第 12 章 多路查找树
文章目录
12.1 二叉树与B 树
12.1.1 二叉树的问题分析
二叉树的操作效率较高,但是也存在问题, 请看下面的二叉树
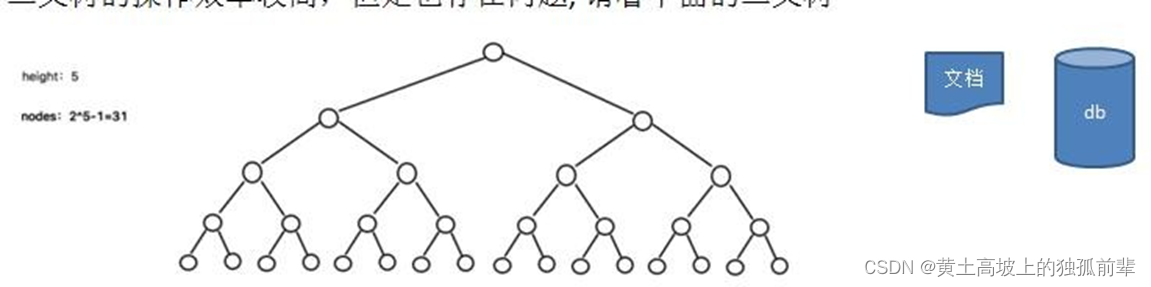
- 二叉树需要加载到内存的,如果二叉树的节点少,没有什么问题,但是如果二叉树的节点很多(比如 1 亿), 就存在如下问题:
- 问题 1:在构建二叉树时,需要多次进行 i/o 操作(海量数据存在数据库或文件中),节点海量,构建二叉树时,速度有影响
- 问题 2:节点海量,也会造成二叉树的高度很大,会降低操作速度.
12.1.2 多叉树
- 在二叉树中,每个节点有数据项,最多有两个子节点。如果允许每个节点可以有更多的数据项和更多的子节点,就是多叉树(multiway tree)
- 后面我们讲解的 2-3 树,2-3-4 树就是多叉树,多叉树通过重新组织节点,减少树的高度,能对二叉树进行优化。
- 举例说明(下面 2-3 树就是一颗多叉树)
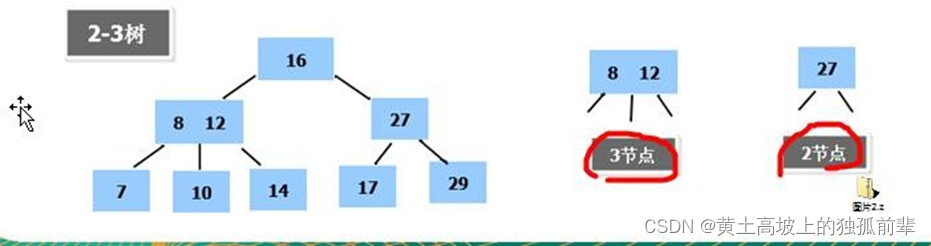
12.1.3 B 树的基本介绍
B 树通过重新组织节点,降低树的高度,并且减少 i/o 读写次数来提升效率。

- 如图 B 树通过重新组织节点, 降低了树的高度.
- 文件系统及数据库系统的设计者利用了磁盘预读原理,将一个节点的大小设为等于一个页(页得大小通常为 4k),这样每个节点只需要一次 I/O 就可以完全载入
- 将树的度M 设置为 1024,在 600 亿个元素中最多只需要 4 次 I/O 操作就可以读取到想要的元素, B 树(B+)广泛应用于文件存储系统以及数据库系统中
12.2 2-3 树
12.2.1 2-3 树是最简单的 B 树结构, 具有如下特点:
-
2-3 树的所有叶子节点都在同一层.(只要是 B 树都满足这个条件)
-
有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点.
-
有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点.
-
2-3 树是由二节点和三节点构成的树。
12.2.2 2-3 树应用案例
将数列{16, 24, 12, 32, 14, 26, 34, 10, 8, 28, 38, 20} 构建成 2-3 树,并保证数据插入的大小顺序。(演示一下构建 2-3
树的过程.)
