电子科技大学《高级算法设计与分析》期末复习汇总
🎉 博主相信: 有足够的积累,并且一直在路上,就有无限的可能!!!
👨?🎓个人主页: 青年有志的博客
💯 说明: 本文中前大部分来自简言之大佬的博客(已附加在 References 部分),主要用于自身学习与对部分知识的扩充说明分析等, 并附历年试题,最新为 2023 年回忆版,问题汇总更有性价比: 电子科技大学高级算法设计问题汇总
第1章:引论
- 掌握什么是算法,算法的特征,算法和程序的差别;
- 理解什么是判断问题、搜索问题和优化问题。

- 程序可以不满足算法的有穷性
第2章:算法分析与设计基础
- 理解指数增长的恐怖;理解算法分析里为什么常数倍的差别可以被忽略
- 掌握渐近符号O、W、Q的含义,能判断一个函数属于哪个渐近增长阶;
- 能对给定函数按照渐进增长率进行排序,典型考题:作业1中的第2题
- 理解贪心算法的思想;能判断一个算法是否贪心算法;掌握工作安排 Interval scheduling 问题的贪心算法及其正确性证明;
理解指数增长的恐怖;理解算法分析里为什么常数倍的差别可以被忽略
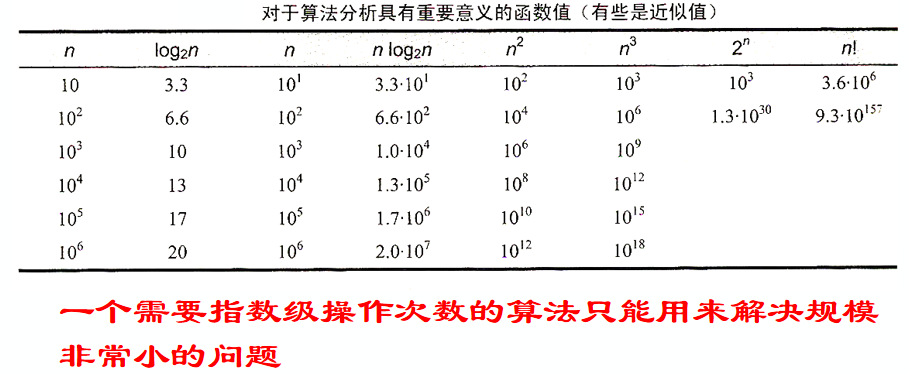

数量级的差别

算法A: 运行时间为100n,时间复杂度为O(n)。
算法B: 运行时间为nlogn,时间复杂度为O(nlogn)。
在这种情况下,可以看到算法 A 的时间复杂度更低。因为 O(n) 增长的速度比 O(nlogn) 慢,所以算法 A 在大多数情况下会更为高效。然而,需要注意的是,常数因子也很重要,因为在某些情况下,较高的常数因子可能导致实际运行时间上算法 B 更快。
注: 小规模问题: 当输入规模较小的时候,常数因子可能对算法性能产生显著影响。在这种情况下,一个具有较大时间复杂度但较小常数因子的算法可能比另一个具有较小时间复杂度但较大常数因子的算法更为优越。
渐进表达式

渐进分析(握渐近符号O、W、Q的含义,能判断一个函数属于哪个渐近增长阶;)
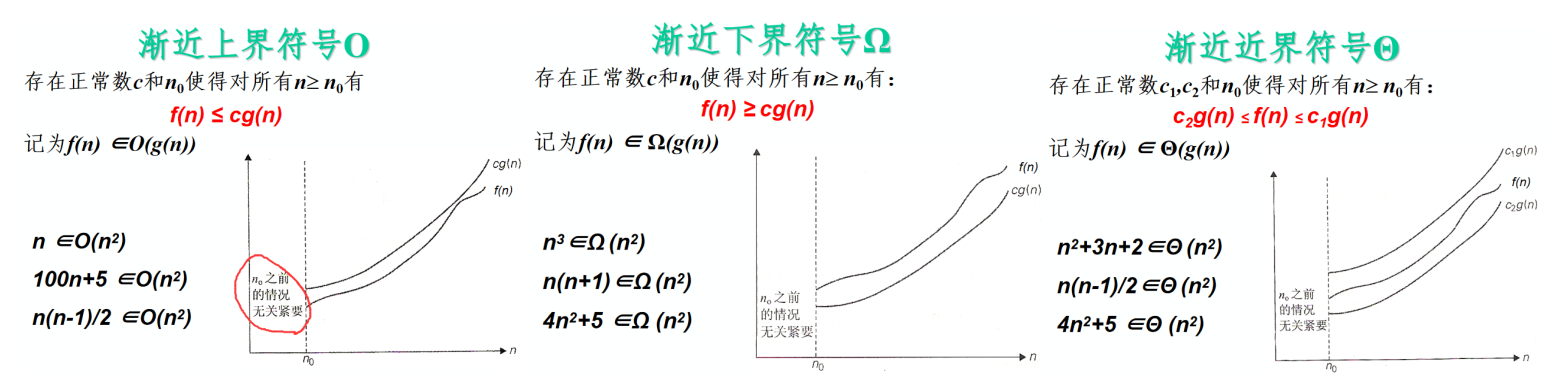
注意: 存在正常数 n 0 n_0 n0?,只关心 n > n 0 n > n_0 n>n0? 后面的情况,不用管前面的情况。


在渐进分析中等于符号的滥用

渐近分析中函数比较
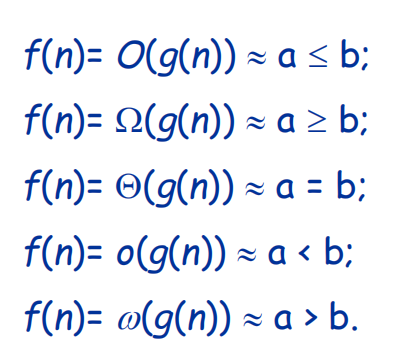
其中 o o o 为非紧上界符号, w w w 为非紧下界符号
渐近分析记号的若干性质
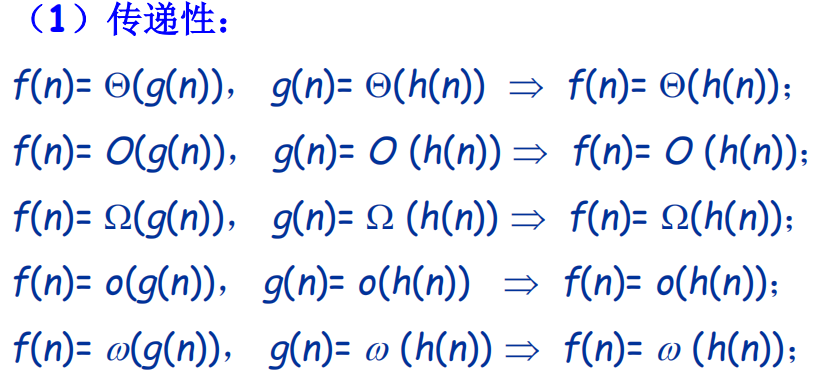

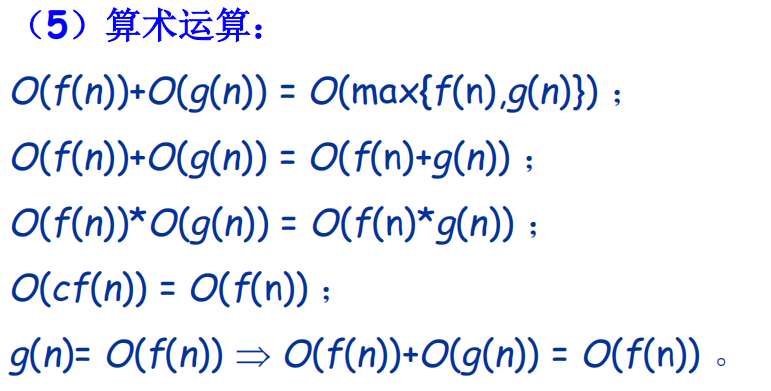

证明题1

证明题2

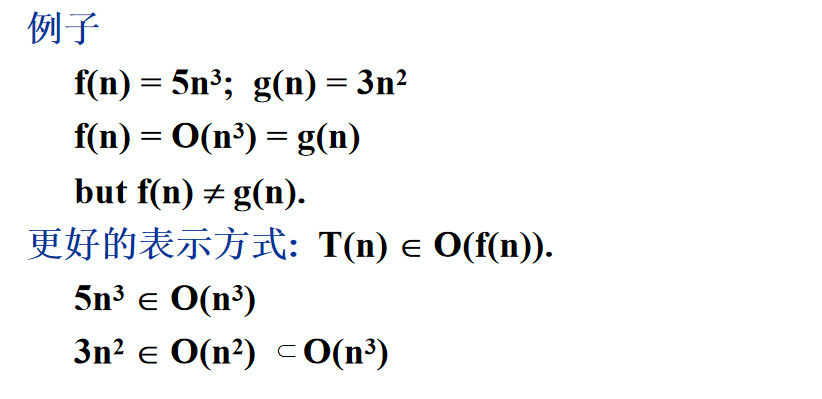
基本时间复杂度大小比较

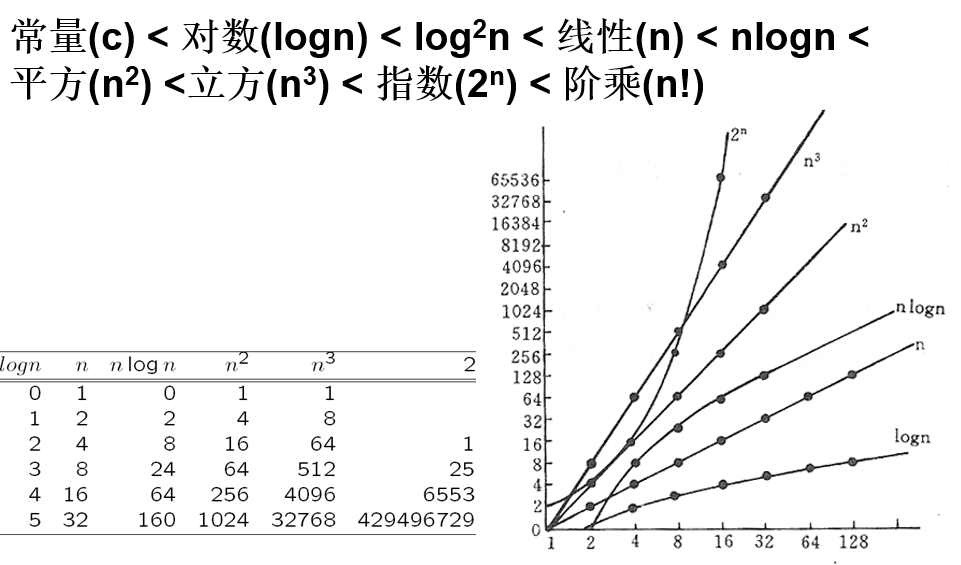
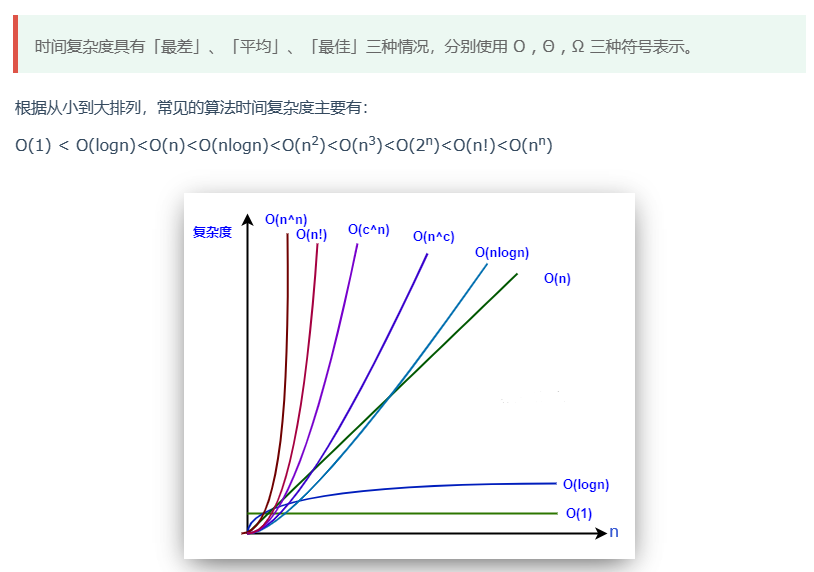
最常用的关系式 ☆☆☆☆☆


渐近增长率比较的三种方法
1. 定义法

2. 极限法


3. 取对数法 ☆☆☆☆☆


例题√


其中对于如下的比较:(相同的部分提取出来整体看)

例题


( log a ) n = O ( n c ) 、 n d = O ( r n ) (\text{log} a)^n = O(n^c)、n^d = O(r^n) (loga)n=O(nc)、nd=O(rn)
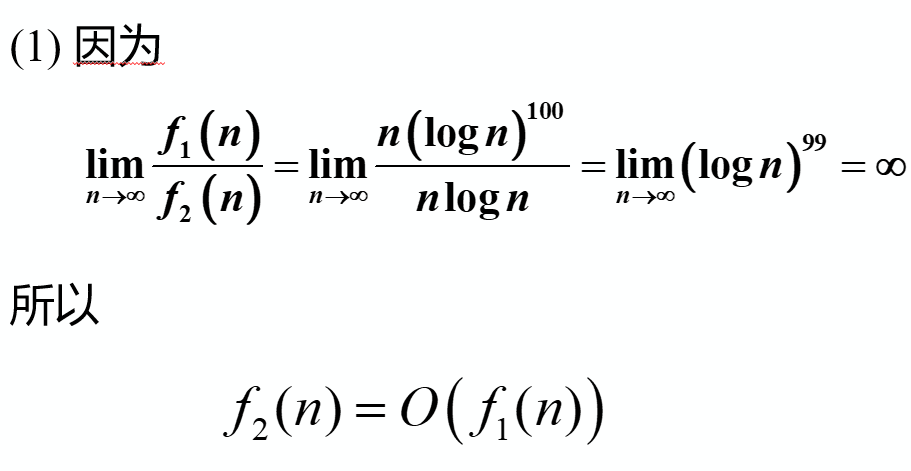

例题√


( log a ) n = O ( n c ) 、 n d = O ( r n ) (\text{log} a)^n = O(n^c)、n^d = O(r^n) (loga)n=O(nc)、nd=O(rn),注意: f 3 f_3 f3? 与 f 1 f_1 f1? 比较时,取极限后 (log n) n ? 1 ^{n-1} n?1 与 n 比较,明显 (log n) n ? 1 ^{n-1} n?1 更大,指数级( 2 n 2^n 2n)还高
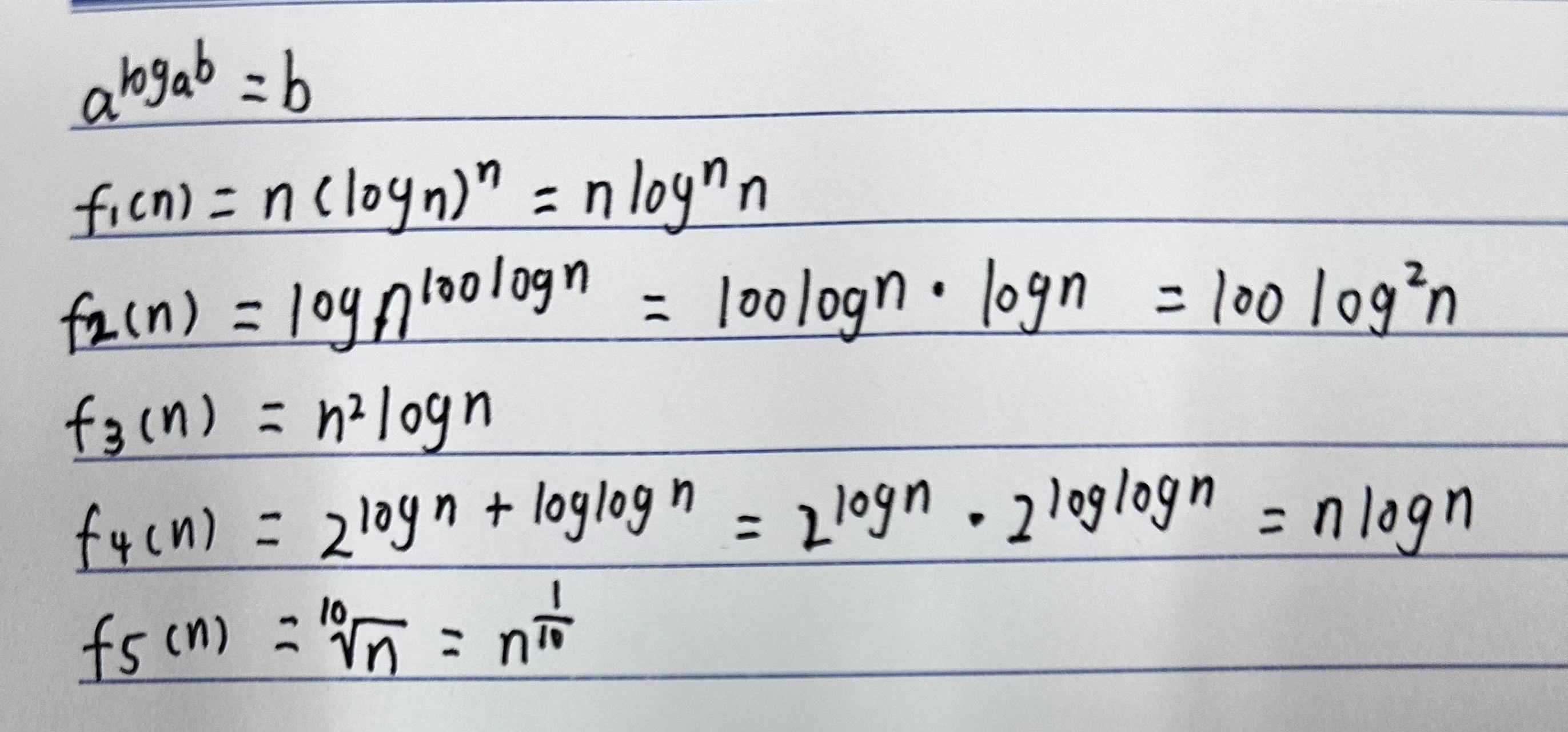
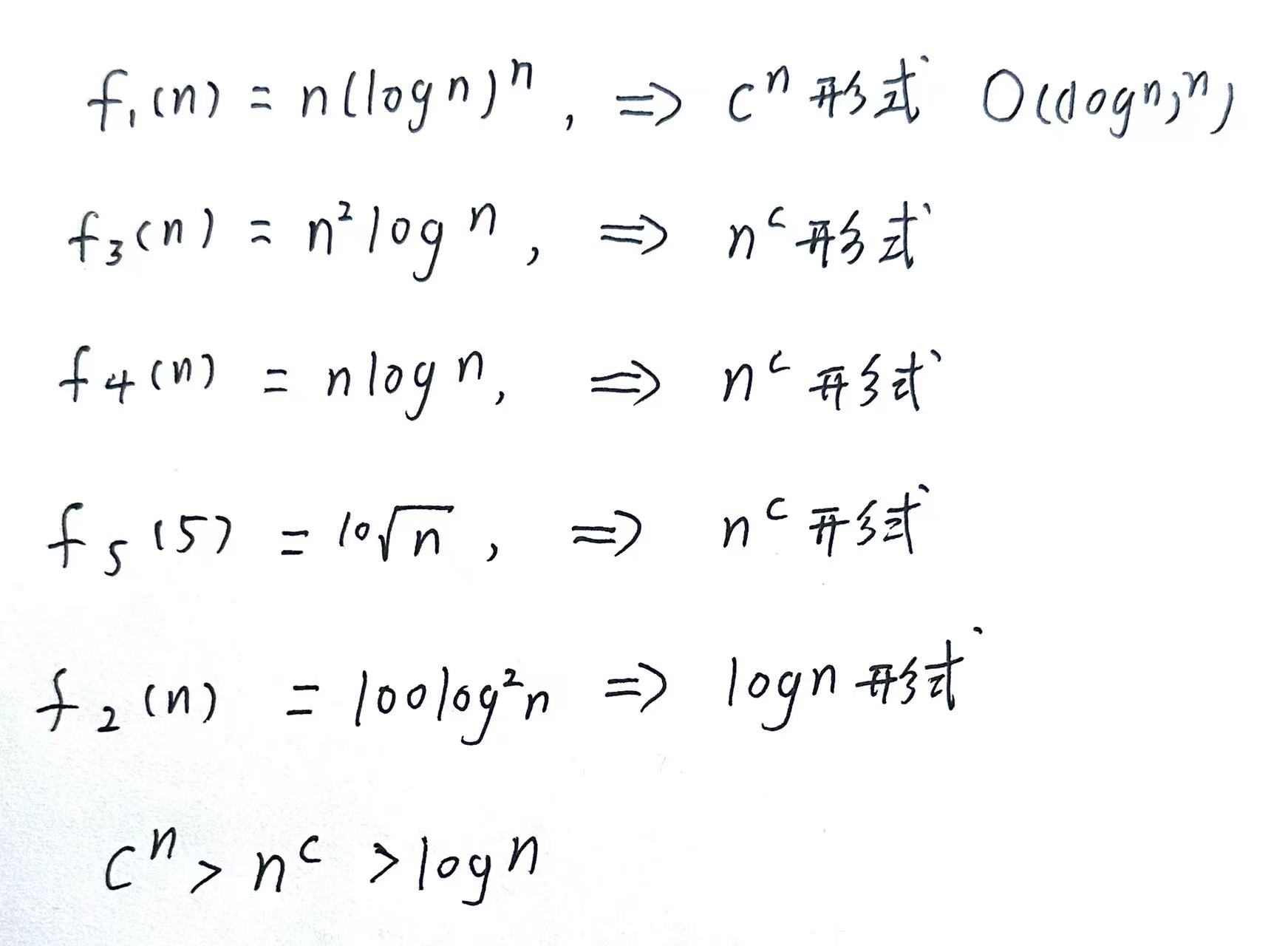

