Checkpoint 执行机制原理解析
在介绍Checkpoint的执行机制前,我们需要了解一下state的存储,因为state是Checkpoint进行持久化备份的主要角色。Checkpoint作为Flink最基础也是最关键的容错机制,Checkpoint快照机制很好地保证了Flink应用从异常状态恢复后的数据准确性。同时 Checkpoint相关的metrics(指标)也是诊断Flink应用健康状态最为重要的指标,成功且耗时较短的Checkpoint表明作业运行状况良好,没有异常或反压。然而,由于Checkpoint与反压的耦合,反压反过来也会作用于Checkpoint,导致Checkpoint的种种问题。Flink在1.11引入Unaligned(未对齐)Checkpoint来解耦Checkpoint机制与反压机制,优化高反压情况下的Checkpoint表现。
Statebackend 的分类
下图阐释了目前Flink内置的三类state backend,其中MemoryStateBackend和FsStateBackend在运行时都是存储在java heap中的,只有在执行Checkpoint时,FsStateBackend才会将数据以文件格式持久化到远程存储上。 而RocksDBStateBackend则借用了 RocksDB(内存磁盘混合的LSM DB)对state进行存储。
[点击并拖拽以移动] ?
对于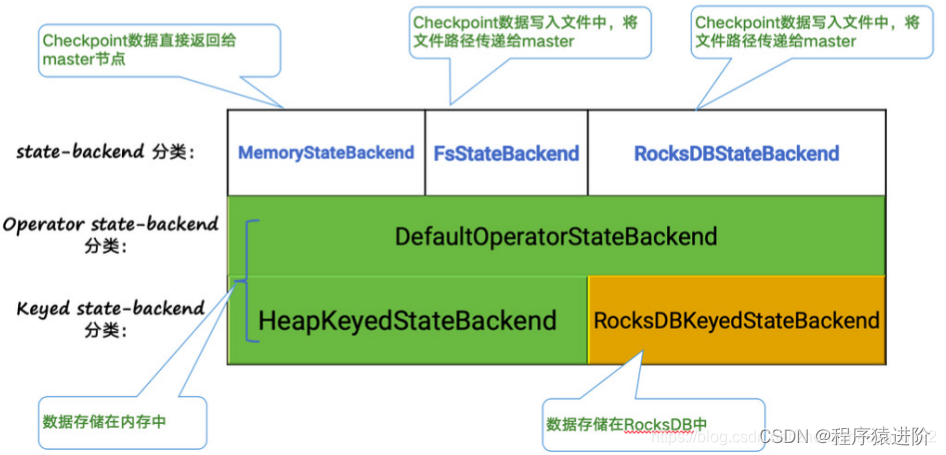
HeapKeyedStateBackend,有两种实现:
【1】支持异步Checkpoint(默认): 存储格式CopyOnWriteStateMap;
【2】仅支持同步Checkpoint: 存储格式NestedStateMap;
特别在MemoryStateBackend内使用HeapKeyedStateBackend时,Checkpoint序列化数据阶段默认有最大5 MB数据的限制。对于 RocksDBKeyedStateBackend,每个state都存储在一个单独的column family内,其中keyGroup,Key和Namespace进行序列化存储在 DB作为key。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/b13c307455064d85b08191575f84f00a.png)
Checkpoint 执行机制详解
对Checkpoint的执行流程逐步拆解进行讲解,下图左侧是Checkpoint Coordinator,是整个Checkpoint的发起者,中间是由两个 source,一个sink组成的Flink作业,最右侧的是持久化存储,在大部分用户场景中对应HDFS。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/8e0c78b8b3ca45998b724ccb6f9f26e6.png)
【1】Checkpoint Coordinator向所有source节点触发trigger Checkpoint;
【2】source节点向下游广播barrier(分界线),这个barrier就是实现Chandy-Lamport分布式快照算法的核心,下游的task只有收到所有input的barrier才会执行相应的Checkpoint。
Chandy-Lamport算法将分布式系统抽象成DAG(暂时不考虑有闭环的图),节点表示进程,边表示两个进程间通信的管道。分布式快照的目的是记录下整个系统的状态,即可以分为节点的状态(进程的状态)和边的状态(信道的状态,即传输中的数据)。因为系统状态是由输入的消息序列驱动变化的,我们可以将输入的消息序列分为多个较短的子序列,图的每个节点或边先后处理完某个子序列后,都会进入同一个稳定的全局统状态。利用这个特性,系统的进程和信道在子序列的边界点分别进行本地快照,即使各部分的快照时间点不同,最终也可以组合成一个有意义的全局快照。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/9ed1aef8c90743af877e5d9534c40d7c.png)
从实现上看,Flink通过在DAG数据源定时向数据流注入名为Barrier的特殊元素,将连续的数据流切分为多个有限序列,对应多个 Checkpoint周期。每当接收到Barrier,算子进行本地的Checkpoint快照,并在完成后异步上传本地快照,同时将Barrier以广播方式发送至下游。当某个Checkpoint的所有Barrier到达DAG末端且所有算子完成快照,则标志着全局快照的成功。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/5f0b9514ccad4d108e448ed070b98c16.png)