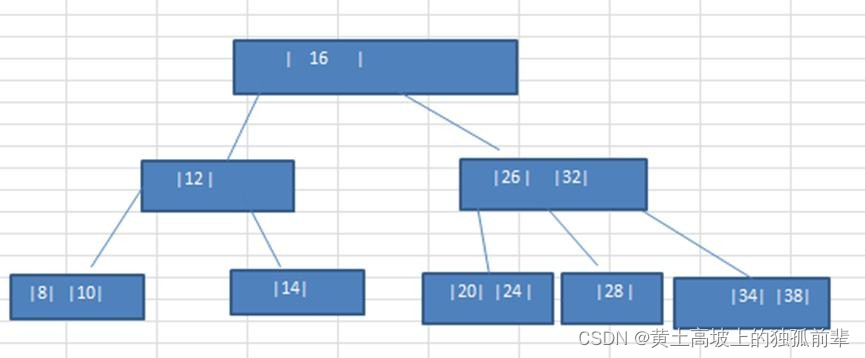
插入规则:
-
2-3 树的所有叶子节点都在同一层.(只要是 B 树都满足这个条件)
-
有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点.
-
有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点
-
当按照规则插入一个数到某个节点时,不能满足上面三个要求,就需要拆,先向上拆,如果上层满,则拆本层,
拆后仍然需要满足上面 3 个条件。 -
对于三节点的子树的值大小仍然遵守(BST 二叉排序树)的规则
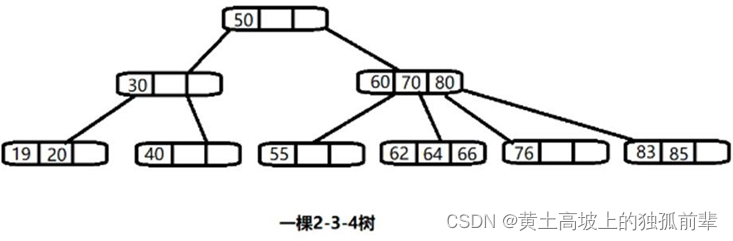
12.2.3 其它说明
除了 23 树,还有 234 树等,概念和 23 树类似,也是一种 B 树。 如图:
12.3 B 树、B+树和 B*树
12.3.1 B 树的介绍
B-tree 树即 B 树,B 即 Balanced,平衡的意思。有人把 B-tree 翻译成 B-树,容易让人产生误解。会以为 B-树是一种树,而 B 树又是另一种树。实际上,B-tree 就是指的 B 树。
12.3.2 B 树的介绍
前面已经介绍了 2-3 树和 2-3-4 树,他们就是 B 树(英语:B-tree 也写成 B-树),这里我们再做一个说明,我们在学习 Mysql 时,经常听到说某种类型的索引是基于 B 树或者 B+树的,如图:
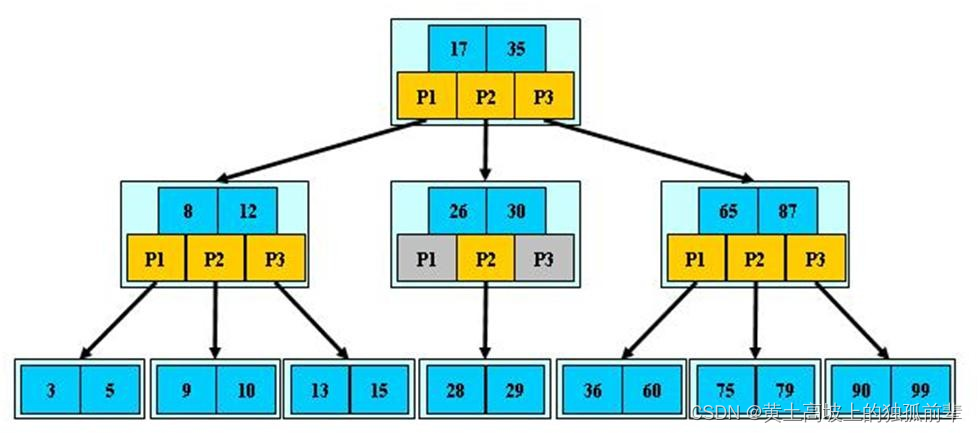
对上图的说明:
-
B 树的阶:节点的最多子节点个数。比如 2-3 树的阶是 3,2-3-4 树的阶是 4
-
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点
-
关键字集合分布在整颗树中, 即叶子节点和非叶子节点都存放数据.