例题√


贪心算法


- Huffman 编码、Prim 算法、Kruskal 算法、Dijkstra 算法、找零钱问题也是
- Dijkstra 算法,每次选择最小的边更新路径
数学归纳法回顾:
首先,在开始 k = 1 时,成立,假设 k = n - 1 时,命题也成立,即满足 f ( n ? 1 ) = 2 n ? 1 ? 1 f(n - 1) = 2^{n - 1} - 1 f(n?1)=2n?1?1,证明,当 k = n 时,命题也成立,即得证



此题贪心算法的正确性证明:

区间调度(Interval scheduling)
注意:最早结束时间和最晚开始时间是相同的意思

算法时间复杂度是 O(nlogn) 的,排序时间复杂度
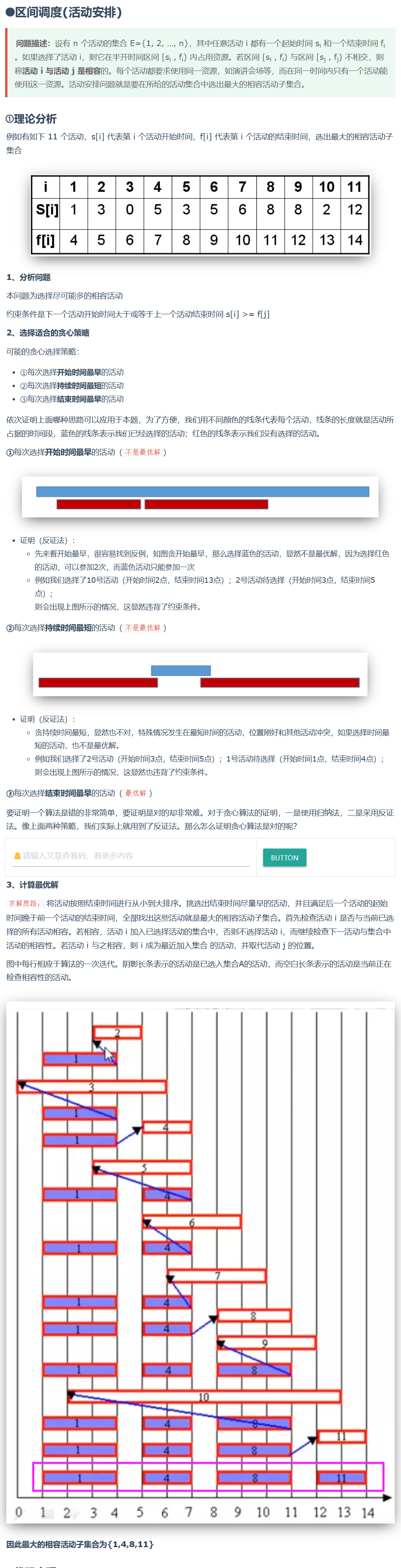
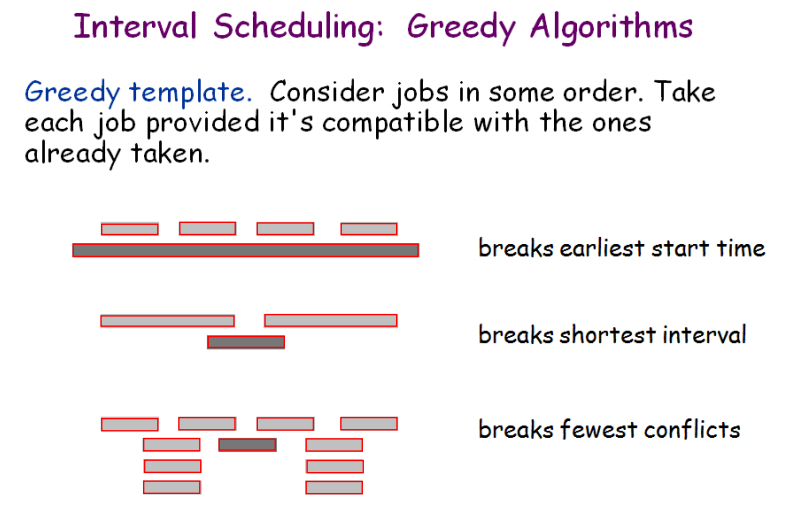
区间调度算法的正确性证明:

PPT 原文证明:

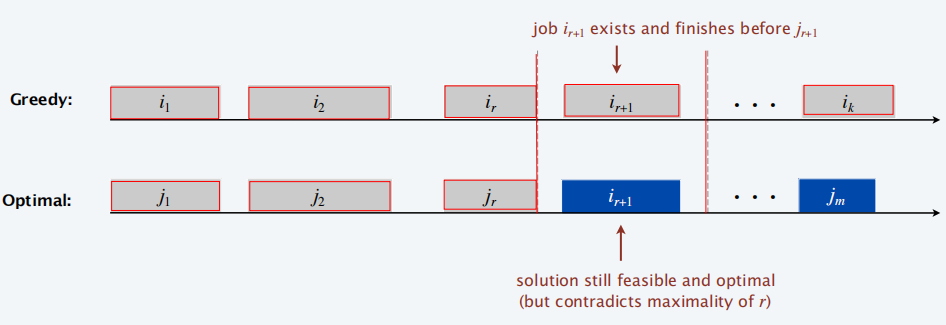

分治算法

典型考题:作业1的第1题

- 快排、归并、堆排序

例三利用主定理进行求解值得商榷!
PPT 中主定理:

第一种情况: 子问题个数 a 不是一个常数
第二种情况: 子问题个数 a 小于 1
第三种情况: 有误,不能直接说这种形式就不能用主定理

nlogn 实际上也是多项式时间算法的,logn 的增长速度十分缓慢。(上述第三条是有误的,具体我也昏了)
O ( n ( l o g n ) 100 ) O(n(log n)^{100}) O(n(logn)100) 是多项式时间。在大 O 表示法中, n ( l o g n ) 100 n(log n)^{100} n(logn)100 表示 n 与 ( l o g n ) 100 (log n)^{100} (logn)100 的乘积,而不是指数级别的增长。logn 的增长速度是相对较慢的,而其 100 次方只是一个常数项。因此,这是一个多项式时间复杂度,而不是指数时间复杂度。多项式时间复杂度通常是计算机科学中可接受的一种复杂度,相对于指数时间复杂度来说,它的增长趋势相对较为缓慢。
深入理解主定理:



如下:同样合并子问题的时间复杂度是 nlogn,但是一个可以使用主定理,一个不能使用。

总结: 判断是否多项式逼近,主要看 f ( n ) / n l o g b a f(n)/n^{log_ba} f(n)/nlogb?a 结果的上界渐进 O,是否是 O( n c n^c nc),实际上看 f ( n ) / n l o g b a f(n)/n^{log_ba} f(n)/nlogb?a 是否 n 被完全抵消即可。
计数逆序(Counting inversions)




在左边与右边进行合并时,如果 a[i] > a[j],由于左右两边均为有序,i 到 mid 的部分均大于 a[j],此时的逆序数为 mid - i + 1
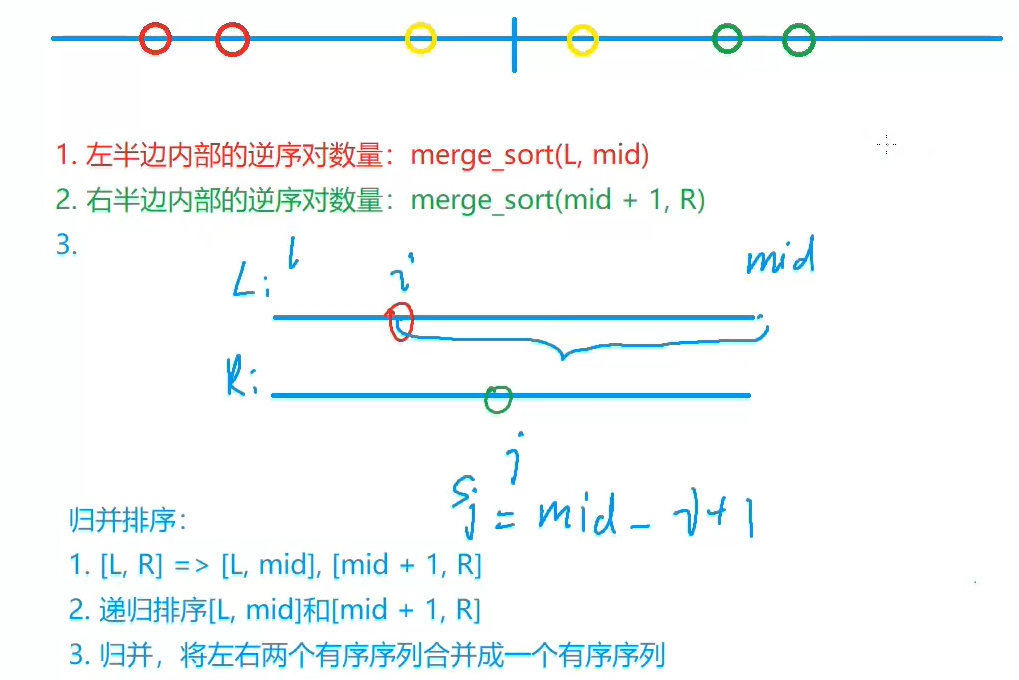
例题



- 不能使用主定理的情况:即找不到能够使得 f ( n ) / n l o g b a f(n)/n^{log_ba} f(n)/nlogb?a多项式逼近 n ε n^ε nε
例题


例题

此题答案没有,结果为 38,开头的 4 去掉
动态规划


带权区间调度
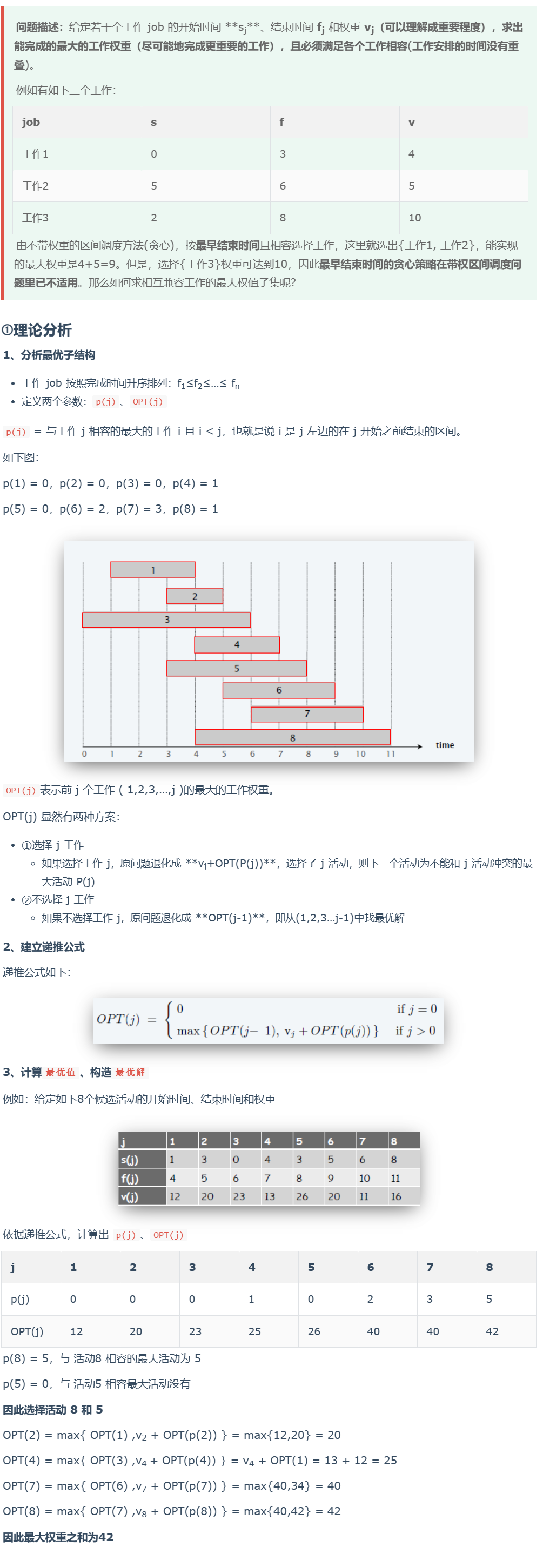
真题练习

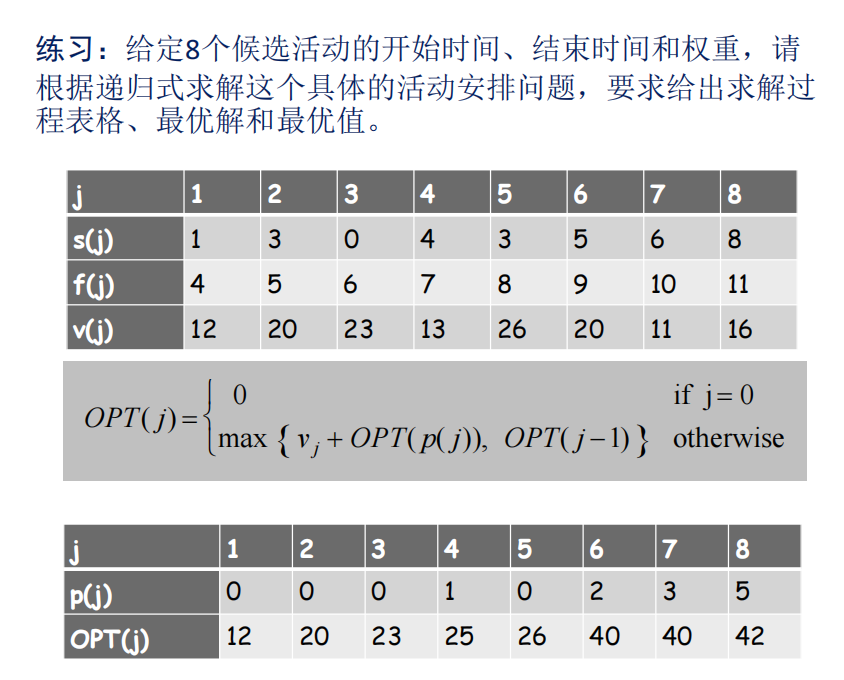
0-1背包问题

为什么矩阵中会考虑背包容量为 0 的情况,是因为,保证可以让任何一个物品都单独被选择出来,即 OPT(w - wi) 中的 w - wi 恰好等于 0 时。
当构造01背包最优解的时候,需要注意因为状态转移方程中如果不选,则有: f[i][j] = f[i-1][j],所以表格中如果列相同,则表明不选,比如下表最后一列,有两个相同的 40,则第 5 个物品不选,而往上没有不相同的了,则第 4 个物品要选,则前面物品的最大价值 = 总价值 40 - 第 4 个物品的价值对应的值(22) = 18,18 此时对应第 5 列,对应于向上当有三个物品时,前面的列没有相同的数值了,所以第 3 个物品要选。为 0 ,再网上所以是物品 3 和 4。
01 背包是 NP

这里输入的 n 就是线性的,因为后续输入了 n 个背包和物品,而 W 只输入了这数,针对内存是 2 l o g W 2^{log W} 2logW 的
NPC 问题的定义为: 所有 NP 问题都归约到这个 NPC 问题,NPC 是更难的问题,NPC 问题都找到了一个多项式时间算法,那所有 NP 问题也就有多项式时间算法,那么 P = NP.
多项式时间是相对于输入规模来说的,也就是说,当输入规模较小时,背包问题是多项式时间的,当输入规模较大时,背包问题是指数时间的。
真题练习

最长公共子序列

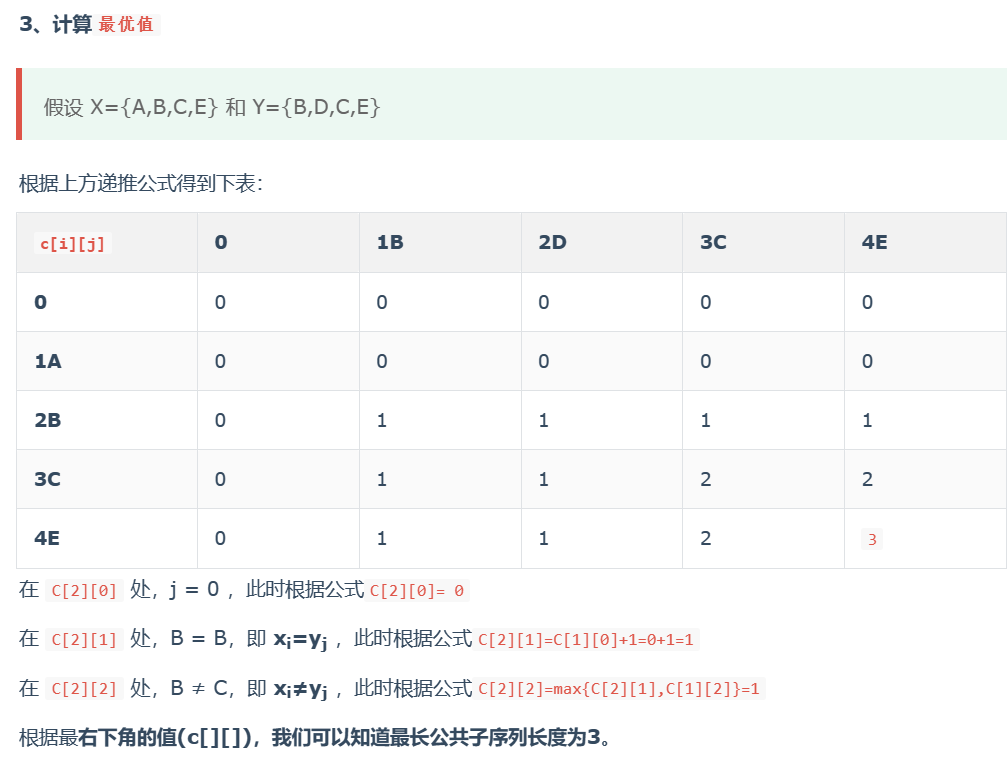
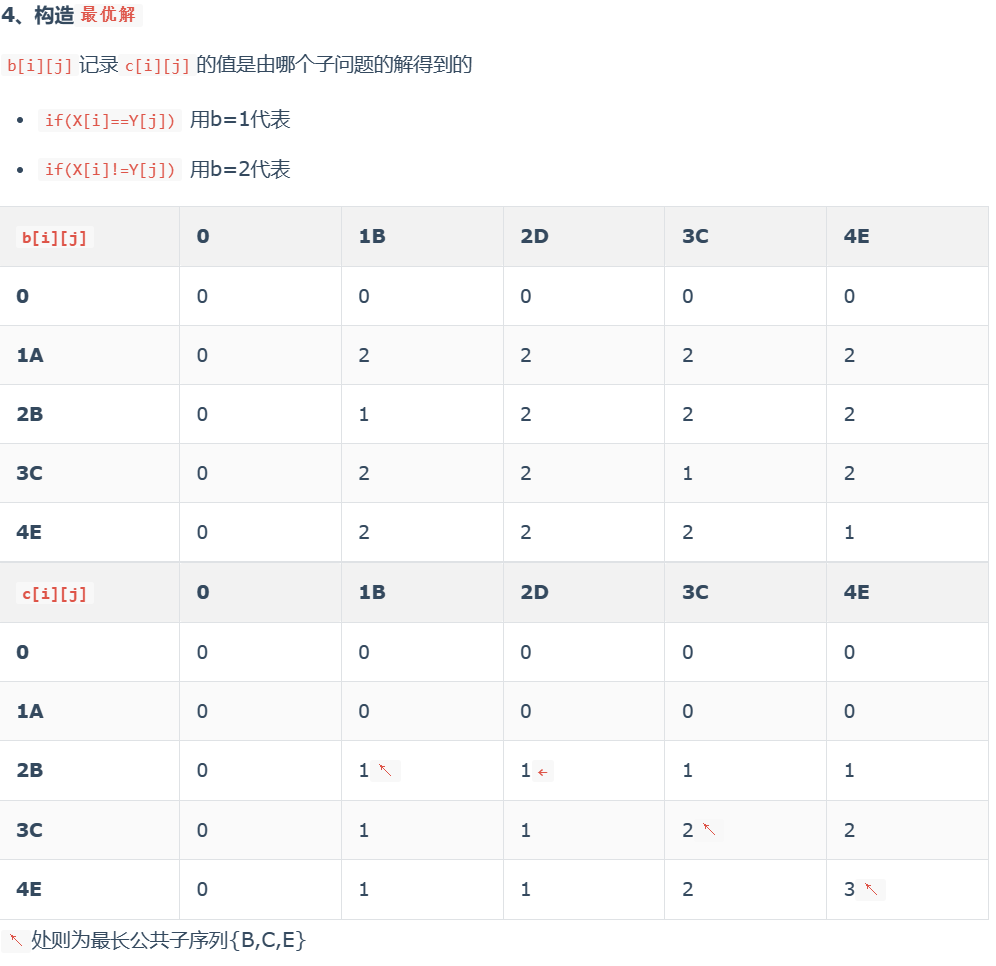
真题练习

