字符编码转换
宽窄字符和字符编码的关系
多字节(窄)字符:在C/C++中,char是一种数据类型,规定sizeof(char)=1,即一个char占用一个字节,1Byte=8bit。并没有规定一个char就要与ASCII对应,不过,通常情况下char值与ASCII编码对应。
宽字符:标准并没有规定wchar_t占多少位,标准只是要求一个wchar_t可以表示任何系统所能认识的字符,在win32 中,wchar_t为16位;Linux中是32位。
wchar_t同样没有规定编码,一个wchar_t可以不同的编码表示,不过鉴于UTF16正好是两个字节,且为通用编码方式,所以通常情况下将wchar_t与uinicode编码对应。在 win32中,wchar_t的编码是UCS-2BE(utf16BE);而Linux中是UTF-32BE(等价于UCS-4BE)。
如果想明确声明使用两个字节大小的类型存储UTF-16编码字符,可使用C++提供的另一个宽字符类型char16_t。
char16_t和wchar_t是两种表示宽字符的数据类型,其在不同的编译器和平台下可能有不同的实现和用途。
char16_t: 是C++11引入的数据类型,用于表示16位宽字符,常用于存储UTF-16编码字符。在大多数平台上,它是确切的16位宽字符类型,每个字符占用2个字节。这种数据类型适用于处理Unicode字符,并且可以使用u""前缀来定义UTF-16编码的字符串字面量。
wchar_t: 是用于表示宽字符的数据类型,其宽度在不同的平台和编译器下可能不同。在Windows平台和Visual C++编译器中,wchar_t通常表示16位宽字符,用于存储UTF-16编码的字符。而在其他平台(Linux)和编译器中,wchar_t通常表示32位宽字符,用于存储UTF-32编码的字符。wchar_t一般用于处理宽字符数据,如文件路径、系统命令等。
所以,char16_t和wchar_t的区别主要在于它们的宽度和使用的场景。char16_t固定为16位,主要用于存储UTF-16编码字符;而wchar_t的宽度可能是16位或32位,用于不同平台和编译器下的宽字符处理。
在使用这两个数据类型时,需要注意平台和编译器的不同实现,以及与其他代码/库的兼容性,在Windows系统下,char16_t和wchar_t都占两个字节(16位)大小。但是,为了避免混淆和错误,建议在代码中明确指定所使用的字符编码和数据类型,以确保程序在不同环境中的正确性。
因此后续会使用char16_t存储UTF-16编码的内容
UTF-16BE、UTF-16LE、UTF-16 三者之间的区别。
用两个字节表示必然存在字节序的问题,即大端小端的问题,因此UTF-16后缀就是大小端的意思了。
UTF-16BE,其后缀是 BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示。
UTF-16LE,其后缀是 LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示。
UTF-16,没有指定后缀,即不知道其是大小端,所以其开始的两个字节表示该字节数组是大端还是小端。即FE FF表示大端,FF FE表示小端。
宽窄字符的转换
首先介绍下如何声明各种编码字符串常量:
char ch_ansi[] = "ABC这是一个测试文本123"; //取决于系统默认编码,简体系统为GBK,繁体系统为BIG5
char ch_utf8[] = u8"ABC这是一个测试文本123"; //明确这是一个UTF-8编码的字符串常量
char16_t ch16_utf16[] = u"ABC这是一个测试文本123"; //明确这是一个UTF-16编码的字符串常量,且存储在16位的宽字符数组中
wchar_t wch_utf16[] = L"ABC这是一个测试文本123"; //声明了一个宽字符编码的字符串常量,具体宽度可能是16位(UTF-16,Windows)或32位(UTF-32,Linux)
u"“前缀和L”"前缀是用于定义字符串字面量的前缀,在C++中有不同的含义和用途。
u"“前缀:u”"前缀表示引号内的字符串是以UTF-16编码的宽字符字符串。它用于定义UTF-16字符串字面量,其中每个字符通常占用2个字节。这种前缀主要用于支持Unicode字符集,并且适用于处理宽字符数据。例如,u"你好"定义了一个UTF-16编码的字符串字面量。
L"“前缀:L”“前缀表示引号内的字符串是以宽字符编码的字符串。它的宽度可能是平台和编译器相关的,可能是16位(UTF-16)或32位(UTF-32)。L”"前缀的主要目的是用于处理宽字符数据,例如文件路径、系统命令等。例如,L"Hello"定义了一个宽字符编码的字符串字面量。
总结来说,u"“前缀表示UTF-16编码的宽字符字符串,L”"前缀表示宽字符编码的字符串。它们的使用取决于编译器和平台的实现,并且在处理宽字符数据时起到重要的作用。
注意:不能使用char16_t接收L"“前缀声明的字符串常量,同样不能使用char16_t存储u”"前缀声明的字符串常量:
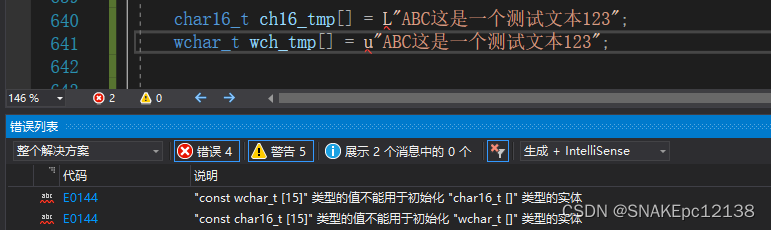
回到正题,对于宽窄字符的转换,这里有两种转换方式:
一种是保持原有字符编码不变,仅进行宽窄字符类型的转换。
另一种是即进行宽窄字符类型的转换,也进行字符编码的转换。
保持原编码转换:只转换类型,不转换编码
char*、char16_t*、wchar* 、UTF-16 等存储的都是二进制数据,不涉及字符编码,因此是能够在不改变字符编码的情况下进行相互转换的。
char* 转 char16_t*
示例:
char ch_ansi[] = "ABC这是一个测试文本123";
//char* 转 char16_t*
size_t srcLen = strlen(ch_ansi);
size_t wideLen = srcLen / 2;
char16_t* wideStr = new char16_t[wideLen + 1];
for (int i = 0; i < wideLen; i++)
{
reinterpret_cast<char*>(&wideStr[i])[0] = ch_ansi[i * 2];
reinterpret_cast<char*>(&wideStr[i])[1] = ch_ansi[i * 2 + 1];
}
wideStr[wideLen] = u'\0';
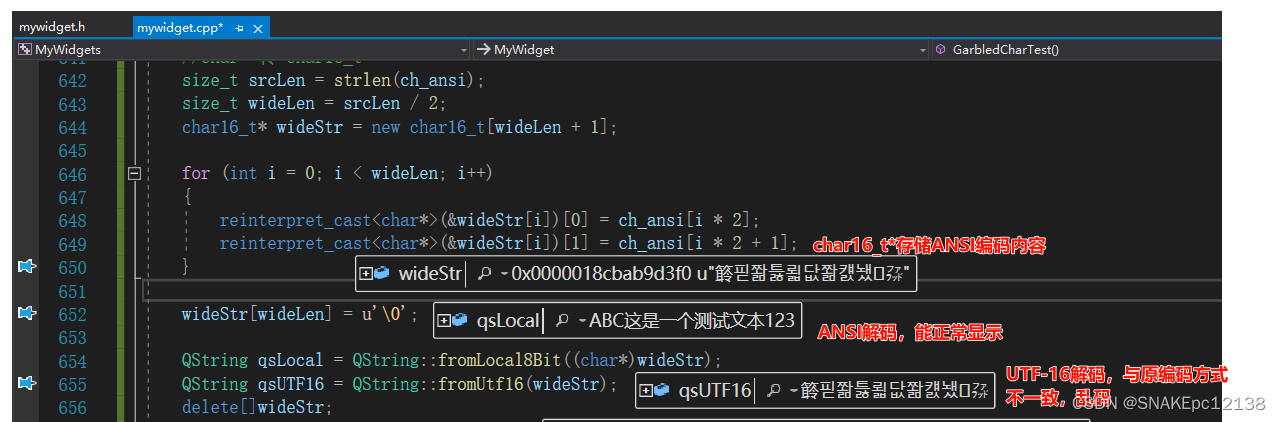
