FCN学习-----第一课
语义分割中的全卷积网络
CVPR IEEE国际计算机视觉与模式识别会议
PAMI IEEE模式分析与机器智能汇刊
需要会的知识点:
神经网络:前向传播和反向传播
卷积神经网络:CNN,卷积,池化,上采样
分类网络:VGG,net,AlexNet,GoogLeNet
Pytorch基础
必须学会:
熟练掌握语义分割常识知识:概念、术语、应用(0.5)
熟练掌握FCN算法模型:结构、意义、补充知识点(1天 )
熟练掌握FCN模型的代码定义:训练、验证、测试、预处理、模型定义、结果输出(4天)

第一课论文导读
1.论文研究背景、成果及意义
(1)语义分割是计算机视觉中的关键任务之一,现实中,越来越多的应用场景需要从影响中推理出相关的知识或者语义(由具体到抽象的过程)。作为计算机视觉的核心问题,语义分割对于场景理解的重要性日渐突出。
理解:把不同目标标记成不同颜色的过程。图像的语义可以理解为:图片表达的意思。
例如:图片中 一个人在骑一辆自行车 这就是语义。分割就是把图像当中所关心的对象用不同的颜色标记出来,达到分割的效果,也就是从具体到抽象的过程。

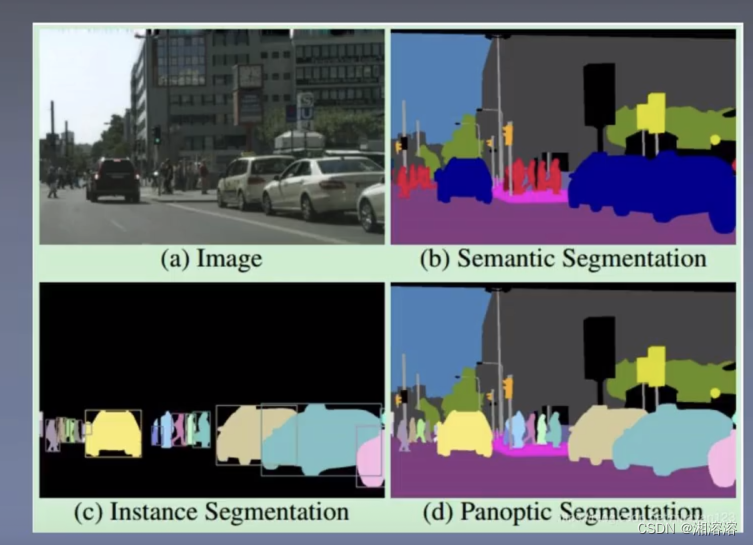
(2)语义分割、实例分割区别:
①不重要的东西成为背景,背景同一设置成黑色,例如在无人驾驶中,旁边的建筑物就是背景。
②在语义分割中同一种类都被分为一种颜色,而在实例分割中同种类也是不同颜色的。
全景分割:语义分割和实例分割的结合,不仅关注背景,在同种类中也要进行区分。
(3)语义分割的研究现状
①传统方法:归一化分割(纹理或者颜色相同进行分割)缺点是较慢需要多次进行分割,还不太准确;结构化的随机森林(很好改善噪点)缺点过拟合准确率不高慢;支持向量机

②深度学习卷积神经网络:FCN、SegNet、LinkNet

深度学习中还存在的问题:

(4)语义分割实现流程
训练:根据batch size大小,将数据集中的训练样本和标签读入卷积神经网络。根据实际需要,应先对训练图片及标签进行预处理,如裁剪、数据增强等。这有利于深层网络的训练,加速收敛过程,同时也避免过拟合问题并增强了模型的泛化能力。
验证:训练一个epoch结束后,将数据集中的验证样本和标签读入卷积神经网络,并载入训练权重。根据编写好的语义分割指标进行训练,得到当前训练过程中的指标分数,保存对应权重。常用一次训练一次验证的方法更好的监督模型表现。
测试:所有训练结束后,将数据集中的测试样本和标签读入卷积神经网络,并将保存的最好权重值载入模型,进行测试,测试结果分为两种,一种是根据常用指标分数衡量网络性能,另一种是将网络的预测结果以图片的形式保存下载,直观感受分割的精确程度。
FCN分割效果不算很好,但是分割的基石。

