线性回归应用梯度下降法
发布时间:2024年01月07日
应用梯度下降法解决线性回归问题
梯度下降法的原理
由于时间原因没有仔细的讲解代码的每一步,但只要明白梯度下降法的原理和熟悉python语法应该可以看懂.
文章目录
前言
实例需要一定的理论基础,不懂梯度下降法的可以看我上面给的链接,这部分实例会让你更加理解梯度下降法在深度学习中的作用.
一、建立数据
应用sklearn中的make_regression创建带噪声的回归数据样本
from sklearn.datasets import make_regression
X,Y=make_regression(n_samples=100, n_features=1,n_targets=1,noise=30,random_state=1)
Y = Y.reshape(len(X),-1)将数据组合成点

画出散点图
plt.scatter(points[:,0],points[:,1])
plt.show()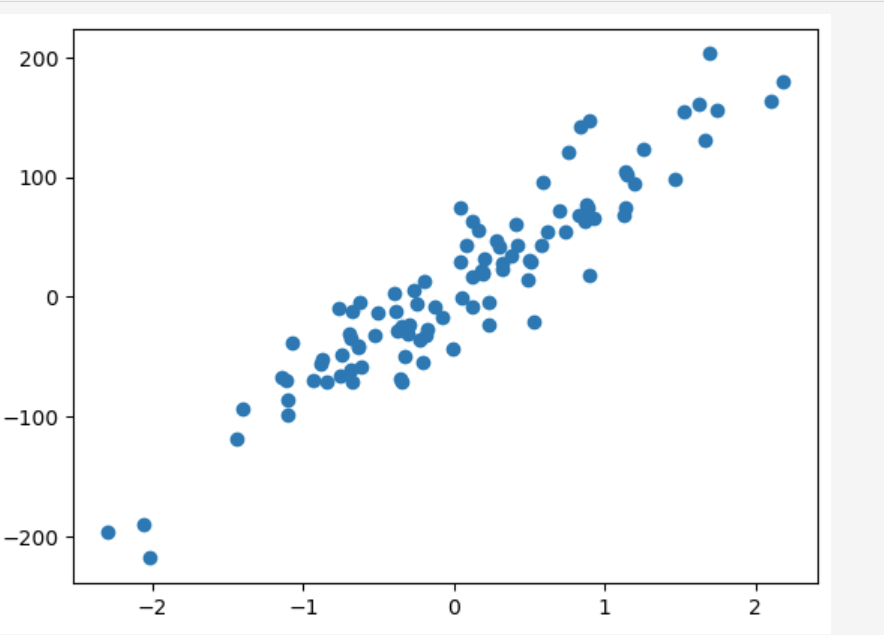
二、使用梯度下降法
1.定义获取损失函数
def compute_error_line_given_points(b , w, points):
total_Error = 0
for i in range(0,len(points)):
x = points[i,0]
y = points[i,1]
total_Error += (y-(w * x + b))**2
return total_Error
2.计算梯度信息并更替
这部分就是梯度下降法参数的更新算法
def step_gradient(b_current, w_current,points,learningRate):
b_gradient = 0
w_gradient = 0
N = float(len(points))
for i in range(0,len(points)):
x = points[i,0]
y = points[i,1]
b_gradient += -(2/N) * (y - (w_current * x + b_current))
w_gradient += -(2/N) * (y - (w_current * x + b_current)) * x
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b,new_w]3.运行函数
主要的目的是显示出所求的参数最优解,和每次损失函数的学习曲线
def run(points):
learningRate = 0.01
initial_b = 0
initial_w = 0
num_iteration = 1000
list1 = []