【3】当task完成state备份后,会将备份数据的地址state handle通知给Checkpoint coordinator。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/6b2bf7cfceaa47d2a3f120ec1024837f.png)
【4】下游的sink节点收集齐上游两个input的barrier之后,会执行本地快照,这里特地展示了RocksDB incremental(增量) Checkpoint的流程,首先RocksDB会全量刷数据到磁盘上(红色大三角表示),然后Flink框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/988ca160fe954f96a569716d97d59c90.png)
【5】同样的,sink节点在完成自己的Checkpoint之后,会将state handle返回通知Checkpoint Coordinator。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/c80156e58f5341158629699815a5014f.png)
【6】最后,当Checkpoint coordinator收集齐所有task的state handle,就认为这一次的Checkpoint全局完成了,向持久化存储中再备份一个Checkpoint meta文件。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/ff8adce1ad304e34b68b867631a5aa4d.png)
Checkpoint 的 EXACTLY_ONCE 语义
EXACTLY ONCE语义: 在有多个输入Channel的时候,为了数据准确性,算子会等待所有流的Barrier都到达之后才会开始本地的快照,这种机制被称为Barrier对齐。在对齐的过程中,算子只会继续处理的来自未出现Barrier Channel的数据,而其余Channel的数据会被写入输入队列(Flink通过一个input buffer将在对齐阶段收到的数据缓存起来),直至在队列满后被阻塞。当所有Barrier到达后(对齐),算子进行本地快照,输出 Barrier 到下游并恢复正常处理。
比起其他分布式快照,该算法的优势在于辅以Copy-On-Write技术的情况下不需要Stop The World影响应用吞吐量,同时基本不用持久化处理中的数据,只用保存进程的状态信息,大大减小了快照的大小。
AT LEAST ONCE语义: 无需缓存收集到的数据,会对后续直接处理,所以导致restore(恢复)时,数据可能会被多次处理。下图是官网文档里面就Checkpoint align的示意图:
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/533be4c6de764ba298223f9239a0dd22.png)
需要特别注意的是,Flink的Checkpoint机制只能保证Flink的计算过程可以做到EXACTLY ONCE,端到端的EXACTLY ONCE需要 source和sink支持。
Checkpoint 与反压的耦合
目前的Checkpoint算法在大多数情况下运行良好,然而当作业出现反压时,阻塞式的Barrier对齐反而会加剧作业的反压,甚至导致作业的不稳定。
首先, Chandy-Lamport分布式快照的结束依赖于Marker的流动,而反压则会限制Marker的流动,导致快照的完成时间变长甚至超时。无论是哪种情况,都会导致Checkpoint的时间点落后于实际数据流较多。这时作业的计算进度是没有被持久化的,处于一个比较脆弱的状态,如果作业出于异常被动重启或者被用户主动重启,作业会回滚丢失一定的进度。如果Checkpoint连续超时且没有很好的监控,回滚丢失的进度可能高达一天以上,对于实时业务这通常是不可接受的。更糟糕的是,回滚后的作业落后的Lag更大,通常带来更大的反压,形成一个恶性循环。
其次,Barrier对齐本身可能成为一个反压的源头,影响上游算子的效率,而这在某些情况下是不必要的。比如典型的情况是一个的作业读取多个Source,分别进行不同的聚合计算,然后将计算完的结果分别写入不同的Sink。通常来说,这些不同的Sink会复用公共的算子以减少重复计算,但并不希望不同Source间相互影响。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/2aa9665f2e284240b0904fbc209d06d1.png)
假设一个作业要分别统计A和B两个业务线的以天为粒度指标,同时还需要统计所有业务线以周为单位的指标,拓扑如上图所示。如果B业务线某天的业务量突涨,使得Checkpoint Barrier有延迟,那么会导致公用的Window Aggregate进行Barrier对齐,进而阻塞业务A的FlatMap,最终令业务A的计算也出现延迟。