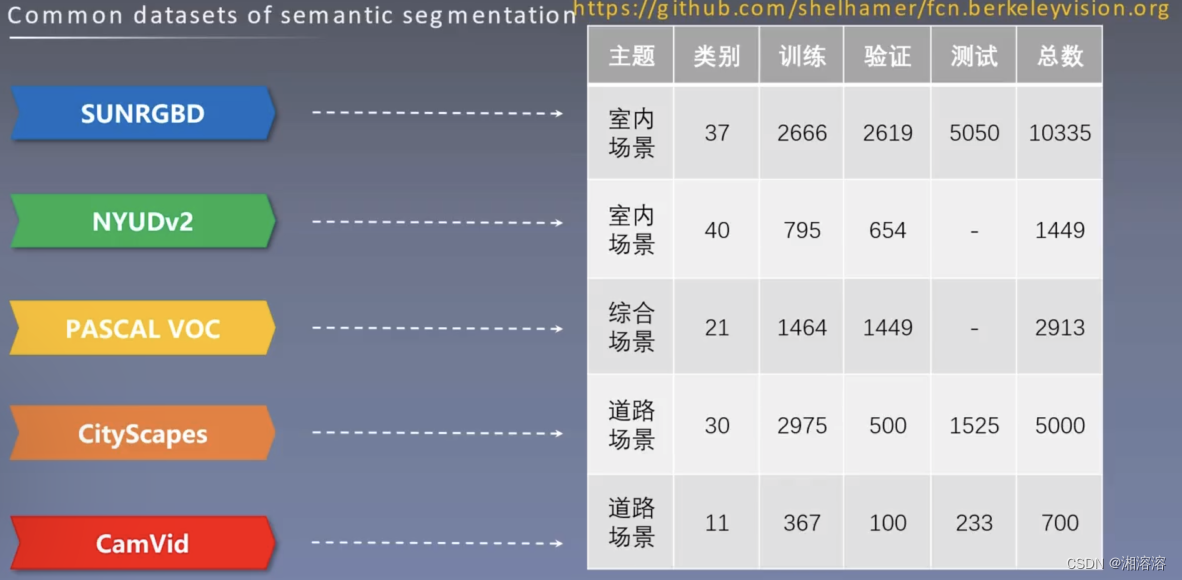
(5)语义分割常用数据集
(6)语义分割常用指标:指标越大越好
①PA像素精度:标记正确的像素占总像素的比例
②MPA均像素精度:计算每个类内被正确分类像素的比例
③MIoU均交并比:计算真实值和预测值的交集和并集

(7)FCN研究成果
①将分类网络改变为全卷积神经网络,具体包括全连接层转化为卷积层以及通过反卷积进行上采样。
②使用迁移学习的方法进行微调。
③使用跳跃结构使得语义信息可以和表征信息相结合,产生准确而精细的分割
④FCN证明了端到端、像素到像素训练方式下的卷积神经网络超过了现有语义分割方向最先进的技术(传统算法)。
⑤FCN成为了PASCAL VOC最出色的分割方法,较2011和2012分割算法的MIoU提高了将近20%

(8)FCN历史意义:
①深度学习应用在语义分割领域的开山之作
②端到端训练为后续语义分割算法的发展铺平了道路
与图分类或目标检测相比,语义分割使我们对图像有更加细致的了解。
2.论文泛读
(1)论文结构:

①概述卷积神经网络(大背景的概述):
Convolutional networks are powerful visual models that yield hierarchies of features.
卷积网络是强大的视觉模型,能够产生层次化的特征
②论点:
We show that convolutional networks by themselves, trained end-to-end, pixels to-pixels, exceed the state-of-the-art in semantic segmentation.
我们展示了卷积网络本身,端到端地训练,从像素到像素,超越了语义分割领域的最新技术水平。
③围绕论点采取的方法,主要的核心思想:(容纳不同尺寸的输入,得到相同尺寸的输出)
Our key insight is to build “fully convolutional” networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning.
我们的关键见解是构建“完全卷积”网络,它可以接受任意尺寸的输入,并生成相应尺寸的输出,具有高效的推断和学习能力。
④具体方法:如何实现核心思想(改变先前模型,做了迁移学习、跳跃连接)
We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations.
我们定义并详细介绍了完全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并与先前的模型进行了联系。我们将当代分类网络(如AlexNet、VGG网络和GoogLeNet)调整为完全卷积网络,并通过微调将它们学到的表示迁移到分割任务中。然后,我们定义了一个跳跃连接的架构,将来自深层次、粗糙层的语义信息与来自浅层、细致层的外观信息相结合,以生成准确且详细的分割结果。
⑤论文结果:(论文在数据集中的结果)
Our fully convolutional network achieves state of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes less than one fifth of a second for a typical image.
我们的完全卷积网络在PASCAL VOC(相对改进20%,在2012年的平均IU达到62.2%)以及NYUDv2和SIFT Flow数据集上实现了最先进的分割效果,同时对于一张典型图像的推断时间不到五分之一秒。

端到端

分割术语:
Pixel-wise(pixels-to-pixels):像素级别。
每张图片都是由一个个pixel组成的,pixel是像素图像的基本单位。
Image-wise:图像级别 比如一张图片的标签是狗,即“狗是对整个图片的标注
Patch-wise块级别,介于像素级别和图像级别之间,每个patch都是由好多个pixel组成的
Patchwise training:针对每个感兴趣的像素,以它为中心取一个patch(小块),然后输入网络,输出则为该像素的标签。
**
3.本课回顾及下节预告
**
(1)语义分割的概念 (2)FCN取得的成果及意义 (3)FCN论文总览 (4)摘要精度
下节课:①引言及相关工作:追溯FCN的思想源头,回顾FCN出现之前的语义分割方法
②先验知识补充:根据论文第三节的顺序,补充相关知识点 ③详解算法结构:按照论文给出的逻辑细致讲解算法构成 ④实验及结论:分析实验细节,总结论文创新点。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 监测服务器硬件设备运行状况的软件 - wgcloud
- 仿hao123导航网源码,网址加色导航网址系统源码 ,附带系统搭建教程
- PHP短链接url还原成长链接
- 拓展操作(一) Linux 2台机器之间进行免密登录
- springboot整合thymeleaf
- Ref和类型断言
- 树莓派ubuntu22桌面配置(一)
- 数据结构Java版(3)——队列Queue
- VPN的简介以及在ENSP中的基础配置
- Hugging Face Datasets文本质量分析,识别低质量内容、垃圾数据、偏见内容、识别毒性内容、检测重复文档、识别测试集污染数据、识别过短的内容