-
搜索有可能在非叶子结点结束
-
其搜索性能等价于在关键字全集内做一次二分查找
12.3.3 B+树的介绍
B+树是 B 树的变体,也是一种多路搜索树。
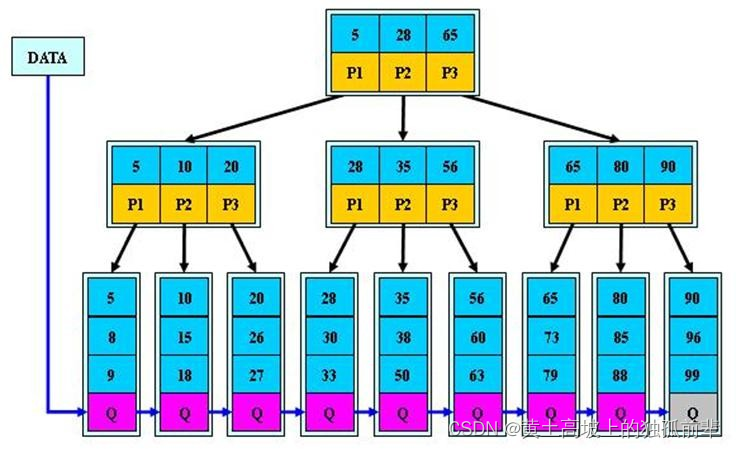
对上图的说明:
-
B+树的搜索与 B 树也基本相同,区别是 B+树只有达到叶子结点才命中(B 树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找
-
所有关键字都出现在叶子结点的链表中(即数据只能在叶子节点【也叫稠密索引】),且链表中的关键字(数据)恰好是有序的。
-
不可能在非叶子结点命中
-
非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
-
更适合文件索引系统
-
B 树和 B+树各有自己的应用场景,不能说 B+树完全比 B 树好,反之亦然.
12.3.4 B*树的介绍
B*树是 B+树的变体,在 B+树的非根和非叶子结点再增加指向兄弟的指针。
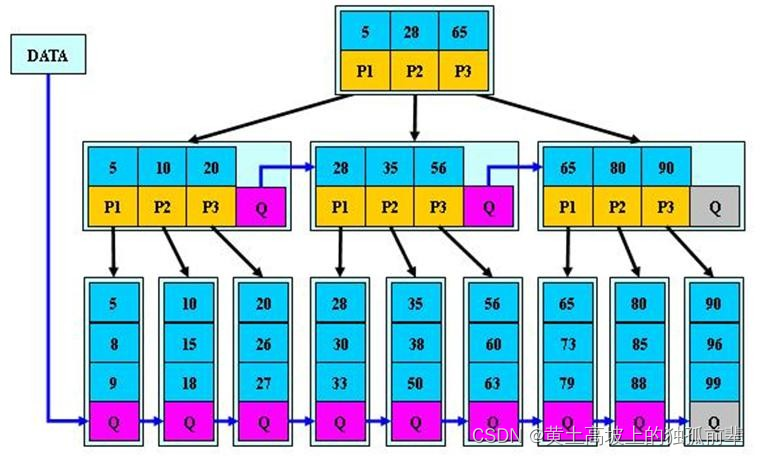
? B*树的说明:
- B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为 2/3,而 B+树的块的最低使用率为的
1/2。 - 从第 1 个特点我们可以看出,B*树分配新结点的概率比 B+树要低,空间使用率更高
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于YOLOv7的学生课堂行为检测,引入BRA注意力和多种IoU改进提升检测能力
- 编程笔记 GOLANG基础 005 第一个程序:hello world
- uview1使用form表单设置required必填项,并更改星花的颜色
- 【已解决】C语言进行多线程数据切割查找数据
- MATLAB - 使用 YOLO 和基于 PCA 的目标检测,对 UR5e 的半结构化智能垃圾箱拣选进行 Gazebo 仿真
- Android 11.0 系统修改usb连接电脑mtp和PTP的显示名称
- LeetCode 297. 二叉树的序列化与反序列化
- CGAL的无限制的Delaunay图
- DINO:DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
- Pandas实践_文本数据