QString qsLocal = QString::fromLocal8Bit((char*)wideStr);
QString qsUTF16 = QString::fromUtf16(wideStr);
delete[]wideStr;
解码结果:
在这段代码中,reinterpret_cast<char*>(&wideString[i])将wchar_t类型的指针&wideString[i]转换为char类型的指针。这样做是为了访问wchar_t类型的指针所指向的内存,并按字节存储到char类型的指针中。
然后,[0]表示通过char类型的指针获取指针所指向的第一个字节的值。因为UTF-16编码的字符由两个字节组成,所以通过reinterpret_cast<char>(&wideString[i])[0]可以获取到UTF-16字符的第一个字节。
在循环中,我们将每个UTF-16编码的字符拆分为两个字节,并分别存储到char*数组中。拆分过程中,使用[0]和[1]分别获取两个字节的值,并存储到对应的位置上。
为什么使用reinterpret_cast而不是static_cast或dynamic_cast
在上述代码中,使用reinterpret_cast而不是static_cast或dynamic_cast是因为需要进行指针类型之间的转换,而不是从一个类层次结构中进行类型转换。
reinterpret_cast是最强大的类型转换操作符,可以在指针类型之间进行任意的转换。它不进行任何运行时的类型检查,而是仅仅对二进制数据进行重新解释。
而static_cast用于在静态类型转换中,包括基本类型的转换,指针或引用之间的上下转换以及类之间的上下转换。但它不能用于没有直接或间接转换关系的类型之间的转换,也不能用于指针类型的底层二进制表示的转换。
同样,dynamic_cast主要用于在具有多态关系的类之间进行类型转换,而不是用于指针类型的底层二进制表示的转换。
在这种情况下,我们需要将wchar_t类型的指针转换为char类型的指针,以进行字节级别的内存操作。由于这两种指针类型之间没有直接的转换关系,也没有多态关系,因此使用reinterpret_cast是最合适的选择。*
直接使用强制类型转换也可以,但不推荐:
char16_t* pCh16 = (char16_t*)ch_ansi;
QString qsLocal_2 = QString::fromLocal8Bit((char*)pCh16);
QString qsUTF16_2 = QString::fromUtf16(pCh16);
解码结果:

这段代码直接将wideString数组指针的类型直接转换为char*类型,而不是对数组中的每个元素进行单独的字节拆分和转换,这会使pCH16按照宽字符的内存布局来处理数据。
char* 转 wchar_t*
示例:
//char* 转 wchar_t*
char ch_ansi[] = "ABC这是一个测试文本123";
size_t srcLen = strlen(ch_ansi);
size_t wideLen = srcLen / 2;
wchar_t* wideStr = new wchar_t[wideLen + 1];
for (int i = 0; i < wideLen; i++)
{
reinterpret_cast<char*>(&wideStr[i])[0] = ch_ansi[i * 2];
reinterpret_cast<char*>(&wideStr[i])[1] = ch_ansi[i * 2 + 1];
}
wideStr[wideLen] = L'\0';
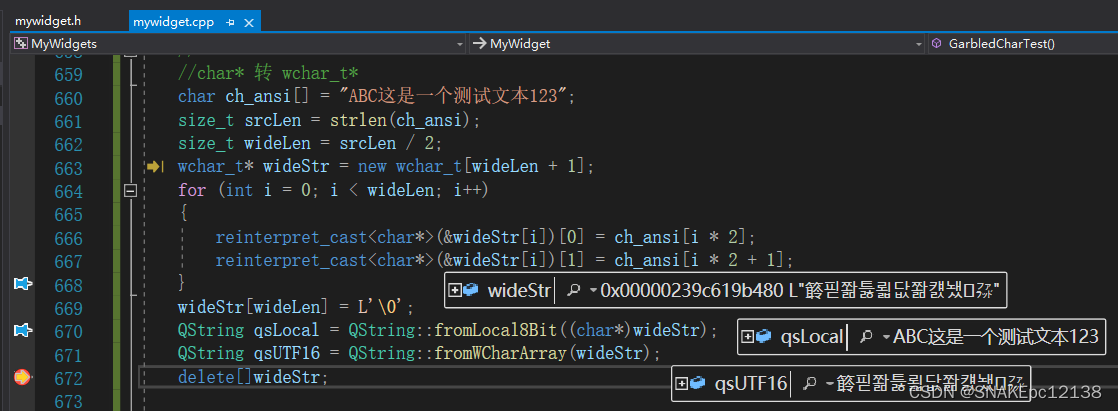
QString qsLocal = QString::fromLocal8Bit((char*)wideStr);
QString qsUTF16 = QString::fromWCharArray(wideStr);
delete[]wideStr;
解码结果:
char16_t* 转 char*
示例:
//char16_t* 转 char*,已测试可行
char16_t ch16_utf16[] = u"SOP这是一个宽字符测试文本456"; // UTF-16编码的字符串
// 计算UTF-16编码字符串的长度
int length = std::char_traits<char16_t>::length(ch16_utf16);
// 计算转换后的char*所需的长度 (每个UTF-16字符需要2个字节)
int charArrayLength = length * 2;
// 创建用于存储转换后的char*的缓冲区
char* charArray = new char[charArrayLength + 1]; // 需要添加额外的终止空字符
// 将UTF-16编码的字符串转换为char*
for (int i = 0; i < length; i++)
{
charArray[i * 2] = reinterpret_cast<char*>(&ch16_utf16[i])[0]; // 高位字节
charArray[i * 2 + 1] = reinterpret_cast<char*>(&ch16_utf16[i])[1]; // 低位字节
}
charArray[charArrayLength] = '\0'; // 添加终止空字符
QString qsLocal = QString::fromLocal8Bit(charArray);
QString qsUtf16 = QString::fromWCharArray((wchar_t*)charArray);
QString qsUtf16_2 = QString::fromUtf16((char16_t*)charArray);
// 释放分配的内存
delete[] charArray;
解码结果:

char16_t* 转 wchar_t*
示例:
//char16_t* 转 wchar_t*
char16_t ch16_utf16[] = u"SOP这是一个宽字符测试文本456";
std::wstring result;
for (int i = 0; ch16_utf16[i] != u'\0'; ++i)
{
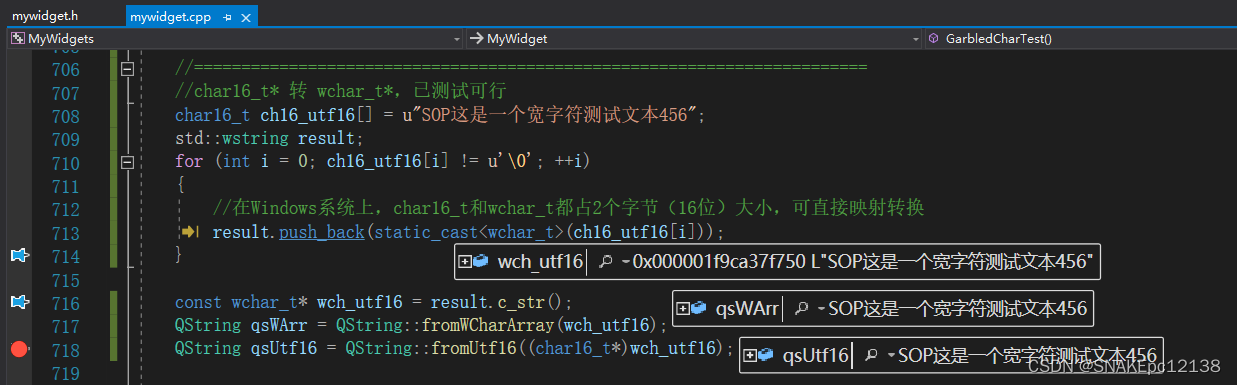
result.push_back(static_cast<wchar_t>(ch16_utf16[i]));
