常用组件的一些数据指标
QPS
metrics 机制,利用 AtomicLong 算出核心接口每分钟调用多少次(除以 60 就是高峰期每秒访问次数)以及每天被调用总次数
TP99 = 100ms , 99%的接口耗时在 100ms以内,1%的接口耗时在100ms以上
TP95 = 100ms , 95%的接口耗时在 100ms以内,5%的接口耗时在100ms以上
平均响应延时 = (每次调用的耗时 + 历史总耗时 )/ 当前请求的总次数
最大 QPS:
假设最大 QPS 为 800 ,当压测工具每秒发起 1000 个请求的时候,只有 800个可以同时被处理,200 个在排队被阻塞住
lvs+nginx
一个大致的配置可能包括:
硬件配置:4台高性能的服务器,每台配备多核 CPU、大容量内存和高速磁盘;例如,每台服务器有 16 核 CPU、64GB 内存、SSD 硬盘等。
网络带宽:每台服务器具有较高的网络带宽,例如千兆或更高的带宽。
LVS:LVS 作为负载均衡器,配置为四台服务器的后端。
Nginx:Nginx 配置为每台服务器的前端,用于处理 HTTP 请求并进行负载均衡。Nginx 配置了反向代理、缓存策略和负载均衡算法等。
Keepalived:用于实现高可用性,确保负载均衡器的高可用性。
对于这样的配置,大概能抗的并发连接数可能在数十万到数百万级别。然而,这个估计仅供参考,实际的性能还会受到请求类型、网络流量、优化设置等多种因素的影响。最准确的评估方法是进行压力测试,模拟实际负载并评估集群的性能极限。
数十万到数百万并发
nginx
中等nginx配置
处理器:4核或以上
内存:8GB或以上
存储:SSD硬盘
网络:1Gbps带宽
单台nginx一般能抗数万到数十万个并发数
同时,Nginx的并发连接数也可以通过调整Nginx的配置文件来进行优化,例如调整worker_processes和worker_connections参数。这些参数的调整需要根据具体的硬件配置和应用需求来进行评估和优化
redis
单机6-8w qps,采用claster分片模式理论上可以横向扩容
rabbitMq
万级并发,主从结构,存在单机瓶颈,横向扩容有限
rocketMq
十万级并发
分布式架构,横向扩容无压力
kafka
十万级
分布式架构,横向扩容无压力
mysql
16 核 32G,物理机,高峰期每秒几千(三四千的时候,网络负载比较高,CPU 使用率比较高,I/O 负载比较高)请求问题不大
