【算法提升】LeetCode每五日一总结【01/07--01/12】
文章目录
LeetCode每五日一总结【01/07–01/12】
2024/01/07
LeetCode每日一刷:450. 删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 1:
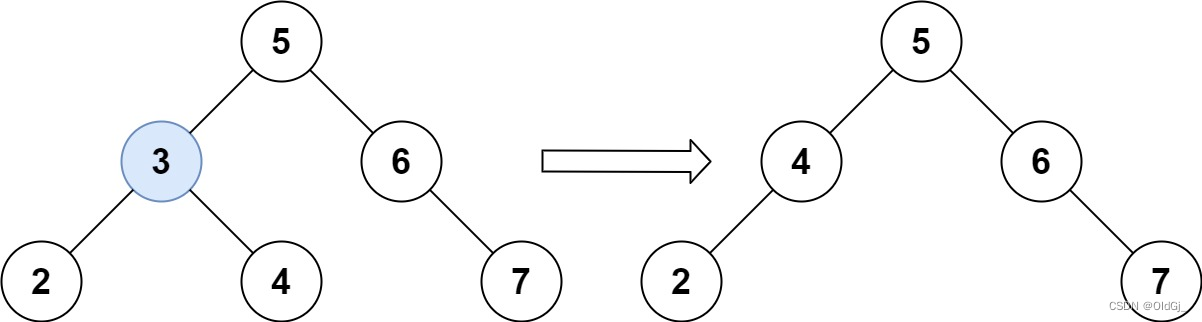
输入:root = [5,3,6,2,4,null,7], key = 3 输出:[5,4,6,2,null,null,7] 解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。 一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。 另一个正确答案是 [5,2,6,null,4,null,7]。示例 2:
输入: root = [5,3,6,2,4,null,7], key = 0 输出: [5,3,6,2,4,null,7] 解释: 二叉树不包含值为 0 的节点示例 3:
输入: root = [], key = 0 输出: []提示:
- 节点数的范围
[0, 104].-105 <= Node.val <= 105- 节点值唯一
root是合法的二叉搜索树-105 <= key <= 105
/**
* 递归法:
* @return 删除节点后剩下的节点
*/
@SuppressWarnings("all")
public TreeNode deleteNode(TreeNode node, int key) {
if (node == null) {
return null;
}
if (key < node.val) {
node.left = deleteNode(node.left, key);
return node;
}
if (node.val < key) {
node.right = deleteNode(node.right, key);
return node;
}
if (node.left == null) {//情况一:只有右孩子
return node.right;
}
if (node.right == null) {//情况二:只有左孩子
return node.left;
}
//情况三:左右孩子都有,让后继节点代替被删除节点的位置
TreeNode s = node.right;
while (s.left != null) {
s = s.left;
}
s.right = deleteNode(node.right, s.val);
s.left = node.left;
return s;
}
方法一:递归
这段代码是用Java编写的递归删除二叉搜索树节点的函数。二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。删除二叉搜索树节点的关键在于找到待删除节点的前驱节点(即小于待删除节点值的最大节点)或后继节点(即大于待删除节点值的最小节点),然后将待删除节点的值替换为后继节点的值,或者将后继节点的值替换为待删除节点的值。
以下是代码的详细解释:
- 定义一个名为
deleteNode的函数,该函数接受两个参数:一个二叉搜索树的根节点node和一个要删除的节点的值key。- 如果根节点为
null,说明树中没有找到要删除的节点,直接返回null。- 如果要删除的节点的值小于当前节点的值,说明要删除的节点在当前节点的左子树中,将当前节点的左子节点设置为递归调用
deleteNode函数删除要删除节点后的结果。- 如果要删除的节点的值大于当前节点的值,说明要删除的节点在当前节点的右子树中,将当前节点的右子节点设置为递归调用
deleteNode函数删除要删除节点后的结果。- 如果当前节点的左子节点为
null,说明当前节点只有右子节点,返回当前节点的右子节点。- 如果当前节点的右子节点为
null,说明当前节点只有左子节点,返回当前节点的左子节点。- 否则,找到当前节点右子树中的最小值节点
s,将当前节点的右子节点设置为递归调用deleteNode函数删除s节点后的结果,然后将s的左子节点设置为当前节点的左子节点,返回s。- 最后,返回根节点。
public TreeNode deleteNode2(TreeNode root, int key) {
TreeNode cur = root, curParent = null;
//找待删除节点并且记录其父节点
while (cur != null && cur.val != key) {
curParent = cur;
if (cur.val > key) {
cur = cur.left;
} else {
cur = cur.right;
}
}
//没找到待删除节点,直接返回根节点
if (cur == null) {
return root;
}
//找到待删除节点,分四种情况
if (cur.left == null && cur.right == null) {
cur = null;//情况一:待删除节点没有左右孩子,直接将待删除节点赋值为null
} else if (cur.right == null) {
cur = cur.left;//情况二:待删除节点只有左孩子没有右孩子
} else if (cur.left == null) {
cur = cur.right;//情况三:待删除节点只有右孩子没有左孩子
} else {//情况四:待删除节点即有左孩子又有右孩子
TreeNode successor = cur.right, successorParent = cur;
//找待删除节点的后继节点并记录后继节点的父亲
while (successor.left != null) {
successorParent = successor;
successor = successor.left;
}
//找到后继节点,分两种情况
if (successorParent.val == cur.val) {
//情况一:后继节点与待删除节点直接相邻
successorParent.right = successor.right;
} else {
//情况二:后继节点与待删除节点不相邻
successorParent.left = successor.right;
}
//将后继节点替换掉待删除节点实现删除
successor.right = cur.right;
successor.left = cur.left;
cur = successor;
}
//如果待删除节点是根节点,没有父亲,则直接返回待删除节点
if (curParent == null) {
return cur;
} else {
//若待删除节点是其父亲节点的左孩子,则将已经删除完成的子树赋值给父亲的左孩子
if (curParent.left != null && curParent.left.val == key) {
curParent.left = cur;
} else {//否则赋值给右孩子
curParent.right = cur;
}
//返回根节点
return root;
}
}
/*
4
/ \
2 5
/ \ \
1 3 6
4
/ \
2 7
/ \ / \
1 3 5 8
\
6
*/
方法二:非递归
这段代码是用Java编写的非递归删除二叉搜索树节点的函数。二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。删除二叉搜索树节点的关键在于找到待删除节点的前驱节点(即小于待删除节点值的最大节点)或后继节点(即大于待删除节点值的最小节点),然后将待删除节点的值替换为后继节点的值,或者将后继节点的值替换为待删除节点的值。
以下是代码的详细解释:
定义一个名为