题目一

题目二直接使用最长单调子序列求解
矩阵连乘

真题练习
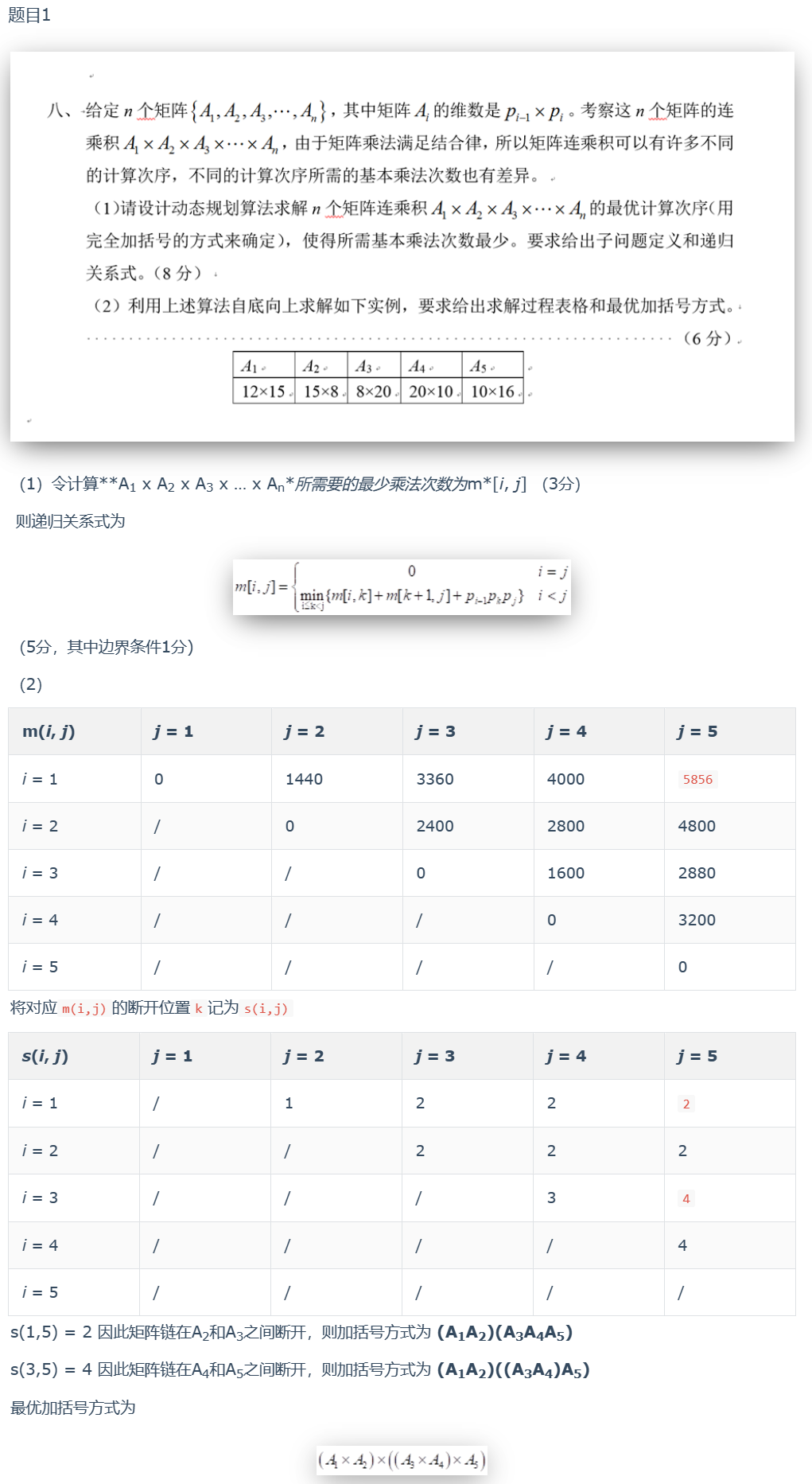
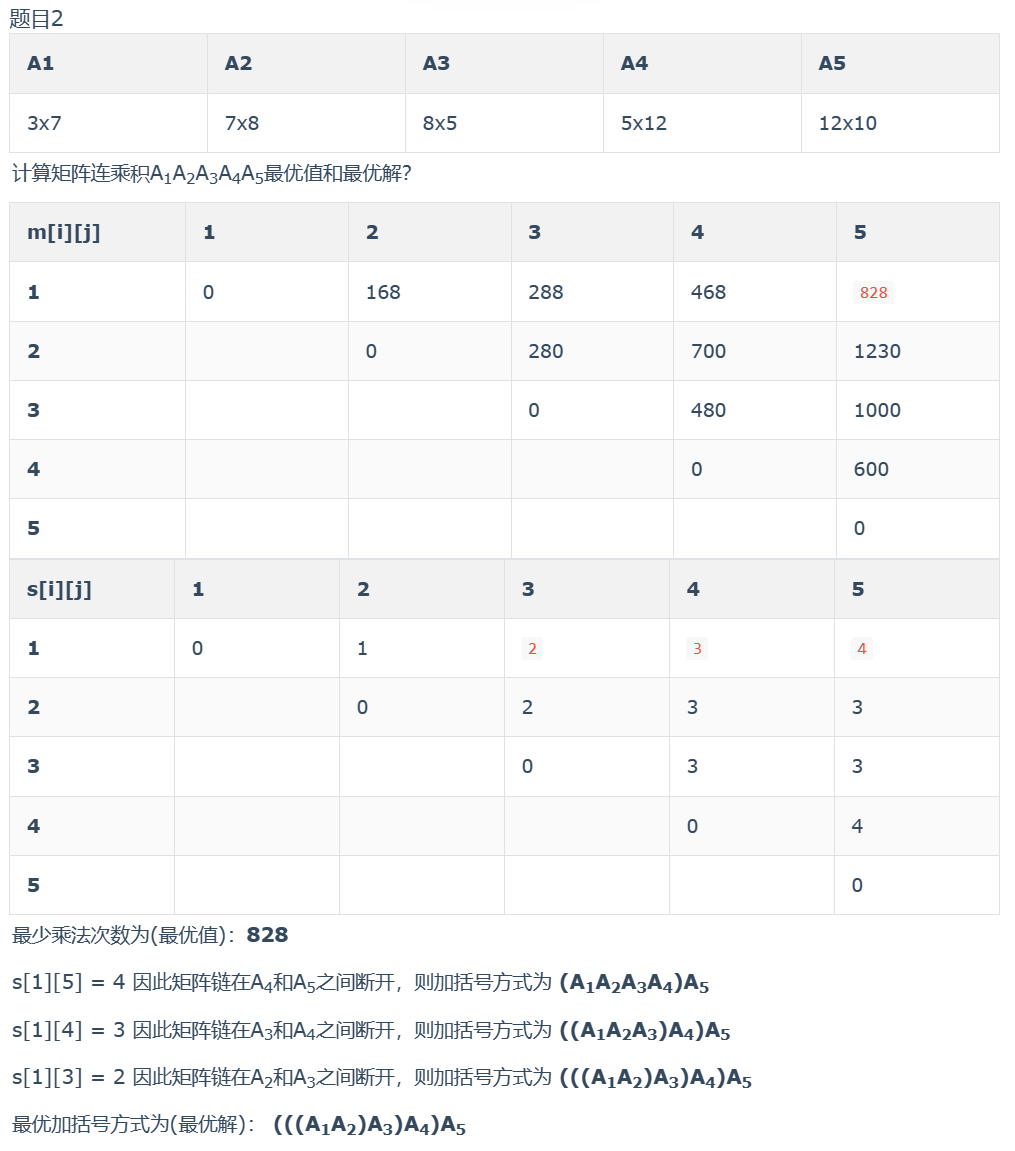

第3章:网络流

3. 掌握Δ-剩余网络构造方法,及求解网络最大流的capacity-scaling算法。
基础概念
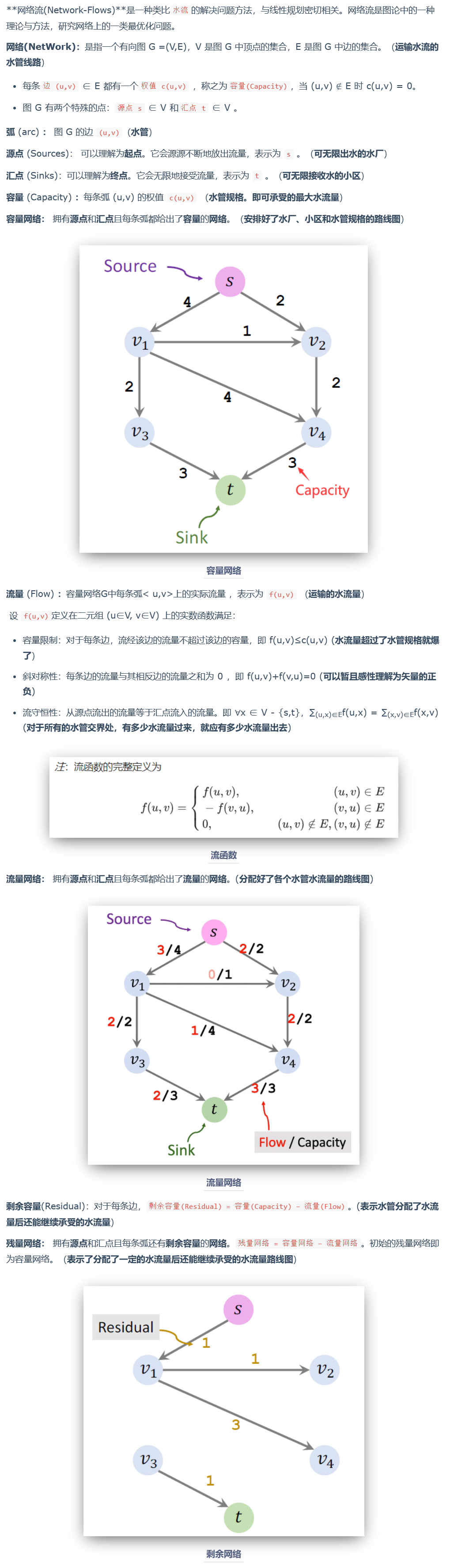
最大流
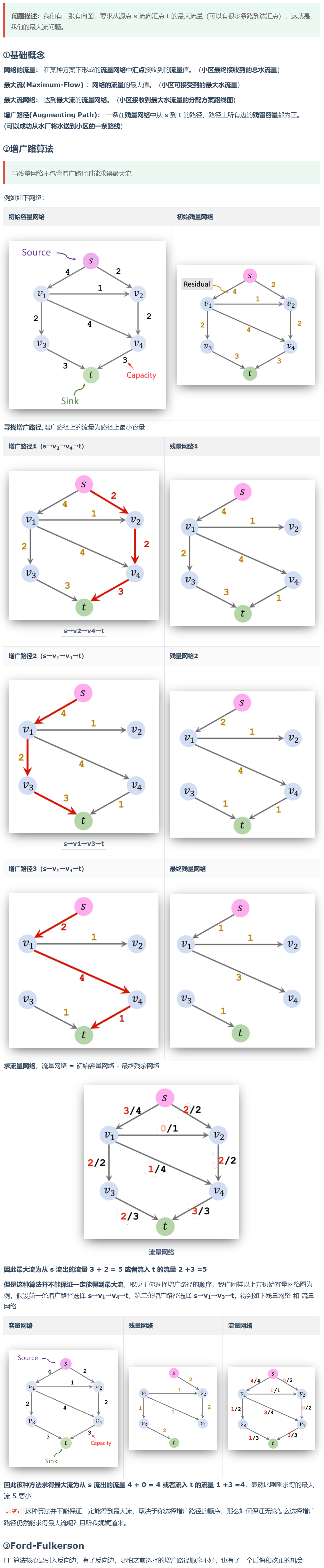
Ford-Fulkerson
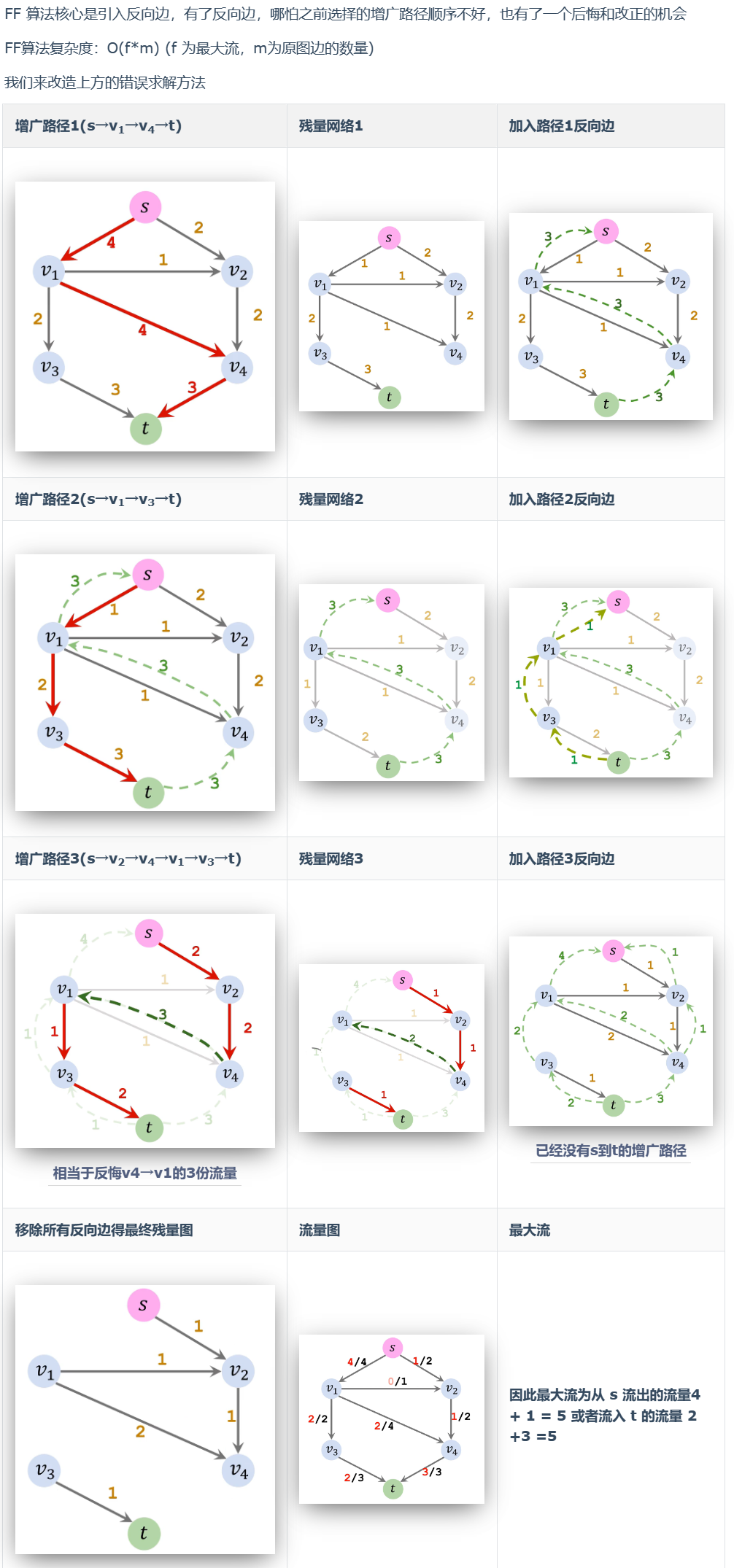
最小割


流与割
PPT 回顾
最大流贪心算法
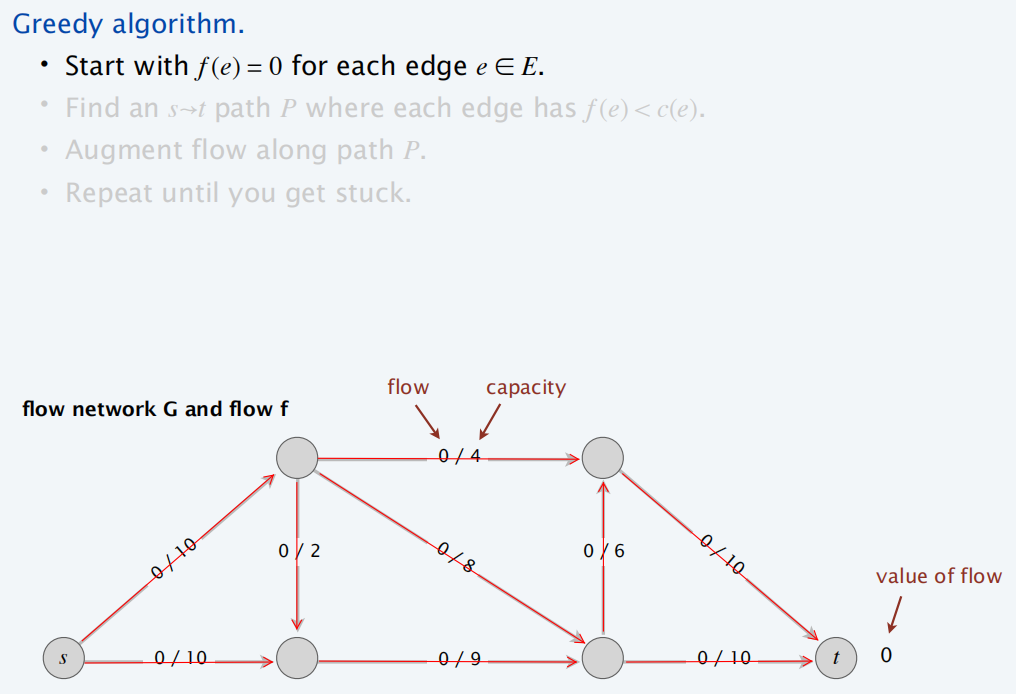
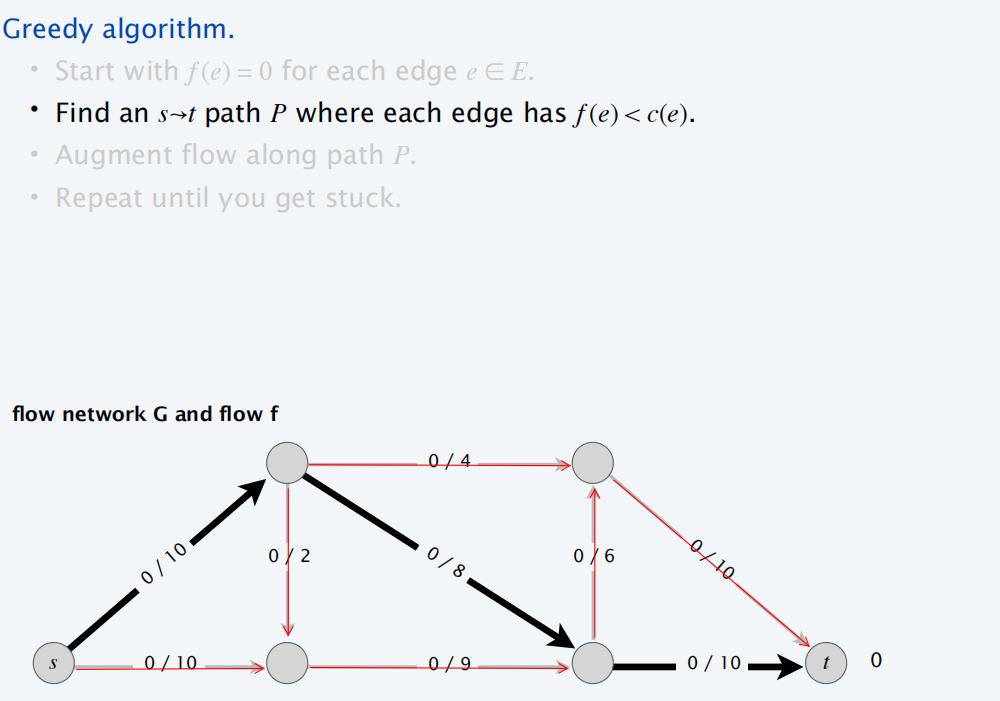
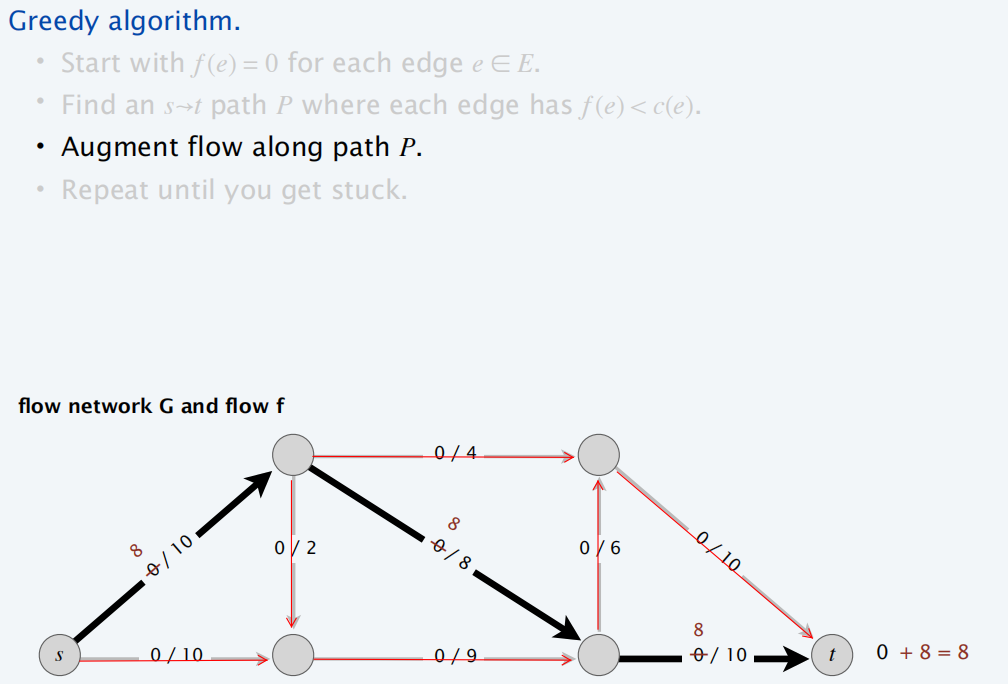