}
const wchar_t* wch_utf16 = result.c_str();
将UTF-16编码的char16_t数组转换为wchar_t时,相当于将UTF-16编码直接存储在wchar_t中,因为它们的大小和编码方式相匹配。所以可以理解为使用wchar_t*存储UTF-16编码的内容。
解码结果:
但在Linux系统上,将UTF-16编码的char16_t数组转换为wchar_t后,并不能直接理解为使用wchar_t存储UTF-16编码的内容。
在Linux系统上,wchar_t的大小通常是4个字节,与UTF-32编码中每个字符的大小相匹配。而UTF-16编码中每个字符的大小是2个字节。
如果您将UTF-16编码的char16_t数组直接转换为wchar_t*,会导致字符编码不匹配。因为在Linux系统上,wchar_t*所表示的是UTF-32编码的内容,而不是UTF-16编码的内容。
wchar_t* 转 char*
示例:
//wchar_t* 转 char*,已测试可行
wchar_t wideString[] = L"SOP这是一个宽字符测试文本456"; // UTF-16编码的wchar_t数组
// 获取宽字符数组的长度
int length = wcslen(wideString);
// 创建存储UTF-16编码字符的char数组
char* narrowString = new char[length * 2 + 1]; // 每个UTF-16字符由两个字节组成
// 将UTF-16编码的wchar_t*数组转换为char*数组
for (int i = 0; i < length; i++) {
narrowString[i * 2] = reinterpret_cast<char*>(&wideString[i])[0];
narrowString[i * 2 + 1] = reinterpret_cast<char*>(&wideString[i])[1];
}
narrowString[length * 2] = '\0'; // 添加字符串结束符
QString qsWArr = QString::fromWCharArray((wchar_t*)narrowString);
QString qsUtf16 = QString::fromUtf16((char16_t*)narrowString);
// 释放内存
delete[] narrowString;
解码结果:
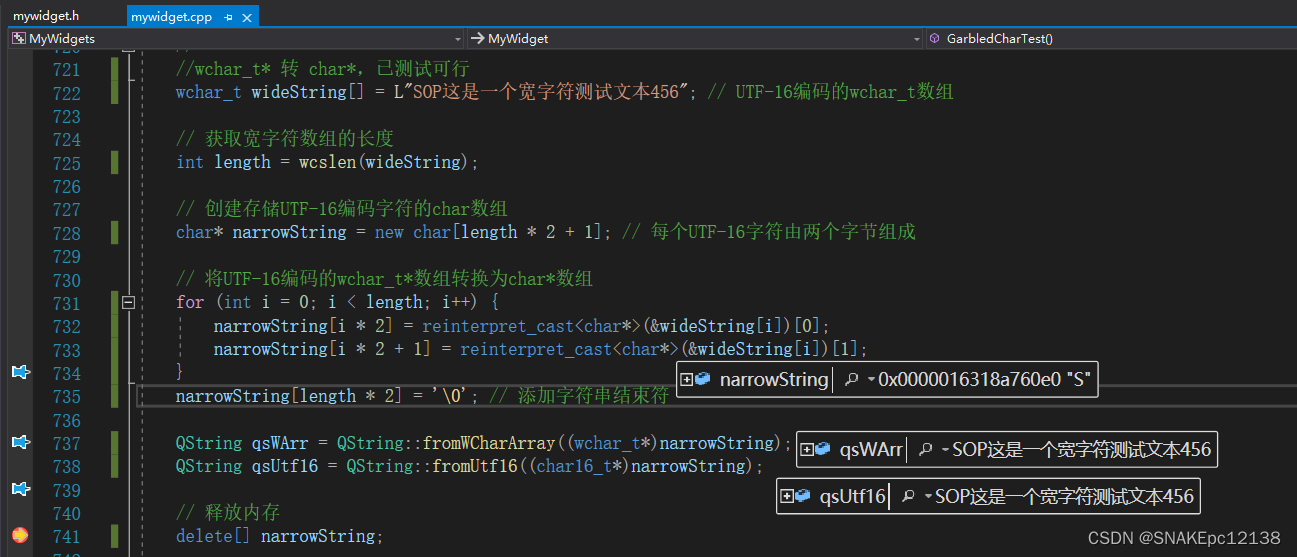
wchar_t* 转 char16_t*
在Windows系统上, 将UTF-16编码的wchar_t数组转换为char16_t后,可以理解为使用char16_t存储UTF-16编码的内容。
//wchar_t* 转 char16_t*
wchar_t wch_utf16[] = L"SOP这是一个宽字符测试文本456"; // UTF-16编码的宽字符数组
// 计算宽字符数组的长度
int wideLength = wcslen(wch_utf16);
// 计算转换后的char16_t*所需的长度 (每个宽字符字符需要2个字节)
int charArrayLength = wideLength;
// 创建用于存储转换后的char16_t*的缓冲区
char16_t* char16Array = new char16_t[charArrayLength + 1]; // 需要添加额外的终止空字符
// 将宽字符数组转换为char16_t*
for (int i = 0; i < wideLength; i++) {
char16Array[i] = static_cast<char16_t>(wch_utf16[i]);
}
char16Array[charArrayLength] = u'\0';
QString qsWArr = QString::fromWCharArray((wchar_t*)char16Array);
QString qsUTF16 = QString::fromUtf16(char16Array);tf16(char16Array);
// 释放分配的内存
delete[] char16Array;
解码结果:
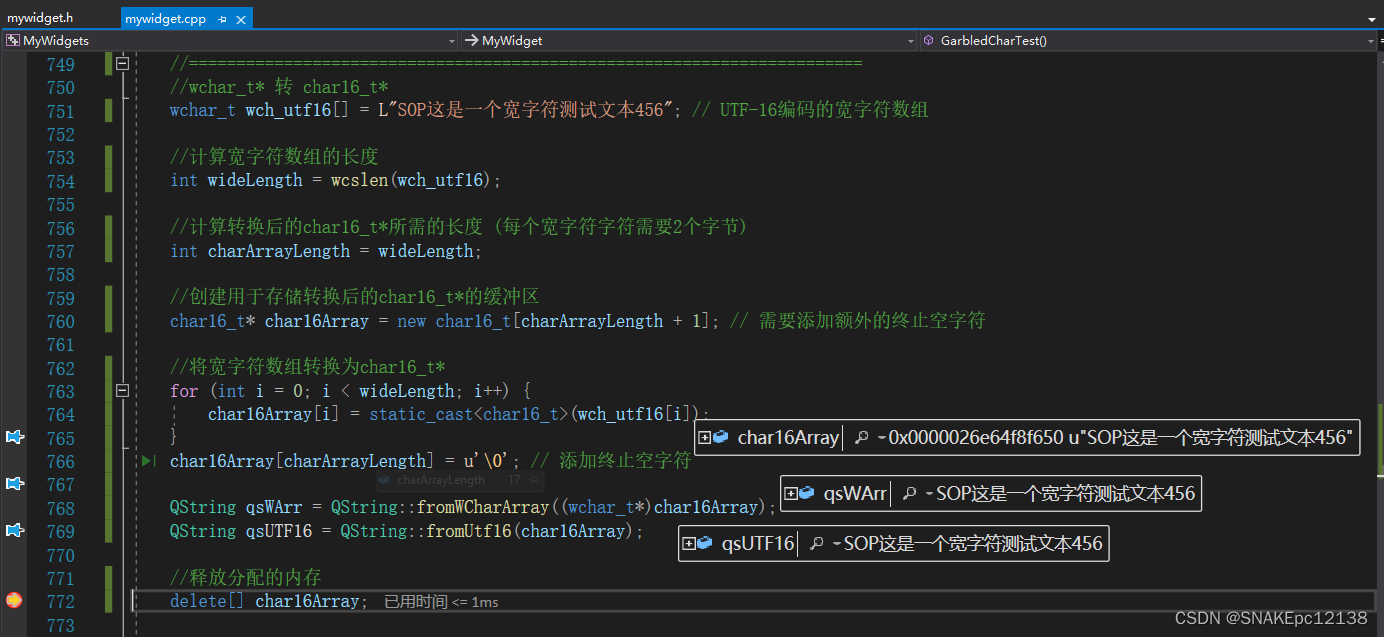
同样在Linux系统上,将wchar_t数组转换为char16_t时,不能直接理解为使用char16_t存储UTF-32编码的内容。这是因为wchar_t和char16_t是不同的数据类型,它们在内存中使用的字节数不同。
小结
本质上,所有字符类型容器存储的都是二进制数据,这些二进制的编码可以是任何字符编码,至于怎么解析这些二进制数据,其值代表什么字符,怎么显示给你看的,就是解码的过程了。
只要清楚源数据的字符编码,无论使用何种容器存储,只能能使用相应的编码方式解码,就一定不会有乱码问题。
字符编码转换:既转换类型,也转换编码
宽字符转多字节字符
WideCharToMultiByte
WideCharToMultiByte是Windows API中的一个函数,用于将宽字符字符串(UTF-16或UCS-2编码)转换为多字节字符字符串(例如ASCII或UTF-8编码)。它通常在需要支持多种字符编码的Windows应用程序中使用。
原型如下:
#include <Windows.h>
int WideCharToMultiByte(
UINT CodePage, // 字符编码标识符
DWORD dwFlags, // 标志位
LPCWCH lpWideCharStr, // 宽字符字符串地址
int cchWideChar, // 宽字符字符串长度
LPSTR lpMultiByteStr, // 多字节字符字符串地址
int cbMultiByte, // 多字节字符字符串长度
LPCCH lpDefaultChar, // 默认字符
LPBOOL lpUsedDefaultChar // 指向布尔值的指针,用于指示是否使用了默认字符
);
注意:WideCharToMultiByte的CodePage参数用于指定目标字符编码。它表示将要转换成的多字节字符的编码方式。即这个参数的值决定了将宽字符转换为多字节字符时所使用的字符集。
#include <Windows.h>
#include <string>
// 宽字符转多字节字符
std::string WideCharToMultiByteWithAcp(const wchar_t* wideStr, UINT codePage)