print("开始梯度下降:b的初值为{0},w的初值为{1},学习率为{2},迭代次数:{3}次".format(initial_b,initial_w,learningRate,num_iteration))
print("Running")
obj = gradient_descent_runner(points,initial_b,initial_w,learningRate,num_iteration)
b = obj[0][0]
w = obj[0][1]
list1 = obj[1]
print("结束梯度下降:b = {0},w = {1},error = {2}".format(b,w,compute_error_line_given_points(b,w,points)))
plt.scatter(points[:,0],points[:,1])
x = np.linspace(-3, 3, 50)
y = w*x + b
plt.plot(x, y)
plt.show()
return list1函数返回的list1就是损失函数的变化值
调用run函数,将数据传进去
list1 = run(points)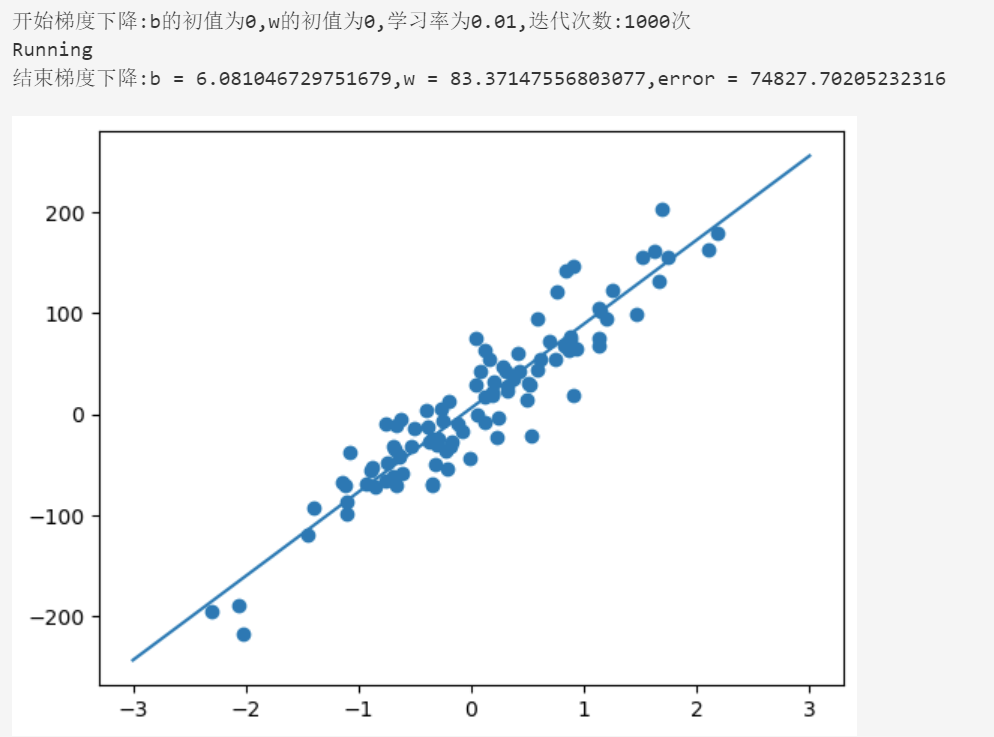
损失函数的学习曲线
plt.plot(range(1,len(list1)+1),list1)
plt.show()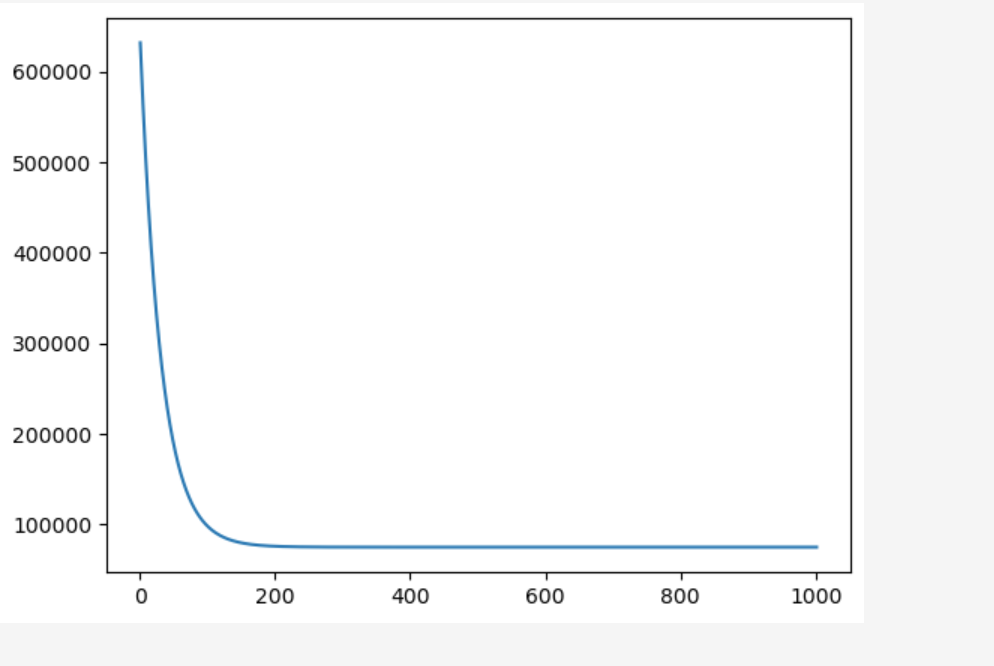
总结
本文章使用梯度下降算法对线性回归问题进行求解,主要部分就是梯度下降法的算法实现思想,其实还是蛮简单的,但要注意学习率learningRate和迭代次数本人刚开始将迭代次数设小了,导致没有效果,一定要注意这两个超参数.
文章来源:https://blog.csdn.net/qq_55383558/article/details/135338188
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录算法训练营第三十二天(回溯算法篇)|332. 重新安排行程
- 002-python(8种)基础数据类型(int,float,bool,str)
- Centos 8.5 Oracle12c安装
- C++的IO流
- 羊奶的奶源,解密优质健康的来源
- L1-087:机工士姆斯塔迪奥
- 美易投资:在经济不确定性中寻求避风港:美股投资者转向高质量股
- 云服务器 nginx自启动、mysql自启动、pyhton后端自启动
- MT3520B SOT23-5 DC-DC1.5MHz同步降压芯片 2A 6V 丝印AS20B5
- mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)