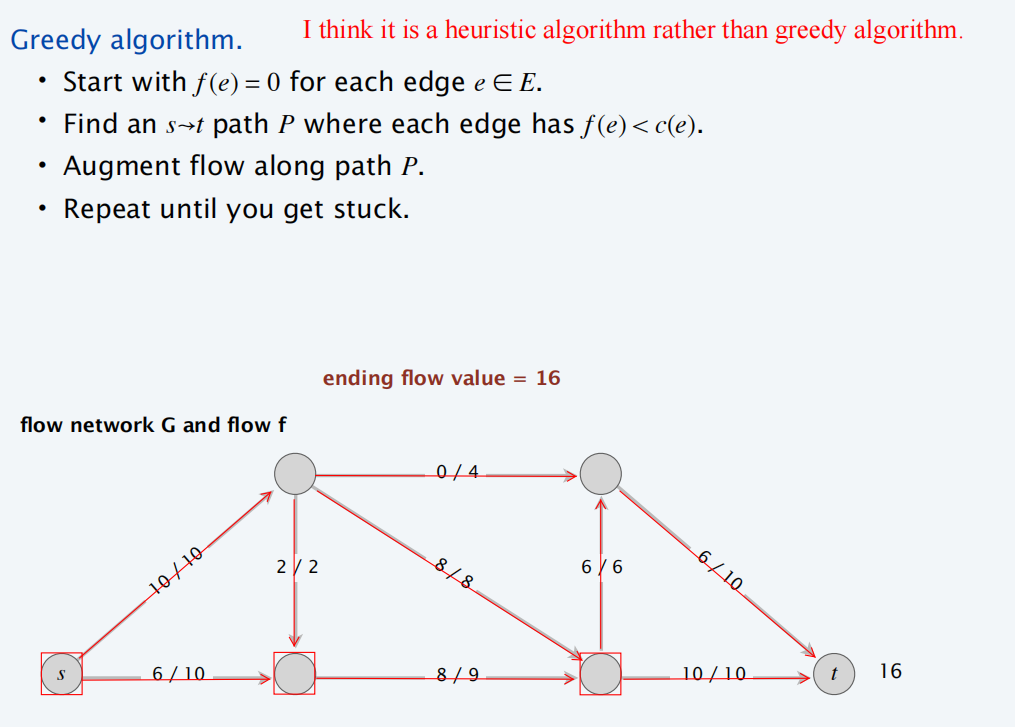
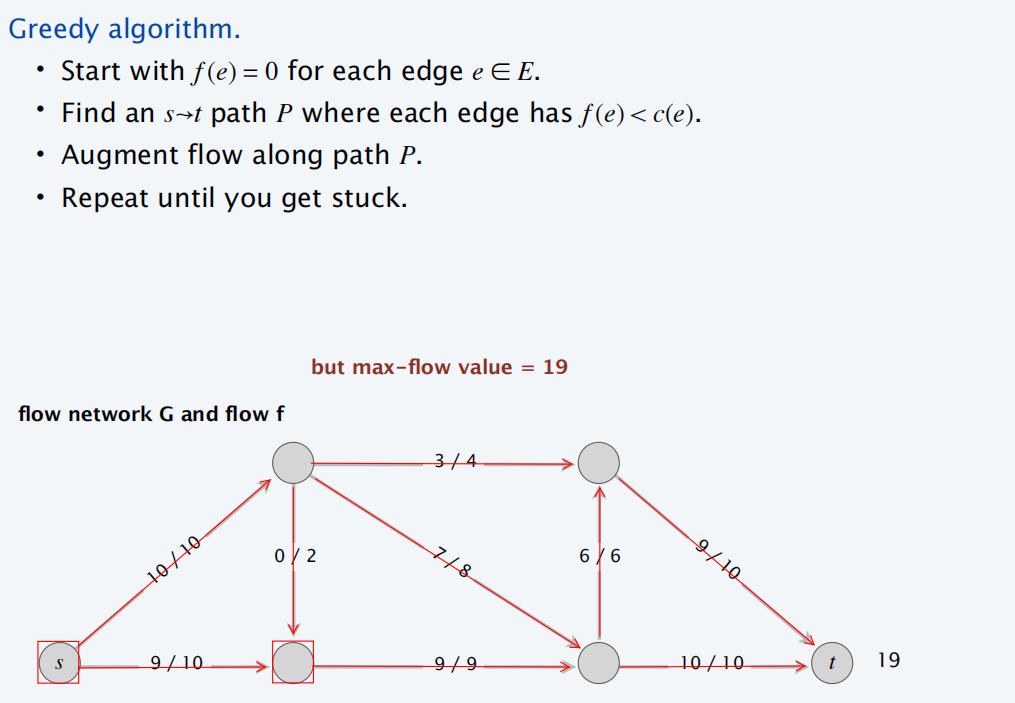
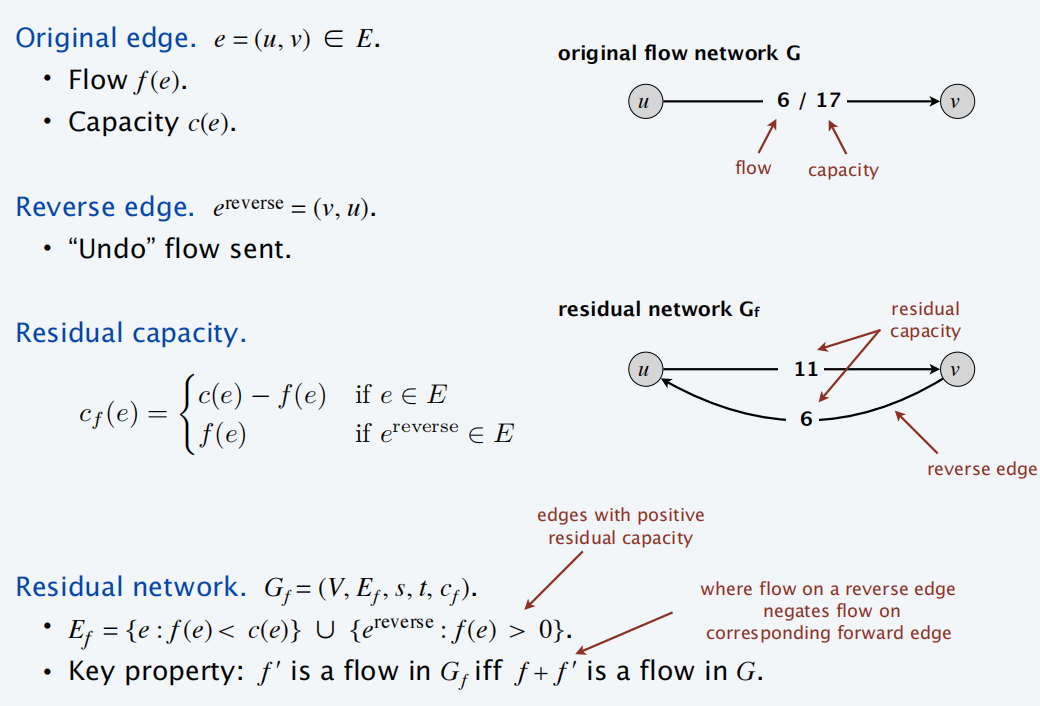
剩余网络
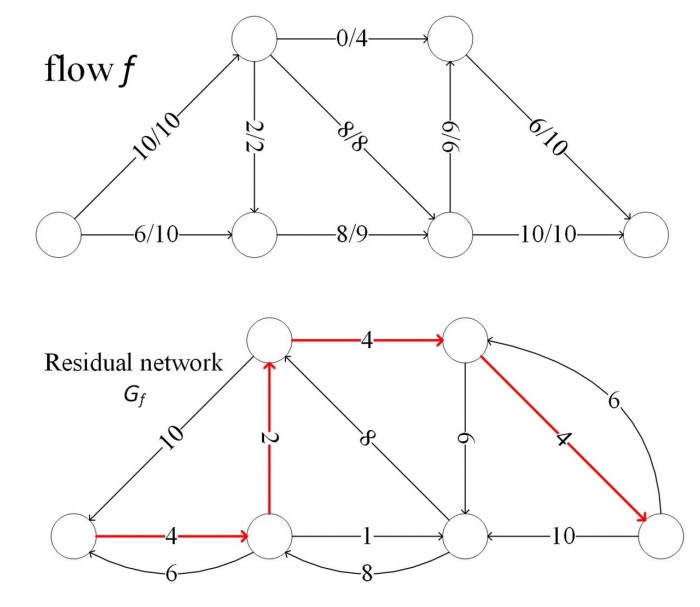

Ford–Fulkerson algorithm

B 站视频再理解
source:源点、sink:终点
Flow:流量、capacity:容量
Residual:残量、Residual Network:残量网络
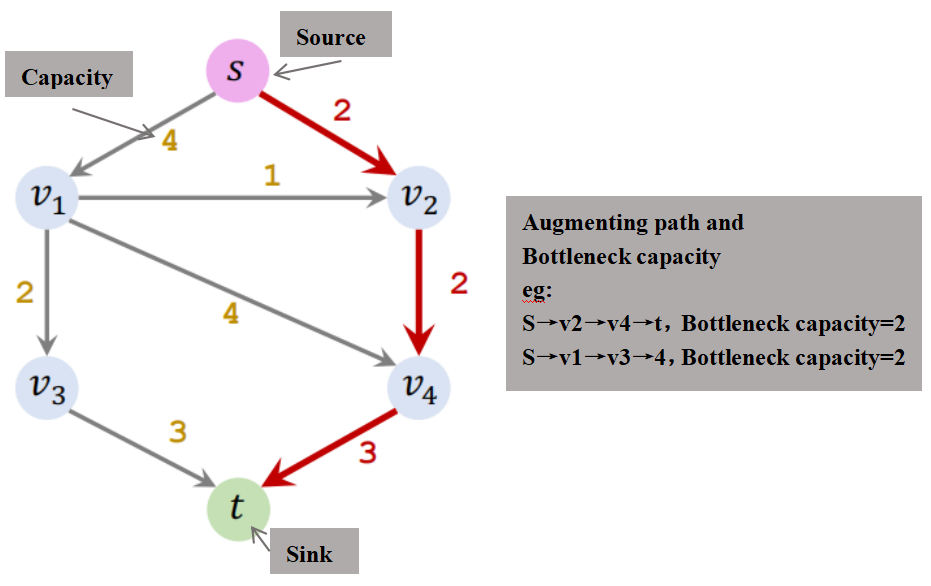
Augmenting path:增广路径,表示从源点 s 到终点 t 不包含环的路径
Bottleneck capacity:瓶颈容量
通过贪心算法,得到下面的残量网络:
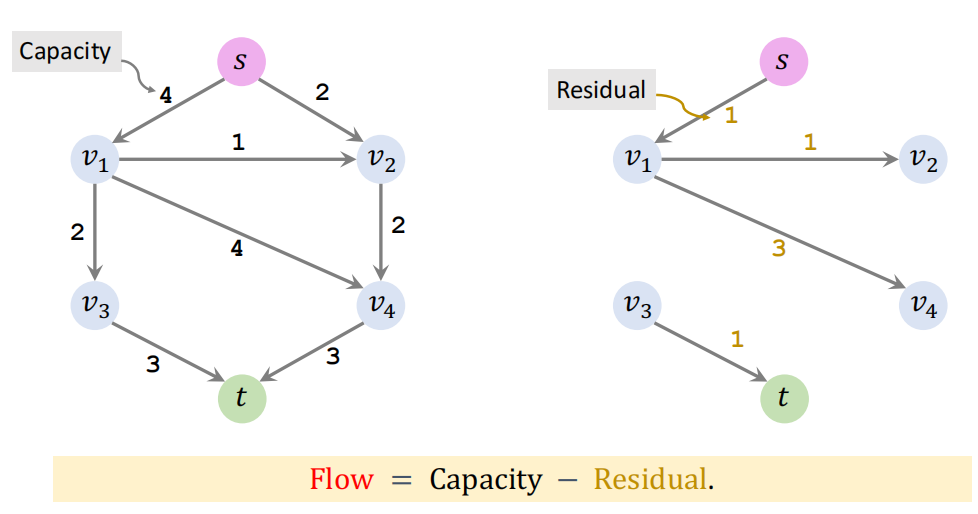
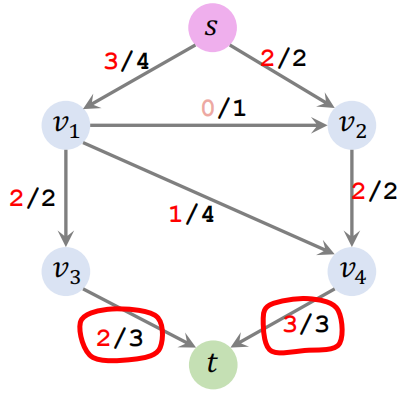
每条线上的流量和容量如下:
Ford–Fulkerson 算法复杂度证明
先看如下案例:
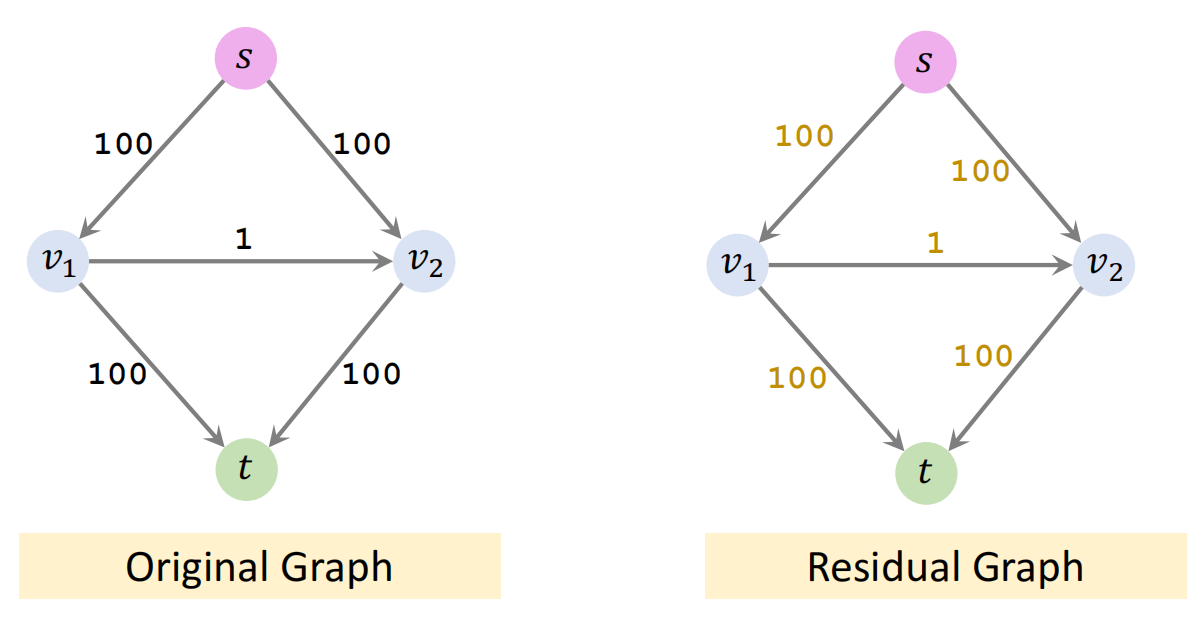
首先选择 S → v1 → v2 → t,并添加反向边

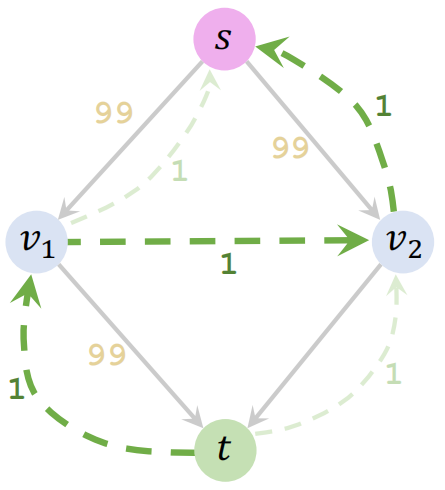
再下一次:可能就是 S → v2 → v1 → t,并添加反向边,这样循环,每次只能增加 1 的流量,相当于要迭代 100 轮
Worst-Case Iteration Complexity
- 每次迭代至少增加 1 的流量,所以迭代次数 ≤ 最大流量
- 在上面案例中,每次仅增加 1 的流量
- 总结:最坏情况,迭代次数 = 最大流量。
假设有 m 条边,寻找一条增广路径的时间为 O(m),最大流量为 f,那么最坏情况下的时间复杂度为 O(f * m)
Ford–Fulkerson 算法总结

循环结束条件为,找不到增广路径:
- 寻找一条增广路径(augmenting path)
- 找到这条增光路径上的瓶颈容量(bottleneck capacity)
- 更新残余网络
- 添加反向边
Ford–Fulkerson 的指数时间来源于对增广路径的选择,如下形式的选择,就只能每次增加 1 的流量,导致算法朝着指数的时间增长。
思考: 是否可以做出改变,每次选择更大的 bottleneck capacity?这样就可以有更少的迭代次数! (即选择最少的边,最大的瓶颈容量,Capacity-scaling algorithm 诞生)

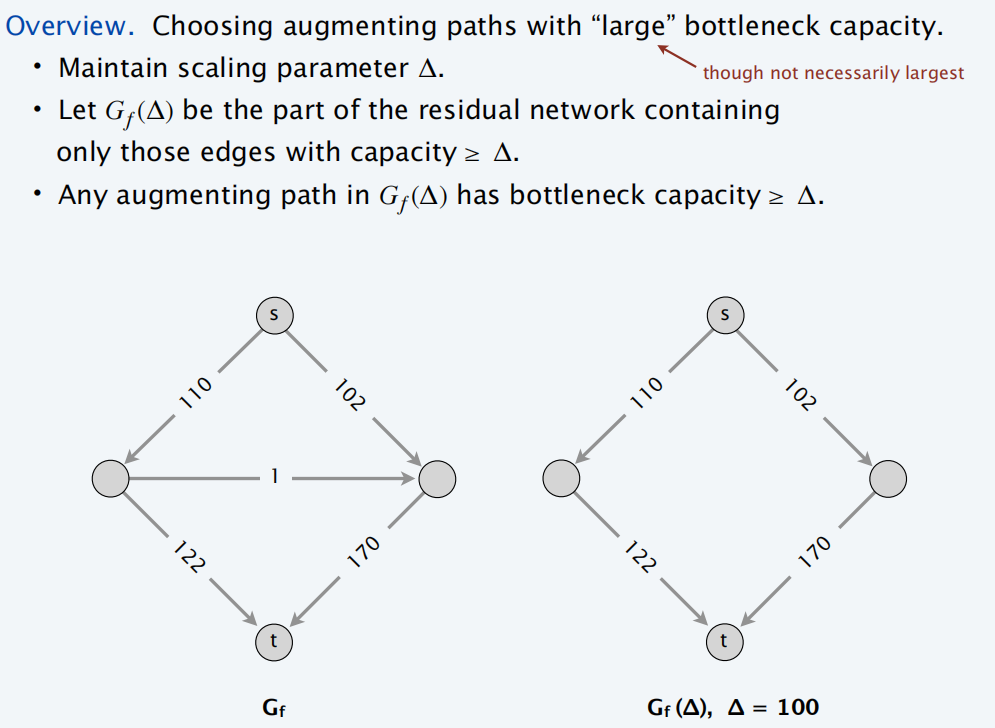
Capacity-scaling 算法
在 Capacity-Scaling 算法中,我们记录一个缩放参数 Δ \Delta Δ ,在每次迭代中,我们不关注整个 G f G_f Gf?,只关注 G f ( Δ ) G_f(\Delta) Gf?(Δ)。 G f ( Δ ) G_f(\Delta) Gf?(Δ) 是 G f G_f Gf? 的子图,只包括 G f G_f Gf? 中残存容量 ≥ Δ ≥ \Delta ≥Δ 的边。我们初始化 Δ \Delta Δ 为不大于最大容量 C 的最大 2 次幂,且在每轮迭代中缩小 Δ \Delta Δ 为 Δ / 2 \Delta/2 Δ/2。
迭代停止条件为: 当 Δ \Delta Δ 不大于等于 1时,因为最差的情况,每轮迭代,流量至少增加 1.

- E:图 G 所有的边
- f(e):流向 e 这条边的流量
- P:增广路径
- G f ( Δ ) G_f(\Delta) Gf?(Δ): G f G_f Gf? 的子图,只包括 G f G_f Gf? 中残存容量 ≥ Δ ≥ \Delta ≥Δ 的边
References
Capacity-scaling 算法来源及正确性证明
最小割案例


最小割不唯一:
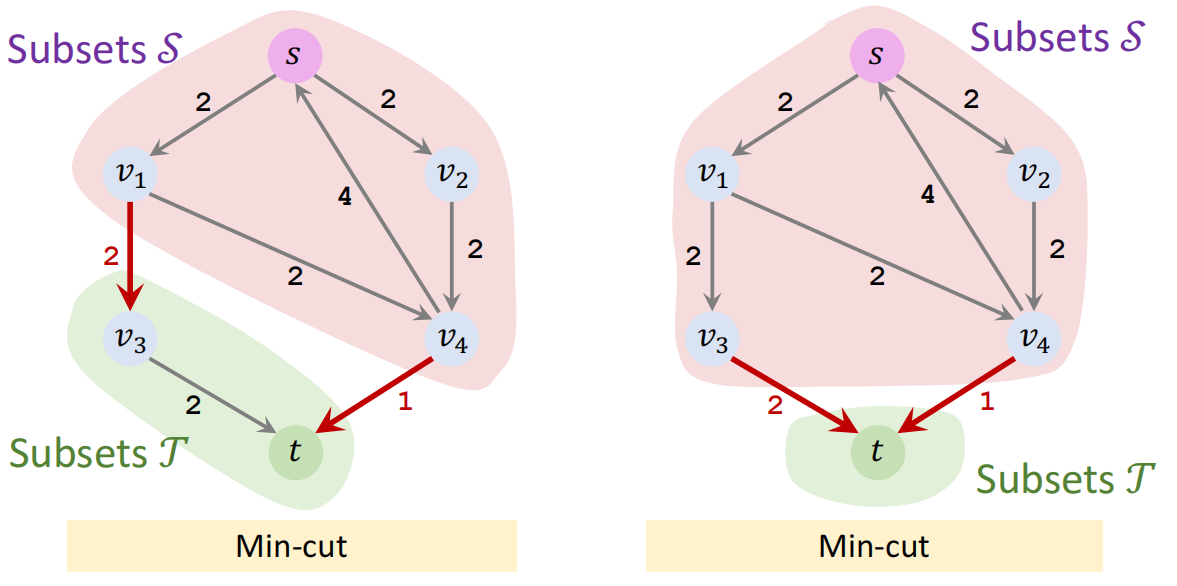
最大流求解最小割

- 通过最大流算法获得最终残余网络
- 寻找最小割(S,T)
- S ← 在剩余网络中,寻找 s 能够到底的所有点
- T ← 除开 S 中包含的其他点。

第 4 章:NP完备性理论


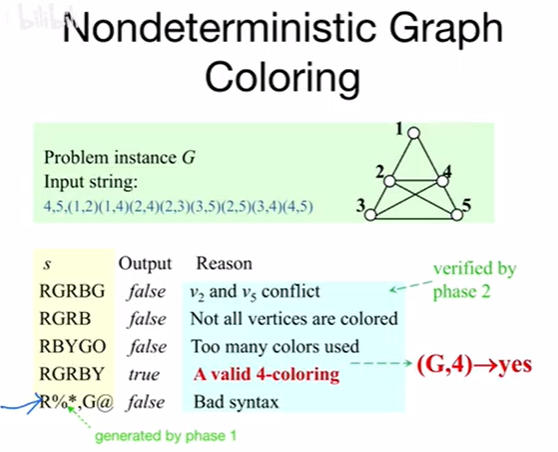
判定问题(Decision Problem)

判定问题(Decision Problem):第一步需要把输入描述清楚;第二步:抛出一个问题,判定问题只回答 yes or no(即正确还是错误,或者有还是没有)
判定问题与优化问题有什么联系?

