分布式系统——广播Broadcasts
1?广播抽象(Broadcast Abstractions)在进程中的两种方法
????????在分布式系统中广播抽象的概念。广播抽象允许系统中的进程使用两种基本方法进行通信:
1.1 Broadcast(m)????????
????????当一个进程 i 使用这个方法时,它会将消息 m 发送给系统中的所有其它进程。
1.2?Deliver(m,src)
????????这个方法会将广播的消息 m 递送给关联的应用程序(associated application)。
????????Deliver(m,src)?方法在分布式系统中的广播抽象里面非常关键。这个方法的作用是接收消息,确保从其他进程广播来的消息能被正确地传递给这个进程的应用程序层。这里的 m?表示接收到的消息内容,src?表示消息的来源,也就是哪个进程发送了这个消息。
1.3 总结
????????在分布式系统的上下文中,Deliver?方法通常由底层的网络层实现,它确保消息能够跨越网络从一个节点传递到另一个节点。当一个进程调用 Broadcast(m)?方法广播消息时,系统会尝试将这个消息传递给所有其他的进程。每当这个消息到达一个进程,就会调用 Deliver(m,src)?方法,以便应用程序可以处理这个消息。
????????例如,在一个聊天应用中,当一个用户发送一条消息时(即调用 Broadcast),这条消息将被发送到服务器,然后服务器将消息分发(Deliver)给所有在线的客户端,这样每个客户端的应用程序就可以显示这条新消息。
????????总的来说,Deliver(m,src) 方法是确保消息在进程间正确传递和接收的机制,它是分布式系统中实现通信和协调的基础。
2.?进程的基本和高级模块
2.1 基本模块包括
????????应用层(Applications)
????????广播层(Broadcast)
????????通道层(Channels)
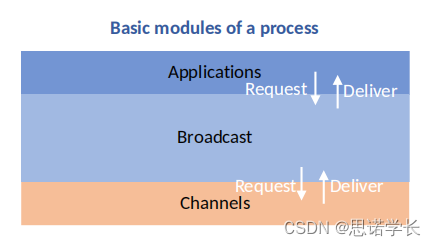
????????在这个模型中,应用层会向广播层发出请求,广播层再通过通道层进行消息的传递。
2.2 高级模块包括
????????应用层(Applications)
????????广播层(Broadcast)
????????故障检测器(Failure detector)
????????通道层(Channels)
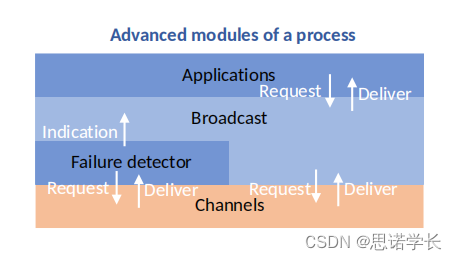
????????在高级模块的架构中,除了基本的广播和通道层之外,还增加了故障检测器,它用于指示可能出现的问题。这个模块可以帮助系统识别和处理进程故障的情况。
????????这两个模块展示了从简单到复杂的进程通信方式,以及系统如何对内部和外部的请求做出响应。高级模块通过包含故障检测器,提供了更复杂的处理机制,能够处理进程间的故障情况,确保系统的鲁棒性。
3 广播抽象的规范
3.1 最大努力广播(Best Effort Broadcast)
3.1.1 例1
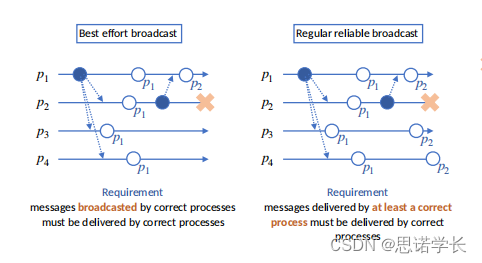
????????最大努力广播:当一个进程(如图中的 P1)广播一个消息(m)时,系统会尽最大努力将这个消息传递给所有其它的进程(P2、P3、P4)。这里的“最大努力”意味着系统不保证所有进程都会接收到消息,特别是在出现进程崩溃(Crash)的情况下。

图中的符号表示如下:
????????实心圆点代表一个进程执行广播操作,即 Broadcast(m)。
????????空心圆点加 P1 表示其他进程接收(Deliver)了由进程 P1 发出的消息。