deleteNode2的函数,该函数接受两个参数:一个二叉搜索树的根节点root和一个要删除的节点的值key。定义三个变量:
cur表示当前遍历到的节点,curParent表示当前节点的父节点,successor表示待删除节点的后继节点。使用一个
while循环来查找要删除的节点cur。如果cur为null,说明树中没有找到要删除的节点,直接返回根节点root。如果
cur的左子节点为null且右子节点为null,说明cur是一个叶子节点,直接将其设置为null。如果
cur的右子节点为null,说明cur只有左子节点,直接将其设置为左子节点。如果
cur的左子节点为null,说明cur只有右子节点,直接将其设置为右子节点。如果
cur的左右子节点都不为null,说明cur既有左子节点又有右子节点。找到cur的右子树中的最小值节点successor(后继节点),然后进行以下操作:a. 如果
successor的父节点是cur,说明successor和cur相邻,将successor的右子节点设置为successorParent的右子节点。(处理后继节点的父亲节点)b. 否则(后继节点和待删除节点不相邻),将
successor的右子节点设置为successorParent的左子节点(处理后继节点的父亲节点)
处理完后继节点后,就可以将待删除节点的右孩子赋值给后继节点的右孩子,待删除节点的左孩子赋值给后继节点的左孩子,然后让后继节点代替待删除节点
cur = successor,即可完成删除。如果
cur的父节点为null,说明cur是根节点,直接返回cur。否则,根据
cur是父节点的左子节点还是右子节点,将successor的值替换cur的值作为父节点的左孩子或者右孩子。最后,返回根节点
root。
2024/01/08
LeetCode每日一刷:701. 二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点
root和要插入树中的值value,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
示例 1:
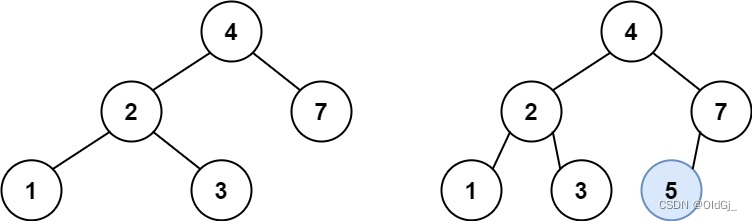
输入:root = [4,2,7,1,3], val = 5 输出:[4,2,7,1,3,5] 解释:另一个满足题目要求可以通过的树是:示例 2:
输入:root = [40,20,60,10,30,50,70], val = 25 输出:[40,20,60,10,30,50,70,null,null,25]示例 3:
输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5 输出:[4,2,7,1,3,5]提示:
- 树中的节点数将在
[0, 104]的范围内。-108 <= Node.val <= 108- 所有值
Node.val是 独一无二 的。-108 <= val <= 108- 保证
val在原始BST中不存在。
/**
* 递归法
* @return 插入后的根节点
*/
@SuppressWarnings("all")
public TreeNode insertIntoBST(TreeNode node, int val) {
if(node==null) {
return new TreeNode(val);
}
if(val<node.val) {
node.left = insertIntoBST(node.left, val);
}
if(val>node.val) {
node.right = insertIntoBST(node.right,val);
}
return node;
}
这段代码是用Java编写的递归插入二叉搜索树节点的函数。二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。插入二叉搜索树节点的关键在于找到插入位置,然后将新节点插入到该位置。
以下是代码的详细解释:
- 定义一个名为
insertIntoBST的函数,该函数接受两个参数:一个二叉搜索树的根节点node和一个要插入的节点的值val。- 如果根节点为
null,说明树中没有找到要插入的节点,直接返回一个新的节点,该节点的值为val,左右子节点为null。- 如果要插入的节点的值小于当前节点的值,说明要插入的节点应该插入到当前节点的左子树中,将当前节点的左子节点设置为递归调用
insertIntoBST函数插入要插入节点后的结果。- 如果要插入的节点的值大于当前节点的值,说明要插入的节点应该插入到当前节点的右子树中,将当前节点的右子节点设置为递归调用
insertIntoBST函数插入要插入节点后的结果。- 最后,返回根节点。
/**
* 非递归
*/
@SuppressWarnings("all")
public TreeNode insertIntoBST2(TreeNode node, int val) {
//如果根节点为空,则直接返回一个插入的新节点
if (node == null) {
return new TreeNode(val);
}
TreeNode p = node;
TreeNode parent = null;
//查找插入节点的合适位置并记录其父节点
while (p != null) {
if (val < p.val) {
parent = p;
p = p.left;
} else if (val > p.val) {
parent = p;
p = p.right;
} else {
//找到树中原本存在值为val的节点,替换该节点的值
p.val = val;
break;
}
}
//如果待插入节点的val小于父亲节点的val,则待插入节点应该做父亲节点的左孩子
if (val < parent.val) {
parent.left = new TreeNode(val);
} else {//否则做父亲节点的右孩子
parent.right = new TreeNode(val);
}
return node;
}
这段代码是用Java编写的非递归插入二叉搜索树节点的函数。二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。插入二叉搜索树节点的关键在于找到插入位置,然后将新节点插入到该位置。
以下是代码的详细解释:
1. 定义一个名为`insertIntoBST2`的函数,该函数接受两个参数:一个二叉搜索树的根节点`node`和一个要插入的节点的值`val`。 2. 如果根节点为`null`,说明树中没有找到要插入的节点,直接返回一个新的节点,该节点的值为`val`,左右子节点为`null`。 3. 定义一个指向当前节点的指针`p`,以及一个指向当前节点父节点的指针`parent`。 4. 使用一个`while`循环来查找插入节点的合适位置。在循环中,如果插入节点的值小于当前节点的值,则将`p`指针移动到当前节点的左子节点,如果插入节点的值大于当前节点的值,则将`p`指针移动到当前节点的右子节点。如果找到要插入的节点,则跳出循环。 5. 如果找到要插入的节点,则将该节点的值替换为新插入的节点的值,然后跳出循环。 6. 如果待插入节点的值小于父节点的值,则待插入节点应该做父节点的左孩子; 7. 否则,待插入节点应该做父节点的右孩子。 8. 最后,返回根节点。
LeetCode每日一刷:700. 二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点
root和一个整数值val。你需要在 BST 中找到节点值等于
val的节点。 返回以该节点为根的子树。 如果节点不存在,则返回null。示例 1:
?
输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]示例 2:
?