判定问题是给定一个输入:只需要回答 yes or no 就行
优化问题是给一堆输入,比如一堆子图,序列等,甚至没有输入,需要找出问题的答案。
最大团问题(Maximum Clique Problem): 如 果 U 是 G 的子集,且 U 是一个完全图,则称U是G的完全子图。G 的最大团即 G 的最大完全子图。
注: 这里是使用最大团问题来对这些理论进行辅助说明

判定问题在某种意义上来讲,是和优化问题相当的。为什么这么说呢? 比如求最大团问题时,假设已经有这么一个判定算法,当我输入是否有一个包含了 k 个点的团时,只需要告诉我 yes or no,f(n) 表示是否包含 k 个点的团的判定问题,而对于需要计算 f(n) 的团,只需要问 f(1)、f(2) 、f(3) 、…、 f(n) 便可以知道结果。假如判定算法 f(n) 的时间复杂度为多项式 n c n^c nc 的,那么 问了 n 次后,时间复杂度为 n ? n c n * n^c n?nc,认为也是一个多项式的时间复杂度,从而也印证了,优化问题从某种意义来讲,与判定问题相当(相当于对判定算法的 n 次调用)
即当一个问题,能通多判定问题在多项式时间内解决,又能通过多项式时间内调用这个判定问题,从而解决这个优化问题,就表示这个优化问题和这个判定问题是相当的。
这样做的目的:将优化问题转化为判定问题去分析讨论,是为了讨论比较不同的算法,如果直接按照优化问题来看,输入不同,输出也不同,比如排序问题,输出一个数组,最短路问题输出一个最短路,这如何去比? 没法比,因此转化为判定问题来讨论后,即可比了(虽然输出不一样,但是如果我输出 yes 你也输出yes,我输出 no 你也输出 no,这个对于后续的规约问题也很大用处)
因此第一步需要做什么?那肯定是先将问题转化为判定问题啦

-
第一个:图染色这个优化问题,转化为判定问题时:是否存在最多用 k 个颜色进行染色,使其满足条件,k 取 1,2,3,4…。
-
第二个:一堆任务,执行任务的顺序,最小化扣分值。判定的描述:给定一个扣分的分值上限 K,能否找到一个策略,使得扣分的上限不超过K,只需回答 yes or no

-
第三个:装箱问题,K 个箱子,n 个物品,最小需要多少个箱子可以将这个 n 个物品装进行。判定问题描述:这最少需要,肯定有一个数值,但是不知道这个数值是多少,可以自己定一个 m = 1, 2, 3, … ,然后问,是否可以将这 n 个物品装进 m 个箱子中,能装进去则停止问。
-
第四个:背包问题。判定问题:直接问,给 n 个物品和容量 C。。。。,能否使得总价值是大于等于 k 的

-
第五个:CNF-SAT 合取范式。 其中的变量赋对应值为 False 或 true,使其最终结果为 true,不需要转化为判定问题,本身就是判定问题
-
第五个:Hamiltonian 圈。给你一个图,能否找到一个路径,使得一次且仅一次便经过所有点。判定问题:给一个图 G,直接问,图 G 有没有 Hamiltonian 圈。
-
第六个:旅行家问题,判定问题,给你一个图G,是否存在一个 Hamiltonian 环,使得代价为 k。
说在前面: NPC 问题可以用于揭示问题与问题之间的关联。(A与B的关联);其次来了个问题 C,可以分析问题 C 大概在什么样的一个难度
P 问题
首先多项式时间表示 : n c , c = 1 , 1000 , 1000000 n^c, c = 1, 1000, 1000000 nc,c=1,1000,1000000 都一样
一个多项式时间内的算法能够解决的问题,即为 P 问题


转换思路: 如果有一个多项式时间内可解决的问题 B,要设计一个多项式时间内的算法解决问题 A,可将问题 A 的输入通过多项式时间转化为了问题 B 的输入,恰巧问题 B 又是多项式时间能解决的,那就找到了 A 的一个多项式时间解法。
Nondeterministic Algorithm 不确定算法
-
算法内容时,先随机产生解,再判断是否正确,不正确则从新产生。
-
比如排序:我随机产生一个序列,检查这个序列对不对,只需回答 yes or no。

NP 问题
对于一个问题,我们无法准确的给出一个多项式时间内的解法,我们退一步,只需要多项式时间内验证一个解是否正确,正常情况只需要遍历一遍,回答 yes or no 即可。
一个问题能在多项式时间内告诉我 yes or no 的,就是 NP 问题

P 与 NP 问题有什么关系呢?
-
对于 P 这个问题,需要设计一个确切的算法去解决这个问题
-
而换到了 NP 这个问题,就变为了验证这个解是否有效。(NP 问题为什么难呢,是因为它可以在多项式时间内可验证,但不一定能在多项式时间内求解)
-
需要注意的是,NP 问题只是说可在多项式时间内可验证,并没有说不能在多项式时间内可解,这是没有因果关系的。
-
因此这样的说法表示,NP 问题不一定不是 P 问题,因此 NP 问题是包含 P 问题的,即有部分 NP 问题是可以在多项式时间内求解的,但是还没找到,或不存在。


对于图着色问题,随机生成一个解,算法进行验证,所有的边都遍历一遍,多项式时间内即可验证,因此为 NP 问题。
最大团,随机 n 个里面选 k 个,判断是不是团,即是不是完全图,也是遍历一遍边即可多项式时间内判断。

和取范式(SAT),也是随机产生一组解,然后算法遍历去检查,即可再多项式时间内验证。

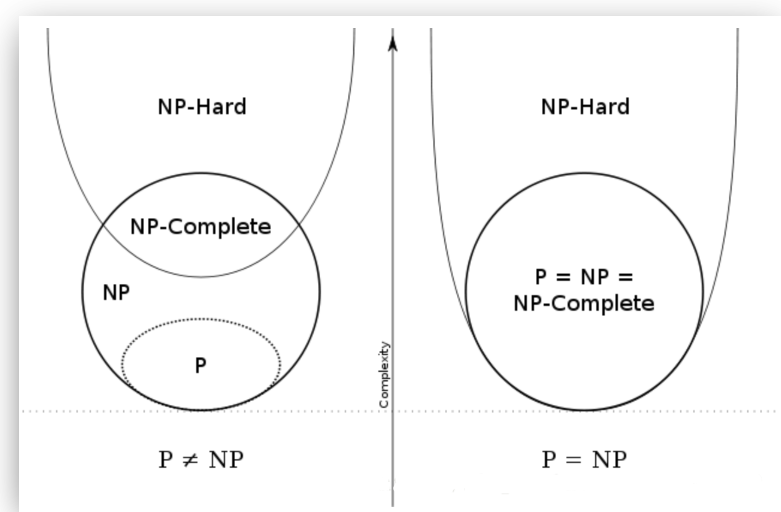
我们现在知道了 P 与 NP 是包含关系,
那 P = NP 与 P ≠ NP 又是什么呢?因为如果所有NP问题可以在多项式时间内求解,不就是 P = NP 了吗,于是出现了下图:(注意:是所有 NP 问题,后面会降到如果一个 NPC 问题找到了多项式时间算法,那么 P = NP 也成立)
归约
归约可以看作是一个工具,可以通过这个工具将两个问题建立关系。
- 一、去解决一些未知的问题
- 二、将问题划分到 class 内
比如 word A 变为 word B,需要进行添加,替换等一系列操作。而问题A和问题B也是一样的,将问题 A 归约到问题 B 的过程,就需要把它们不一样的地方变为一样的。(即输入输出形式)
A:in out
B:in out
前面讲到优化问题:输入输出都不一样。
当转化为判定问题时,输出即为 yes or no,此时重点就只需要将输入转化为一致即可。
下图:首先有一个P问题的输入 x x x,我们需要设计一个解决 P 问题的算法。现在不想直接解决 P 问题,我有一个工具 T,可以将 P 问题的输入转换为 Q 问题的输入,正好有一个解决 Q 问题的算法,直接将转化后的输入 输入到 Q 中,即可得到结果。
但是有个问题:还差一步,最后的 yes or no 要对得上,上帝视角,如果 P 问题的输出是 yes, 那么转化成 Q 问题的输出也要是 yes 才行,不能瞎归约。
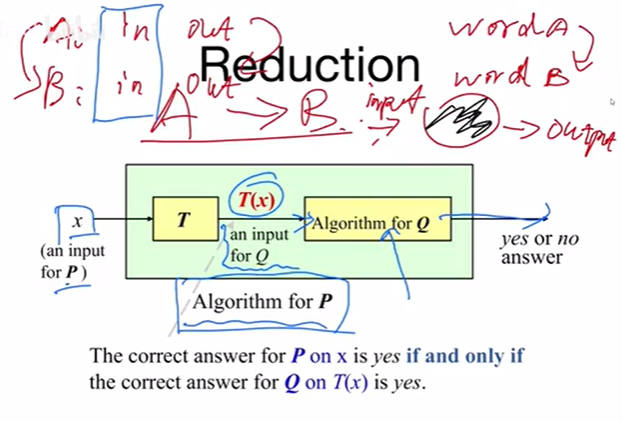
举例:(这里的 P 问题就是一个普通的问题,不是 NP 问题中的 P 问题)
P 问题: 给一个序列,布尔变量,这里面是否存在至少一个元素的值为 True 时,存在则输出 yes,否则输出 no。([False True False True True True False False])
Q 问题: 给一个序列,是整数,是否存在最大的元素是正的,存在则输出 yes,否则输出 no。([1 2 3 4 5 6 1 -1 -4])
P 问题输入转到 Q 问题的输入:两个都是序列,格式相同,将 P 中的 False 转化为 0,将 P 的 true 转化为 1,输入到 Q 中,当 Q 中,存在一个 1,满足元素时正的,输出 yes,全为 0 时,不满足最大元素正的,输出 no,结果和 P 问题一致。

但是这个输入的转化是需要时间的,需要根据具体问题进行讨论
现在考虑如果算法 Q 是多项式时间的,并且 P 的输入能多项式时间转化为 Q 的输入,则找到一个多项式时间算法解决这个问题。这个就叫多项式时间归约

现已知 Q 能够解决,Q 不一定是多项式时间算法内,可能解决起来非常复杂,不在乎。但是我们问题 P 现在未知,但是能将其的输入转化为问题 Q 的输入,让问题 Q 去解决,那么说明,问题 P 是比问题 Q 更简单的,因为问题 P 就算再难,我都能通过转化输入,然后让问题 Q 去解决。
归约是 NPC 问题的一个抓手

P 问题的所有输入点,在 Q 问题中要找到位置,但并不是说 P 问题的输入点形成的空间,在转化到 Q 问题的输入空间时,占据了 Q 问题所有的输入点,而是 Q 问题输入点的子集也可以。只要能在 Q 问题中找到映射即可。
反过来,问题 P 解决了,问题 Q 没解决,就不能用规约的方式来解决。因为在 P 转化为 Q 的过程中,P 的输入集只是 Q 的输入集的子集,还有一部分是没有解决的。

NP 问题是随机生成一个解后,再去判定这个解对不对
归约不能去帮助你解决问题,但是可以告诉你什么样的问题是 NPC 的,什么的问题是怎么怎么样的

假设有一个算法已经可以解决 Q 了,现在有个转换函数,可以将问题 P 的输入转化为问题 Q 的形式,就可以用问题 Q 来解决了,现在需要对这个转换函数 T 进行一个精细化调整,以致于 P Q 问题的答案 yes 对 yes,no 对 no,

归约到底干啥用的呢?
用处在于对于 NPC 问题提供了一个很好的抓手,用于度量一个问题的难度。
归约实际上建立了一个 P 与 Q 问题的关系,P 归约到 Q,实际上 P 就比问题 Q 更简单。因为从输入规模将,P 问题的输入是 Q 问题输入集合的子集。
实际上有些问题都不能在多项式时间内去判定,这个时候就需要我们借助归约去判定,
来了一个未知问题 Q,需要去和 NP 集合中的所有问题去比,所有NP问题都归约到 Q 问题,也意味着,Q 问题比所有 NP 问题难,即 NP-Hard
NPC 问题说的是,一个问题即是 NP 问题又是 NP-Hard 问题

直观感受,当 P ≠ NP 时, P 比 NP 简单,NPC 是 NP 问题的天花板,
如果 P = NP了, 意思是 NPC 哪怕是问题里面的天花板,还是 P 问题,所以 P = NP = NPC, 哪怕这个算法还没找出来,但是可以判定,一定存在。
什么是 NPC 问题呢?
首先需要判定是 NP 问题,只需要在多项式时间内可判定即可。简单
NP-Hard ,要求所有 P 问题都归约到 这个 NP 问题,总不能所有的都归约一下吧,怎么办呢?归约这个工具是具备传递性的,已知一个问题是 NPC 问题,那它就一定是 NP-Hard 问题,它是 NP-Hard 就说明了任何的 NP 问题都可以归约到它,
现在已知 P 是一个 NPC 问题,要证明 Q 是一个 NPC 问题,只要将 P 归约到 Q 即可。

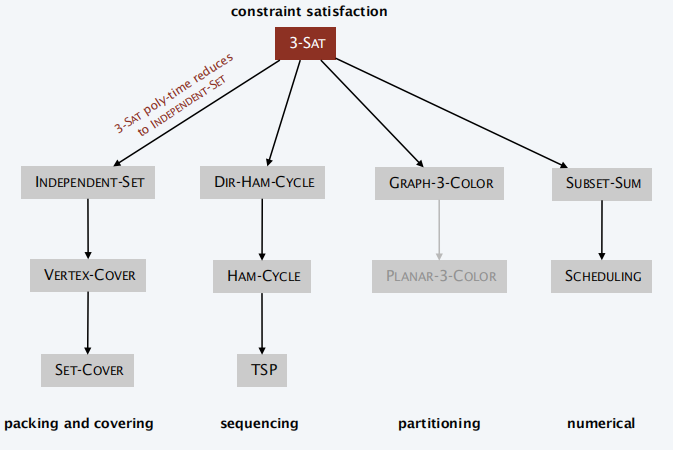
第一个 NPC 问题便是 SAT 问题

SAT 问题是一个很大的问题,下分了多种类型,有 CNF-SAT:合取范式,也有 3-SAT 问题
3-SAT:表示三个变量的合取范式问题。
3-SAT 是已知的 NPC 问题,要将 3-SAT 问题归约到 Q 问题,即可证明 Q 问题为 NPC 问题,这个时候就需要调整输入,

比如最开始证明了 3-SAT 是 NPC 问题,通过 3-SAT 证明了团问题是 NPC 问题,那么就可以通过团问题,去证明其他问题是 NPC 问题。
P&NP&NPC
P 问题: 多项式时间内被求解。
NP 问题: 多项式时间内被验证。
NP-Hard: 所有的 NP 问题都归约到 NP-Hard 问题,算法不一定能在多项式时间内被验证,并且不一定有多项式时间的求解方法
NPC: ① 算法可以在多项式的时间内被验证,但是是 NP 问题中最难的一部分问题,NP 问题的天花板,② 所有 NP 问题都归约到这个问题

多项式时间归约


① 顶点覆盖 ≡p 独立集
顶点覆盖: k 个顶点的子集,图中每条边都能在这个子集中找到与之相连的顶点。
独立集问题: k 个顶点的子集,任意两条边不相连。


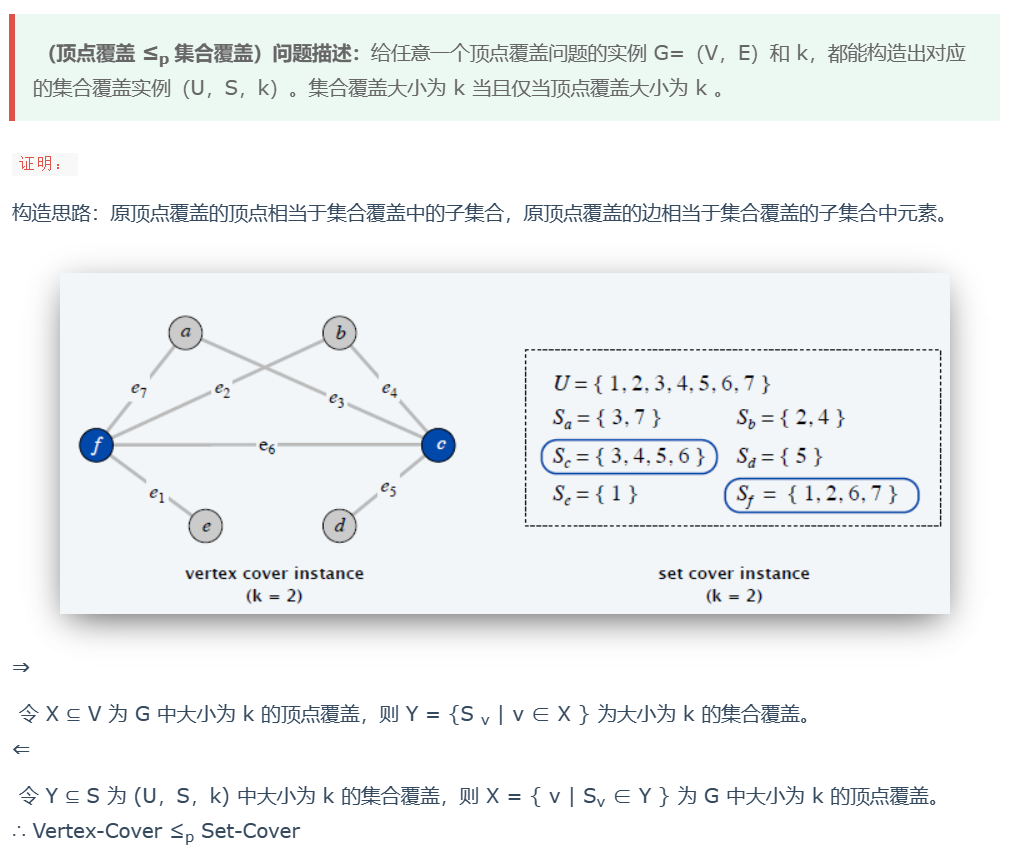
② 顶点覆盖 ≤p 集合覆盖
集合覆盖:题目应该是至少含有 k 组子集,即 ≤ k 的子集并起来包含了全集

将顶点覆盖的输入转化为集合覆盖的输出,证明,当顶点覆盖回答为 k 时,集合覆盖也要回答为 k。当集合覆盖回答为 k 时,顶点覆盖也为 k
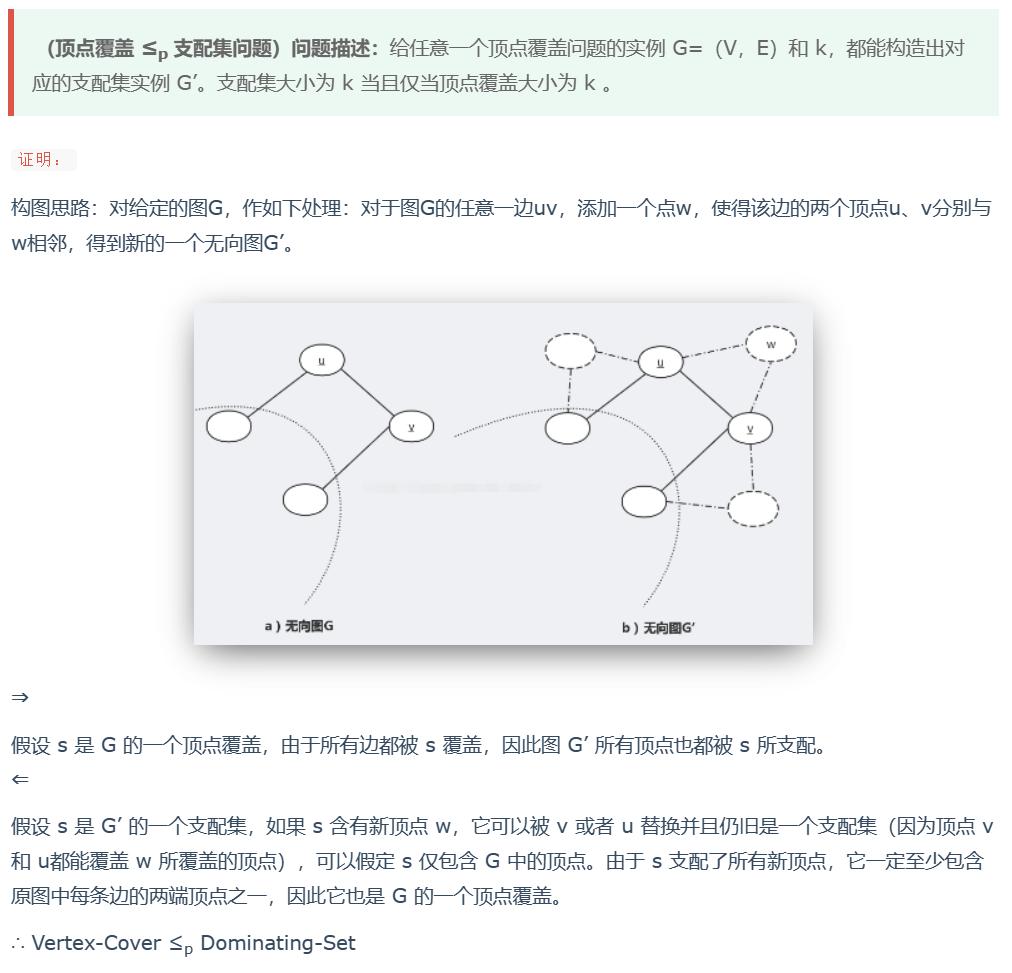
③ 顶点覆盖 ≤p 支配集
支配集问题: 给定无向图 G 和正整数 k, 问图 G 中是否存在 k 个顶点的子集 S,使得对于图 G 中的任意顶点 v,要么 v ∈ \in ∈ S,要么 v 至少与 S 中的至少一个顶点相邻。(图G中除了支配集之外的点都与支配集中至少一个点相连)
通俗地讲,支配集就是将一个图的点集分成两个部分,这两部分点中任意一个点都与另一部分有边相连。
证明顶点覆盖 S 中顶点与其他顶点相连,相连也就相互支配了

