java-HashMap&LinkedHashMap 源码分析
HashMap
底层结构:数组(根据hashcode判断k,v的存储地址 即不同key可能有相同的hashCode)+链表(链表长度>8会先扩容 数组长度扩容到64树化)/红黑树(数组长度到64会树化)
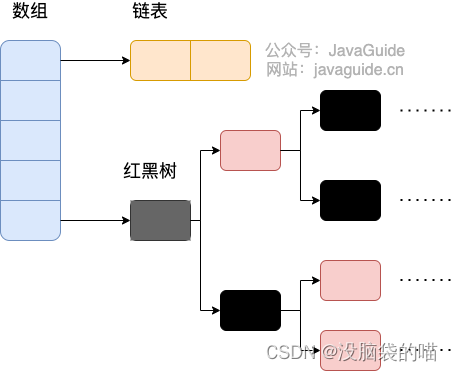
hashMap遍历-六大遍历方式




扩容机制
loadFactor 负载因子
loadFactor 的默认值为 0.75f。给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量超过了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容

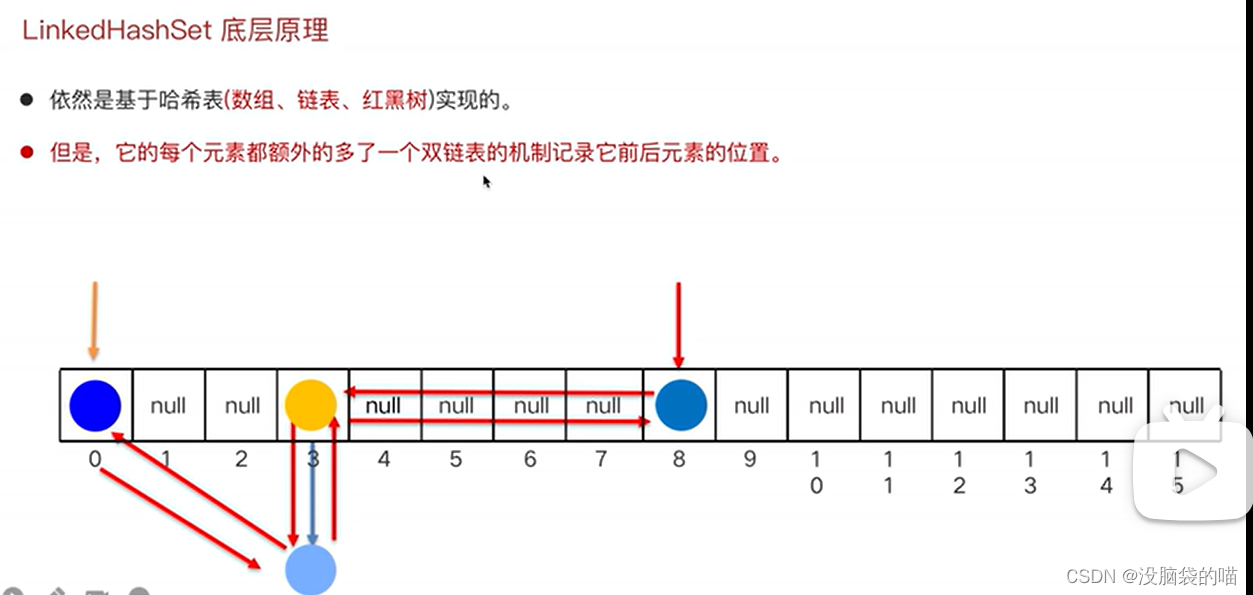
LinkedHashSet
LinkedHashMap
保证顺序:每个链表记录上一个插入的节点和下一个插入节点 head指向第一个元素 tail指向最后一个元素
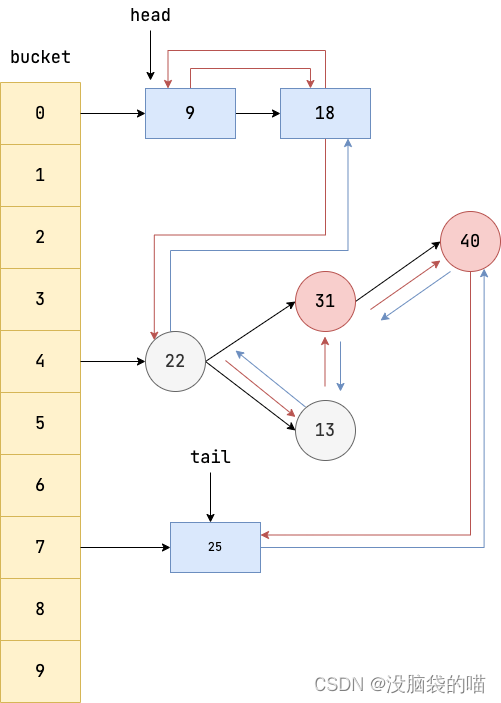
特点:
1.支持遍历时会按照插入顺序有序进行迭代。
2.支持按照元素访问顺序排序,适用于封装 LRU 缓存工具
使用LinkedHashMap实现LRU 缓存
具体实现思路如下:
1.继承 LinkedHashMap;
2.构造方法中指定 accessOrder 为 true ,这样在访问元素时就会把该元素移动到链表尾部,链表首元素就是最近最少被访问的元素;
3.重写removeEldestEntry 方法,该方法会返回一个 boolean 值,告知 LinkedHashMap 是否需要移除链表首元素(缓存容量有限)。
代码如下:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 判断size超过容量时返回true,告知LinkedHashMap移除最老的缓存项(即链表的第一个元素)
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}
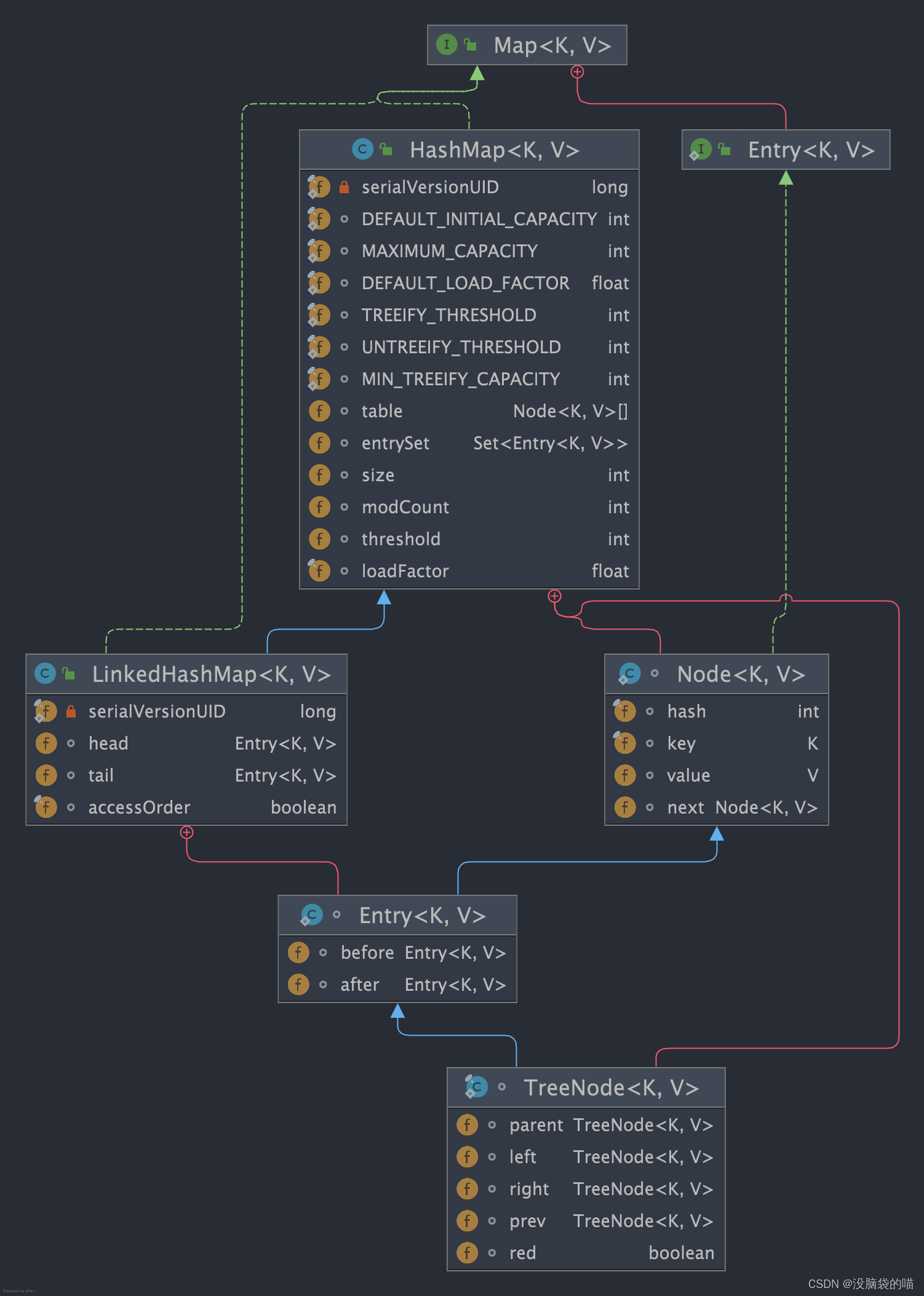
