DSL查询文档--查询结果处理
排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
普通字段排序
keyword、数值、日期类型排序的语法基本一致。
语法:
GET?/indexName/_search
{
??"query":?{
????"match_all":?{}
??},
??"sort":?[
????{
??????"FIELD":?"desc"??//?排序字段、排序方式ASC、DESC
????}
??]
}
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推。
示例:
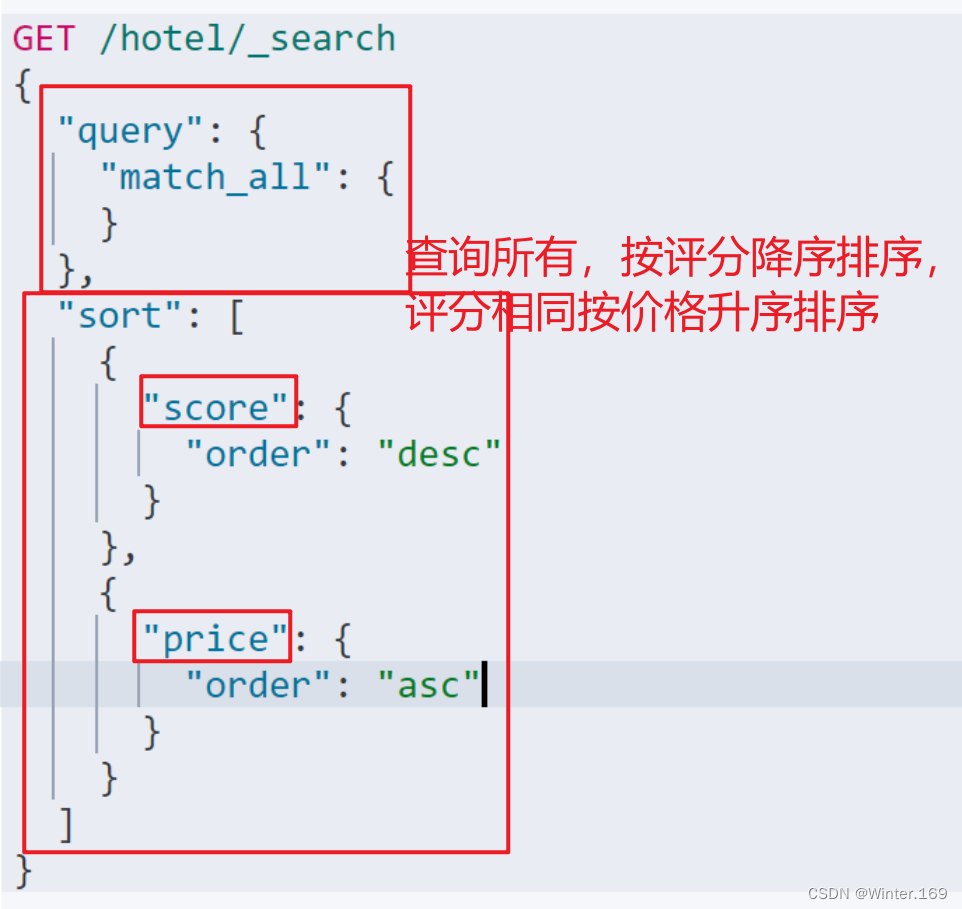
需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
地理坐标排序
地理坐标排序略有不同。
语法说明:
GET?/indexName/_search
{
??"query":?{
????"match_all":?{}
??},
??"sort":?[
????{
??????"_geo_distance"?:?{
??????????"FIELD"?:?"纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
??????????"order"?:?"asc", // 排序方式
??????????"unit"?:?"km" // 排序的距离单位
??????}
????}
??]