顶点覆盖表示: 每条边至少有一个顶点在顶点覆盖集合内
支配集表示: 每个支配集以外的顶点一定与支配集中某个顶点相连
因为所有边都与支配集中的点相连,每条边加上一个顶点连过去得到 G’,这些新加的顶点肯定也会与支配集中的顶点相连
如: {v1, v3} 为支配集,同时也是顶点覆盖集,添加新的点 w 时,所有 w 同样被 v1,v3 所支配(所覆盖)
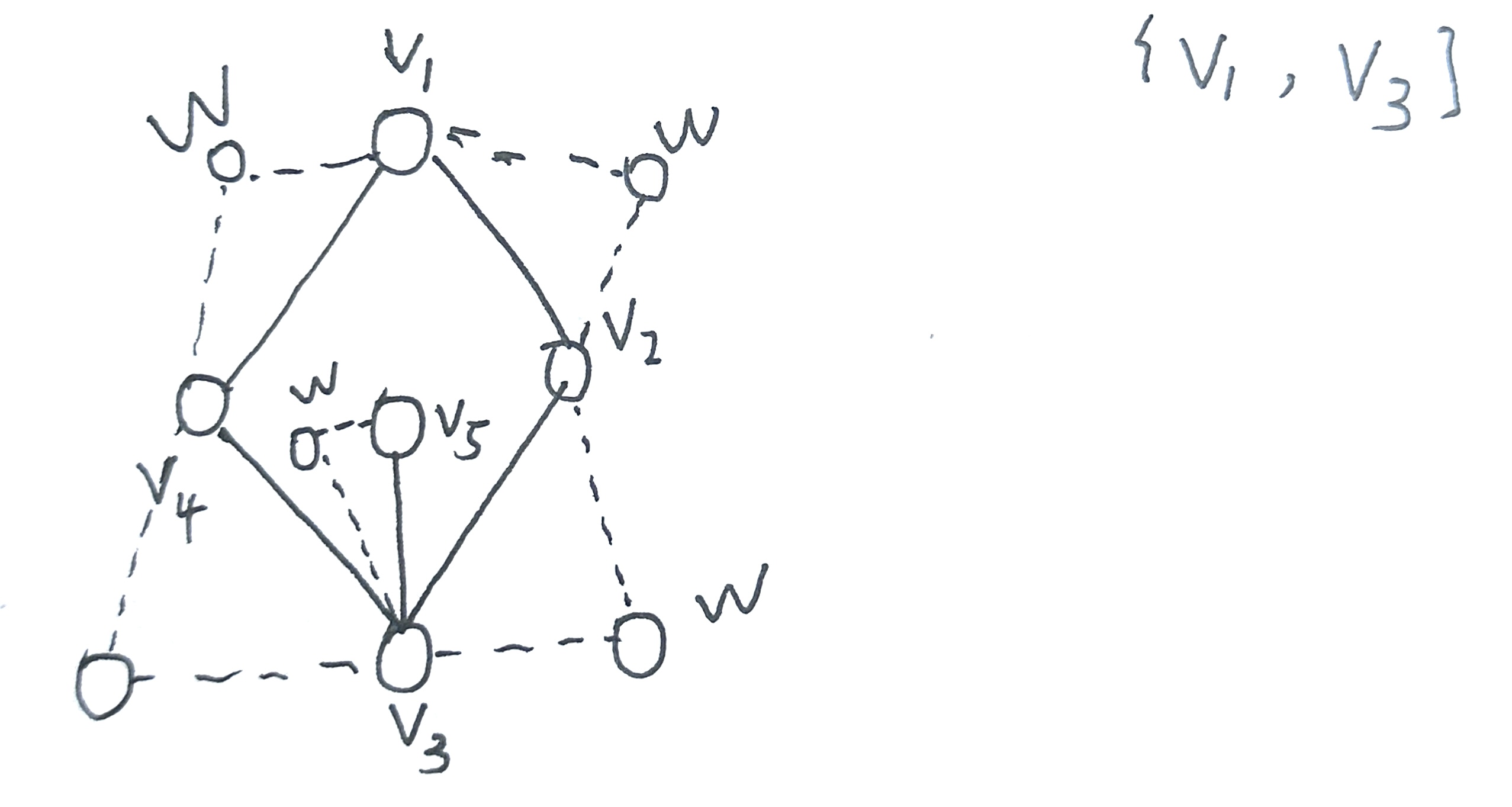
因此: 假设 s 是 G’ 的一个支配集,如果 s 含有新顶点 w,这个 w 是可以被 v 或 u 替换的,因为 w 支配覆盖 v 和 u,即顶点 v 或 u 都能覆盖 w 所覆盖的顶点。因此可以直接假设 s 仅包含 G 中的顶点。由于 s 支配所有顶点,它一定至少包含原图中每条边的两端顶点之一。
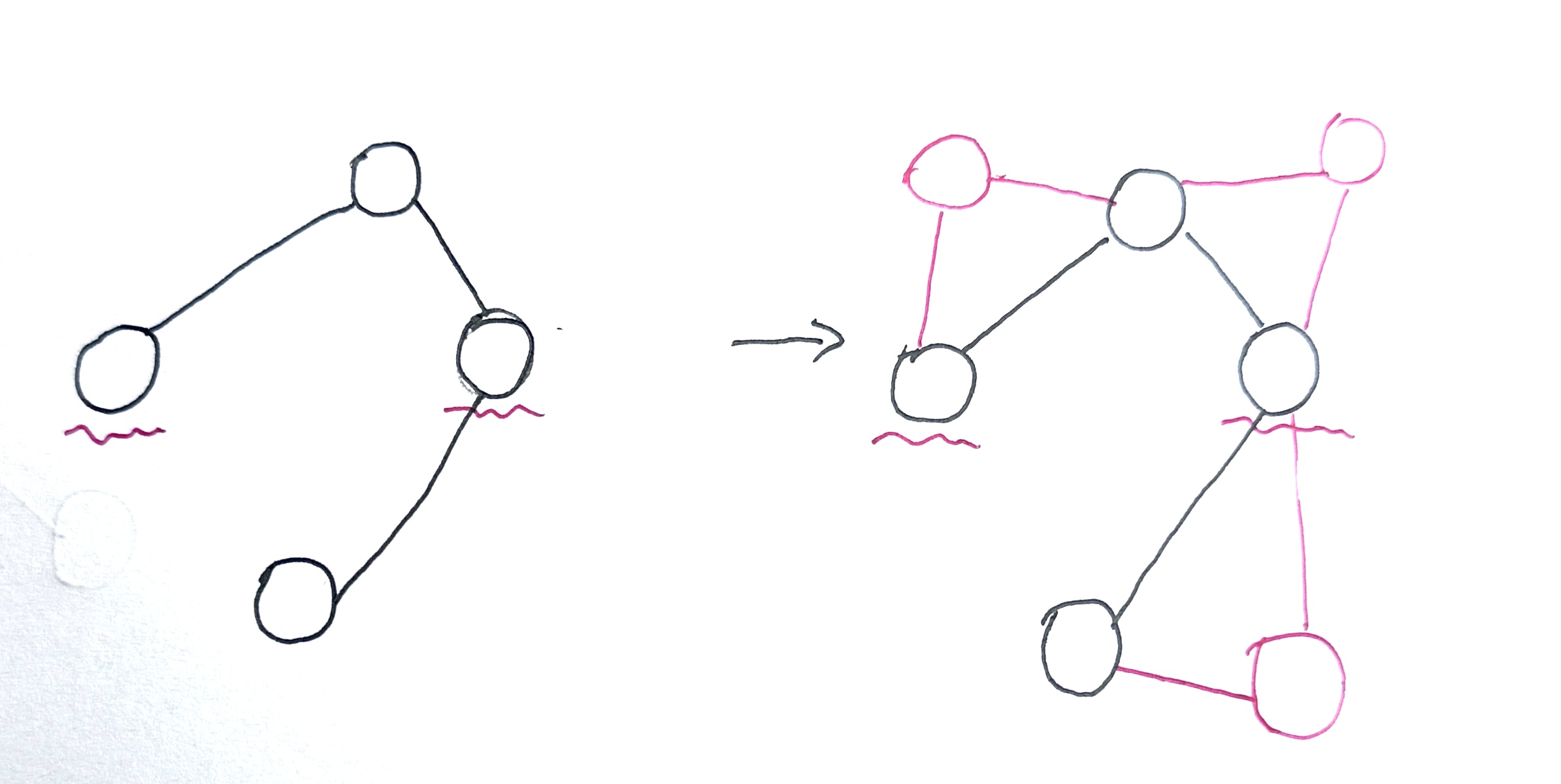
正向证明时,为什么会说: s 是 G 的一个顶点覆盖,由于所有边都被 s 覆盖,因此图 G’ 所有顶点也都被 s 所支配;是因为每条边都有一个端点连接到 s 中的顶点,而 G’ 中加入的新顶点,连接到了每条边的两个端点,必要会连接到 s 中的一个顶点,如下图:(波浪线为顶点覆盖集同时也是支配集)
④ 3-SAT ≤p 独立集

思路: 每个句子对应一个三角形,句子取反的两个三角形中的变量连接起来。

注: 第二点证明有误,当 ? \phi ? 被满足,在 k 个句子中选择 k 个变量设置为 true 才对
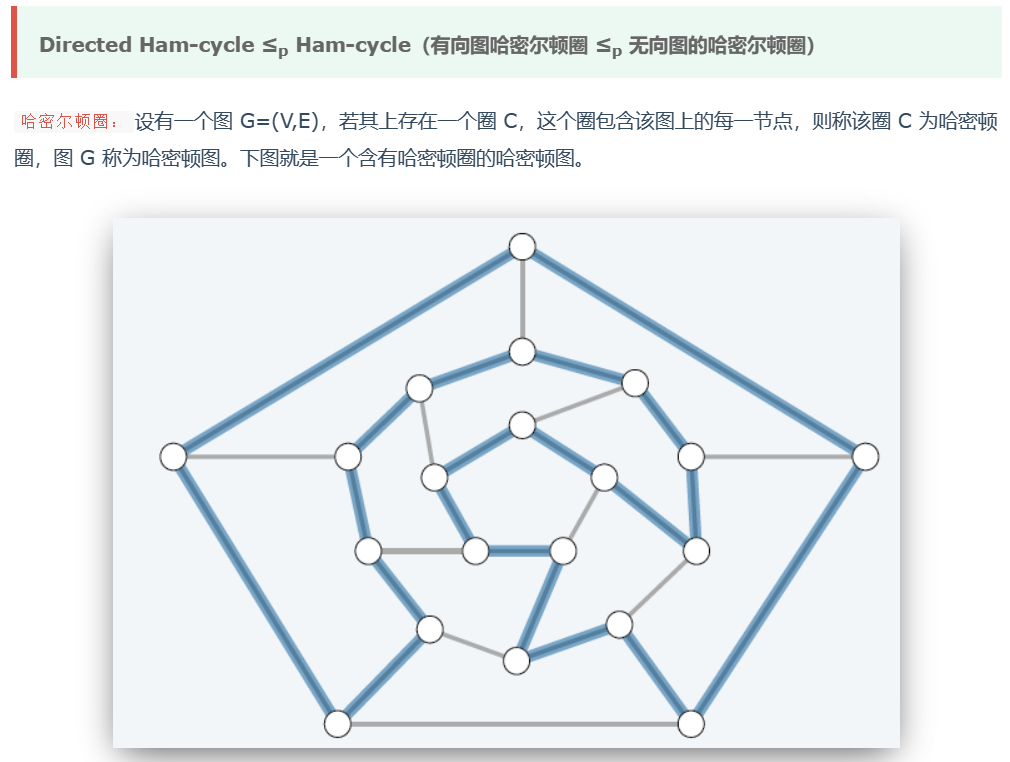
⑤ 有向图Ham ≤p 无向图Ham
哈密顿圈: 经过所有顶点一次且仅一次。

⑥ 哈密尔顿圈 ≤p 旅行售货员

⑦ 哈密尔顿圈 ≤p 最长路径

⑧ 三着色 ≤p k着色
⑨ 子集和 ≤p 分区问题

v
n
+
1
=
2
∑
w
i
?
W
v_{n+1} = 2\sum w_i - W
vn+1?=2∑wi??W
v
n
+
2
=
∑
w
i
+
W
v_{n+2} = \sum w_i + W
vn+2?=∑wi?+W
将 v n + 1 v_{n+1} vn+1? 和 v n + 2 v_{n+2} vn+2? 划分进不同的子集中
这样设置是因为,前面 v 1 , v 2 , . . . v n v_1, v_2, ... v_n v1?,v2?,...vn? 的和为 ∑ w i \sum w_i ∑wi?,并且满足 v 1 = w 1 , v 2 = w 2 , . . . v n = w n v_1 = w_1, v_2 = w_2, ... v_n = w_n v1?=w1?,v2?=w2?,...vn?=wn?,因此某个子集的和就为 W W W,将此子集提出后,剩余元素的和为 ∑ w i ? W \sum w_i - W ∑wi??W。
因此子集和 A = W, S - A 的集合为 ∑ w i ? W \sum w_i - W ∑wi??W,因此划分方式就变为了 A ∪ \cup ∪ v n + 1 v_{n+1} vn+1? 和 S-A ∪ \cup ∪ v n + 1 v_{n+1} vn+1?

⑩子集和 ≤p 背包问题


自归身约

? 基础概念

? Vertex-Cover问题
删除点判断是否存在,如果存在,则真正删除,如果不存在,则不能删除,并且将此点添加到集合 S 中。

? Hamilton Cycle问题
遍历每条边,如果去掉这条边,还存在哈密尔顿圈则真正去掉,如果去掉后,不存在哈密尔顿圈,则将 e 这条边添加到集合 S 中,并且不能将其在 G 中去掉

? 3-Color问题

? Longest-Path

? Subset-Sum 问题

真题练习
? 题目1

? 题目2

顶点覆盖的大小为 k,将这 k 个顶点覆盖给删除掉
? 题目3

? 题目4

第5章:近似算法

基础知识

负载均衡问题


? 2 倍近似算法-List Scheduling

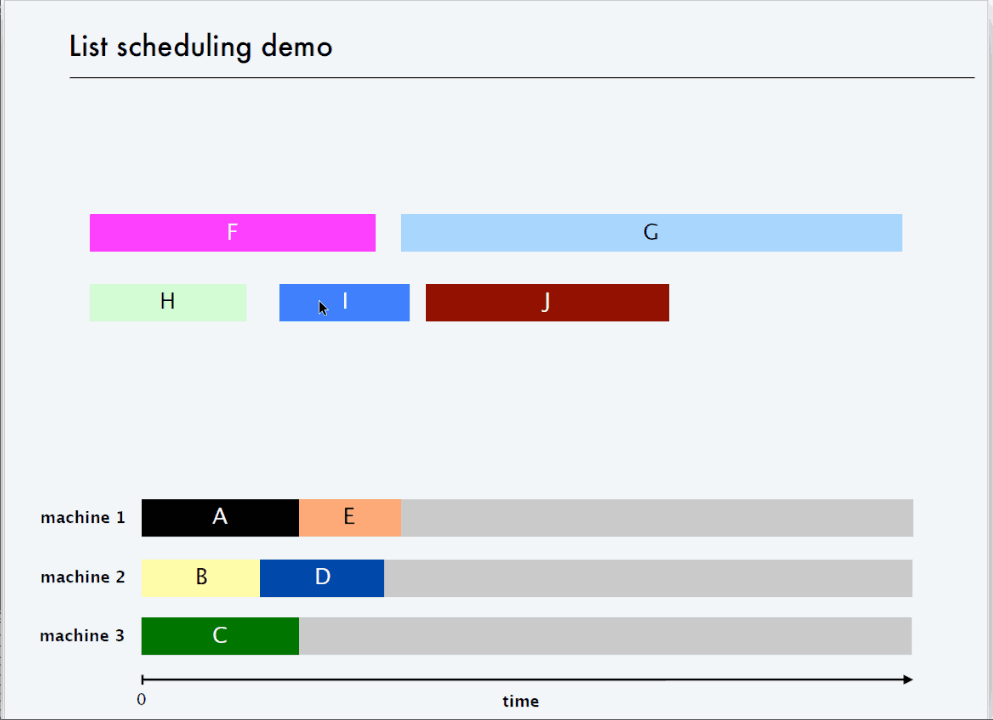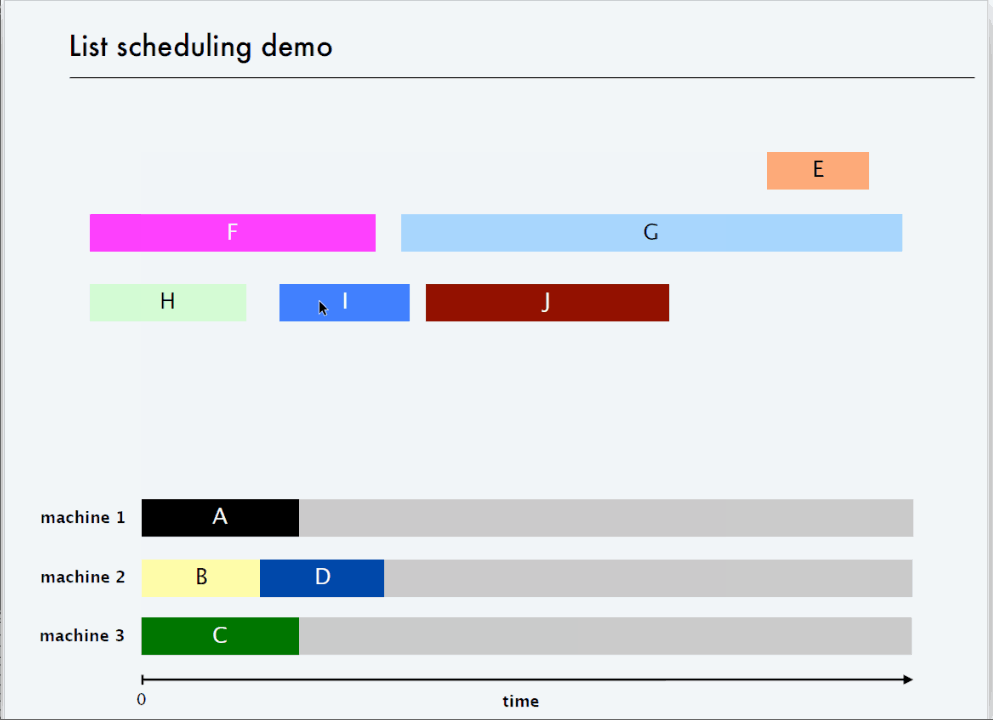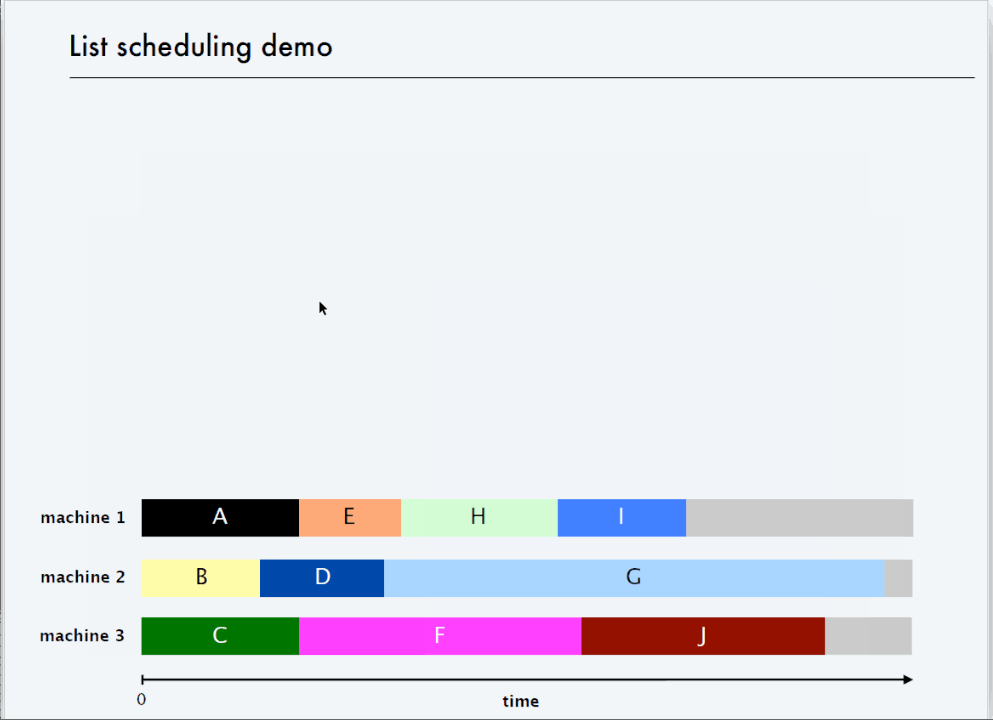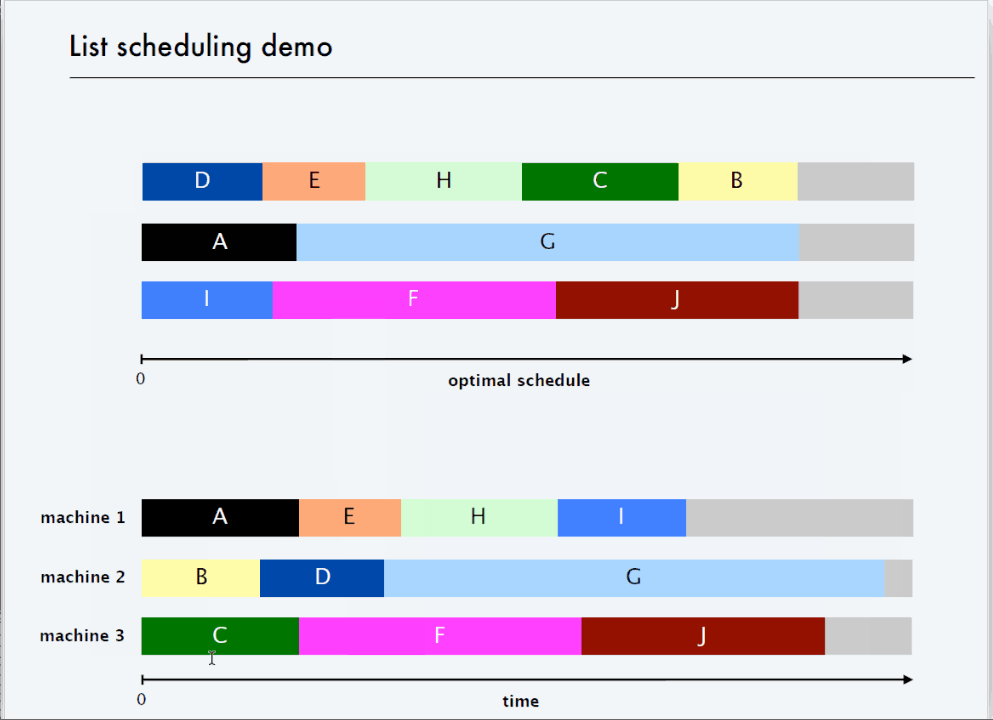