{
int bufferSize = WideCharToMultiByte(codePage, 0, wideStr, -1, nullptr, 0, nullptr, nullptr);
if (bufferSize == 0)
{
// 转换失败
return "";
}
std::string multiStr(bufferSize, '\0');
if (WideCharToMultiByte(codePage, 0, wideStr, -1, &multiStr[0], bufferSize, nullptr, nullptr) == 0)
{
// 转换失败
return "";
}
return multiStr;
}
codePage参数是用来指定字符编码的参数,其中不同的值代表不同的字符编码。以下是一些常用的codePage值及其对应的字符编码:
CP_ACP(常用):系统默认的 Windows ANSI 代码页。简体-GBK,繁体-BIG5
CP_MACCP:当前系统 Macintosh 代码页。
CP_OEMCP:当前系统 OEM 代码页。
CP_SYMBOL:Windows 2000: 符号代码页 (42) 。
CP_THREAD_ACP:Windows 2000: 当前线程的 Windows ANSI 代码页。
CP_UTF7:UTF-7。 仅当受 7 位传输机制强制使用此值。 最好使用 UTF-8。 设置此值后, 必须将 lpDefaultChar 和 lpUsedDefaultChar 设置为 NULL。
CP_UTF8(常用):UTF-8。 设置此值后, 必须将 lpDefaultChar 和 lpUsedDefaultChar 设置为 NULL。
测试示例:
char16_t ch16_utf16[] = u"这是一个UTF-16编码的测试文本";
wchar_t wch_utf16[] = L"在Windows系统上,这是一个UTF-16编码的测试文本";
//接口测试
// 测试环境:Windows系统,CodePage: 936 简体中文 - GB2312//WideCharToMultiByte & MultiByteToWideChar
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 UTF-8编码的多字节
std::string sUtf8_fromWCH = WideCharToMultiByteWithAcp(wch_utf16, CP_UTF8);
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sGB2312_fromWCH = WideCharToMultiByteWithAcp(wch_utf16, CP_ACP);
//UTF-16编码的宽字符 转 UTF-8编码的多字节
std::string sUTF8_fromCh16 = WideCharToMultiByteWithAcp((wchar_t*)ch16_utf16, CP_UTF8);
//UTF-16编码的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sGB2312_fromCh16 = WideCharToMultiByteWithAcp((wchar_t*)ch16_utf16, CP_ACP);
测试结果:

优点:
可指定转换时的编码
缺点:
Windows接口,不能跨平台
W2A
W2A宏是特定于Windows平台的,依赖于MFC库。
W2A定义如下:
//atlconv.h
#define W2A(lpw) (\
((_lpw = lpw) == NULL) ? NULL : (\
(_convert = (static_cast<int>(wcslen(_lpw))+1), \
(_convert>INT_MAX/2) ? NULL : \
ATLW2AHELPER((LPSTR) alloca(_convert*sizeof(WCHAR)), _lpw, _convert*sizeof(WCHAR), _acp))))
#define ATLW2AHELPER AtlW2AHelper
_Ret_maybenull_z_ _Post_writable_byte_size_(nChars) inline LPSTR WINAPI AtlW2AHelper(
_Out_writes_opt_z_(nChars) LPSTR lpa,
_In_opt_z_ LPCWSTR lpw,
_In_ int nChars) throw()
{
return AtlW2AHelper(lpa, lpw, nChars, CP_ACP);
}
ATLPREFAST_SUPPRESS(6054)
_Ret_maybenull_z_ _Post_writable_byte_size_(nChars) inline LPSTR WINAPI AtlW2AHelper(
_Out_writes_opt_z_(nChars) LPSTR lpa,
_In_opt_z_ LPCWSTR lpw,
_In_ int nChars,
_In_ UINT acp) throw()
{
ATLASSERT(lpw != NULL);
ATLASSERT(lpa != NULL);
if (lpa == NULL || lpw == NULL)
return NULL;
// verify that no illegal character present
// since lpa was allocated based on the size of lpw
// don't worry about the number of chars
*lpa = '\0';
int ret = WideCharToMultiByte(acp, 0, lpw, -1, lpa, nChars, NULL, NULL);
if(ret == 0)
{
ATLASSERT(FALSE);
return NULL;
}
return lpa;
}
ATLPREFAST_UNSUPPRESS()
可以看到W2A宏也是使用Windows接口WideCharToMultiByte进行宽字符到多字节字符的转换,因此使用W2A时,还需要包含Windows.h头文件:
#include <Windows.h>