LinkedHashMap源码解析
树化与双向链表的冲突
LinkedHashMap 是在 HashMap 的基础上为 bucket 上的每一个节点建立一条双向链表,这就使得转为红黑树的树节点也需要具备双向链表节点的特性,即每一个树节点都需要拥有两个引用存储前驱节点和后继节点的地址,
LinkedHashMap 的节点内部类 Entry 基于 HashMap 的基础上,增加 before 和 after 指针使节点具备双向链表的特性。HashMap 的树节点 TreeNode 继承了具备双向链表特性的 LinkedHashMap 的 Entry。
构造函数
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
默认情况下 accessOrder 为 false,如果我们要让 LinkedHashMap 实现键值对按照访问顺序排序(即将最近未访问的元素排在链表首部、最近访问的元素移动到链表尾部),需要调用第 4 个构造方法将 accessOrder 设置为 true
get方法
public V get(Object key) {
Node < K, V > e;
//获取key的键值对,若为空直接返回
if ((e = getNode(hash(key), key)) == null)
return null;
//若accessOrder为true,则调用afterNodeAccess将当前元素移到链表末尾
if (accessOrder)
afterNodeAccess(e);//最近访问的被移动到队尾
//返回键值对的值
return e.value;
}
afterNodeAccess 方法的实现
这个方法负责将元素移动到链表末尾。
afterNodeAccess 方法完成了下面这些操作:
如果 accessOrder 为 true 且链表尾部不为当前节点 p,我们则需要将当前节点移到链表尾部。
获取当前节点 p、以及它的前驱节点 b 和后继节点 a。
将当前节点 p 的后继指针设置为 null,使其和后继节点 p 断开联系。
尝试将前驱节点指向后继节点,若前驱节点为空,则说明当前节点 p 就是链表首节点,故直接将后继节点 a 设置为首节点,随后我们再将 p 追加到 a 的末尾。
再尝试让后继节点 a 指向前驱节点 b。