????????叉号代表进程崩溃。
????????在这个示例中,要求是由正确的进程广播出去的消息必须被其他正确的进程接收。这里的“正确的进程”指的是没有发生故障的进程。
????????在实际的分布式系统中,这种广播通常用于不需要严格一致性保证的情况,比如某些类型的信息传播或者服务发现。如果系统中的一个进程崩溃了,它可能无法接收到消息,但是这种机制并不保证消息一定会被重新发送或者系统会进行恢复操作。这就是为什么这种广播被称为“最大努力”的原因。
3.1.2?例2

????????在提供的图像中,我们看到了最大努力广播的一个示例。最大努力广播的要求是,如果一个正确的进程(未发生故障的进程)广播了消息,那么所有其他正确的进程都必须接收这条消息。
在这个图像中:
- ????????进程 P1 尝试广播消息 m。
- ????????然后进程 P1 崩溃了(表示为叉号)。
- ????????尽管 P1 崩溃,消息 m 仍被 P2 投递(表示为 P2 接收了消息 m)。
????????问题是,这种执行是否满足最大努力广播的要求。答案取决于 P1 在崩溃前是否能将消息 m 广播出去。如果 P1 成功广播了消息 m,并且 P2、P3 和 P4 都是正确的进程,那么根据最大努力广播的定义,它们都应该接收消息 m。然而,如果 P1 在成功广播消息之前崩溃了,那么就不能保证所有其他进程都会接收消息 m。
????????从图中可以看出,P1 似乎在崩溃后,消息 m 被 P2 接收了。这可能表明 P1 已经成功地向至少 P2 广播了消息 m。但是,没有足够的信息来判断 P3 和 P4 是否也已经接收了消息 m。如果 P2、P3 和 P4 最终都接收了消息 m,则此执行满足最大努力广播的要求;如果有任何正确的进程没有接收到消息 m,则不满足。
3.1.3?例3

根据图像分析:
- ????????进程 P1 广播了消息 m。
- ????????进程 P2 收到了消息 m,并准备向其他进程转发消息。
- ????????进程 P3 和 P4 在收到消息前崩溃了。
????????最大努力广播的核心要求是,一个正确的进程(没有发生故障的进程)广播的消息必须被所有其他正确的进程接收。在这个场景中,只有进程 P2 是能够接收消息的正确进程。由于进程 P3 和 P4 已经崩溃,它们无法接收消息。
????????所以,根据最大努力广播的定义,只要进程 P2 接收了消息 m,这个场景就满足了最大努力广播的要求。这是因为在消息 m 被广播时,P2 是唯一能够接收消息的正确进程,而已崩溃的进程不在此要求的考虑范围内。因此,尽管 P3 和 P4 崩溃了,这个执行过程仍然满足了最大努力广播的要求,因为正确的进程(在这个例子中是 P2)接收了消息。
3.2?常规可靠广播
3.2.1?例1
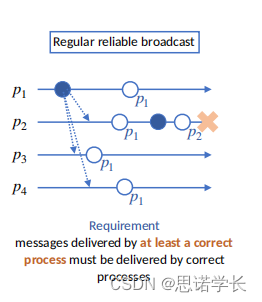
????????右图展示的是 常规可靠广播 (Regular Reliable Broadcast)的一个场景。这里有四个进程:P1, P2, P3, 和 P4。在这种类型的广播中,一旦至少有一个正确的进程接收并投递了消息,其他所有正确的进程也都必须接收并投递这个消息。
????????在分布式系统中,“投递消息”(Deliver a message)是指一个进程在接收到消息后,将其传递到应用程序或上层服务的动作。换句话说,就是当一个进程从网络中接收到一条消息时,并不是仅仅在网络层面上认为已经收到,而是需要进一步的操作,确保这个消息被进程识别并按照程序逻辑进行处理。这个处理过程可能包括更新数据、响应请求或触发其他事件。