输入:root = [4,2,7,1,3], val = 5 输出:[]提示:
- 树中节点数在
[1, 5000]范围内1 <= Node.val <= 107root是二叉搜索树1 <= val <= 107
/**
* 递归法
*/
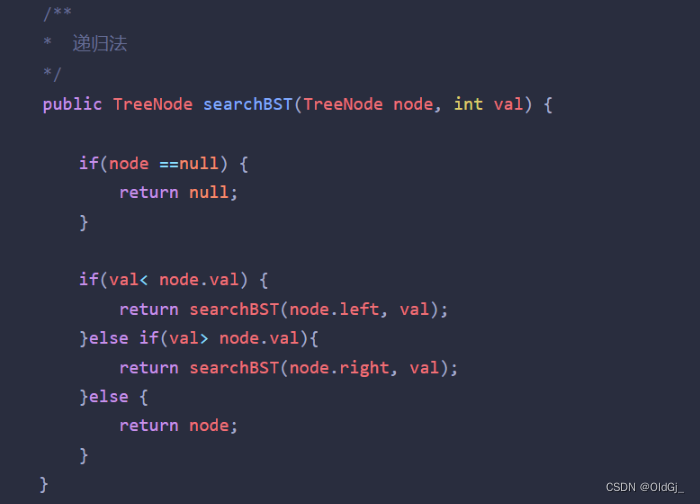
public TreeNode searchBST(TreeNode node, int val) {
if(node ==null) {
return null;
}
if(val< node.val) {
return searchBST(node.left, val);
}else if(val> node.val){
return searchBST(node.right, val);
}else {
return node;
}
}
该函数用于在二叉搜索树(BST)中搜索给定的值。BST的特点是:每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。
函数的输入参数为一个节点和一个要搜索的值。函数首先判断节点是否为空,如果为空,则返回null。
然后,函数会根据给定值的大小与节点值的大小关系,递归地搜索左子树或右子树。如果找到匹配的值,则返回该节点;否则,继续搜索下一个子树。如果最终没有找到匹配的值,则返回null。
/**
* 非递归
*/
public TreeNode searchBST2(TreeNode node,int val){
if(node==null){
return null;
}
while (node!=null){
if (val<node.val){
node=node.left;
}else if(val>node.val){
node=node.right;
}else {
break;
}
}
return node;
}
这是一个使用非递归方法搜索二叉搜索树(BST)的Java方法。二叉搜索树满足左子树的节点值都小于根节点,右子树的节点值都大于根节点。
方法接收两个参数:一个二叉搜索树的根节点
node和一个要搜索的值val。方法首先判断根节点是否为空,如果是,则返回空。然后,它使用一个
while循环来遍历树。在每次迭代中,它会检查当前节点的值与给定值的关系。如果给定值小于当前节点的值,它将搜索左子树;如果给定值大于当前节点的值,它将搜索右子树。如果给定值等于当前节点的值,它将跳出循环并返回当前节点。最后,方法返回找到的节点,如果没有找到,则返回空。
2024/01/09
LeetCode每日一刷:98. 验证二叉搜索树
给你一个二叉树的根节点
root,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
?
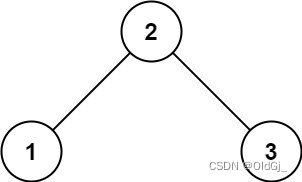
输入:root = [2,1,3] 输出:true示例 2:
?
输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。提示:
- 树中节点数目范围在
[1, 10^4]内-2^31 <= Node.val <= 2^31 - 1

/**
* 中序遍历 非递归
* 核心思想:如果中序遍历的结果集为升序的,则证明该树为二叉搜索树
*/
public boolean isValidBST1(TreeNode root) {
TreeNode p = root;
//中序遍历需要用到栈数据结构
LinkedList<TreeNode> stack = new LinkedList<>();
//定义一个长整形变量,存放遍历结果的前一个值
long prev = Long.MIN_VALUE;
while (p != null || !stack.isEmpty()) {
if (p != null) {
stack.push(p);
p = p.left;
} else {
TreeNode pop = stack.pop();
//如果遍历结果的前一个值大于等于当前值,不满足升序,返回FALSE
if (prev >= pop.val) {
return false;
}
prev = pop.val;
p = pop.right;
}
}
return true;
}
这段代码实现了一个中序遍历非递归方法,用于判断一棵树是否为二叉搜索树(BST)。二叉搜索树的中序遍历结果是一个升序序列。
首先,创建一个指针
p指向根节点,然后创建一个栈stack和一个变量prev,用于存储上一个节点的值。当
p不为空时,将当前节点压入栈中,然后将p指向当前节点的左子节点。当
p为空时,弹出栈顶节点,将其值与prev进行比较。如果prev大于等于当前节点的值,说明当前节点的值小于等于栈顶节点的值,不满足升序条件,返回false。否则,将当前节点的值赋给prev,并将p指向当前节点的右子节点。重复步骤 2 和 3,直到栈为空且
p为空,说明已经遍历了整个树,返回true。总之,这段代码通过中序遍历非递归方法实现了判断一棵树是否为二叉搜索树的功能。
/**
* 中序遍历,递归实现
* 必须左右子树全都满足二叉搜索树才返回 true
*/
long prev = Long.MIN_VALUE;
public boolean isValidBST2(TreeNode node) {
if (node == null) {
return true;
}
boolean a = isValidBST2(node.left);
if (!a) {
return false;
}
//处理值
if (prev >= node.val) {
return false;
}
prev = node.val;
return isValidBST2(node.right);
}
这段代码实现了一个中序遍历递归方法,用于判断一棵树是否为二叉搜索树(BST)。二叉搜索树的中序遍历结果是一个升序序列。
首先,定义一个全局变量
prev,用于存储上一个节点的值,初始化为Long.MIN_VALUE。定义一个方法
isValidBST2,接收一个节点node作为参数。如果节点为空,返回
true。递归地调用
isValidBST2方法,判断左子树是否为二叉搜索树,如果不满足,返回false。如果上一个节点的值大于等于当前节点的值,说明当前节点的值小于等于上一个节点的值,不满足升序条件,返回
false。否则,将当前节点的值赋给prev。递归地调用
isValidBST2方法,判断右子树是否为二叉搜索树,如果不满足,返回false。总之,这段代码通过中序遍历递归方法实现了判断一棵树是否为二叉搜索树的功能。
/**
* 递归实现
* 其中prev作为参数传入,注意:要传入对象类型的AtomicLong,否则prev作为局部变量,
在递归方法中不起作用
*/
public boolean isValidBST3(TreeNode node) {
return doValidBST1(node, new AtomicLong(Long.MIN_VALUE));
}
private boolean doValidBST1(TreeNode node, AtomicLong prev) {
if (node == null) {
return true;
}
boolean a = doValidBST1(node.left, prev);
if (!a) {
return false;
}
if (prev.get() >= node.val) {
return false;
}
prev.set(node.val);
return doValidBST1(node.right, prev);
}
这段代码实现了一个递归方法,用于判断一棵树是否为二叉搜索树(BST)。二叉搜索树的中序遍历结果是一个升序序列。
定义一个方法
isValidBST3,接收一个节点node作为参数。调用另一个方法
doValidBST1,接收一个节点node和一个原子长整数类型prev作为参数。其中,prev用于存储上一个节点的值,初始化为Long.MIN_VALUE。如果节点为空,返回
true。递归地调用
doValidBST1方法,判断左子树是否为二叉搜索树,如果不满足,返回false。如果上一个节点的值大于等于当前节点的值,说明当前节点的值小于等于上一个节点的值,不满足升序条件,返回
false。否则,将当前节点的值赋给prev。递归地调用
doValidBST1方法,判断右子树是否为二叉搜索树,如果不满足,返回false。总的来说,这段代码通过递归方法实现了判断一棵树是否为二叉搜索树的功能。与前两个方法相比,这里使用了原子长整数类型来存储上一个节点的值,避免了在递归方法中出现局部变量 prev 不起作用的问题。
/**
* 判断每个节点的上下限
* 其中,父节点的左孩子的下限与父节点相同,上限为父节点的值
* 父节点的右孩子的上限与父节点相同,下限为父节点的值
* 如果有节点不符合上下限,则该二叉树不是二叉搜索树
*/
public boolean isValidBST(TreeNode node) {
return doValidBST(node, Long.MIN_VALUE, Long.MAX_VALUE);
}
private boolean doValidBST(TreeNode node, long minValue, long maxValue) {
if (node == null) {
return true;
}
if (node.val >= maxValue || node.val <= minValue) {
return false;
}
return
doValidBST(node.left, minValue, node.val)
&&
doValidBST(node.right, node.val, maxValue);
}
这段代码定义了一个名为
isValidBST的方法,该方法接受一个TreeNode类型的参数,表示要检查的树。该方法的主要目的是判断给定的树是否是二叉搜索树(BST)。首先,它定义了一个名为
doValidBST的方法,该方法接受三个参数:node,minValue和maxValue。node表示当前要检查的节点,minValue和maxValue分别表示当前节点可以接受的下限和上限。
doValidBST方法的主要逻辑如下:
- 如果当前节点为
null,则返回true,因为空树被认为是二叉搜索树。- 如果当前节点的值大于等于
maxValue或小于等于minValue,则返回false,因为二叉搜索树的每个节点的值都应大于其左子树中的所有节点的值,小于其右子树中的所有节点的值。- 递归地检查当前节点的左子树和右子树,确保它们也是二叉搜索树,且它们的下限和上限分别大于等于当前节点的值和小于等于当前节点的值。
最后,
isValidBST方法会递归地调用doValidBST方法,传入根节点和上下限值,以检查整棵树是否是二叉搜索树。如果整棵树都是二叉搜索树,则返回true,否则返回false。
2024/01/10
力扣每日一刷:938. 二叉搜索树的范围和
给定二叉搜索树的根结点
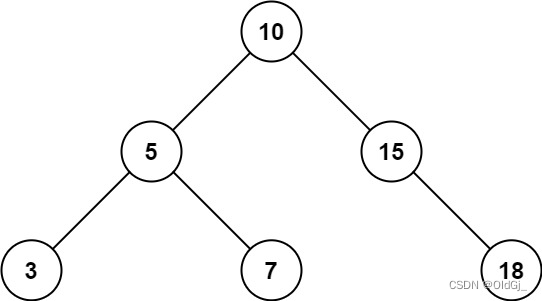
root,返回值位于范围[low, high]之间的所有结点的值的和。示例 1:
?