? 3/2 倍近似算法 - LPT Rule



为什么存在 L ? ≥ 2 t m + 1 L^* ≥ 2t_{m+1} L?≥2tm+1? ?首先当 n > m 时,右鸽笼原理,有一个机器上一定会有两个任务,所有最优的瓶颈时间 L ? ≥ 2 t m + 1 L^* ≥ 2t_{m+1} L?≥2tm+1?。
上式 t m + 1 t_{m + 1} tm+1? 转换为了瓶颈机器的最后一个任务 j j j,时间 t j t_j tj? 是一样的哦这两个,所以可以直接转换
L [ i ] ? t j ≤ L ? L[i] - t_j ≤ L^* L[i]?tj?≤L? 因为这里按照时间从大到小排序后,瓶颈机器 L[i] 减去最后一个 t j t_j tj?,最后一个任务之所以会放到机器 i i i 是,是因为此机器的前 i - 1 个任务,在所有机器上是最小的,即小于所有时间的平均值,而 L ? L^* L? 大于所有时间的平均值。
带权顶点覆盖问题
? 2倍近似算法-Pricing method(竞价法/定价法)

算法流程:


∑ e p e ≤ w ( S ) \sum_e p_e ≤ w(S) ∑e?pe?≤w(S),其中前面的 e 是所有边 E 中的 e,S 为顶点覆盖集合,因为只有需要紧的边才赋予价格,并且顶点权重大于等于其领接所价格总和。所以任意顶点覆盖的权重都 ≥ 边的价格之和

当有一条边没被覆盖时,那这条边对应的顶点一定不是紧的,所以算法不会结束


其中: V 表示图 G 中的所有顶点, E 表示图 G 中的所有边
带权重的顶点覆盖算法流程:
- 输入:图 G=(V, E),权重向量 w
- 初始化:把所有的边的价格(权重)都置为0.
- 循环:
- 循环条件:当边 e 的两个顶点 i 和 j 都是非紧致的时候(紧致的意思就是该顶点所有边的价格之和等于该顶点的权值)
- 循环体:选择这个边,不断的增加它的价格(权重),直到有一个边达到紧致的状态。(注:如果是第一循环,则边 e 的价格等于顶点 i 和 j 中权值较小的一个)
- 把紧致的顶点加入到集合 S 中。
- 返回 S。

? 2倍近似算法-ILP(整数规划)
PPT 描述:

解释:


PPT : 重点在于整数划分的最优解不小于线性规划


背包问题(去掉,只掌握)


真题练习
? 题目1

列举一个反例说明:


? 题目2

? 题目3

? 题目4

这里是因为: x i = 1 x_i = 1 xi?=1 时,在独立集中,当 x 1 = 0 x_1 = 0 x1?=0 时,不在独立集中,对于每条边,最多只有一个点在独立集中,所以 x i + x j ≤ 1 x_i + x_j ≤ 1 xi?+xj?≤1,而对于顶点覆盖问题,每条边至少有一个点在顶点覆盖中,所以 x i + x j ≥ 1 x_i + x_j ≥ 1 xi?+xj?≥1
⑨历年期末真题
1.多项式时间求解与输入问题的规模有关,但是存在一个多项式的运行时间,不能说明这个问题就能在多项式时间内被求解。
4.应该是所有 NP 算法都存在多项式时间算法,则 P = NP。(注:如果我们能够在多项式时间内解决一个NP问题,那么我们也可以在多项式时间内解决所有NP问题)
7.分而治之算法的效率通常由递归的深度和每层的工作量决定。在这两个算法中,递归深度相同,即都是对输入规模进行对数级别的划分。
- 对于算法A,每一层递归需要进行两次数字的排序和一次合并。所以,总的工作量是 O(n log n)。
- 对于算法B,每一层递归需要进行三次数字的排序和两次合并。虽然每一层的工作量更大,但递归深度相同,因此总体的渐进复杂度仍然是 O(n log n)。
- 因此,从渐进分析的角度来看,算法A和算法B的效率并没有本质的区别。在实际应用中,选择算法A还是算法B可能会受到具体实现、硬件环境、输入数据分布等因素的影响。
10.这个说法是不准确的。实际上,两个问题都不属于NP问题。
- 对于最短路径问题,像Dijkstra算法和Bellman-Ford算法这样的算法可以在多项式时间内解决,因此最短路径问题不属于NP问题。
- 对于最长路径问题,即求两点之间的最长路径,这个问题是NP-hard的。在一般情况下,寻找两个点之间的最长路径需要尝试所有可能的路径,这会导致指数级的计算复杂度。因此,最长路径问题是一个NP-hard问题,但并不一定是NP-complete,因为它并没有在多项式时间内验证一个解的算法。
- 总的来说,两者都不属于NP问题,而最长路径问题是一个更为困难的NP-hard问题。

肖老师习题
1.给定一个图 G = ( V , E ) G=(V, E) G=(V,E),边支配集 S 是 E 中的子集, E 中的任何一条边都连接到该子集 S 中至少有一条边的端点。边支配集问题是检查一个给定的图是否具有一个大小最多为 k 的边支配集。
对于一个给定的边集 X ,我们可以多项式时间内遍历图中的所有边来确定是否所有边都与 X 中某条边共点,所以边支配集属于NP。

为什么是添加 2k 个点,而不是 k 个点呢,是因为在添加
(
u
i
,
v
i
)
(u_i, v_i)
(ui?,vi?) 这条线时, 固定了在充分性证明时:F 中的 k 条边分别与每个
v
i
v_i
vi? 相连,即这 k 条边支配集分别与
v
i
v_i
vi? 相连。且因为是边支配集,所以 G 中所有边均与 F 中边共点,所以这 k 条边的端点不是
v
i
v_i
vi? 的那些顶点组成了一个大小为 k 的点覆盖。

在多路切割问题中,我们给出了一个无向图G=(V,E)和V中的一些特殊的顶点(称为终端)。这个问题要求我们从图中删除最小的边数,这样就不会连接到终端对。请给出这个问题的一个2-近似算法。
- In the multiway cut problem, we are given a undirected graph G=(V,E) and some
special vertices in V (called terminals). The problem asks us to delete the minimum
number of edges from the graph such that no pair of terminals is connected. Please
give a 2-approximation algorithm for this problem.




董老师作业



判断题
2018
1.所有 NP 问题都能被多项式时间算法解决才行。但是如果一个NPC问题存在多项式时间算法,那么所有NP问题都可以在多项式时间内求解,即P=NP成立。 这是因为每一个NPC问题都可以在多项式时间内转化成任何一个NP问题。 只要任意一个NPC问题找到了一个 多项式算法 ,那么所有NP问题都能用这个算法解决,也就解决了NP=P问题。
2.反证法
4.判断是否存在大小为 k 的点覆盖,直接遍历所有大小为 k 的顶点子集,然后判断子集是否覆盖所有的边。
5.问题A属于P,当且仅当 P = NP = NPC
8.运行时间和这个算法是那种类型的算法没有关系。
11.证明是双向的
12.这需要看输入问题的规模。

2019

2020

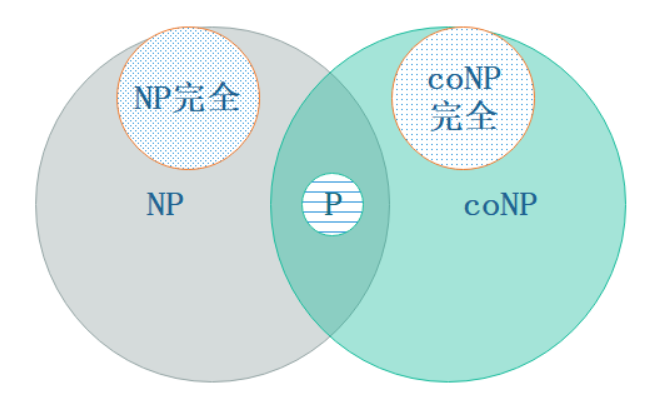
NP 表示可以在多项式时间内验证一个解的问题集合,而 coNP 表示可以在多项式时间内验证一个非解的问题集合。
计算题&简单题
样题
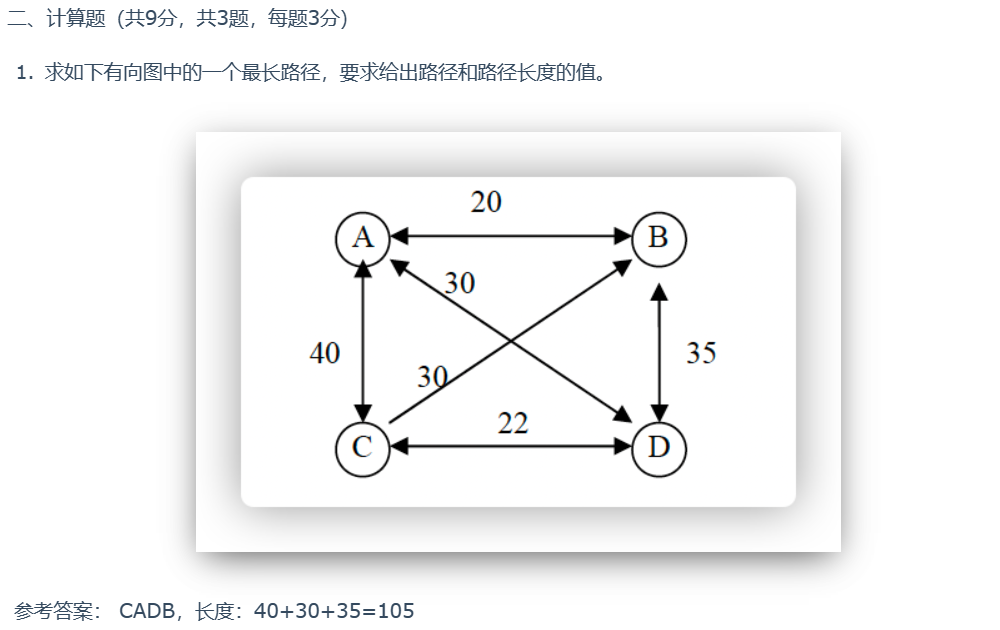

2018




此题有疑问
2019
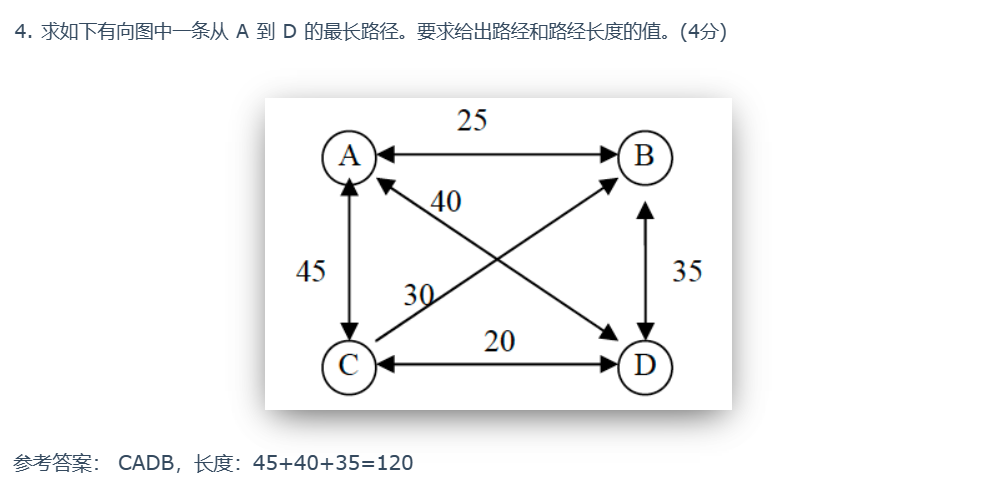
注意: 哈密尔顿圈:在经过所有点仅一次后,需要回到开始点!!!

此题有疑问
数学归纳法都是,先假设 n = k 时,不存在,然后假设 n = k + 1,或 k + 2 时不存在。或者反着来
为了使用数学归纳法证明具有奇数个顶点的二分图不能存在哈密尔顿圈,我们首先理解数学归纳法的两个基本步骤:
- 基础步骤:证明当 ( n ) 为最小的奇数(例如 ( n = 3 ))时,命题成立。
- 归纳步骤:假设当 ( n = k )(其中 ( k ) 是一个奇数)时命题成立,然后证明当 ( n = k + 2 ) 时命题也成立。
证明过程:
-
基础步骤:
- 对于 ( n = 3 ),最小的二分图是两个集合中各有一个顶点和一个集合有两个顶点。这样的图不能形成哈密尔顿圈,因为不可能从一个顶点出发,访问所有顶点恰好一次又回到出发点。所以,对于 ( n = 3 ),命题成立。
-
归纳步骤:
- 假设当 ( n = k )(( k ) 为奇数)时命题成立,即一个有 ( k ) 个顶点的二分图不能存在哈密尔顿圈。
- 现在考虑 ( n = k + 2 ) 的情况。二分图的两个集合中至少有一个集合的顶点数增加了 1(因为总顶点数增加了 2)。因此,这两个集合中至少有一个集合的顶点数仍然是奇数。
- 在二分图中,哈密尔顿圈需要交替地经过两个集合的顶点。如果两个集合中至少有一个集合的顶点数是奇数,那么不可能形成一个经过每个顶点恰好一次的圈,因为这会导致至少有一个集合中有连续两个顶点在圈中相邻,这违反了二分图的定义。
- 因此,当 ( n = k + 2 ) 时,这样的二分图也不能存在哈密尔顿圈。
通过这两个步骤,我们可以得出结论:对于任何奇数 ( n ),一个有 ( n ) 个顶点的二分图不能存在哈密尔顿圈。这就完成了使用数学归纳法的证明。
反证法如下:
要证明一个具有奇数个顶点的二分图不能存在哈密尔顿圈,我们可以使用反证法。假设存在这样的一个二分图,并且它有一个哈密尔顿圈。
-
二分图的定义:二分图是一种图,其中的顶点可以被分成两个不相交的集合,使得图中的每条边都连接这两个集合中的顶点。也就是说,在二分图中,同一个集合内的顶点之间没有边。
-
哈密尔顿圈的定义:哈密尔顿圈是图中的一个圈,它经过每个顶点恰好一次并返回到起点。
-
奇数顶点的影响:在二分图中,由于每条边都连接两个不同集合中的顶点,因此任何圈(包括哈密尔顿圈)必须交替地通过这两个集合的顶点。这意味着圈中的顶点数必须是偶数——因为每完成一次从一个集合到另一个集合的转换,都需要两个顶点(一个来自每个集合)。
-
矛盾:如果二分图有奇数个顶点,那么它不可能有一个哈密尔顿圈。因为要形成一个圈,从一个集合到另一个集合的转换次数必须是偶数,这意味着总顶点数也必须是偶数。但在我们的假设中,图有奇数个顶点,这与哈密尔顿圈的要求相矛盾。
由此,我们可以得出结论:一个具有奇数个顶点的二分图不可能存在哈密尔顿圈。这与我们最初的假设相矛盾,因此证明了这样的二分图不存在哈密尔顿圈。


此题答案不唯一
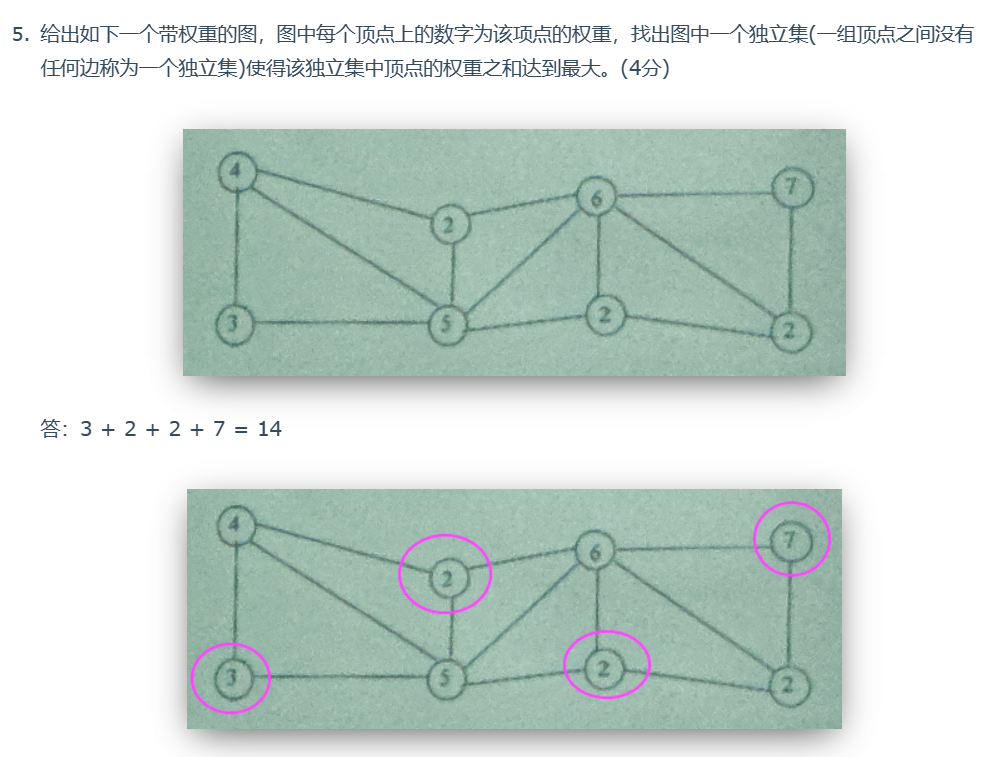
注意独立集,独立集之间不能有边相连
这里需要回顾:
2020

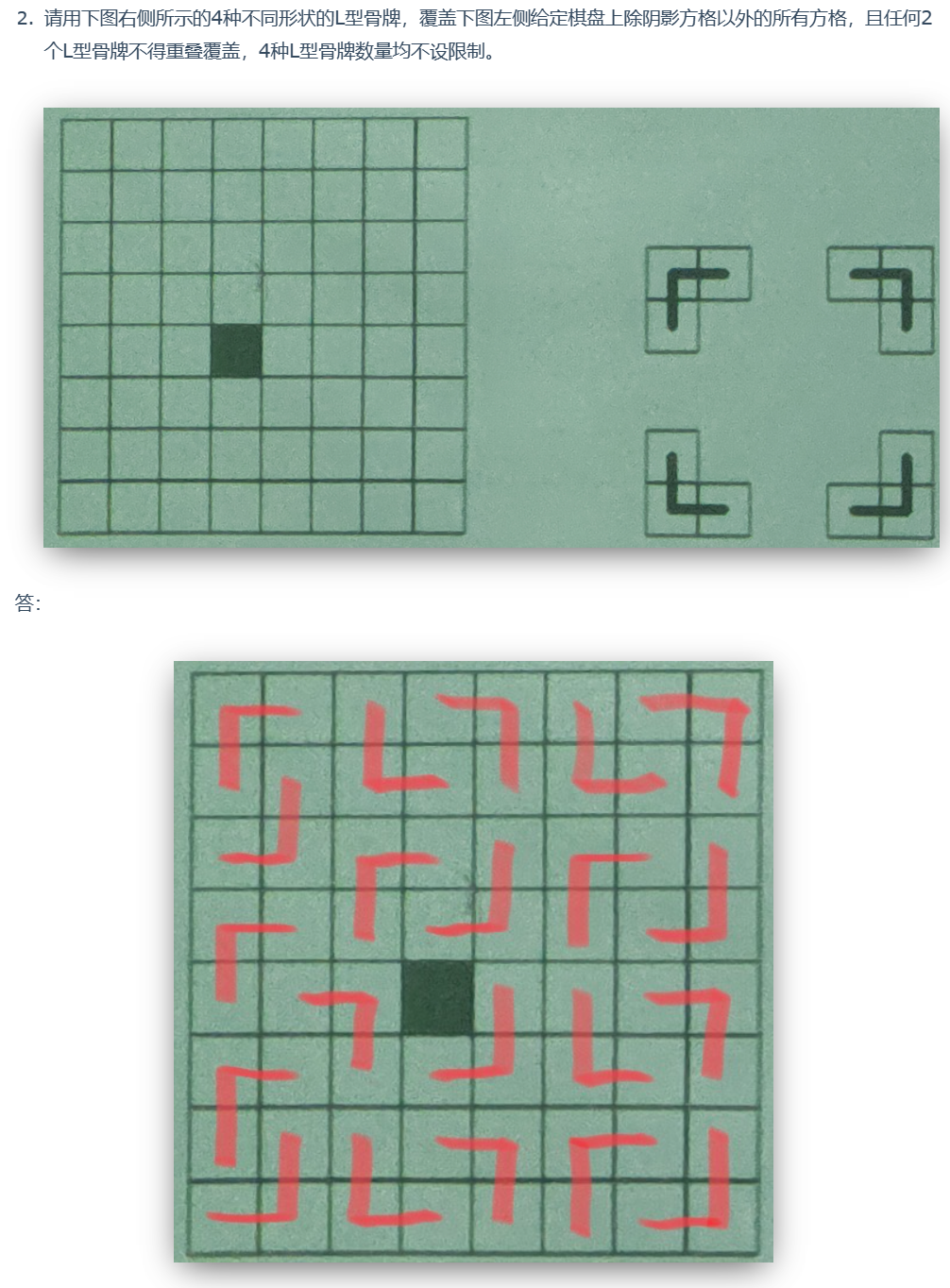
棋盘覆盖(考试重点)
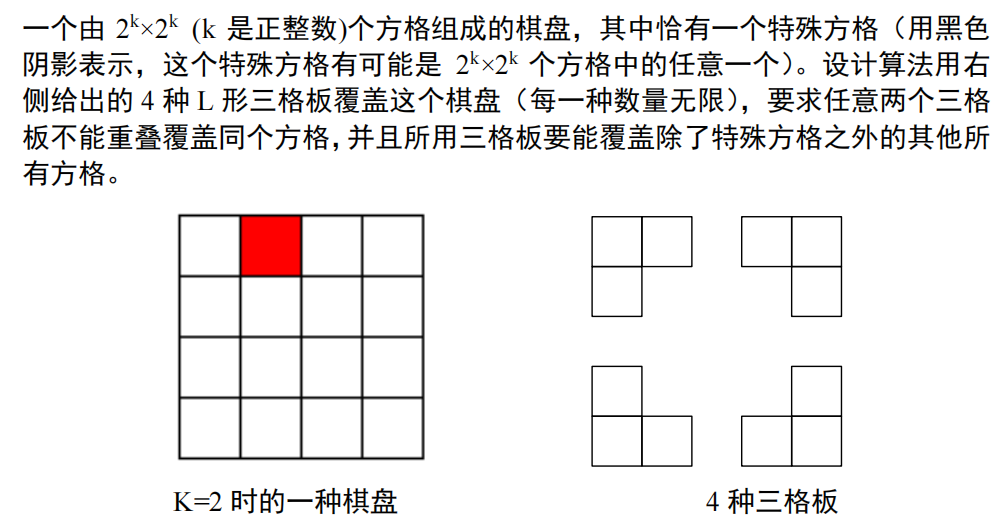
实例: 16 × 16 的棋盘
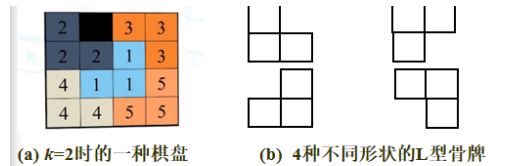