}
这个查询的含义是:
-
指定一个坐标,作为目标点
-
计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
-
根据距离排序
示例:
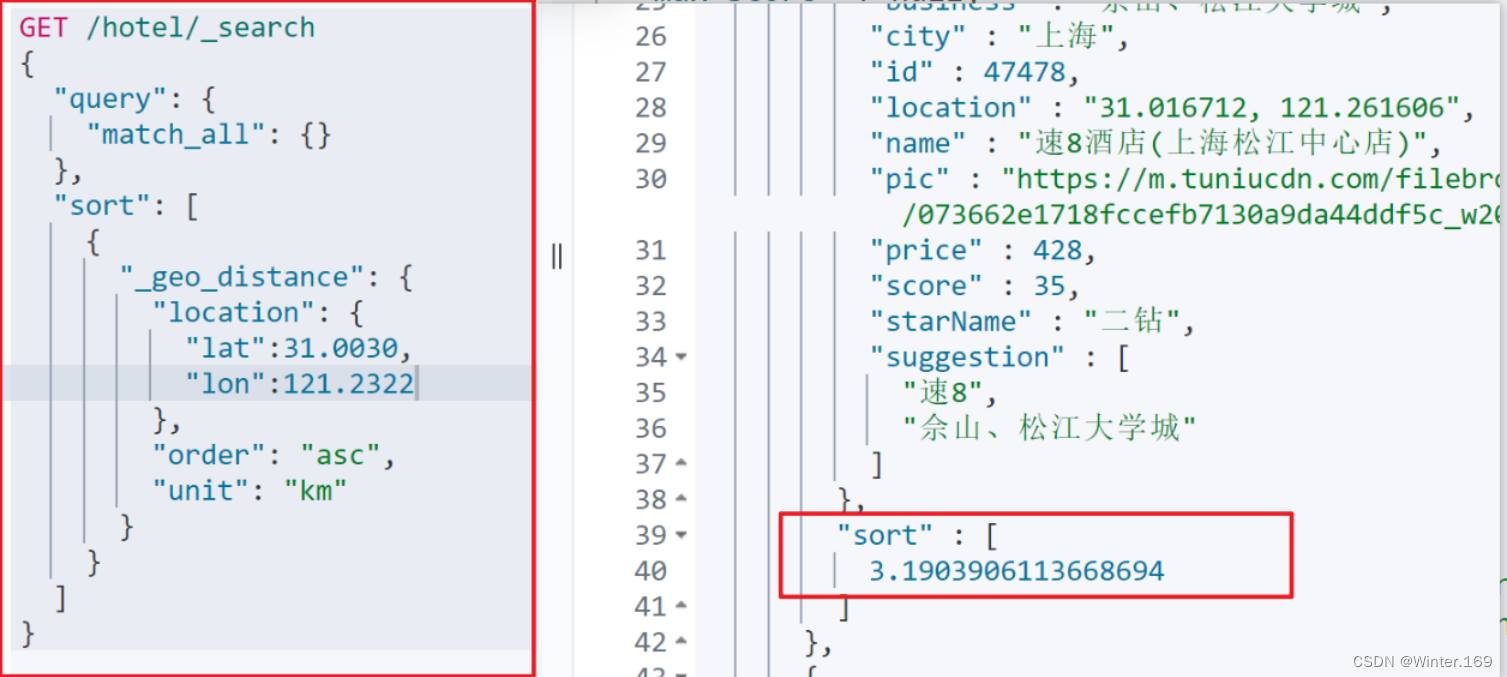
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
提示:获取你的位置的经纬度的方式:获取鼠标点击经纬度-地图属性-示例中心-JS API 2.0 示例 | 高德地图API
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
-
from:从第几个文档开始
-
size:总共查询几个文档
类似于mysql中的limit ?, ?
基本的分页
分页的基本语法如下:
GET?/hotel/_search
{
??"query":?{
????"match_all":?{}
??},
??"from":?0,?//?分页开始的位置,默认为0
??"size":?10,?//?期望获取的文档总数
??"sort":?[
????{"price":?"asc"}
??]
}
深度分页问题
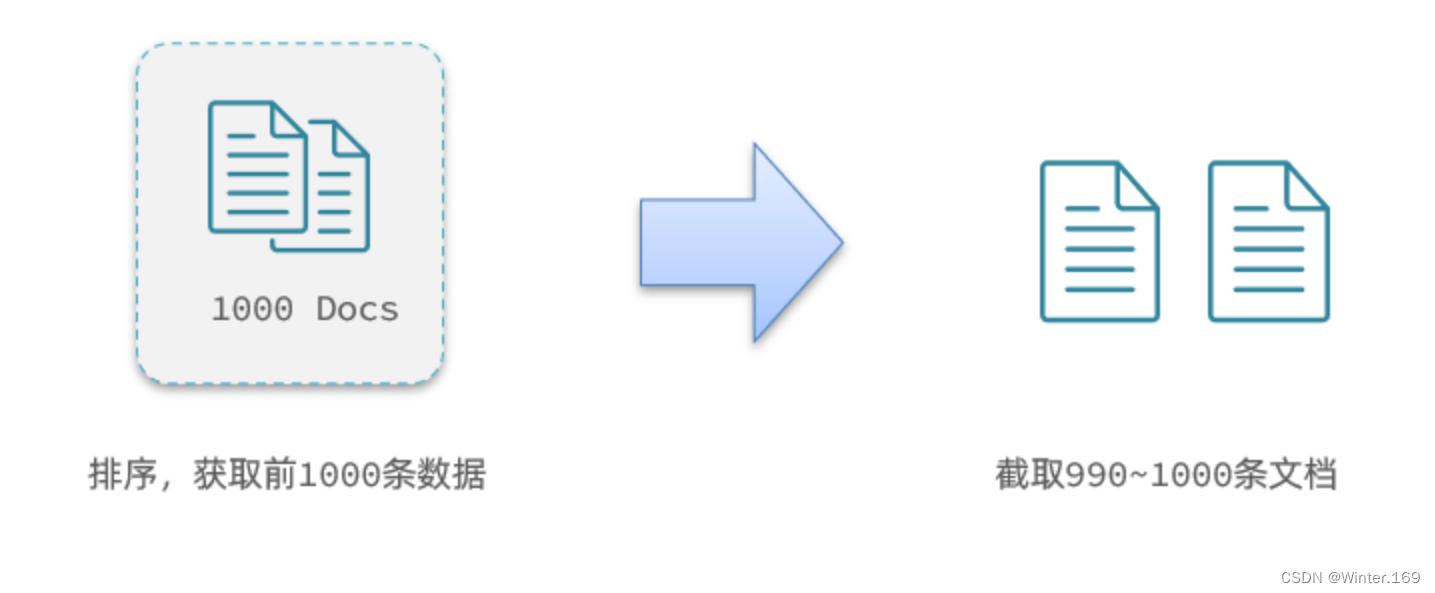
现在,我要查询990~1000的数据,查询逻辑要这么写:
GET?/hotel/_search
{
??"query":?{
????"match_all":?{}
??},
??"from":?990,?//?分页开始的位置,默认为0
??"size":?10,?//?期望获取的文档总数
??"sort":?[
????{"price":?"asc"}
??]
}
这里是查询990开始的数据,也就是 第990~第1000条 数据。