输入:root = [10,5,15,3,7,null,18], low = 7, high = 15 输出:32示例 2:
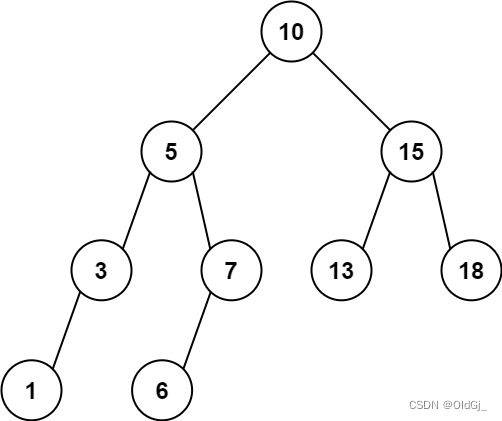
?
输入:root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10 输出:23提示:
- 树中节点数目在范围
[1, 2 * 104]内1 <= Node.val <= 1051 <= low <= high <= 105- 所有
Node.val互不相同
/**
* 中序遍历
*/
public int rangeSumBST1(TreeNode root, int low, int high) {
TreeNode p = root;
LinkedList<TreeNode> stack = new LinkedList<>();
int sum = 0;
while (p != null || !stack.isEmpty()) {
if (p != null) {
stack.push(p);
p = p.left;
} else {
TreeNode pop = stack.pop();
//如果pop值已经大于high,由于是中序遍历,那么后序的值一定不符合上下限范围,直接 break即可
if(pop.val>high){
break;
}
if (pop.val >= low) {
sum += pop.val;
}
p = pop.right;
}
}
return sum;
}
根据中序遍历,将符合上下限的节点的类加并返回即可
这段代码定义了一个名为
rangeSumBST1的方法,该方法接受三个参数:root,low和high。root表示要检查的树,low和high分别表示要计算的范围内节点的下限和上限。
rangeSumBST1方法的主要逻辑如下:
- 初始化一个指向根节点的指针
p,以及一个堆栈stack来存储节点。- 初始化一个变量
sum来存储范围内的节点值之和。- 使用一个
while循环来遍历树。在循环中,首先检查p是否为null,如果是,则从堆栈中弹出一个节点,并将其右子节点作为新的p。如果p不为null,则将p入栈,并将其左子节点作为新的p。- 在循环中,如果当前节点的值大于
high,则跳出循环,因为该节点及其右子树的所有节点的值都大于high,因此不需要继续遍历。- 如果当前节点的值大于等于
low,则将该节点的值加到sum中。- 如果
p为null,则从堆栈中弹出一个节点,并将其右子节点作为新的p。- 循环结束后,返回
sum作为范围内的节点值之和。总之,
rangeSumBST1方法会遍历树,计算并返回指定范围内的节点值之和。
public int rangeSumBST(TreeNode root, int low, int high) {
if(root==null){
return 0;
}
//如果root小于下限,则返回root的右子树中符合上下限的值
if(root.val<low){
return rangeSumBST(root.right,low,high);
}
//如果root大于上限,则返回root的左子树中符合上下限的值
if(root.val>high){
return rangeSumBST(root.left,low,high);
}
//当root的值在上下限范围内,返回root的值+左子树中符合上下限的值+右子树中符合上下限的值
return root.val +
rangeSumBST(root.right,low,high) +
rangeSumBST(root.left,low,high);
}
这段代码定义了一个名为
rangeSumBST的方法,该方法接受三个参数:root,low和high。root表示要检查的树,low和high分别表示要计算的范围内节点的下限和上限。
rangeSumBST方法的主要逻辑如下:
- 如果根节点为
null,则返回0,因为空树的节点值之和为0。- 如果根节点的值小于下限,则返回右子树中符合上下限的值之和。因为根节点及其左子树的节点值都小于下限,所以只需要考虑右子树的节点值。
- 如果根节点的值大于上限,则返回左子树中符合上下限的值之和。因为根节点及其右子树的节点值都大于上限,所以只需要考虑左子树的节点值。
- 如果根节点的值在上下限范围内,则返回根节点的值加上左子树中符合上下限的值之和加上右子树中符合上下限的值之和。因为根节点符合上下限,所以需要考虑左右子树的节点值。
总之,
rangeSumBST方法会遍历树,计算并返回指定范围内的节点值之和。
2024/01/11
每日LeetCode: 1008. 前序遍历构造二叉搜索树
给定一个整数数组,它表示BST(即 二叉搜索树 )的 先序遍历 ,构造树并返回其根。
保证 对于给定的测试用例,总是有可能找到具有给定需求的二叉搜索树。
二叉搜索树 是一棵二叉树,其中每个节点,
Node.left的任何后代的值 严格小于Node.val,Node.right的任何后代的值 严格大于Node.val。二叉树的 前序遍历 首先显示节点的值,然后遍历
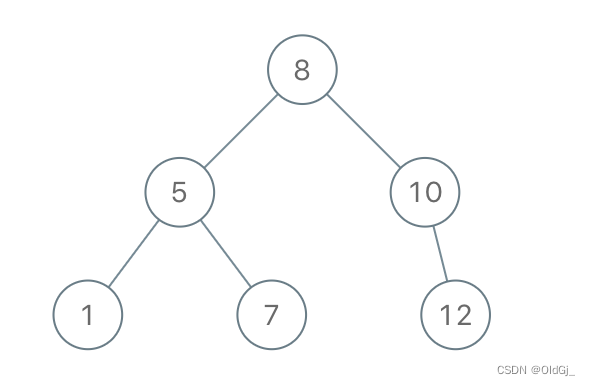
Node.left,最后遍历Node.right。示例 1:
?