需要注意的是,使用W2A宏进行字符串转换时,会使用系统默认的字符编码(CP_ACP)进行转换。如果需要使用其他字符编码进行转换,可以使用上面用WideCharToMultiByte实现的转换函数并指定相应的字符编码。
这里使用alloca在在W2A宏函数所在的作用域内的栈上分配内存,无需再手动释放内存!
自定义转换接口如下:
std::string WToA(const wchar_t* wideStr)
{
USES_CONVERSION;
return std::string(W2A(wideStr));
}
测试示例:
//W2A & A2W : 默认使用系统默认编码转换,不支持指定转换编码
char16_t ch16_utf16[] = u"这是一个UTF-16编码的测试文本";
wchar_t wch_utf16[] = L"在Windows系统上,这是一个UTF-16编码的测试文本";
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sAnsi_fromWCH = WToA(wch_utf16);
//UTF-16编码的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sAnsi_fromCH16 = WToA((wchar_t*)ch16_utf16);
测试结果:
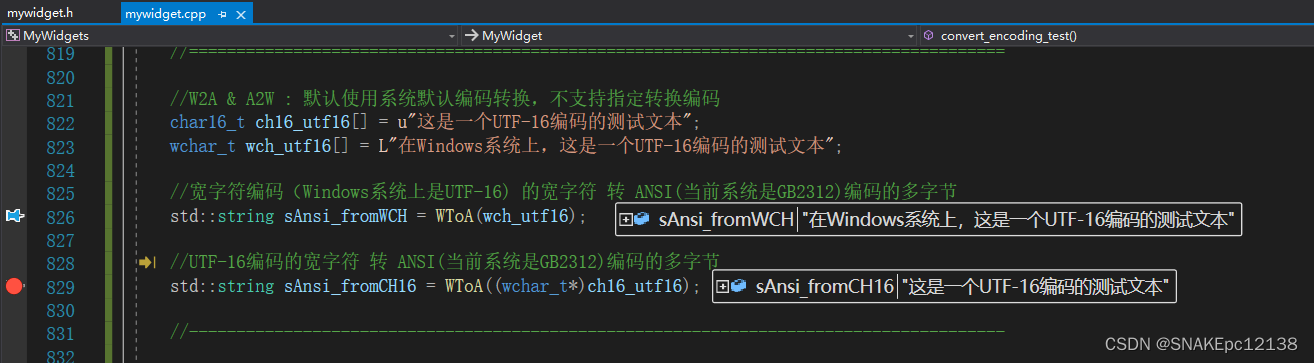
不能指定编码,且不能跨平台,直接拉黑。
wcstombs
wcstombs 是一个 C/C++ 标准库函数,用于将宽字符字符串(wchar_t 类型)转换为多字节字符串(char 类型)。
函数原型:
size_t wcstombs(char* dest, const wchar_t* src, size_t destSize);
//dest:指向目标多字节字符串的指针,用于存储转换后的结果。
//src:指向源宽字符字符串的指针,要进行转换的字符串。
//destSize:目标多字节字符串的最大长度,包括终止符 \0。
//返回值:
//如果转换成功,则返回转换后的多字节字符数(不包括终止符 \0)。
//如果目标多字节字符串的空间不足以存储转换后的结果或发生了无效的宽字符,则返回 SIZE_MAX 并设置 errno 为 EILSEQ。
注意事项:
wcstombs函数将宽字符字符串按照当前的本地编码进行转换。因此,转换结果可能因系统区域设置而异,对于非 ASCII 字符,可能需要使用 Unicode 或其他编码来转换。- 目标多字节字符串应该具备足够的空间,以确保转换后的结果不会溢出。
- 如果
dest参数为NULL,则wcstombs函数会计算转换后的结果长度,但不进行实际转换。可以通过检查返回值来获取所需的缓冲区大小。
可使用std::setlocale获取、设置当前程序的本地化(locale)环境。
std::setlocale函数用于设置程序的本地化环境,以便程序能够正确处理与语言、字符集、日期时间格式等相关的操作。根据指定的本地化环境,不同的函数和库可能在字符转换、字符串比较、日期时间格式化等方面表现出不同的行为。
关于std::setlocale的使用,详见:std::setlocale详解
这里列举下常规的使用示例:
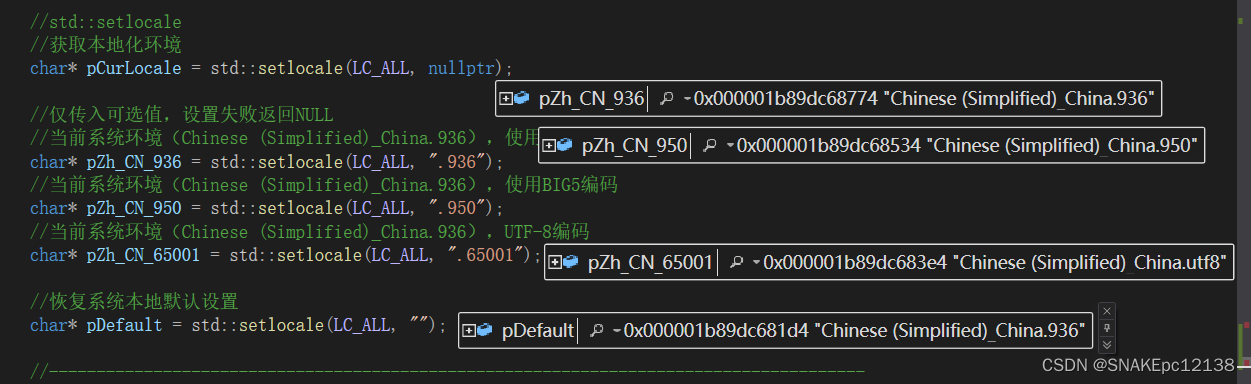
//std::setlocale
//获取本地化环境
char* pCurLocale = std::setlocale(LC_ALL, nullptr);
//仅传入可选值,设置失败返回NULL
//当前系统环境(Chinese (Simplified)_China.936),使用GB2312编码
char* pZh_CN_936 = std::setlocale(LC_ALL, ".936");
//当前系统环境(Chinese (Simplified)_China.936),使用BIG5编码
char* pZh_CN_950 = std::setlocale(LC_ALL, ".950");
//当前系统环境(Chinese (Simplified)_China.936),UTF-8编码
char* pZh_CN_65001 = std::setlocale(LC_ALL, ".65001");
//恢复系统本地默认设置
char* pDefault = std::setlocale(LC_ALL, "");
结果:
自定义转换接口(带编码参数)如下:
// 将宽字符字符串转换为多字节字符串
std::string WcsToMbs(const wchar_t* wideStr, const char* encoding)
{
// 获取源宽字符字符串的长度
size_t len = std::wcslen(wideStr);
// 计算多字节字符串所需的缓冲区大小
int nCnt = sizeof(wchar_t);
size_t bufferSize = (len + 1) * nCnt;
char* multiByteStr = new char[bufferSize];
// 设置转换编码
//先保存当前本地化设置
const char* currentLocale = std::setlocale(LC_ALL, nullptr);
std::setlocale(LC_ALL, encoding);
// 将宽字符字符串转换为多字节字符串
wcstombs(multiByteStr, wideStr, bufferSize);
// 恢复之前的本地化设置
std::setlocale(LC_ALL, currentLocale);
std::string result(multiByteStr);
delete[] multiByteStr;
return result;
}
**注意:**MbsToWcs的encoding参数用于指定目标字符编码。它表示将要转换成的多字节字符的编码方式。即这个参数的值决定了将宽字符转换为多字节字符时所使用的字符集。同前面的WideCharToMultiByte。
测试示例:
char16_t ch16_utf16[] = u"这是一个UTF-16编码的测试文本";
wchar_t wch_utf16[] = L"在Windows系统上,这是一个UTF-16编码的测试文本";
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sANSI_fromWCH = WcsToMbs(wch_utf16, "");