当然这种情况可以通过拆分作业等方式优化,但难免引入更多开发维护成本,而且更重要的是这本来就符合Flink用户常规的开发思路,应该在框架内尽量减小出现用户意料之外的行为的可能性。
Unaligned Checkpoint
为了解决这个问题,Flink在1.11版本引入了Unaligned Checkpoint的特性。要理解Unaligned Checkpoint的原理,首先需要了解 Chandy-Lamport论文中对于Marker处理规则的描述:自行百度翻译
Marker-Sending Rule for a Process p. For each channel c, incident on, and
directed away from p:
p sends one marker along c after p records its state and before p sends further messages
along c.
Marker-Receiving Rule for a Process q. On receiving a marker along a channel
C:
if q has not recorded its state then
begin q records its state;
q records the state c as the empty sequence
end
else q records the state of c as the sequence of messages received along c after q’s state
was recorded and before q received the marker along c.
其中关键是if q has not recorded its state,也就是接收到Marker时算子是否已经进行过本地快照。一直以来Flink的Aligned Checkpoint通过Barrier对齐,将本地快照延迟至所有Barrier到达,因而这个条件是永真的,从而巧妙地避免了对算子输入队列的状态进行快照,但代价是比较不可控的 Checkpoint时长和吞吐量的降低 。实际上这和Chandy-Lamport算法是有一定出入的。举个例子,假设我们对两个数据流进行equal-join,输出匹配上的元素。按照Flink Aligned Checkpoint的方式,系统的状态变化如下(图中不同颜色的元素代表属于不同的Checkpoint周期):
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/cc9eef7c14a64e8494f8b3e97a72f1ac.png)
图 a: 输入Channel 1存在3个元素,其中2在Barrier前面;Channel 2存在4个元素,其中2、9、7在Barrier前面。
图 b: 算子分别读取Channel一个元素,输出2。随后接收到Channel 1的Barrier,停止处理Channel 1后续的数据,只处理 Channel 2的数据。
图 c: 算子再消费2个自Channel 2的元素,接收到Barrier,开始本地快照并输出Barrier。
对于相同的情况,Chandy-Lamport算法的状态变化如下:
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/b98e799641734d17aceaa7166c7837df.png)
图 a: 输入Channel 1存在3个元素,其中2在Barrier前面;Channel 2存在4个元素,其中2、9、7在Barrier前面。
图 b: 算子分别处理两个Channel一个元素,输出结果2。此后接收到Channel 1的Barrier,算子开始本地快照记录自己的状态,并输出Barrier。
图 c: 算子继续正常处理两个Channel的输入,输出9。特别的地方是Channel 2后续元素会被保存下来,直到Channel 2的 Barrier出现(即Channel 2的9和7)。保存的数据会作为Channel的状态成为快照的一部分。
两者的差异主要可以总结为两点:
快照的触发是在接收到第一个Barrier时还是在接收到最后一个Barrier时。
是否需要阻塞已经接收到Barrier的Channel的计算。
从这两点来看,新的 Unaligned Checkpoint将快照的触发改为第一个Barrier且取消阻塞Channel的计算 ,算法上与Chandy-Lamport基本一致,同时在实现细节方面结合Flink的定位做了几个改进。
