2023_Spark_实验二十八:Flume部署及配置
发布时间:2023年12月18日
实验目的:熟悉掌握Flume部署及配置
实验方法:通过在集群中部署Flume,掌握Flume配置
实验步骤:
一、Flume简介
Flume是一种分布式的、可靠的和可用的服务,用于有效地收集、聚合和移动大量日志数据。它有一个简单灵活的基于流数据流的体系结构。它具有健壮性和容错性,具有可调可靠性机制和多种故障转移和恢复机制。它使用了一个简单的可扩展数据模型,允许在线分析应用程序。其体系结构如下:
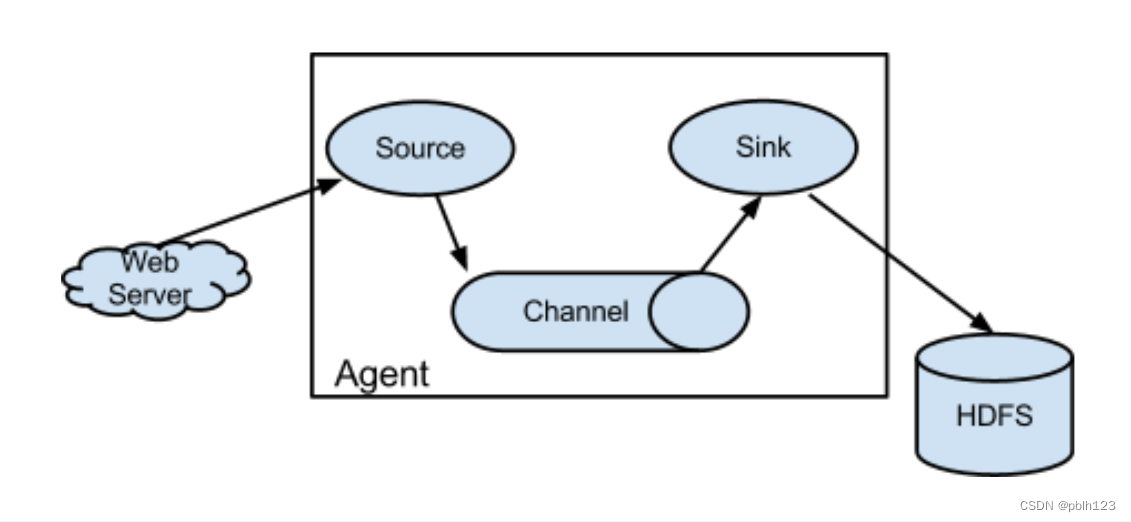
二、Flume安装与配置
下载Flume
https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
安装Flume
将下载好的Flume上传到集群中主节点,解压【注意改成自己的安装部署路径】
tar -zvxf apache-flume-1.9.0-bin.tar.gz -C /opt/module配置Flume环境变量,在~/.bash_profile 或?~/.bashrc中配置
# FLUME_HOME
FLUEM_HOME=/opt/module/apache-flume-1.9.0-bin