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 UTF-8编码的多字节
std::string sUTF8_fromWCH = WcsToMbs(wch_utf16, ".65001");
//UTF-16编码的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
std::string sANSI_fromCh16 = WcsToMbs((wchar_t*)ch16_utf16, "");
//UTF-16编码的宽字符 转 UTF-8编码的多字节
std::string sUTF8_fromCh16 = WcsToMbs((wchar_t*)ch16_utf16, ".65001");
测试结果:

优点:C/C++ 标准库接口实现,可跨平台,且能指定编码转换
std::wstring_convert
std::wstring_convert 是 C++ 标准库中的一个类模板,它提供了多字节字符串和宽字符字符串之间的转换功能。它是在 C++11 标准中引入的,定义在 <locale> 头文件中。
std::wstring_convert 类模板主要用于将多字节字符串(std::string)和宽字符字符串(std::wstring)之间进行转换。它提供了一种方便的方法来处理不同编码之间的字符串转换,而无需直接使用底层的 C 标准库函数。
下面是 std::wstring_convert 类模板的基本语法:
template <class Codecvt, class Elem = wchar_t, class Wide_alloc = std::allocator<Elem>, class Byte_alloc = std::allocator<char>>
class wstring_convert;
std::wstring_convert 模板有四个参数:
Codecvt:指定编码转换器的类型。这是一个实现了std::codecvt接口的类型,用于执行不同编码之间的转换。通常可以使用std::codecvt_utf8,std::codecvt_utf16,std::codecvt_utf8_utf16等标准实现的编码转换器。Elem:目标字符类型,默认为wchar_t,表示宽字符。Wide_alloc:宽字符字符串的分配器类型,默认为std::allocator<Elem>。Byte_alloc:多字节字符串的分配器类型,默认为std::allocator<char>。
std::wstring_convert 类模板提供了以下成员函数:
wstring_convert(Codecvt* pcvt): 构造函数,使用指定的编码转换器pcvt创建一个std::wstring_convert对象。~wstring_convert(): 析构函数,释放std::wstring_convert对象的资源。std::string to_bytes(const std::wstring& str): 将宽字符字符串str转换为多字节字符串,并返回转换后的结果。std::wstring from_bytes(const std::string& str): 将多字节字符串str转换为宽字符字符串,并返回转换后的结果。
std::wstring_convert 模板的 Codecvt 参数指定了编码转换器的类型,它是一个实现了 std::codecvt 接口的类型。下面是一些常见的可用的 Codecvt 参数值:
std::codecvt_utf8<wchar_t>:用于将 UTF-8 编码的多字节字符串转换为宽字符字符串。std::codecvt_utf16<wchar_t>:用于将 UTF-16 编码的多字节字符串转换为宽字符字符串。std::codecvt_utf8_utf16<wchar_t>:用于在 UTF-8 编码和 UTF-16 编码之间进行转换。std::codecvt_byname<wchar_t, char, std::mbstate_t>:使用特定名称的编码转换器。std::codecvt<char16_t, char, std::mbstate_t>:用于将 UTF-16 编码的多字节字符串转换为char16_t类型的宽字符字符串。std::codecvt<char32_t, char, std::mbstate_t>:用于将 UTF-32 编码的多字节字符串转换为char32_t类型的宽字符字符串。
注意,具体可用的 Codecvt 参数值取决于你的编译器和标准库的实现,以及系统所支持的编码类型。
另外需注意,如果你使用的编译器和标准库不支持特定的编码转换器,你可以自定义实现 std::codecvt 接口的子类,并将其作为 Codecvt 参数传递给 std::wstring_convert 模板实例化。这样可以根据您的需要支持其他编码转换(例ANSI编码)。
std::wstring_convert 并不能直接使用 ANSI 编码进行转换。std::wstring_convert 模板的 Codecvt 参数是一个实现了 std::codecvt 接口的类型,但是标准库并没有提供直接支持 ANSI 编码的 std::codecvt 实现。
ANSI 编码是一个与操作系统和环境相关的编码方式,不同的操作系统和环境可能使用不同的 ANSI 编码。在 C++ 标准库中,提供了与 ANSI 编码相关的 std::codecvt 实现的特定名称,例如 std::codecvt_byname,它允许使用特定名称的编码来进行转换。但是,具体可用的编码名称取决于操作系统和环境的支持。
如果需要使用 ANSI 编码进行字符串转换,可以考虑以下几种方法:
-
使用底层的 C 语言标准库函数,例如
mbstowcs和wcstombs,来手动进行 ANSI 编码和宽字符字符串之间的转换。 -
使用第三方库,例如
iconv,它可以提供更灵活和全面的字符串编码转换功能。 -
根据具体需求,可以自己实现一个符合 ANSI 编码转换要求的
std::codecvt子类。
自定义转换接口:
std::string ws_convert_to_s(const std::wstring& wideStr)
{
try
{
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>> converter;
return converter.to_bytes(wideStr);
}
catch (...)
