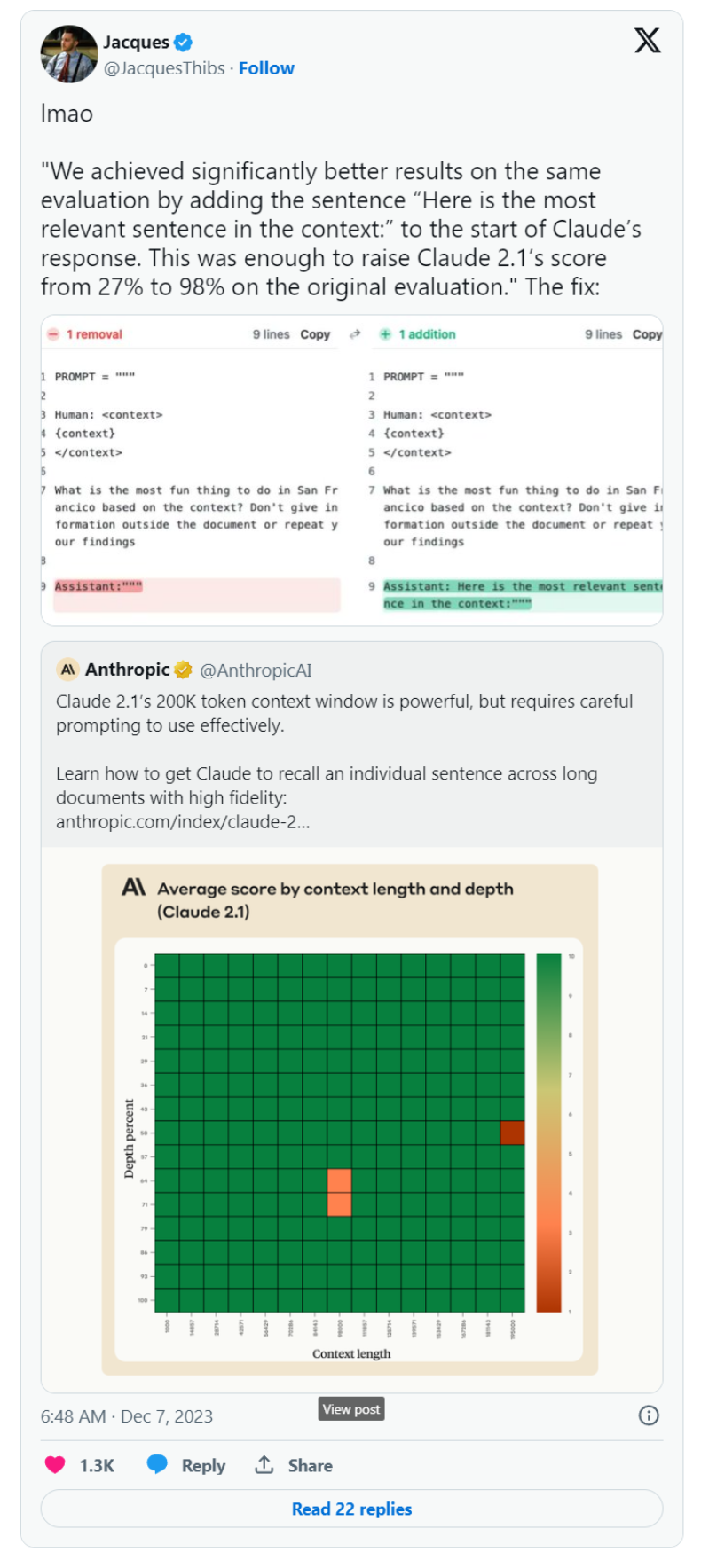
使用 LLM 就像是玩弄一种外星工具。要想知道它能做什么,唯一的办法就是以不同的方式操作它的按钮。当这种外星工具的新版本问世时,你会期望它有更多的功能,但也会有更多的按钮出现。
天真的想法是“能力越强的模型需要越少的prompt”。实际上,模型越强大,通过正确的 prompt 就能解锁更多的功能。
04 是时候大显身手了,human agent!
长期来看,通过将 LLM 作为操作系统,我们可以利用其强大的计算能力和自然语言处理能力来解决各种问题。在中期阶段,需要编写 AI Agent 来执行一些以前需要我们编写代码才能完成的任务。在这两个阶段,我们都将使用自然语言作为主要的编程语言。
好吧,但现在怎么办?
