一元线性回归模型(公式推导+举例应用)
引言
一元线性回归是回归分析中简单而重要的一种模型,旨在找到一条直线,以最佳方式拟合输入变量与输出变量之间的关系。在这篇文章中,我们将深入探讨一元线性回归的原理及其应用。
模型表达式
一元线性回归模型的表达式为:
f
(
x
i
)
=
k
x
i
+
b
f(x_i)=kx_i+b
f(xi?)=kxi?+b
其中,
x
i
x_i
xi?为输入变量,
f
(
x
i
)
f(x_i)
f(xi?)为模型的输出,
k
k
k为斜率,
b
b
b为截距,我们的目标是通过学习
k
k
k和
b
b
b使得
f
(
x
i
)
f(x_i)
f(xi?)尽可能的接近真实观测值
y
i
y_i
yi?。
均方误差和优化目标
为了衡量模型的性能,我们引入均方误差
J
(
k
,
b
)
:
J(k,b):
J(k,b):
J
(
k
,
b
)
=
∑
i
=
1
m
(
f
(
x
i
)
?
y
i
)
2
J(k,b)=\sum_{i=1}^m(f(x_i)-y_i)^2
J(k,b)=i=1∑m?(f(xi?)?yi?)2
其中
m
m
m为样本数量。我们的优化目标是最小化均方误差,即:
E ( k ? , b ? ) = a r g ( k , b ) m i n ∑ i = 1 m ( y i ? k x i ? b ) 2 E(k^\star,b^\star)=arg_{(k,b)}min\sum_{i=1}^m(y_i-kx_i-b)^2 E(k?,b?)=arg(k,b)?mini=1∑m?(yi??kxi??b)2
最小二乘法
通过最小二乘法,我们对均方误差函数分别对
k
k
k和
b
b
b求偏导数,令其等于零,得到优化的解:
?
?
k
E
(
k
,
b
)
=
?
2
∑
i
=
1
n
x
i
(
y
i
?
(
k
x
i
+
b
)
)
=
0
\frac{\partial}{\partial k} E(k, b)=-2\sum_{i=1}^n x_i\left(y_i-\left(k x_i+b\right)\right)=0
?k??E(k,b)=?2i=1∑n?xi?(yi??(kxi?+b))=0
?
?
b
E
(
k
,
b
)
=
?
2
∑
i
=
1
n
(
y
i
?
(
k
x
i
+
b
)
)
=
0
\frac{\partial}{\partial b} E(k, b)=-2\sum_{i=1}^n\left(y_i-\left(k x_i+b\right)\right)=0
?b??E(k,b)=?2i=1∑n?(yi??(kxi?+b))=0
整理并得到:
k
=
∑
i
=
1
m
y
i
(
x
i
?
x
ˉ
)
∑
i
=
1
m
x
i
2
?
1
m
(
∑
i
=
1
m
x
i
)
2
k=\frac{\sum_{i=1}^my_i(x_i- \bar x)}{\sum_{i=1}^mx_i^2-\frac{1}{m}(\sum_{i=1}^mx_i)^2}
k=∑i=1m?xi2??m1?(∑i=1m?xi?)2∑i=1m?yi?(xi??xˉ)?
b
=
1
m
∑
i
=
1
m
(
y
i
?
k
x
i
)
b=\frac{1}{m}\sum_{i=1}^m(y_i-kx_i)
b=m1?i=1∑m?(yi??kxi?)
其中,
x
ˉ
\bar x
xˉ为输入变量
x
x
x的均值。最终得到模型表达式:
f
(
x
i
)
=
k
T
x
i
+
b
f(x_i)=k^Tx_i+b
f(xi?)=kTxi?+b
使得
f
(
x
i
)
f(x_i)
f(xi?)尽可能地接近
y
i
y_i
yi?。
利用协方差和方差求解 k k k和 b b b
另一种求解斜率
k
k
k和截距
b
b
b的方法是通过协方差和方差的关系。
因为
Y
=
k
X
+
b
Y=kX+b
Y=kX+b,所以
E
Y
=
k
E
X
+
b
EY=kEX+b
EY=kEX+b
又因为
X
Y
=
k
X
2
+
b
X
XY=kX^2+bX
XY=kX2+bX,所以
E
X
Y
=
k
E
X
2
+
b
E
X
EXY=kEX^2+bEX
EXY=kEX2+bEX
联立两个式子可得:
k
=
E
X
Y
?
E
X
E
Y
E
X
2
?