{
return "";
}
}
该方式不能指定ANSI编码进行转换,若想指定需自定义std::codecvt子类,较为麻烦。
但对于Unicode字符集中的编码转换较为方便。
测试示例:
//std::wstring_convert
char16_t ch16_utf16[] = u"这是一个UTF-16编码的测试文本";
wchar_t wch_utf16[] = L"在Windows系统上,这是一个UTF-16编码的测试文本";
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
//不支持转 ANSI(当前系统是GB2312)编码的多字节
//宽字符编码(Windows系统上是UTF-16) 的宽字符 转 UTF-8编码的多字节
std::string sANSI_fromWCH = ws_convert_to_s(wch_utf16);
//UTF-16编码的宽字符 转 ANSI(当前系统是GB2312)编码的多字节
//不支持转 ANSI(当前系统是GB2312)编码的多字节
//UTF-16编码的宽字符 转 UTF-8编码的多字节
std::string sANSI_fromCh16 = ws_convert_to_s((wchar_t*)ch16_utf16);
测试结果:

多字节字符转宽字符
MultiByteToWideChar
MultiByteToWideChar是Windows API中的一个函数,用于将多字节字符字符串(例如ASCII或UTF-8编码)转换为宽字符字符串(UTF-16或UCS-2编码)。它与WideCharToMultiByte相反,可以在Windows应用程序中进行字符编码的转换。该函数可以根据指定的代码页来处理字符转换,同时还可以处理不可转换的字符。
原型如下:
#include <Windows.h>
int MultiByteToWideChar(
UINT CodePage, // 字符编码标识符
DWORD dwFlags, // 标志位
LPCCH lpMultiByteStr, // 多字节字符字符串地址
int cbMultiByte, // 多字节字符字符串长度
LPWSTR lpWideCharStr, // 宽字符字符串地址
int cchWideChar // 宽字符字符串长度
);
注意:MultiByteToWideChar函数中的CodePage参数是指定源字符编码的参数。它表示将要转换的多字节字符的编码方式。参数nCodePage指定了输入多字节字符的代码页,用于将多字节字符转换为宽字符(UTF-16或UCS-2编码)。即这个参数的值决定了多字节字符转换为宽字符时所使用的字符集。
#include <Windows.h>
#include <string>
// 多字节字符转宽字符
std::wstring MultiByteToWideCharWithAcp(const char* multiStr, UINT codePage)
{
int bufferSize = MultiByteToWideChar(codePage, 0, multiStr, -1, nullptr, 0);
if (bufferSize == 0)
{
// 转换失败
return L"";
}
std::wstring wideStr(bufferSize, L'\0');
if (MultiByteToWideChar(codePage, 0, multiStr, -1, &wideStr[0], bufferSize) == 0)
{
// 转换失败
return L"";
}
return wideStr;
}
测试示例:
char ch_ansi[] = "这是一个ANSI编码的测试文本";
char ch_utf8[] = u8"这是一个UTF-8编码的测试文本";
//ANSI(当前系统是GB2312)编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromANSI = MultiByteToWideCharWithAcp(ch_ansi, CP_ACP);
//ANSI(当前系统是GB2312)编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromANSI = (const char16_t*)wsWide_fromANSI.c_str();
//UTF-8编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromUTF8 = MultiByteToWideCharWithAcp(ch_utf8, CP_UTF8);
//UTF-8编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromUTF8 = (const char16_t*)wsWide_fromUTF8.c_str();
测试结果:

优点:
可指定转换时的编码
缺点:
Windows接口,不能跨平台
A2W
同理,A2W宏是特定于Windows平台的,依赖于MFC库。
A2W定义如下:
//atlconv.h
#define A2W(lpa) (\
((_lpa = lpa) == NULL) ? NULL : (\
_convert = (static_cast<int>(strlen(_lpa))+1),\
(INT_MAX/2<_convert)? NULL : \
ATLA2WHELPER((LPWSTR) alloca(_convert*sizeof(WCHAR)), _lpa, _convert, _acp)))
#define ATLA2WHELPER AtlA2WHelper
_Ret_maybenull_z_ _Post_writable_byte_size_(nChars) inline LPWSTR WINAPI AtlA2WHelper(
_Out_writes_opt_z_(nChars) LPWSTR lpw,
_In_opt_z_ LPCSTR lpa,
_In_ int nChars) throw()
{
return AtlA2WHelper(lpw, lpa, nChars, CP_ACP);
}
ATLPREFAST_SUPPRESS(6054)
_Ret_maybenull_z_ _Post_writable_byte_size_(nChars) inline LPWSTR WINAPI AtlA2WHelper(
_Out_writes_opt_z_(nChars) LPWSTR lpw,
_In_opt_z_ LPCSTR lpa,
_In_ int nChars,
_In_ UINT acp) throw()
{
ATLASSERT(lpa != NULL);
ATLASSERT(lpw != NULL);
if (lpw == NULL || lpa == NULL)
return NULL;
// verify that no illegal character present
// since lpw was allocated based on the size of lpa
// don't worry about the number of chars
*lpw = '\0';
int ret = MultiByteToWideChar(acp, 0, lpa, -1, lpw, nChars);
if(ret == 0)
{
ATLASSERT(FALSE);
return NULL;
}
return lpw;
}
ATLPREFAST_UNSUPPRESS()
注意:
使用A2W同样需要包含Windows.h
#include <Windows.h>
转换时也是使用系统默认的字符编码(CP_ACP)进行转换。
这里使用alloca在在A2W宏函数所在的作用域内的栈上分配内存,无需再手动释放内存!