输入:preorder = [8,5,1,7,10,12] 输出:[8,5,10,1,7,null,12]示例 2:
输入: preorder = [1,3] 输出: [1,null,3]提示:
1 <= preorder.length <= 1001 <= preorder[i] <= 10^8preorder中的值 互不相同
/**
* 前序遍历构造二叉搜索树
*/
public class E06Leetcode1008 {
/**
* 思路: 将前序遍历的第一个元素作为二叉搜索树的根节点
* 遍历前序遍历数组,依次将从第二个开始的元素插入到以第一个元素为节点的二叉搜索树中
*/
public TreeNode bstFromPreorder(int[] preorder) {
TreeNode root = new TreeNode(preorder[0]);
for (int i = 1; i < preorder.length; i++) {
insert(root, preorder[i]);
}
return root;
}
/**
* 向二叉搜索树中插入元素
*/
private TreeNode insert(TreeNode node, int val) {
//如果当前节点为空,说明找到空位置,返回以val为值的节点
if (node == null) {
return new TreeNode(val);
}
//如果当前值小于当前节点的值,递归调用插入方法,向当前节点的左子树中插入值
if (node.val > val) {
node.left = insert(node.left, val);
}
//如果当前值大于当前节点的值,递归调用插入方法,向当前节点的右子树中插入值
if (node.val < val) {
node.right = insert(node.right, val);
}
return node;
}
}
定义一个名为
bstFromPreorder的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。首先,它创建一个根节点,其值为
preorder[0]。然后,它遍历前序遍历数组preorder中的每个元素,并将它们插入到以根节点为节点的二叉搜索树中。
insert方法是一个辅助方法,用于向二叉搜索树中插入元素。当遇到一个空节点时,它会创建一个新的以val为值的节点并返回。如果当前值小于当前节点的值,它会递归地调用insert方法,将值插入到当前节点的左子树中。如果当前值大于当前节点的值,它会递归地调用insert方法,将值插入到当前节点的右子树中。最后,
bstFromPreorder方法返回根节点,即以preorder[0]为值的二叉搜索树。
/**
* 上限法 [ 8,5,1,7,10,12 ]
* 思路: 依次处理preorder中每个值, 返回创建好的节点或 null 作为上个节点的孩子
* 1. 如果超过上限, 返回 null
* 2. 如果没超过上限, 创建节点, 并将其左右孩子设置完整后返回
* i++ 需要放在设置左右孩子之前,意思是从剩下的元素中挑选左右孩子
*/
public TreeNode bstFromPreorder(int[] preorder) {
return insert(preorder, Integer.MAX_VALUE);
}
int i = 0;
// 参数一:二叉搜索树的前序遍历数组 参数二:当前节点的上限
public TreeNode insert(int[] preorder, int max) {
if (i == preorder.length) {
return null;
}
int val = preorder[i];
//如果大于上限返回null
if (val > max) {
return null;
}
//不大于上限,创建节点
TreeNode node = new TreeNode(val);
//取前序遍历数组中的下一个值
i++;
node.left = insert(preorder, val);
node.right = insert(preorder, max);
return node;
}
这段代码是用Java实现的,它定义了一个名为
bstFromPreorder3的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。这段代码使用了上限法来构建二叉搜索树。上限法的思路是:依次处理
preorder中的每个值,返回创建好的节点或null作为上个节点的孩子。具体来说:
- 如果当前值超过上限,即大于
max,则返回null。- 如果当前值没有超过上限,则创建一个新的节点,将其左孩子设置完整后返回,然后继续处理下一个值。
在
insert方法中,i表示当前正在处理的前序遍历数组的索引。当i等于preorder.length时,表示已经处理完所有值,返回null。在
bstFromPreorder3方法中,i初始化为0,表示正在处理preorder中的第一个值。然后,它调用insert方法,将preorder和Integer.MAX_VALUE作为参数传递。Integer.MAX_VALUE表示当前节点的上限,即比当前节点值大的所有值。最后,
bstFromPreorder3方法返回根节点,即以preorder[0]为值的二叉搜索树。
/**
* 分治法:
* 刚开始 8, 5, 1, 7, 10, 12,方法每次执行,确定本次的根节点和左右子树的分界线
* 第一次确定根节点为 8,左子树 5, 1, 7,右子树 10, 12
* 对 5, 1, 7 做递归操作,确定根节点是 5, 左子树是 1, 右子树是 7
* 对 1 做递归操作,确定根节点是 1,左右子树为 null
* 对 7 做递归操作,确定根节点是 7,左右子树为 null
* 对 10, 12 做递归操作,确定根节点是 10,左子树为 null,右子树为 12
* 对 12 做递归操作,确定根节点是 12,左右子树为 null
* 递归结束,返回本范围内的根节点
*/
public TreeNode bstFromPreorder(int[] preorder) {
return partition(preorder, 0, preorder.length - 1);
}
public TreeNode partition(int[] preorder, int start, int end) {
if (start > end) {
return null;
}
TreeNode root = new TreeNode(preorder[start]);
int index = start + 1;
while (index <= end) {
if (preorder[index] > preorder[start]) {
break;
}
index++;
}
root.left = partition(preorder, start + 1, index - 1);
root.right = partition(preorder, index, end);
return root;
}
这段代码是用Java实现的,它定义了一个名为
bstFromPreorder的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。这段代码使用了分治法来构建二叉搜索树。分治法的思路是:首先确定根节点,然后对左右子树递归执行相同的操作。
具体来说:
- 方法开始时,首先检查
start和end是否满足条件,即start是否小于等于end。如果不满足条件,则返回null。- 创建一个新的二叉搜索树节点,其值为数组中的第一个值
preorder[start]。- 初始化一个
index变量,表示当前子树的范围。从start + 1开始,遍历preorder数组,直到找到一个大于preorder[start]的值,或者遍历完整个数组。- 将
preorder[start + 1]到preorder[index - 1]的值作为左子树的节点值,递归调用partition方法,创建左子树。- 将
preorder[index]到preorder[end]的值作为右子树的节点值,递归调用partition方法,创建右子树。- 返回根节点。
在
partition方法中,start表示当前子树的开始索引,end表示当前子树的结束索引。该方法首先检查start是否大于end,如果是,则表示当前子树为空,返回null。然后,创建一个新的二叉搜索树节点,其值为preorder[start]。接下来,初始化一个index变量,表示当前子树的范围。从start + 1开始,遍历preorder数组,直到找到一个大于preorder[start]的值,或者遍历完整个数组。然后,将preorder[start + 1]到preorder[index - 1]的值作为左子树的节点值,递归调用partition方法,创建左子树。最后,将preorder[index]到preorder[end]的值作为右子树的节点值,递归调用partition方法,创建右子树。最后,返回根节点。
LeetCode每日一刷:235. 二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
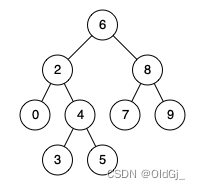
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
?