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$KAFKA_HOME/bin:$HIVE_HOME/bin:$FLUEM_HOME/bin:$SPARK_HOME/bin
export JAVA_HOME HADOOP_HOME KAFKA_HOME HIVE_HOME FLUEM_HOME SPARK_HOME PATH
让环境变量生效并检查效果
# 刷新环境变量
source ~/.bash_profile
# 检查flume效果
flume-ng version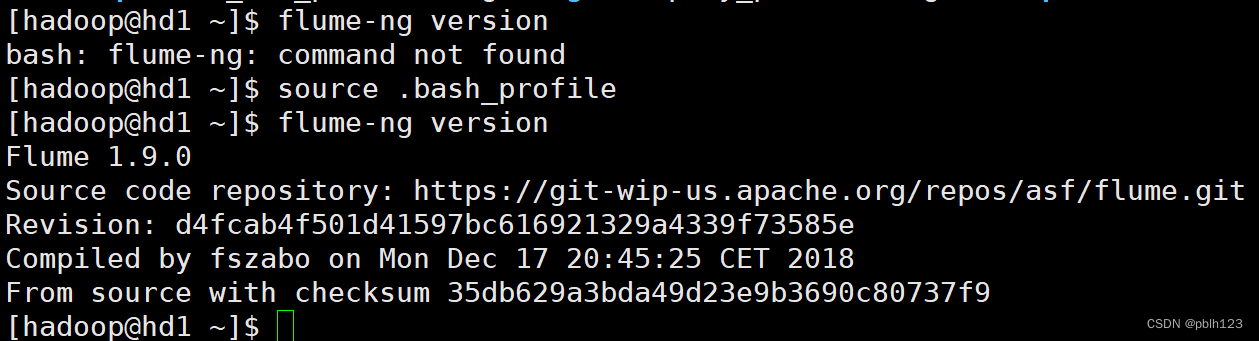
三、Flume基本操作
Flume的基础操作教程资料:
Flume 1.9.0 User Guide — Apache Flume
Flume入门案例
简单Flume使用案例:通过一个单节点Flume部署。此配置允许用户生成事件并随后将其记录到控制台。
在Flume的安装目录conf下,创建一个hello.conf配置文件
#声明三种组件 a1 = agent1
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#定义source信息
a1.sources.r1.type=netcat
a1.sources.r1.bind=hd1
a1.sources.r1.port=9888
#定义sink信息
a1.sinks.k1.type=logger