不过,elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:
查询TOP1000,如果es是单点模式,这并无太大影响。
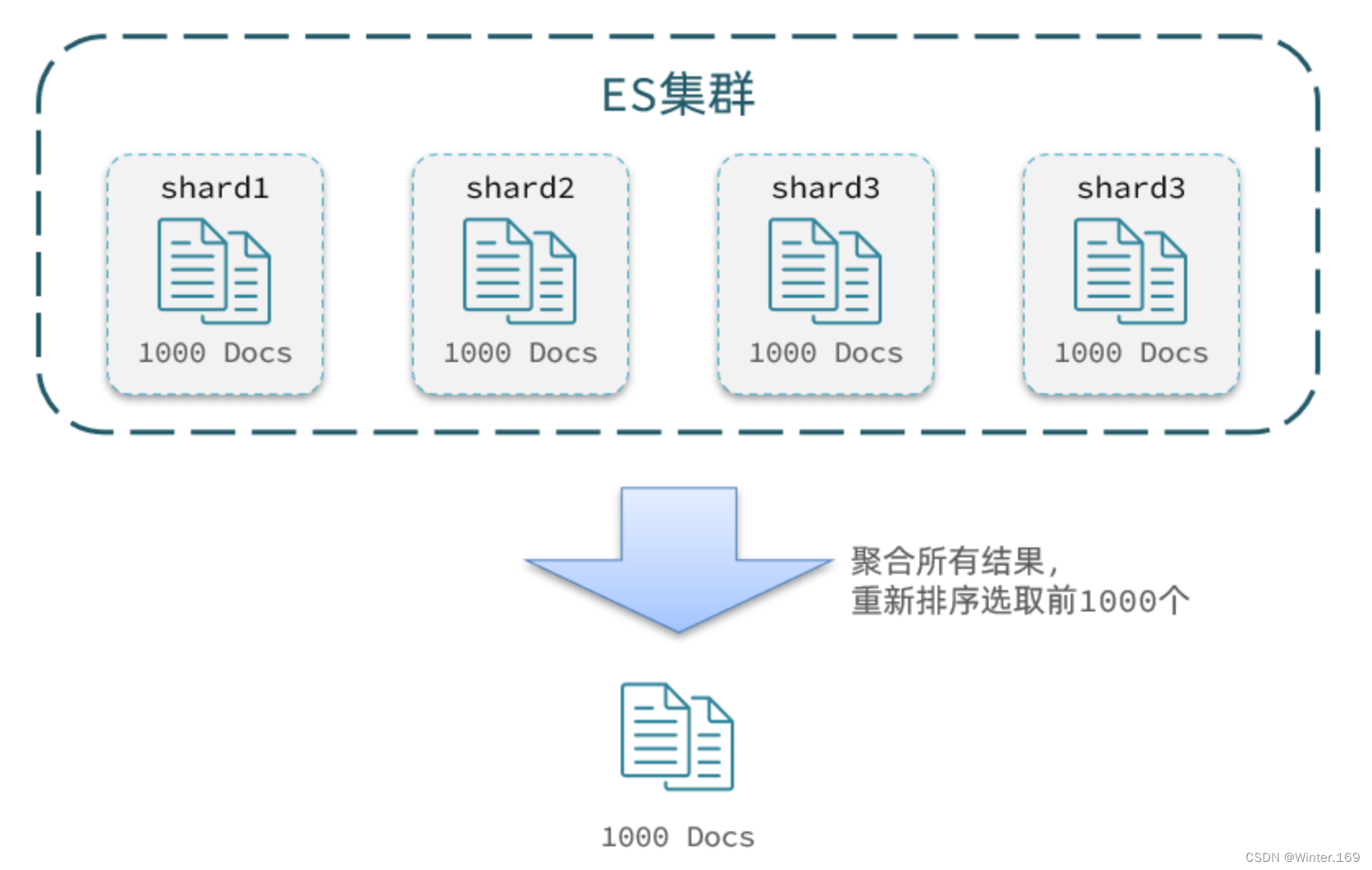
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。
因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
-
scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
分页查询的常见实现方案以及优缺点:
-
from + size:-
优点:支持随机翻页
-
缺点:深度分页问题,默认查询上限(from + size)是10000
-
场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
-
after search:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:只能向后逐页查询,不支持随机翻页
-
场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
-
scroll:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:会有额外内存消耗,并且搜索结果是非实时的
-
场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
-
高亮
实现高亮
高亮的语法:
GET?/hotel/_search
{
??"query":?{
????"match":?{