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出: 6 解释: 节点 2 和节点 8 的最近公共祖先是 6。示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出: 2 解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
/**
* 二叉搜索树的最近公共祖先
* 点:若 p,q 在 ancestor 的两侧,则 ancestor 就是它们的最近公共祖先
*/
public class E07Leetcode235 {
/**
* 思路:当 p 和 q 在一个节点的两侧时(包括p或q等于公共节点),则这个节点就是最近公共祖先
*/
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
TreeNode curr = root;
// q 和 p 在curr节点的同一侧,需要继续查找
while (curr.val > p.val && curr.val > q.val || curr.val < p.val && curr.val < q.val) {
if (curr.val > p.val) {
curr = curr.left;
} else {
curr = curr.right;
}
}
return curr;
}
}
核心思想:p 和 q 在同一节点的两侧时(包括p或q等于公共节点的情况),这个节点就是p和q 的最近公共祖先。
这段代码是用Java实现的,它定义了一个名为
lowestCommonAncestor的方法,该方法接受一个二叉搜索树的根节点root、两个节点p和q作为参数,并返回它们在二叉搜索树中的最近公共祖先(LCA)。这段代码的思路是:从根节点开始,遍历整棵树。当节点
p和q在当前节点的两侧时(包括p或q等于公共节点),则当前节点就是最近公共祖先。如果当前节点的值大于p和q的值,则继续查找左子树;如果当前节点的值小于p和q的值,则继续查找右子树。具体来说:
- 初始化
curr节点为根节点root。- 当
curr节点的值大于p和q的值,或者小于p和q的值时,进入循环。- 如果
curr节点的值大于p和q的值,则查找curr节点的左子树;否则,查找curr节点的右子树。- 循环结束后,
curr节点就是最近公共祖先。这个方法的时间复杂度为O(n),其中n是二叉搜索树的高度。
2024/01/12
全排列问题:
问题描述:
??有1,2,3,4个数,问你有多少种排列方法,并输出排列。问题分析:
若采用==分治思想==进行求解,首先需要把大问题分解成很多的子问题,大问题是所有的排列方法。那么我们分解得到的小问题就是以 1 开头的排列,以 2 开头的排列,以 3 开头的排列,以 4 开头的排列。现在这些问题有能继续分解,比如以 1 开头的排列中,只确定了 1 的位置,没有确定 2 ,3 ,4 的位置,把 2,3,4 三个又看成大问题继续分解,2 做第二个,3 做第二个,或者 4 做第二个。一直分解下去,直到分解成的子问题只有一个数字的时候,不能再分解。只有一个数的序列只有一种排列方式,则子问题求解容易的多。
/**
* 全排列
*/
public class FullPermutation {
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4};
fullPermutation(arr,0,arr.length-1);
}
private static void fullPermutation(int[] arr, int start, int end) {
if(start==end) {
for(int i : arr) {
System.out.print(i);
}
System.out.println();
}
for(int i = start;i<=end;i++) {
swap(arr, start, i);
fullPermutation(arr, start+1, end);
swap(arr, start, i);
}
}
private static void swap(int[]arr,int i,int j) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
LeetCode每五日一总结【01/07–01/12】
2024/01/07:
二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。删除二叉搜索树节点的关键在于找到待删除节点的前驱节点(即小于待删除节点值的最大节点)或后继节点(即大于待删除节点值的最小节点),然后将待删除节点的值替换为后继节点的值,或者将后继节点的值替换为待删除节点的值。
方法一:递归
- 定义一个名为
deleteNode的函数,该函数接受两个参数:一个二叉搜索树的根节点node和一个要删除的节点的值key。- 如果根节点为
null,说明树中没有找到要删除的节点,直接返回null。- 如果要删除的节点的值小于当前节点的值,说明要删除的节点在当前节点的左子树中,将当前节点的左子节点设置为递归调用
deleteNode函数删除要删除节点后的结果。- 如果要删除的节点的值大于当前节点的值,说明要删除的节点在当前节点的右子树中,将当前节点的右子节点设置为递归调用
deleteNode函数删除要删除节点后的结果。- 如果当前节点的左子节点为
null,说明当前节点只有右子节点,返回当前节点的右子节点。- 如果当前节点的右子节点为
null,说明当前节点只有左子节点,返回当前节点的左子节点。- 否则,找到当前节点右子树中的最小值节点
s(待删除节点的后继节点),将当前节点的右子节点设置为递归调用deleteNode函数删除s节点后的结果(将后继节点的右孩子设置为待删除节点的右孩子删除后继节点后的结果),然后将s的左子节点设置为待删除节点的左子节点,返回s。- 最后,返回根节点。
方法二:非递归
定义一个名为
deleteNode2的函数,该函数接受两个参数:一个二叉搜索树的根节点root和一个要删除的节点的值key。定义三个变量:
cur表示当前遍历到的节点,curParent表示当前节点的父节点,successor表示待删除节点的后继节点。使用一个
while循环来查找要删除的节点cur。如果cur为null,说明树中没有找到要删除的节点,直接返回根节点root。如果
cur的左子节点为null且右子节点为null,说明cur是一个叶子节点,直接将其设置为null。如果
cur的右子节点为null,说明cur只有左子节点,直接将其设置为左子节点。如果
cur的左子节点为null,说明cur只有右子节点,直接将其设置为右子节点。如果
cur的左右子节点都不为null,说明cur既有左子节点又有右子节点。找到cur的右子树中的最小值节点successor(后继节点),然后进行以下操作:a. 如果
successor的父节点是cur,说明successor和cur相邻,将successor的右子节点设置为successorParent的右子节点。(处理后继节点的父亲节点)b. 否则(后继节点和待删除节点不相邻),将
successor的右子节点设置为successorParent的左子节点(处理后继节点的父亲节点)
处理完后继节点后,就可以将待删除节点的右孩子赋值给后继节点的右孩子,待删除节点的左孩子赋值给后继节点的左孩子,然后让后继节点代替待删除节点
cur = successor,即可完成删除。如果
cur的父节点为null,说明cur是根节点,直接返回cur。否则,根据
cur是父节点的左子节点还是右子节点,将successor的值替换cur的值作为父节点的左孩子或者右孩子。最后,返回根节点
root。2024/01/08:
二叉搜索树是一种特殊的二叉树,其中每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。插入二叉搜索树节点的关键在于找到插入位置,然后将新节点插入到该位置。
方法一:递归
以下是代码的详细解释:
- 定义一个名为
insertIntoBST的函数,该函数接受两个参数:一个二叉搜索树的根节点node和一个要插入的节点的值val。- 如果根节点为
null,说明找到了合适的插入位置,直接创建一个待插入节点,该节点的值为val,左右子节点为null。- 如果要插入的节点的值小于当前节点的值,说明要插入的节点应该插入到当前节点的左子树中,将当前节点的左子节点设置为递归调用
insertIntoBST函数插入要插入节点后的结果。- 如果要插入的节点的值大于当前节点的值,说明要插入的节点应该插入到当前节点的右子树中,将当前节点的右子节点设置为递归调用
insertIntoBST函数插入要插入节点后的结果。- 最后,返回根节点。
方法二:非递归
- 定义一个名为
insertIntoBST2的函数,该函数接受两个参数:一个二叉搜索树的根节点node和一个要插入的节点的值val。- 如果根节点为
null,说明树中没有找到要插入的节点,直接返回一个新的节点,该节点的值为val,左右子节点为null。- 定义一个指向当前节点的指针
p,以及一个指向当前节点父节点的指针parent。- 使用一个
while循环来==查找插入节点的合适位置。==在循环中,如果插入节点的值小于当前节点的值,则将p指针移动到当前节点的左子节点,如果插入节点的值大于当前节点的值,则将p指针移动到当前节点的右子节点。如果找到要插入的节点,则跳出循环。- 如果找到要插入的节点,则将该节点的值替换为新插入的节点的值,然后跳出循环。
- 如果待插入节点的值小于父节点的值,则待插入节点应该做父节点的左孩子;
- 否则,待插入节点应该做父节点的右孩子。
- 最后,返回根节点。
BST的特点是:每个节点的左子节点的值都小于该节点,每个节点的右子节点的值都大于该节点。
?