(
E
X
)
2
=
C
O
V
(
X
,
Y
)
D
X
k=\frac{EXY-EXEY}{EX^2-(EX)^2}=\frac{COV(X,Y)}{DX}
k=EX2?(EX)2EXY?EXEY?=DXCOV(X,Y)?
b
=
E
Y
?
k
E
X
b=EY-kEX
b=EY?kEX
我们同样可以得到一元线性回归模型
f
(
x
i
)
=
k
T
x
i
+
b
f(x_i)=k^Tx_i+b
f(xi?)=kTxi?+b
结论
通过最小二乘法和协方差方差的推导,我们得到了一元线性回归的两种求解方法。这些方法为我们建立模型和预测提供了有力的工具,同时也帮助我们理解了回归分析的基本原理。在实际应用中,我们可以根据具体情况选择合适的方法来进行建模和分析。
实验分析
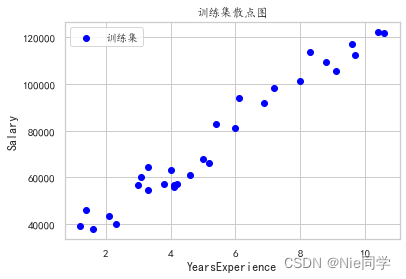
以下是工人工作年限与对应薪水的数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context="notebook", style="whitegrid", palette="deep")
# 读入数据集
data = pd.read_csv('data/Salary_dataset.csv')
# 绘制散点图
plt.rcParams['font.family'] = 'KaiTi'
plt.scatter(data['YearsExperience'], data['Salary'], c='blue', label='训练集')
# 添加标签和标题
plt.xlabel('x')
plt.ylabel('y')
plt.title('训练集散点图')
# 添加图例
plt.legend()
# 显示图形
plt.show()
# 更新k,b(协方差)
def update_k_b(data, k, b):
# 计算协方差和方差
cov_xy = np.sum((data['YearsExperience'] - data['YearsExperience'].mean()) * (data['Salary'] - data['Salary'].mean()))
var_x = np.sum((data['YearsExperience'] - data['YearsExperience'].mean())**2)
# 计算k和b
k = cov_xy / var_x
b = data['Salary'].mean() - k * data['YearsExperience'].mean()
return k, b
# 更新k,b(最小二乘法)
def update_k_b_2(data, k, b):
w = np.sum(data['Salary'] * (data['YearsExperience'] - data['YearsExperience'].mean())) / (np.sum(data['Salary'] ** 2) - np.sum(data['Salary']) ** 2 / len(data))
b = data['Salary'].mean() - k * data['YearsExperience'].mean()
return k, b
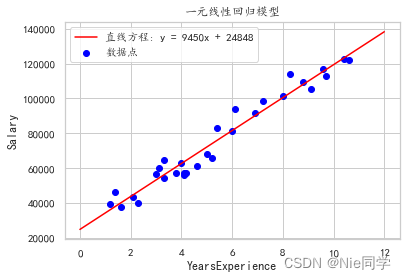
计算 k k k和 b b b
k = b = 0
k, b = update_k_b(data, k, b)
得到
k
=
9449.962321455076
k=9449.962321455076
k=9449.962321455076,
b
=
24848.2039665232
b=24848.2039665232
b=24848.2039665232。
绘制最终的拟合直线:
# 绘制散点图
plt.rcParams['font.family'] = 'KaiTi'
plt.scatter(data['YearsExperience'], data['Salary'], c = 'blue', label = '数据点')
# 生成一些x值
x_line = np.linspace(0, 12, 100)
# 根据直线方程计算对应的y值
y_line = k * x_line + b
# 绘制直线图
plt.plot(x_line, y_line, label = f'直线方程: y = {k:.0f}x + {b:.0f}', c = 'red')
# 添加标签和标题
plt.xlabel('YearsExperience')
plt.ylabel('Salary')
plt.title('一元线性回归模型')
# 添加图例
plt.legend()
# 显示图形
plt.show()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Swagger升级指南:Swagger2与Swagger3注解差异揭秘
- mllib可扩展学习库java api使用
- 阻抗继电器行业分析:全球市场规模约为7.3亿美元
- 2023云数据安全技术总结,与2024技术展望
- PDF文档转换工具箱流量主小程序开发
- 条件覆盖和条件组合覆盖测试设计-实验八例题
- 【matlab】绘制竖状双组渐变柱状图
- 机器学习——主成成分分析PCA
- 全网最全fiddler使用教程和fiddler如何抓包(fiddler手机抓包)-笔者亲测
- 爬虫与反爬虫技术简介