??????"FIELD":?"TEXT" // 查询条件,高亮一定要使用全文检索查询
????}
??},
??"highlight":?{
????"fields":?{?//?指定要高亮的字段
??????"FIELD":?{
????????"pre_tags":?"<em>",??//?用来标记高亮字段的前置标签
????????"post_tags":?"</em>"?//?用来标记高亮字段的后置标签
??????}
????}
??}
}
注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
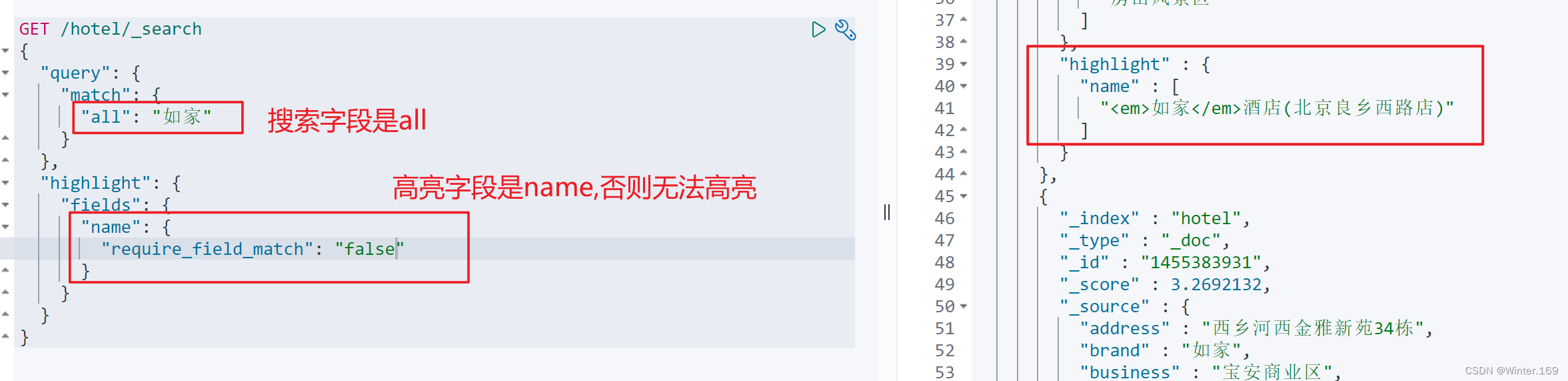
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
总结
查询的DSL是一个大的JSON对象,包含下列属性:
-
query:查询条件
-
from和size:分页条件
-
sort:排序条件
-
highlight:高亮条件
示例:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- django二手车辆管理系统(程序+开题报告)
- 关于大一上学期STM32培训的经验及教训(完全初学)
- Stable Diffusion(SD)核心基础知识——(文生图、图生图)
- windows server 2012、2019服务器定时重启
- 【UML】第7篇 用例图(2/3)
- ssm基于Javaweb的物流信息管理系统的设计与实现论文
- OpenHarmony之HDF驱动框架
- 让 Vue 模板引用更加简洁清晰
- 产品经理学习-策略产品指标
- Java面试——Overload 和 Override 的区别。Overloaded 的方法是否可以改变返回值类型?