自定义转换接口如下:
std::wstring AToW(const char* multiStr)
{
USES_CONVERSION;
return std::wstring(A2W(multiStr));
}
测试示例:
char ch_ansi[] = "这是一个ANSI编码的测试文本";
//ANSI(当前系统是GB2312)编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromANSI = AToW(ch_ansi);
//ANSI(当前系统是GB2312)编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromAnsi = (const char16_t*)wsWide_fromANSI.c_str();
测试结果:
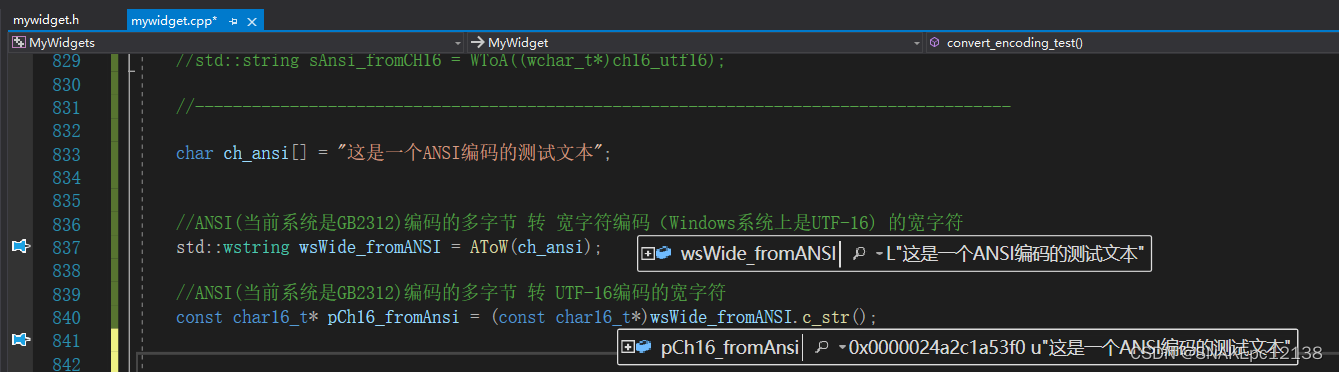
因默认使用系统默认编码进行转码,传入UTF-8编码内容时转码会乱码:
//传入UTF-8编码内容转码 会 乱码
char ch_utf8[] = u8"这是一个UTF-8编码的测试文本";
std::wstring wsWide_fromUTF8 = AToW(ch_utf8);
测试结果:

mbstowcs
mbstowcs 是一个 C/C++ 标准库函数,用于将多字节字符串(char 类型)转换为宽字符字符串(wchar_t 类型)。
函数原型:
size_t mbstowcs(wchar_t* dest, const char* src, size_t destSize);
dest:指向目标宽字符字符串的指针,用于存储转换后的结果。
src:指向源多字节字符串的指针,要进行转换的字符串。
//destSize:目标宽字符字符串的最大长度,以宽字符的单位进行计数。
//返回值:
//如果转换成功,则返回转换后的宽字符数(不包括终止符 \0)。
//如果目标宽字符字符串的空间不足以存储转换后的结果或发生了无效的多字节字符,则返回 SIZE_MAX 并设置 errno 为 EILSEQ。
注意事项:
mbstowcs函数将多字节字符串按照当前的本地化设置进行转换。因此,转换结果可能因系统区域设置而异,对于非 ASCII 字符,可能需要使用 Unicode 或其他宽字符编码来转换。- 目标宽字符字符串应该具备足够的空间,以确保转换后的结果不会溢出。
- 如果
dest参数为NULL,则mbstowcs函数会计算转换后的结果长度,但不进行实际转换。可以通过检查返回值来获取所需的缓冲区大小。
自定义转换接口(带编码参数)如下:
// 将多字节字符串转换为宽字符字符串
std::wstring MbsToWcs(const char* multiByteStr, const char* encoding)
{
// 获取源多字节字符串的长度
size_t len = std::strlen(multiByteStr);
// 计算宽字符字符串所需的缓冲区大小
size_t bufferSize = len + 1;
wchar_t* wideStr = new wchar_t[bufferSize];
// 设置转换编码
//先保存当前本地化设置
const char* currentLocale = std::setlocale(LC_ALL, nullptr);
std::setlocale(LC_ALL, encoding);
// 将多字节字符串转换为宽字符字符串
mbstowcs(wideStr, multiByteStr, bufferSize);
// 恢复之前的本地化设置
std::setlocale(LC_ALL, currentLocale);
std::wstring result(wideStr);
delete[] wideStr;
return result;
}
注意:MbsToWcs函数中的encoding参数是指定源字符编码的参数。它表示将要转换的多字节字符的编码方式。参数nCodePage指定了输入多字节字符的代码页,用于将多字节字符转换为宽字符(UTF-16或UCS-2编码)。即这个参数的值决定了多字节字符转换为宽字符时所使用的字符集。同MultiByteToWideChar。
测试示例:
char ch_ansi[] = "这是一个ANSI编码的测试文本";
char ch_utf8[] = u8"这是一个UTF-8编码的测试文本";
//ANSI(当前系统是GB2312)编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromANSI = MbsToWcs(ch_ansi, "");
//ANSI(当前系统是GB2312)编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromANSI = (const char16_t*)wsWide_fromANSI.c_str();
//UTF-8编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromUTF8 = MbsToWcs(ch_utf8, ".65001");
//UTF-8编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromUTF8 = (const char16_t*)wsWide_fromUTF8.c_str();
测试结果:

若指定编码和原数据编码不一致时,会导致转码失败:
//若指定编码和原数据编码不一致时,会导致转码失败
//原数据是ANSI(当前系统是GB2312)编码,却指定UTF-8编码
std::wstring wsTmp = MbsToWcs(ch_ansi, ".65001");
//原数据是UTF-8编码,却指定ANSI(当前系统是GB2312)编码
std::wstring wsTmp2 = MbsToWcs(ch_utf8, "");
结果:

因使用C/C++标准库接口,相较前两种转换,会更通用。
std::wstring_convert
相关介绍同上。
自定义转换接口:
std::wstring s_convert_to_ws(const std::string& multiStr)
{
try
{
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>> converter;
return converter.from_bytes(multiStr);
}
catch (...)
{
return L"";
}
}
测试示例:
char ch_ansi[] = "这是一个ANSI编码的测试文本";
char ch_utf8[] = u8"这是一个UTF-8编码的测试文本";
//ANSI(当前系统是GB2312)编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromANSI = s_convert_to_ws(ch_ansi);
//ANSI(当前系统是GB2312)编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromANSI = (const char16_t*)wsWide_fromANSI.c_str();
//UTF-8编码的多字节 转 宽字符编码(Windows系统上是UTF-16) 的宽字符
std::wstring wsWide_fromUTF8 = s_convert_to_ws(ch_utf8);
//UTF-8编码的多字节 转 UTF-16编码的宽字符
const char16_t* pCh16_fromUTF8 = (const char16_t*)wsWide_fromUTF8.c_str();
测试结果:

总结
本文详细介绍了宽窄字符和字符编码之间的关系,同时归纳了两种宽窄字符转换的情况:
一种是保持原有字符编码不变,仅进行宽窄字符类型的转换。
另一种是即进行宽窄字符类型的转换,也进行字符编码的转换。
并给出了对应的测试示例及测试结果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Ubuntu安装和配置ssh教程
- Java基础面试题-2day
- C语言入门到精通之练习七:输出特殊图案,请在c环境中运行,看一看,Very Beautiful!
- (三维重建学习)衡量指标
- 跨境电商进化论:从B2C到C2M的创新商业模式
- 米贸搜|facebook加人有限制吗?facebook每天最多加多少人
- ruoyi-Vue前后端分离版生成代码后的处理
- 一分钟带你了解支持向量机(SVM)
- 一篇文章看懂mysql加锁
- kubernetes(k8s) Yaml 文件详解