首先,不同于 Chandy-Lamport模型的只需要考虑算子输入Channel的状态,Flink的算子有输入和输出两种Channel ,在快照时两者的状态都需要被考虑。其次,无论在Chandy-Lamport还是Flink Aligned Checkpoint算法中,Barrier都必须遵循其在数据流中的位置,算子需要等待Barrier被实际处理才开始快照。而Unaligned Checkpoint改变了这个设定,允许算子优先摄入并优先输出Barrier。如此一来,第一个到达Barrier会在算子的缓存数据队列(包括输入Channel和输出Channel)中往前跳跃一段距离,而被”插队”的数据和其他输入Channel在其Barrier之前的数据会被写入快照中。
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/55e3f4469cff4fde88dd743a45a74bd0.png)
这样的主要好处是,如果本身算子的处理就是瓶颈,Chandy-Lamport的Barrier仍会被阻塞,但Unaligned Checkpoint则可以在 Barrier进入输入Channel就马上开始快照。这可以从很大程度上加快Barrier流经整个DAG的速度,从而降低Checkpoint整体时长。回到之前的例子,用Unaligned Checkpoint来实现,状态变化如下:
![[点击并拖拽以移动] ?](https://img-blog.csdnimg.cn/direct/f36306f4249e4be9a7f818aab64786bf.png)
图 a: 输入Channel 1存在3个元素,其中2在Barrier前面;Channel 2存在4个元素,其中2、9、7在Barrier前面。输出 Channel已存在结果数据1。
图 b: 算子优先处理输入Channel 1的Barrier,开始本地快照记录自己的状态,并将Barrier插到输出Channel末端。
图 c: 算子继续正常处理两个Channel的输入,输出2、9。同时算子会将Barrier越过的数据(即输入Channel 1的2和输出 Channel的1)写入Checkpoint,并将输入Channel 2后续早于Barrier的数据(即 2、9、7)持续写入Checkpoint。
比起Aligned Checkpoint中不同Checkpoint周期的数据以算子快照为界限分隔得很清晰,Unaligned Checkpoint进行快照和输出Barrier时,部分本属于当前Checkpoint的输入数据还未计算(因此未反映到当前算子状态中),而部分属于当前Checkpoint的输出数据却落到Barrier之后(因此未反映到下游算子的状态中)。
这也正是 Unaligned的含义: 不同Checkpoint周期的数据没有对齐,包括不同输入Channel之间的不对齐,以及输入和输出间的不对齐。而这部分不对齐的数据会被快照记录下来,以在恢复状态时重放。换句话说,从Checkpoint恢复时,不对齐的数据并不能由Source端重放的数据计算得出,同时也没有反映到算子状态中,但因为它们会被Checkpoint恢复到对应Channel中,所以依然能提供只计算一次的准确结果。
当然,Unaligned Checkpoint并不是百分百优于Aligned Checkpoint,它会带来的已知问题就有:
【1】由于要持久化缓存数据,State Size会有比较大的增长,磁盘负载会加重。
【2】随着State Size增长,作业恢复时间可能增长,运维管理难度增加。
目前看来,Unaligned Checkpoint更适合容易产生高反压同时又比较重要的复杂作业。对于像数据ETL同步等简单作业,更轻量级的 Aligned Checkpoint显然是更好的选择。
总结:Flink 1.11的Unaligned Checkpoint主要解决在高反压情况下作业难以完成Checkpoint的问题,同时它以磁盘资源为代价,避免了Checkpoint可能带来的阻塞,有利于提升Flink的资源利用率。随着流计算的普及,未来的Flink应用大概会越来越复杂,在未来经过实战打磨完善后Unaligned Checkpoint很有可能会取代Aligned Checkpoint成为Flink的默认Checkpoint策略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue3的Uniapp用renderjs 进行视频切图操作
- ElasticSearch 文本分析
- openHarmony添加system_basic权限安装报错
- “智”绘出海新航道,亚马逊云科技携手涂鸦智能助力智能家居企业全球化
- linux系统官方yum源安装nginx和源码编译安装nginx
- 脆皮大学生“拯救”方案——智慧高校智能视频监控系统的建设
- 数据的存储
- 【unity学习笔记】2.脚本组件
- nodejs微信小程序+python+PHP的勤工俭学系统-计算机毕业设计推荐
- tauri build打包问题-- wix, nsis下载