#定义channel信息
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#绑定在一起
a1.sources.r1.channels=c1
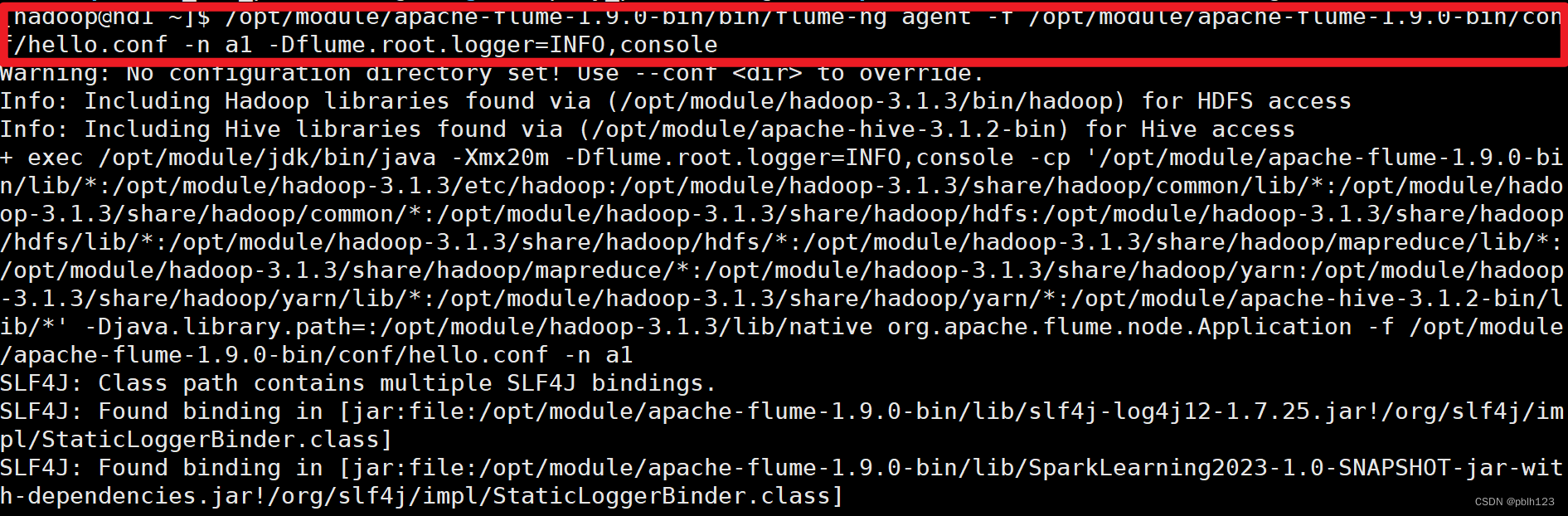
a1.sinks.k1.channel=c1启动flume
/opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent -f /opt/module/apache-flume-1.9.0-bin/conf/hello.conf -n a1 -Dflume.root.logger=INFO,console
重新打开一个terminal 远程回话,启动nc,检查启动的flume是否收到消息。
nc hd1 9888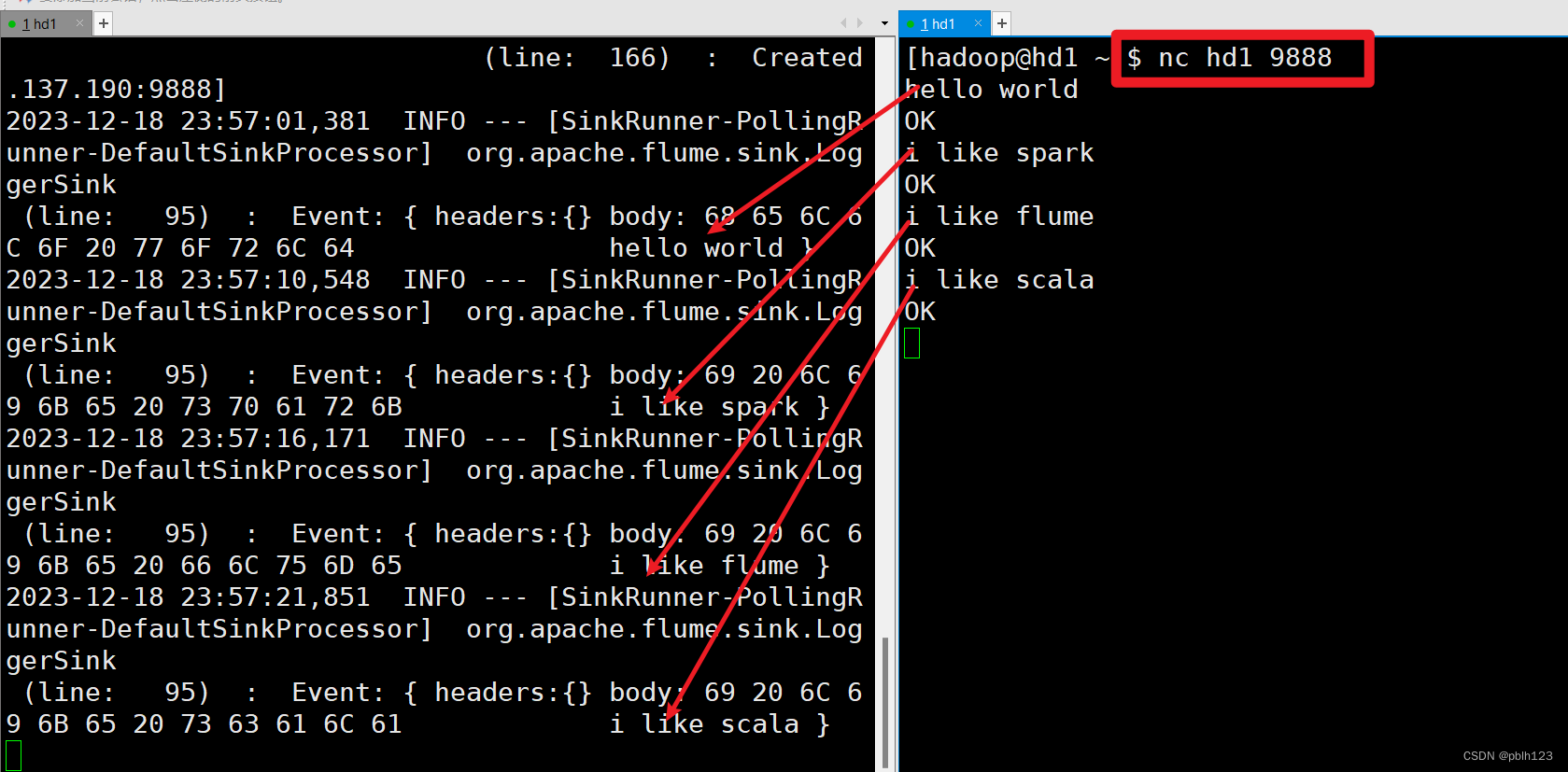
通过简单测试确定flume已经正常部署
实验结果:
本次实验通过在集群中单节点部署flume,并通过一个简单案例掌握flume使用方法。成功实现通过flume采集网络字节流数据。
文章来源:https://blog.csdn.net/pblh123/article/details/135060987
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!