在 AI Agent 赶上之前,是你大显身手的时候了。把自己想象成一个技术工匠,将AI模型、代码和传统应用程序结合起来,应对复杂的挑战。可以说,将像搭乐高一样,而且由于开源社区的存在,你将有无尽的积木可以组合,创造新的项目。
LLM 是这个假想乐高中的特殊部件,因为你的创作通常会以它为中心。Prompt Engineering 这个概念有两个互补的含义。
请看,两个含义[7]分别如下:(1)为LLM编写高质量的自然语言指令,(2)在LLM上编写代码,使用 conditional prompting 和其他技术来改进其输出。
第二个定义包含了第一个定义,因为即使在 LLM 上编写代码,你仍然是用自然语言与它进行交互。
- 将 LLM 作为一个独立程序来使用:在这里,我们可以用自然语言编写高质量的 prompt,以获得最佳输出。例如创意生成、文档摘要和代码编写。
- 将 LLM 作为程序的一部分来使用:在这种情况下,我们可以编写基于 LLM 的软件(使用 Python、Java、C++ 或其他编程语言),以完成特定任务。例如,社交媒体评论的情感分析、Chatbots和autonomous agents。
现在,让我们来探讨一下 Prompt Engineering 在每个使用场景中的表现。
4.1 1?? 将 LLM 作为一个独立程序来使用所需的Prompt Engineering
LLMs 最常见的使用情况是通过 ChatGPT 和 Bard 等网页界面与之交互。
根据我们的具体需求,可以建立一个个人 prompt 库。希望这些 prompt 是模板化的,且易于更新。这样一来,我们就不必从头开始重写 prompt,也不必每次都在聊天记录中搜索 prompt。
以下是三个不同的 prompt 示例,也许会对您有所启发:
[PROMPT TEMPLATE #1 DOCUMENT SUMMARY]
Act like a research assistant in the field of <field_name>.
I will give you a report titled <title_of_the_report> as input.
Please access the report through the following link <URL_of_the_report> using the online browsing feature.
Summarize the report in less than <summary_wordcount> and add <number_of_quotes> from the authors.
Make sure to pick precise quotes and list them as bullet points.
##
Desired format:
Title: <title_of_the_report>
Link: <URL_of_the_report>
Summary of the report based on the previous instructions.
- Quote #1
- Quote #2
- Quote #3
- etc.
##
Inputs:
<field_name> = Placeholder for the field of expertise of your document.
<title_of_the_report> = Placeholder for the title of the report you want summarize.
<URL_of_the_report> = Placeholder for web address where the report can be found.
<summary_wordcount> = Placeholder for the maximum word count for the summary.
<number_of_quotes> = Placeholder for the number of quotes to be extracted from the report.
[PROMPT TEMPLATE #2 PRODUCT DESCRIPTION]
Act like an expert copywriter.
##
Role:
Write a product description for an e-commerce shop.
Use the following structure and fill in the details based on the placeholders provided:
Product Name: <product_name>
Introduction: Start with a captivating opening sentence about <product_name>, suitable for <target_audience>.
Key Features: List the main features of <product_name>. Include <product_features>.
Benefits: Explain how <product_name> benefits the user, addressing <target_audience> needs.
Call to Action: Encourage the reader to make a purchase decision with a compelling call-to-action.
SEO Keywords: Integrate <seo_keywords> naturally within the text for SEO purposes.
Tone: Maintain a <brand_tone> throughout the description to align with the brand's voice.
##
Inputs:
<product_name> = Placeholder for the name of the product.
<product_features> = Placeholder for listing the specific features of the product.
<target_audience> = Placeholder to specify the target audience or demographic for the product.
<seo_keywords> = Placeholder for SEO-optimized keywords relevant to the product.
<brand_tone> = Placeholder to define the brand's tone of voice to be reflected in the product description.
[PROMPT TEMPLATE #3 PROGRAMMING ASSISTANT]
Act like a software engineer.
##
Role:
Your role is to write a program in <programming_language>.
Your program must follow these instructions: <user_instructions>.
Reason step by step to make sure you understand the user's instructions before you generate the code.
Ensure the code is clear, well-commented, and adheres to best practices in <programming_language>.
##
Format:
Give a clear title to each code snippet you generate.
For example you can title the first snippet "Snippet #1 version 1," the second snippet "Snippet #2 version 1," and an updated version of the second snippet can be "Snippet #2 version 2."
##
Inputs:
<programming_language> = Placeholder for the programming language in which you want the code to be written (e.g., Python, JavaScript).
<user_instructions> = Placeholder for the specific instructions or description of the task you want to be turned into code.