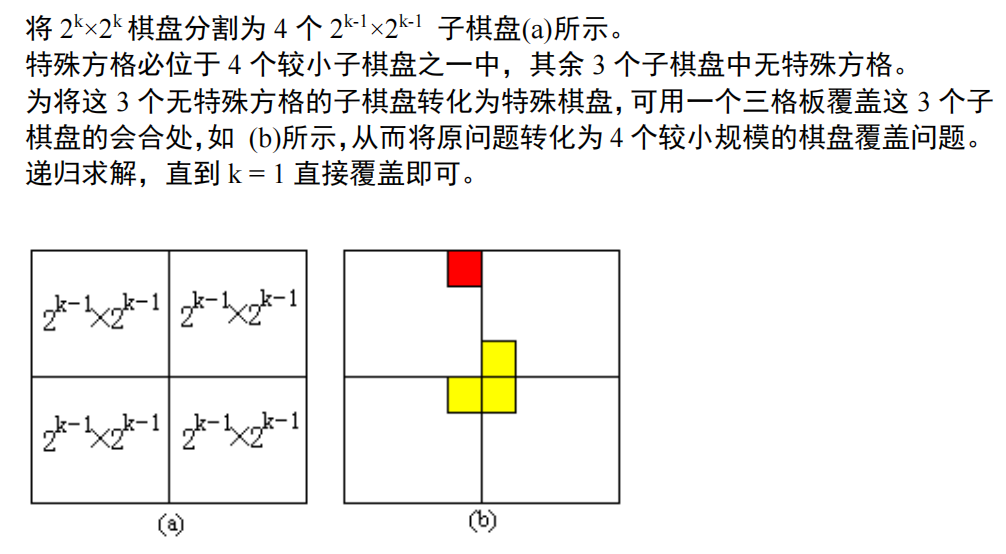
分为 4 个 8 × 8 的棋盘:并在中心产生一个与 L (满足 L 的形状不在黑点所在方格内)


进一步划分棋盘
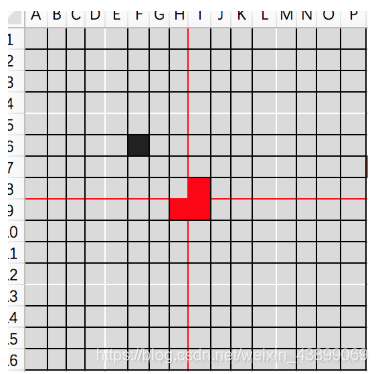
并在方格内填入 L(同样需要满足填入的整体方格不存在其他的点)





解答题
2018




2019


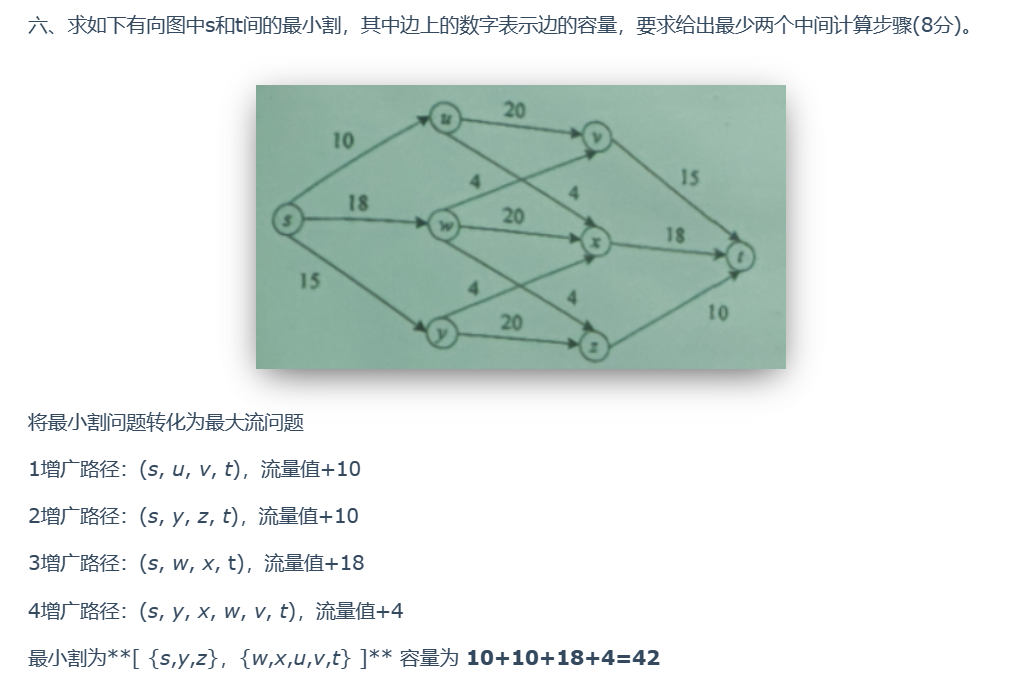

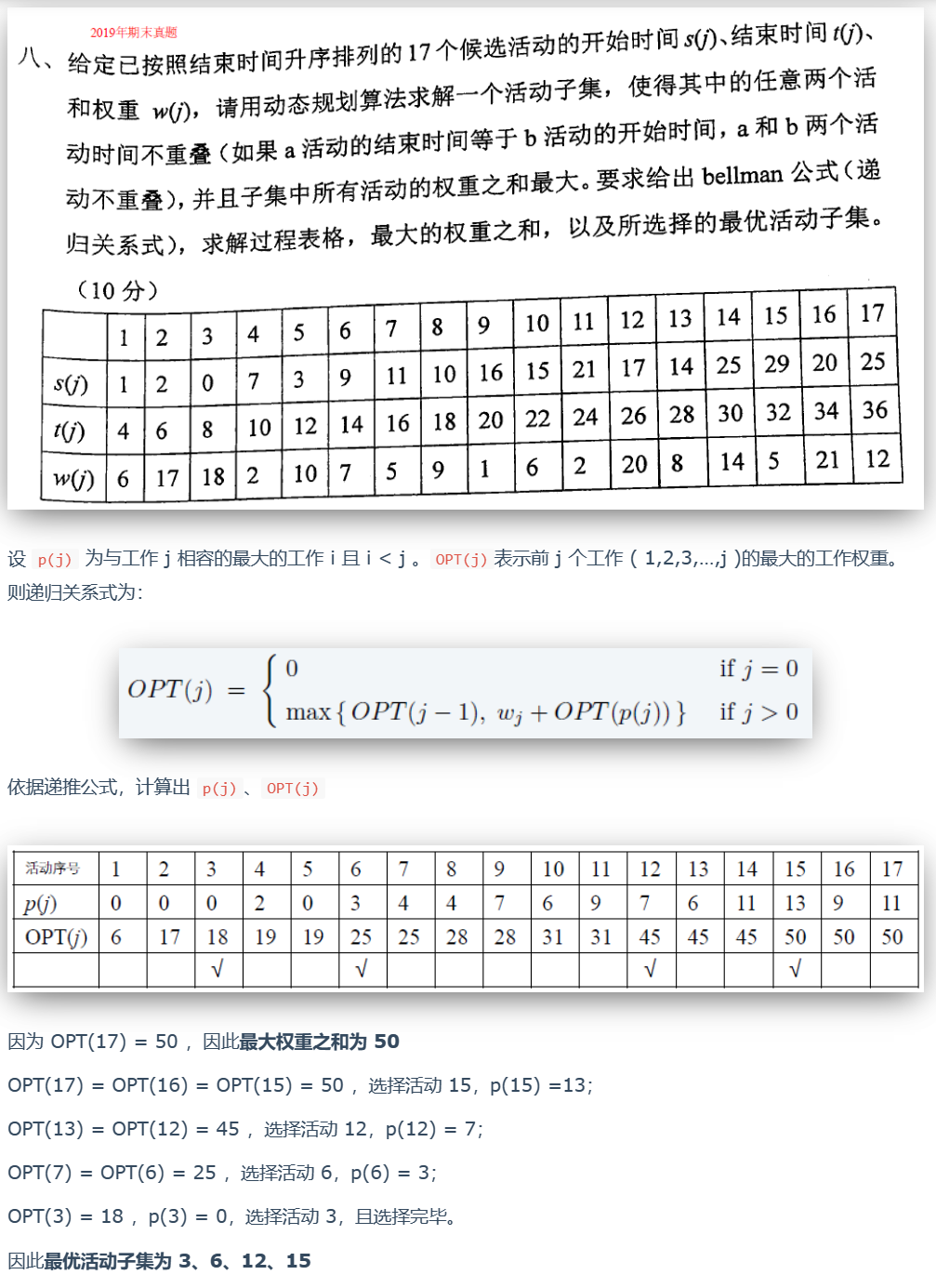

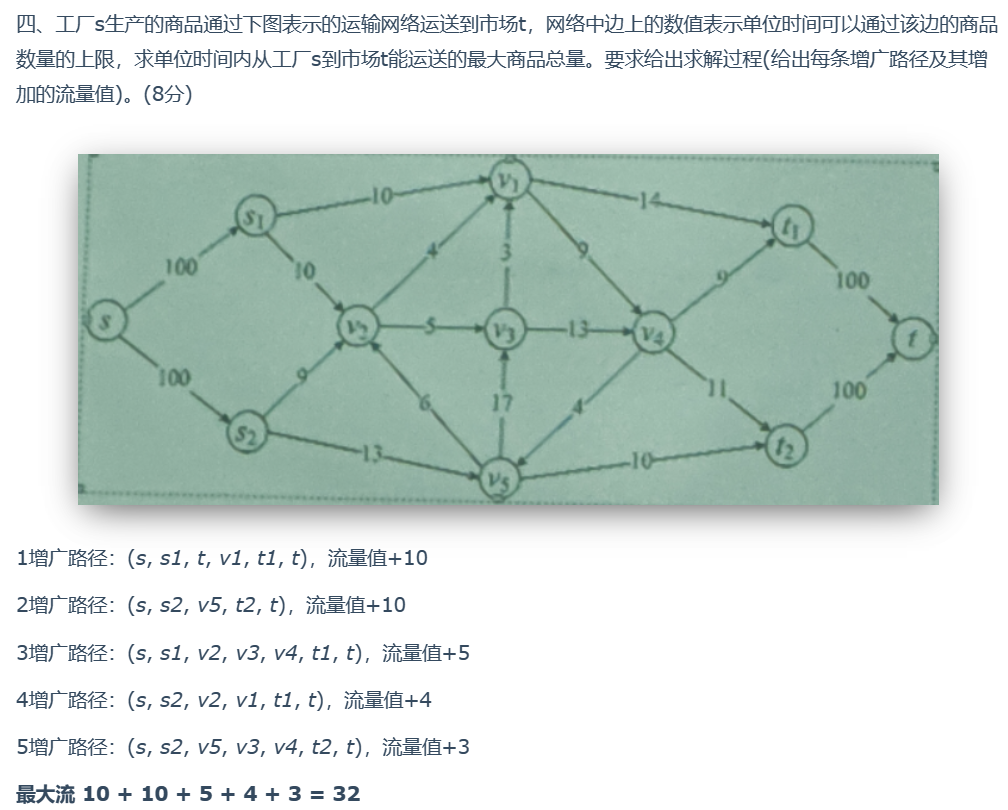
2020

根据 Kruskal(克鲁斯卡尔)算法,将所有边进行从小到大排序,然后每新添加一条边,会判断是否存在环,所以最小权重的边一定会被添加进去


就是单调递增子序列,不需要连续起来数字,X 就是为了描述,不用连续起来




2021

师兄师姐给的习题
样题1


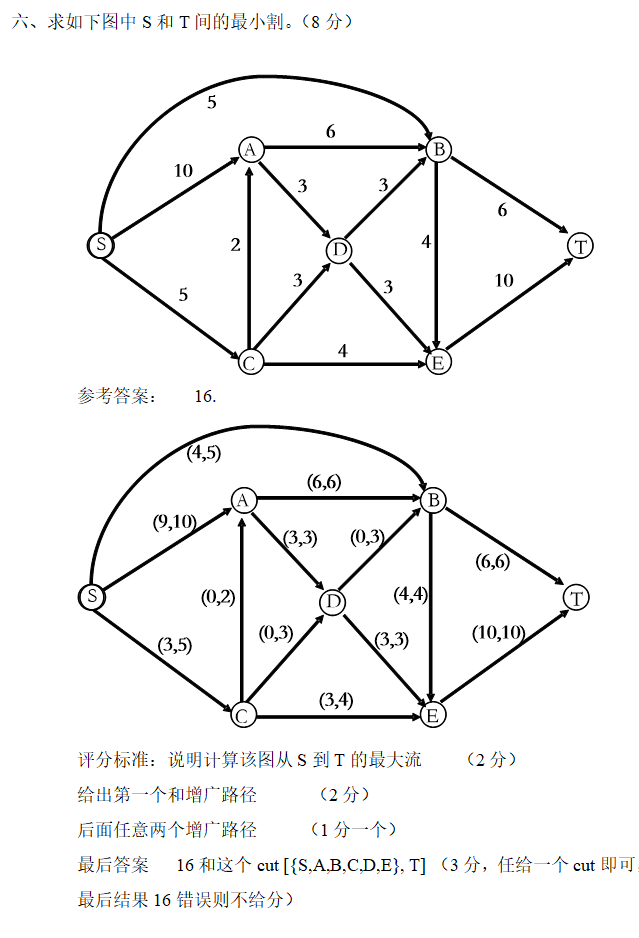





2018 年秋






2023 年试题(回忆版)
一、判断题复习上述内容即可,共计 10 题 20 分。(很easy基础)
二、计算题:(不需要中间过程)
- 说明斐波拉契数列的动态规划算法是否为多项式时间算法,分析原因
- 渐进时间复杂度从小到大排序
- 给定 4 个顶点和一个边权,求最短路径的大小和具体路径。(肉眼可得)
- 利用主定理求渐进表达式:2 个
- 给定一个图,用 1,2,3 表示三种颜色,对图进行三着色
- 说明题:等价于区间调度问题中,为什么最小冲突排序不能得到最大的活动数量,说明具体原因。(需画图举例)
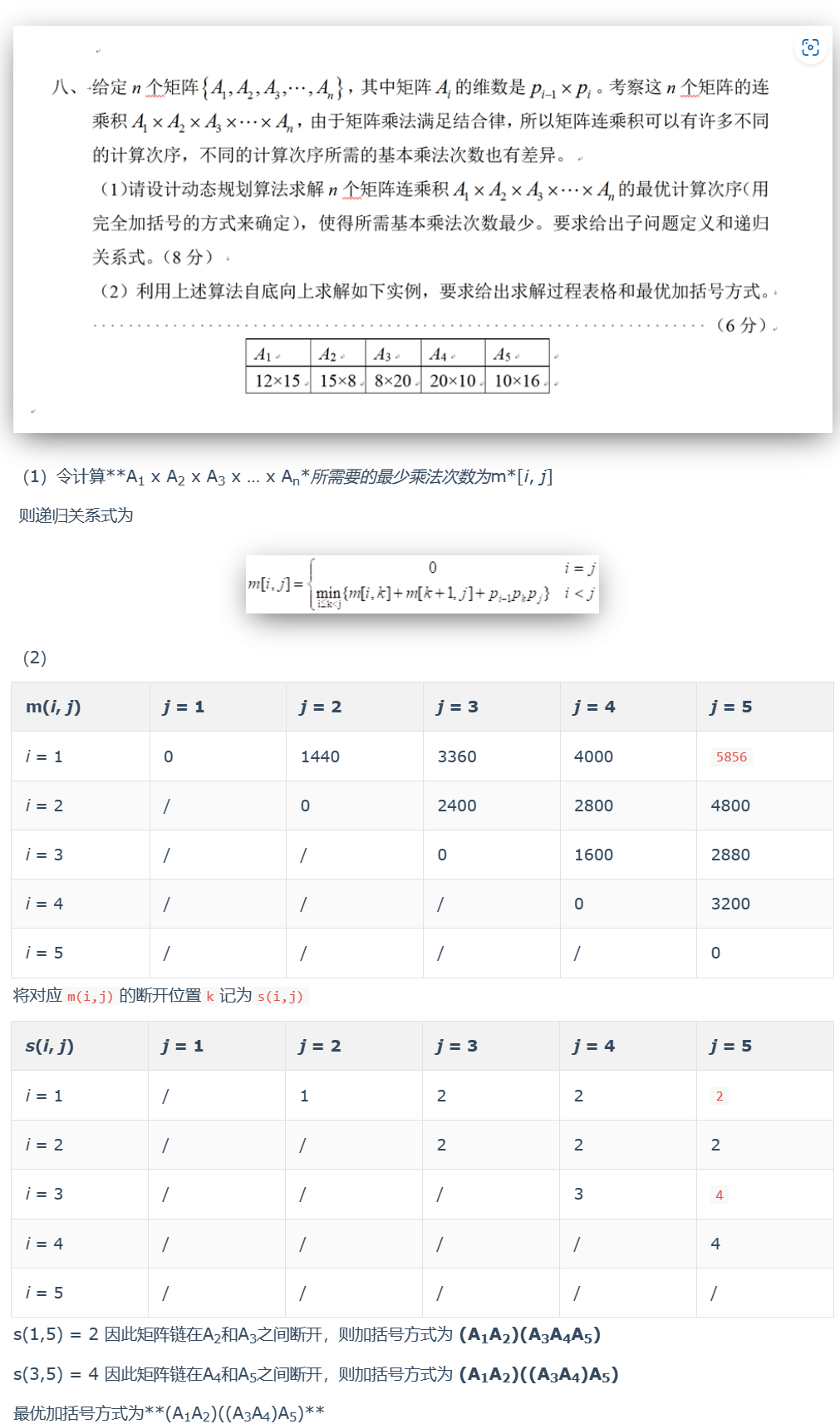
三、网络流:给定一个图,图中部分边设定了一定流量,画出此图的残余网络,并在残余网络上求最大流,写出增广路径和流量
四、(1)求支配集与顶点覆盖问题的区别。 (2)支配集的自身归约
五、证明边支配集是 NPC 的???
六、动态规划题:很简单的求从 (0, 0),到 (n, m) 所捡到的最大金币是多少,并给出路径。 w[i][j] 为每个格子的金币, f[i][j] 为对应格子中的最大金币,f[i][j] = max(f[i - 1][j], f[i][j - 1) + w[i][j]; 完事!
七、独立边集:集合中所有边与图 G 中所有其他边没有公共点,求图 G 的最大独立边集。设计一个 1/2 近似算法,并证明这是一个 1/2 近似 的。
总结:
- TSP 问题既是 NPC 问题,也是 NPH 问题,因为 NPC 问题是 NPH 问题的真子集
- P-problem 是: 多项式时间内有确定性算法可解的问题;
- Np-problem 是:多项式时间内有不确定性算法的问题,也就是说,你不一定多项式时间可以给出一个正确的解,但是给了你一个解之后,你可以多项式时间内判断他是否是个正确的解;
- Np-complete 问题是:所有的 NP 问题都可以规约到这样的一个问题上,而且这个问题本身也是一个 NP 问题;
- Np-hard 是:所有的 NP 问题都可以规约到这样的一个问题上的问题。所以,NPC 问题一定是NPH 问题,但是 NPH 问题不一定是 NPC 问题(因为它可能不是个 NP 问题)
- 最长路径也是 NPC 问题的,所以是 NPC 问题,它也就是 NPH 问题。
- 哈密尔顿圈:在经过所有点仅一次后,需要回到开始点,所以最后回到开始点那一步也需要考虑,在证明奇数个点的二分图一定不存在哈密顿圈时很重要!!!

判断一个图是否存在大小为 k 的独立集,是多项式时间的 O ( n k ) O(n^k) O(nk)

最大独立集问题是指数时间问题

找零钱的贪心算法只对美元是最优的,最优美国邮政票,欧元等不是最优的
所有的 NPC 问题都是判定问题
NPC问题限制了规模就可以多项式时间求解
References
[1] 简言之大佬高级算法设计与分析 ☆☆☆☆☆
[2] 贪心算法-区间调度问题解之证明
[3] 从调度问题看贪心算法最优性证明
[5] 多项式规约——续
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024最新 8 款电脑数据恢复软件推荐分享
- 深入理解HarmonyOS UIAbility:生命周期、WindowStage与启动模式探析
- PaddleSeg的训练与测试推理全流程(超级详细)
- 更便捷的访问共享盘方式 pyfilesystem
- 封装、继承、多态
- L1-049 天梯赛座位分配
- FileStream文件管理
- 麒麟信安杨涛董事长获评 “第二届新湖南贡献奖先进个人”
- 2024.1.3
- 直流过欠压继电器JSZD-1A DC220V 0-220V 面板嵌入式安装