MySQL——表的增删查改
目录

一.Create(创建)
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...案例:
创建一张学生表:
mysql> create table students(
-> id int unsigned primary key auto_increment,
-> name varchar(20) not null,
-> qq varchar(20) not null
-> );

?1.单行数据 + 全列插入
插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增。
指定插入:

?全列插入:

2.多行数据 + 指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致:
mysql> insert into students (name,qq) values
-> ('孙仲谋','65988135'),
-> ('曹孟德','974623215'),
-> ('刘玄德','948735415');
3.插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败:
可以选择性的进行同步更新操作 语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...案例:
insert students value (100,'八戒','100100100') on duplicate key update name='项羽(-_-)',qq='110110110';
解释:Query OK, 2 rows affected (0.00 sec)
- -- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- -- 1 row affected: 表中没有冲突数据,数据被插入
- -- 2 row affected: 表中有冲突数据,并且数据已经被更新
通过 MySQL 函数获取受到影响的数据行数:
SELECT ROW_COUNT();
4.?替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入;
replace into students value(100,'八戒','100100100');

-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入?
二.Retrieve(读取)
语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...案例:
-- 创建表结构
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
1. select 列 查询
全列查询:
-- 通常情况下不建议使用 * 进行全列查询:
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。(索引待后面课程讲解)
select * from exam_result;

指定列查询:
select id,name,english from exam_result;
查询字段为表达式 :

数学成绩统一加十分:
select id ,name,math+10 from exam_result;

计算成绩总分:

为查询结果指定别名
计算成绩总分,并且修改别名为‘总分’:
select id ,name,chinese+math+english 总分 from exam_result;

结果去重 :
select distinct math from exam_result;
?2.where 条件
比较运算符:
| 运算符 | 说明 |
| >, >=, | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
案例:?
英语不及格的同学即英语成绩 ( < 60 ):
select id,name,english from exam_result where english<60;
语文成绩在 [80, 90] 分的同学及语文成绩:
方法一:
select id,name,chinese from exam_result where chinese>=80 and chinese<=90;
方法二:
select id,name,chinese from exam_result where chinese between 80 and 90;

数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩 :
方法一:
select id,name,math from exam_result where math=58 or math=65 or math=99 or math=98;
方法二:
select id,name,math from exam_result where math in (58,65,99,98);
姓孙的同学 及 孙某同学 :
姓孙的同学,包括孙某某和孙某:
select id,name from exam_result where name like '孙%';
?孙某同学,姓名只有两个字:
select id,name from exam_result where name like '孙_';
语文成绩好于英语成绩的同学 :
select id,name,chinese,math from exam_result where chinese>math;
总分在 200 分以下的同学:
注意:WHERE 条件中使用表达式,别名不能用在 WHERE 条件中。
select id,name,chinese+math+english total from exam_result where chinese+math+english <200;

为什么别名不能用在 WHERE 条件中使用?
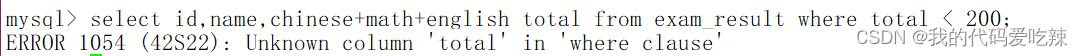
上述SQL语句包括两部分:select和where部分,由于where的语句优先级比select语句优先级高,所以在where中别并并未生效。
语文成绩 > 80 并且不姓孙的同学:
select id,name,chinese from exam_result where chinese>80 and name not like '孙%';
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80:
select name,chinese,math,english,chinese+math+english total from exam_result where name like '孙_' or (chinese+math+english>200 and chinese < math and english > 80);
NULL 的查询
select id,name,qq from exam_result where qq is not null;
select id,name,qq from exam_result where qq is null;

NULL 和 NULL 的比较,= 和 <=> 的区别:


3.结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序.
案例:
同学及数学成绩,按数学成绩升序显示:
select id,name,math from exam_result order by math;
select id,name,math from exam_result order by math asc;

同学及数学成绩,按数学成绩降序显示:
select id,name,math from exam_result order by math desc;

?同学及 qq 号,按 qq 号排序显示:
select id,name,qq from exam_result order by qq desc;

注意:NULL 视为比任何值都小,降序出现在最下面 。
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示 :
select name,chinese,math,english from exam_result order by math desc , english asc ,chinese asc;

查询同学及总分,由高到低:
order by 中可以使用表达式。
select name,chinese+math+english total from exam_result order by chinese+math+english desc;
select name,chinese+math+english total from exam_result order by total desc;
order by 中可以使用别名的原因是,order SQL语句的优先级小于select的优先级,先筛选出结果在排序。
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示:
select name,math from exam_result where name like '孙%' or name like '曹%' order by math desc;

4.筛选分页结果
语法:
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
案例:
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页:
select id,name,chinese,math,english from exam_result order by id limit 3 offset 0;
select id,name,chinese,math,english from exam_result order by id limit 3 offset 3;
select id,name,chinese,math,english from exam_result order by id limit 3 offset 6;
三.Update (修改)
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新。
案例:
将孙悟空同学的数学成绩变更为 80 分:

将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分 :

将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
update exam_result set math=math+30 order by chinese+math+english limit 3 ;

??将所有同学的语文成绩更新为原来的 2 倍:
update exam_result set chinese=chinese*2 ;
四.Delete(删除)
1.删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]案例:
删除孙悟空同学的考试成绩:
delete from exam_result where name='孙悟空';
2.删除整张表数据
注意:删除整表操作要慎用!!!!
测试:

删除整张表:

?再次插入数据:

我们发现id的,auto_increment,还是会递增。
3.截断表
语法:
TRUNCATE [TABLE] table_name注意:这个操作慎用
- 1. 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 2. 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 3. 会重置 AUTO_INCREMENT 项
案例:

截断表:

再次插入数据:

发现:AUTO_INCREMENT会重新计数。
4.去重表数据
数据准备:

步骤:
- 创建一张和原表一模一样规模的表
- 将原表的数据去重插入到新表中
- 将原表重命名,将新表重命名为原表的名称


五.聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
?统计班级共有多少同学:

?统计班级同学的 qq 号有多少:
NULL 不会计入结果。

统计本次考试的数学成绩分数个数 :

?统计数学成绩总分:

统计平均总分 :

?返回英语最高分 :

返回 > 70 分以上的数学最低分 :

六.group by子句的使用?
在select中使用group by 子句可以对指定列进行分组查询:
select column1, column2, .. from table group by column;准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
?数据库文件 ? scott_data.sql 文件?提取码wqwq。
这是一个sql数据库备份文件使用souce 直接恢复到mysql。



?如何显示每个部门的平均工资和最高工资:
显示每个部门的每种岗位的平均工资和最低工资 :

显示平均工资低于2000的部门和它的平均工资 :
分组查询时使用having进行条件过滤:

?--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI创作系统ChatGPT网站源码,支持Midjourney绘画,GPT语音对话+智能AI思维导图生成
- 10.docker卷
- 建筑施工安全管理系统
- 全国国控监测点点位数据,shp/excel格式,已可视化
- 实时数仓应用价值(上)
- CESS 课程开启招募,邀所有开发者共建数据价值网络!
- Jetpack Room使用
- 触摸屏监控双速电动机-确定地址分配
- go语言面试一逃逸分析
- Androidstudio加载编译时kotlin-compiler-embeddable一直下载中