4.2 2?? 将 LLM 作为程序的一部分来使用所需的Prompt Engineering
在这种情况下,可以将 LLMs 作为可调用的函数来处理、分析和生成自然语言。
例如,通过编写代码调用 LLM 来分析与给定产品相关的一系列评论的情感。处理完这些评论之后,可以使用另一个依赖 LLM 的函数,根据之前的结果生成回复。
现在,让我们来看看如何在代码中嵌入 LLM。有三种主要方法:
- 通过其他公司提供的 API 进行连接;
- 使用公司内网的本地服务器;
- 直接在个人计算机上安装开源LLM。
下面是一个如何在程序中使用 LLM 的基本示例:
# Objective: Carry out a sentiment analysis on a series of comments stored in an Excel file
# LLM choice: We'll use OpenAI API to call the gpt-4 model
import pandas as pd # version used 2.1.3
from openai import OpenAI # version used 1.2.0
# Define the path to your API key file
API_key_path = "C:/Users/.....API_Key.txt" # Replace with your actual API key file path
# Read the API key from the file
with open(API_key_path, 'r') as file:
API_key = file.read().strip() # .strip() removes any leading/trailing whitespace
# Create the OpenAI client object with the API key
client = OpenAI(api_key=API_key)
# Define a function that analyzes sentiment in a series of comments stored in an Excel file
def analyze_sentiments(input_file):
# Read the input Excel file
inputs_df = pd.read_excel(input_file)
# Select the column by its name 'comments'
if 'comments' in inputs_df.columns:
comments = inputs_df['comments']
else:
raise ValueError("Column 'comments' not found in the input file")
sentiments = []
for comment in comments:
# Prepare API call
messages = [
{
"role": "system",
"content": "Analyze the sentiment of the following comment. Use a single word to describe the sentiment. Either `Positive` or `Negative`. Refrain from writing any extra text. Thanks!", },
{
"role": "user",
"content": comment,
}
]
model = "gpt-4"
temperature = 1.0
max_tokens= 100 # Adjust based on expected response length
# Make the API call
chat_completion = client.chat.completions.create(
model=model,
temperature=temperature,
max_tokens= max_tokens,
messages=messages
)
# Extract response
if chat_completion.choices:
sentiment_result = chat_completion.choices[0].message.content.strip()
else:
sentiment_result = "No response"
sentiments.append(sentiment_result)
# Combine comments with their sentiments
result_df = pd.DataFrame({
'Comment': comments,
'Sentiment': sentiments
})
# Write to a new Excel file
output_file = "path_to_your_output_file.xlsx" # Replace with your desired output file path
result_df.to_excel(output_file, index=False)
print("Sentiment analysis complete. Results saved to", output_file)
# Example usage
input_file = "path_to_your_input_file.xlsx" # Replace with your input file path
analyze_sentiments(input_file)
# Homework exercice: Write a function that uses a dynamic prompt to write a different response based on the result of sentiment analysis
05 如何增强我们的 Prompt Engineering 技能
简而言之,我从斯蒂芬-金(Stephen King)那里偷来了一句优雅的名言。 “在所有事情中,你必须做两件事,” 他说。 “多读书,多写作。”
就像写作一样,Prompt Engineering 在我们坐下来敲击键盘之前似乎很容易。由于我们使用自然语言来编写 prompt ,所以我们会有一种错误的简单感。
请原谅我在此重复,目前人工智能模型无法读懂我们的想法。
如果想获得高质量的回复,就必须学会尽可能清晰地表达自己的意图。要不断阅读文献,学习新的技术,并尽可能多地重复,将它们融会贯通。
您可能会厌倦在闪烁的上下文窗口中随意输入指令。解药就是寻找难题来解决。如何使输出的部分内容随机化?如何动态改变 prompt 内容?您是否能编写一个能够抵抗越狱行为的助手?
只要找到难以解决的问题,Prompt Engineering 将从“您必须学会的技能”变成每日“充满喜悦(但有时令人沮丧)的智力刺激”。
此外,还有另外两个值得关注的内容:机器学习(Machine Learning)和深度学习(Deep Learning)。需要探索它们的优点和缺点,因为一旦我们了解了生成式人工智能背后的技术原理,就会对模型为什么会有某些行为产生直觉。
以下是一些可以帮助您入门的资源:
- Making Friends of Machine Learning by Cassie Kozyrkov. (Series of YouTube videos)[8]
- Intro to Large Language Models by Andrej Karpathy. (YouTube video)[9]
- Prompt Engineering for Developers by Isa Fulford and Andrew Ng (Free online course)[10]
- How to Write Expert Prompts for LLMs by this bald dude (Full 16,000-word guide that includes 25+ prompting techniques, examples, and commentary).[11]
在此免费订阅原文作者的substack: https://nabilalouani.substack.com
在 Linkedin 上联系原文作者: https://www.linkedin.com/in/nabil-alouani/
Thanks for reading!
END
参考资料
[1]https://karpathy.ai/
[2]https://www.coursera.org/articles/what-is-programming
[3]https://nabilalouani.substack.com/p/chatgpt-hype-is-proof-nobody-really
[4]https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/unleashing-developer-productivity-with-generative-ai#/
[5]https://arxiv.org/abs/2311.16452
[6]https://www.anthropic.com/index/claude-2-1-prompting
[7]https://simonwillison.net/2023/Feb/21/in-defense-of-prompt-engineering/
[8]https://www.youtube.com/watch?v=lKXv19eRLZg&list=PLRKtJ4IpxJpDxl0NTvNYQWKCYzHNuy2xG&ab_channel=CassieKozyrkov
[9]https://www.youtube.com/watch?v=zjkBMFhNj_g&ab_channel=AndrejKarpathy
[10]https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
[11]https://towardsdatascience.com/how-to-write-expert-prompts-for-chatgpt-gpt-4-and-other-language-models-23133dc85550?sk=49c4528973c462c1c6d3d28cc29855fe
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/prompt-engineering-could-be-the-hottest-programming-language-of-2024-heres-why-a9ccf4ba8d49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!