函数的输入参数为一个节点和一个要搜索的值。函数首先判断节点是否为空,如果为空,则返回null。
然后,函数会根据给定值的大小与节点值的大小关系,递归地搜索左子树或右子树。如果找到匹配的值,则返回该节点;否则,继续搜索下一个子树。如果最终没有找到匹配的值,则返回null。
2024/01/09:
核心思想:对二叉树进行中序遍历,如果中序遍历结果为升序的,即可证明该二叉树是二叉搜索树,否则不是。(都需要记录上一个节点的值和当前节点的值比大小以判断是否升序)
方法一:非递归中序遍历
首先,创建一个指针
p指向根节点,然后创建一个栈stack和一个变量prev(赋值为长整形的最小值),用于存储上一个节点的值。当
p不为空时,将当前节点压入栈中,然后将p指向当前节点的左子节点。当
p为空时,弹出栈顶节点,将其值与prev进行比较。如果prev大于等于当前节点的值,说明当前节点的值小于等于栈顶节点的值,不满足升序条件,返回false。否则,将当前节点的值赋给prev,并将p指向当前节点的右子节点。重复步骤 2 和 3,直到栈为空且
p为空,说明已经遍历了整个树,返回true。方法二:递归中序遍历
核心思想:必须左右子树全部满足二叉搜索树才返回true
首先,定义一个全局变量
prev,用于存储上一个节点的值,初始化为Long.MIN_VALUE。定义一个方法
isValidBST2,接收一个节点node作为参数。如果节点为空,返回
true。递归地调用
isValidBST2方法,判断左子树是否为二叉搜索树,如果不满足,返回false。如果上一个节点的值大于等于当前节点的值,说明当前节点的值小于等于上一个节点的值,不满足升序条件,返回
false。否则,将当前节点的值赋给prev。递归地调用
isValidBST2方法,判断右子树是否为二叉搜索树,如果不满足,返回false。方法三:判断每个节点的上下限
核心思想:父节点的左孩子的下限与父节点的下限相同,上限为父节点的值,父节点的右孩子的上限于父节点的上限相同,下限为父节点的值,如果有节点不符合上下限,则该二叉树不是二叉搜索树。
这段代码定义了一个名为
isValidBST的方法,该方法接受一个TreeNode类型的参数,表示要检查的树。该方法的主要目的是判断给定的树是否是二叉搜索树(BST)。首先,它定义了一个名为
doValidBST的方法,该方法接受三个参数:node,minValue和maxValue。node表示当前要检查的节点,minValue和maxValue分别表示当前节点可以接受的下限和上限。
doValidBST方法的主要逻辑如下:
- 如果当前节点为
null,则返回true,因为空树被认为是二叉搜索树。- 如果当前节点的值大于等于
maxValue或小于等于minValue,则返回false,因为二叉搜索树的每个节点的值都应大于其左子树中的所有节点的值,小于其右子树中的所有节点的值。- 递归地检查当前节点的左子树和右子树,确保它们也是二叉搜索树,且它们的下限和上限分别大于等于当前节点的值和小于等于当前节点的值。
最后,
isValidBST方法会递归地调用doValidBST方法,传入根节点和上下限值,以检查整棵树是否是二叉搜索树。如果整棵树都是二叉搜索树,则返回true,否则返回false。2024/01/10:
方法一:中序遍历(比方法二效率慢)
根据中序遍历,将符合上下限的节点的类加并返回即可
这段代码定义了一个名为
rangeSumBST1的方法,该方法接受三个参数:root,low和high。root表示要检查的树,low和high分别表示要计算的范围内节点的下限和上限。
rangeSumBST1方法的主要逻辑如下:
- 初始化一个指向根节点的指针
p,以及一个堆栈stack来存储节点。- 初始化一个变量
sum来存储范围内的节点值之和。- 使用一个
while循环来遍历树。在循环中,首先检查p是否为null,如果是,则从堆栈中弹出一个节点,并将其右子节点作为新的p。如果p不为null,则将p入栈,并将其左子节点作为新的p。- 在循环中,如果当前节点的值大于
high,则跳出循环,因为该节点及其右子树的所有节点的值都大于high,因此不需要继续遍历。- 如果当前节点的值大于等于
low,则将该节点的值加到sum中。- 如果
p为null,则从堆栈中弹出一个节点,并将其右子节点作为新的p。- 循环结束后,返回
sum作为范围内的节点值之和。方法二:递归(效率高)
这段代码定义了一个名为
rangeSumBST的方法,该方法接受三个参数:root,low和high。root表示要检查的树,low和high分别表示要计算的范围内节点的下限和上限。
rangeSumBST方法的主要逻辑如下:
- 如果根节点为
null,则返回0,因为空树的节点值之和为0。- 如果根节点的值小于下限,则返回右子树中符合上下限的值之和。因为根节点及其左子树的节点值都小于下限,所以只需要考虑右子树的节点值。
- 如果根节点的值大于上限,则返回左子树中符合上下限的值之和。因为根节点及其右子树的节点值都大于上限,所以只需要考虑左子树的节点值。
- 如果根节点的值在上下限范围内,则返回根节点的值加上左子树中符合上下限的值之和加上右子树中符合上下限的值之和。因为根节点符合上下限,所以需要考虑左右子树的节点值。
2024/01/11:
方法一:遍历插入
定义一个名为
bstFromPreorder的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。首先,它创建一个根节点,其值为
preorder[0]。然后,它遍历前序遍历数组preorder中的每个元素,并将它们插入到以根节点为节点的二叉搜索树中。
insert方法是一个辅助方法,用于向二叉搜索树中插入元素。当遇到一个空节点时,它会创建一个新的以val为值的节点并返回。如果当前值小于当前节点的值,它会递归地调用insert方法,将值插入到当前节点的左子树中。如果当前值大于当前节点的值,它会递归地调用insert方法,将值插入到当前节点的右子树中。最后,
bstFromPreorder方法返回根节点,即以preorder[0]为值的二叉搜索树。方法二:上限法
/** * 前序遍历构造二叉搜索树 */ public class E06Leetcode1008 { /** * 思路: 将前序遍历的第一个元素作为二叉搜索树的根节点 * 遍历前序遍历数组,依次将从第二个开始的元素插入到以第一个元素为节点的二叉搜索树中 */ public TreeNode bstFromPreorder(int[] preorder) { TreeNode root = new TreeNode(preorder[0]); for (int i = 1; i < preorder.length; i++) { insert(root, preorder[i]); } return root; } /** * 向二叉搜索树中插入元素 */ private TreeNode insert(TreeNode node, int val) { //如果当前节点为空,说明找到空位置,返回以val为值的节点 if (node == null) { return new TreeNode(val); } //如果当前值小于当前节点的值,递归调用插入方法,向当前节点的左子树中插入值 if (node.val > val) { node.left = insert(node.left, val); } //如果当前值大于当前节点的值,递归调用插入方法,向当前节点的右子树中插入值 if (node.val < val) { node.right = insert(node.right, val); } return node; } }这段代码是用Java实现的,它定义了一个名为
bstFromPreorder3的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。这段代码使用了上限法来构建二叉搜索树。上限法的思路是:依次处理