上述操作让前驱节点和后继节点完成关联,并将当前节点 p 独立出来,
这一步则是将当前节点 p 追加到链表末端,如果链表末端为空,则说明当前链表只有一个节点 p,所以直接让 head 指向 p 即可。
上述操作已经将 p 成功到达链表末端,最后我们将 tail 指针即指向链表末端的指针指向 p 即可
!!!(再看)
void afterNodeAccess(Node < K, V > e) { // move node to last
LinkedHashMap.Entry < K, V > last;
//如果accessOrder 且当前节点不未链表尾节点
if (accessOrder && (last = tail) != e) {
//获取当前节点、以及前驱节点和后继节点
LinkedHashMap.Entry < K, V > p =
(LinkedHashMap.Entry < K, V > ) e, b = p.before, a = p.after;
//将当前节点的后继节点指针指向空,使其和后继节点断开联系
p.after = null;
//如果前驱节点为空,则说明当前节点是链表的首节点,故将后继节点设置为首节点
if (b == null)
head = a;
else
//如果后继节点不为空,则让前驱节点指向后继节点
b.after = a;
//如果后继节点不为空,则让后继节点指向前驱节点
if (a != null)
a.before = b;
else
//如果后继节点为空,则说明当前节点在链表最末尾,直接让last 指向前驱节点,这个 else其实 没有意义,因为最开头if已经确保了p不是尾结点了,自然after不会是null
last = b;
//如果last为空,则说明当前链表只有一个节点p,则将head指向p
if (last == null)
head = p;
else {
//反之让p的前驱指针指向尾节点,再让尾节点的前驱指针指向p
p.before = last;
last.after = p;
}
//tail指向p,自此将节点p移动到链表末尾
tail = p;
++modCount;
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!