数据库换成32 核 128G (每秒抗住几千请求问题不大)
采用分库分表、读写分离(一主一从,两主两从等),再怎么优化很难超过10w级 qps
固态硬盘
IOPS 大概在 3 万左右
eureka
配置 8核 16G 单台,16 核 32G,每台机器每秒钟的请求支撑几千绝对没问题,可以支撑上千个服务
建议3~5台左右配置就可以了
中小型公司 20~30 个服务,注册中心 2 ~3 台机器(4 核 8G),每秒抗上千请求
注册中心优化服务注册和发现配置
注册表多级缓存同步 1 秒,注册表拉取频率 1 秒
服务心跳 1 秒上报一次,服务故障发现 1 秒,发现 2 秒内服务没上报心跳,就故障
zuul
每秒并发在1000 以内,每个服务部署 2 台机器,每台机器 4 核 8G,每台机器抗几百请求一点问题都没
大部分系统高峰期每秒几百请求,低峰期每秒几十请求,几个请求
springCloudGateway
每台机器 8 核 16G 能抗2000左右,springCloudGateway性能是比较吃cpu和内存的
一次用户请求时长
一般互联网类的企业,对用户的直接操作,一般要求每个请求都必须在 200ms以内,对用户几乎是无感知的。
示例cat查看指标

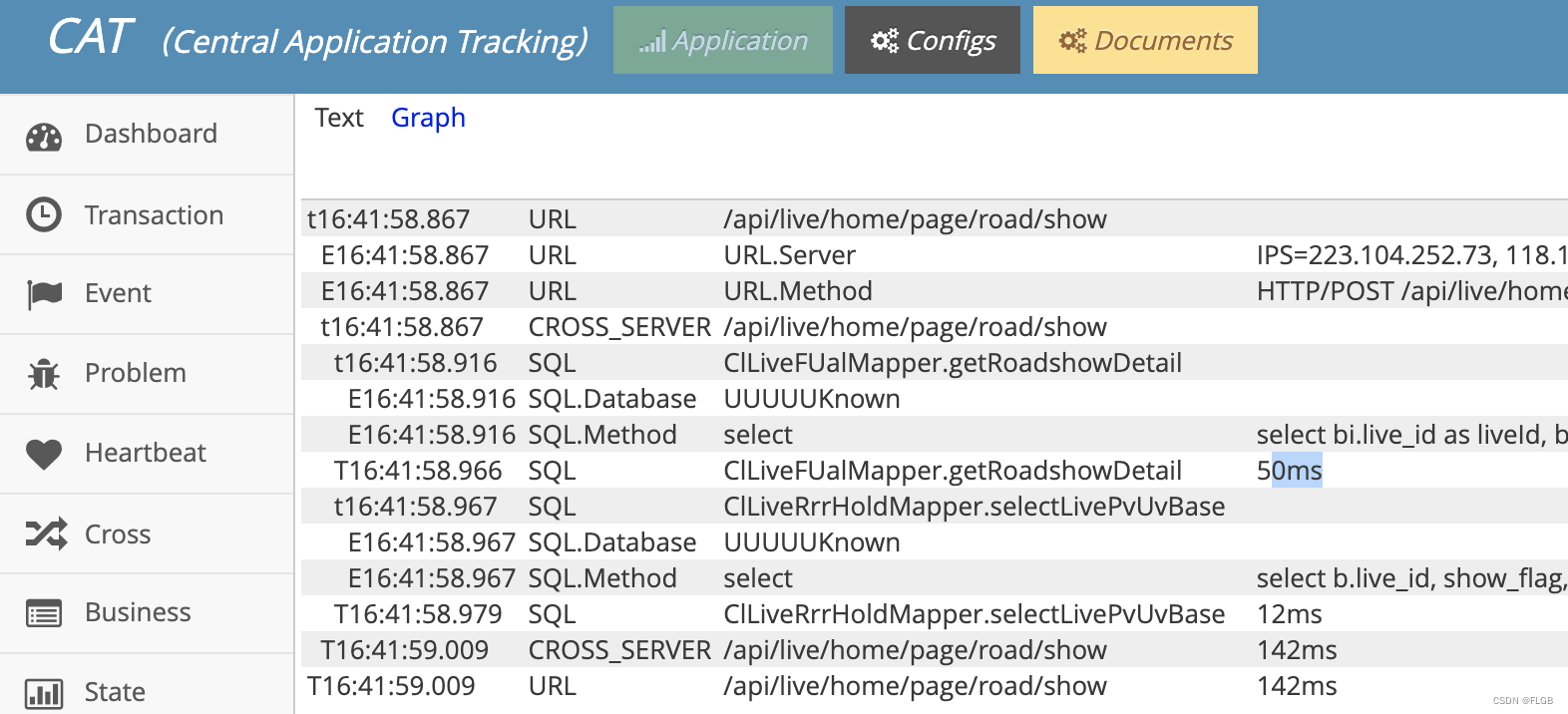
一次数据库查询时长
在十毫秒级别完成一次简单的查询
binlog同步延迟
十毫秒级别(几毫秒到十几毫秒不等)
一次rpc接口调用时长
30毫秒左右,最好在50毫秒以内(十几毫秒到几十毫秒不等)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- WEB前端人机交互导论实验-实训4 DIV+CSS综合运用
- java实现适配器设计模式
- Dock的安装部署和基础命令
- 【漏洞复现】傲盾信息安全管理系统前台 sichuan_login 远程命令执行
- 机器学习算法---回归
- 使用VSCode内的jupyter编写R语言:绘制中国省份地区热力图
- 基于深度学习的热红外图像增强算法
- 洛谷P2911 [USACO08OCT] Bovine Bones G(C语言)
- 前端JavaScript篇之实现有序数组原地去重方法有哪些?
- 2017年认证杯SPSSPRO杯数学建模D题(第二阶段)教室的合理设计全过程文档及程序