preorder中的每个值,返回创建好的节点或null作为上个节点的孩子。具体来说:
- 如果当前值超过上限,即大于
max,则返回null。- 如果当前值没有超过上限,则创建一个新的节点,将其左孩子设置完整后返回,然后继续处理下一个值。
在
insert方法中,i表示当前正在处理的前序遍历数组的索引。当i等于preorder.length时,表示已经处理完所有值,返回null。在
bstFromPreorder3方法中,i初始化为0,表示正在处理preorder中的第一个值。然后,它调用insert方法,将preorder和Integer.MAX_VALUE作为参数传递。Integer.MAX_VALUE表示当前节点的上限,即比当前节点值大的所有值。最后,
bstFromPreorder3方法返回根节点,即以preorder[0]为值的二叉搜索树。方法三:分治法
/** * 分治法: * 刚开始 8, 5, 1, 7, 10, 12,方法每次执行,确定本次的根节点和左右子树的分界线 * 第一次确定根节点为 8,左子树 5, 1, 7,右子树 10, 12 * 对 5, 1, 7 做递归操作,确定根节点是 5, 左子树是 1, 右子树是 7 * 对 1 做递归操作,确定根节点是 1,左右子树为 null * 对 7 做递归操作,确定根节点是 7,左右子树为 null * 对 10, 12 做递归操作,确定根节点是 10,左子树为 null,右子树为 12 * 对 12 做递归操作,确定根节点是 12,左右子树为 null * 递归结束,返回本范围内的根节点 */ public TreeNode bstFromPreorder(int[] preorder) { return partition(preorder, 0, preorder.length - 1); } public TreeNode partition(int[] preorder, int start, int end) { if (start > end) { return null; } TreeNode root = new TreeNode(preorder[start]); int index = start + 1; while (index <= end) { if (preorder[index] > preorder[start]) { break; } index++; } root.left = partition(preorder, start + 1, index - 1); root.right = partition(preorder, index, end); return root; }这段代码是用Java实现的,它定义了一个名为
bstFromPreorder的方法,该方法接受一个整数数组preorder作为参数,并返回一个二叉搜索树(BST)。这段代码使用了分治法来构建二叉搜索树。分治法的思路是:首先确定根节点,然后对左右子树递归执行相同的操作。
具体来说:
- 方法开始时,首先检查
start和end是否满足条件,即start是否小于等于end。如果不满足条件,则返回null。- 创建一个新的二叉搜索树节点,其值为数组中的第一个值
preorder[start]。- 初始化一个
index变量,表示当前子树的范围。从start + 1开始,遍历preorder数组,直到找到一个大于preorder[start]的值,或者遍历完整个数组。- 将
preorder[start + 1]到preorder[index - 1]的值作为左子树的节点值,递归调用partition方法,创建左子树。- 将
preorder[index]到preorder[end]的值作为右子树的节点值,递归调用partition方法,创建右子树。- 返回根节点。
在
partition方法中,start表示当前子树的开始索引,end表示当前子树的结束索引。该方法首先检查start是否大于end,如果是,则表示当前子树为空,返回null。然后,创建一个新的二叉搜索树节点,其值为preorder[start]。接下来,初始化一个index变量,表示当前子树的范围。从start + 1开始,遍历preorder数组,直到找到一个大于preorder[start]的值,或者遍历完整个数组。然后,将preorder[start + 1]到preorder[index - 1]的值作为左子树的节点值,递归调用partition方法,创建左子树。最后,将preorder[index]到preorder[end]的值作为右子树的节点值,递归调用partition方法,创建右子树。最后,返回根节点。核心思想:p 和 q 在同一节点的两侧时(包括p或q等于公共节点的情况),这个节点就是p和q 的最近公共祖先。
这段代码是用Java实现的,它定义了一个名为
lowestCommonAncestor的方法,该方法接受一个二叉搜索树的根节点root、两个节点p和q作为参数,并返回它们在二叉搜索树中的最近公共祖先(LCA)。这段代码的思路是:从根节点开始,遍历整棵树。当节点
p和q在当前节点的两侧时(包括p或q等于公共节点),则当前节点就是最近公共祖先。如果当前节点的值大于p和q的值,则继续查找左子树;如果当前节点的值小于p和q的值,则继续查找右子树。具体来说:
- 初始化
curr节点为根节点root。- 当
curr节点的值大于p和q的值,或者小于p和q的值时,进入循环。- 如果
curr节点的值大于p和q的值,则查找curr节点的左子树;否则,查找curr节点的右子树。- 循环结束后,
curr节点就是最近公共祖先。这个方法的时间复杂度为O(n),其中n是二叉搜索树的高度。
2024/01/12:
**全排列问题:**分治法
/** * 全排列 */ public class FullPermutation { public static void main(String[] args) { int[] arr = new int[]{1,2,3,4}; fullPermutation(arr,0,arr.length-1); } private static void fullPermutation(int[] arr, int start, int end) { if(start==end) { for(int i : arr) { System.out.print(i); } System.out.println(); } for(int i = start;i<=end;i++) { swap(arr, start, i); fullPermutation(arr, start+1, end); swap(arr, start, i); } } private static void swap(int[]arr,int i,int j) { int t = arr[i]; arr[i] = arr[j]; arr[j] = t; } }
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【力扣刷题练习】20. 有效的括号
- Keras常用的激活函数详细介绍
- vivado JTAG链、连接、IP关联规则
- 琴行销售管理系统(JSP+java+springmvc+mysql+MyBatis)
- vue element 多个日期组件选择禁止重叠
- Python 面向对象绘图(Matplotlib篇-16)
- 第11章 《GUI》Page404 课堂作业,验证鼠标事件的坐标,GUI编程如何在控制台输出调试
- 「 典型安全漏洞系列 」06.路径遍历(Path Traversal)详解
- 使用WSL
- Linux内核--网络协议栈(三)UDP协议层/IP层的处理