????????在右图中,我们看到了一个常规可靠广播过程的示例。这个过程确保了一旦一个正确的进程接收并投递了消息,所有其他正确的进程也必须投递该消息。这里是该过程的具体步骤:
????????a. 广播消息:进程 P1 作为源节点,它开始了广播过程,发送消息 m 到它的所有邻居。
????????b. 消息传递:当进程 P2 接收到消息 m 时,它将消息 m 投递给自己,并且向它的邻居(这里是 P3)转发消息 m。
????????c. 节点崩溃:在图中,进程 P2 在完成消息 m 的投递和转发后崩溃了(表示为一个叉号)。常规可靠广播保证即使 P2 崩溃,其他进程仍然能够接收到消息 m。
????????d. 保证消息传递:进程 P3 接收到 P2 转发的消息 m 并投递给自己。由于常规可靠广播的要求,P3 知道必须将消息 m 继续转发下去,即使它的上游节点 P2 已经崩溃。
????????e. 完成广播:最终,所有正确的进程(这里的 P3 和 P4)都会投递消息 m。即使源节点的直接邻居(P2)崩溃了,消息也会通过其他路径到达所有正确的进程。
????????在这个过程中,“Deliver”操作表示进程接收和处理了消息,而“Broadcast”操作表示进程向它的邻居发送消息。这个例子展示了即使在面对进程崩溃的情况下,常规可靠广播如何确保消息传递的完整性和系统的一致性。
????????根据常规可靠广播的要求,一旦至少有一个正确的进程投递了某个消息,所有其他的正确进程也必须投递该消息。在这个例子中,P2 在崩溃前已经投递了消息,因此按照定义,P3 和 P4(如果它们是正确的进程)也必须最终投递消息 m。这个图示中没有显示 P3 和 P4 是否处理了消息,但是根据要求,它们都应该处理消息。
????????总结一下,常规可靠广播强调的是消息的可靠投递:只要有一个正确的进程投递了消息,所有其他的正确进程也都保证会投递这个消息,即使有进程在之后崩溃。这个属性对于确保分布式系统中的一致性和可靠性是非常重要的。
3.2.2?例2
3.3?最大努力广播 VS?常规可靠广播
????????最大努力广播只保证消息会被尽可能多的正确进程接收,但如果进程在消息传递后崩溃,那么这个消息可能不会被所有正确的进程接收。
????????常规可靠广播增加了一项更强的保证,即如果任何一个正确的进程接收并处理了消息,那么所有其他正确的进程也都必须接收并处理这个消息。
3.4?统一可靠广播(Uniform Reliable Broadcast)
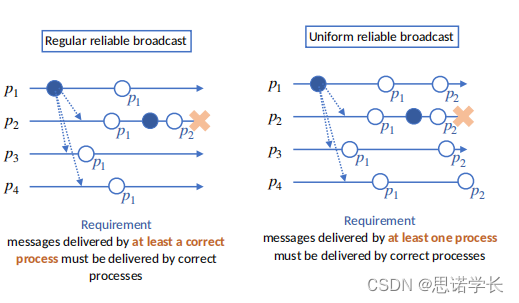
? ? ? ?本图展示了“统一可靠广播”(Uniform Reliable Broadcast)的概念。在统一可靠广播中,有一个强有力的保证,即如果任何一个进程(即使是将要发生故障的进程)成功投递了消息,那么所有其他正确的进程(没有发生故障的进程)也必须投递该消息。
图中描述的场景如下:
????????进程 P1 广播了消息 m。
????????进程 P2 和 P3 成功接收并投递了这个消息,这在图中表示为它们各自的圈圈。
????????然后,进程 P2 在进程 P4 投递消息之前发生了崩溃(显示为叉号)。
????????根据统一可靠广播的要求,即使进程 P2 发生了崩溃,所有其他的正确进程(如 P3 和 P4)都必须保证能够投递消息 m。这意味着,不论 P2 的状态如何,只要消息已经被 P2 投递,P3 和 P4 都应当最终接收并处理这条消息。
????????这种广播抽象级别在分布式系统中尤其重要,因为它提供了即使在面对进程故障时,也能确保所有存活的进程之间消息一致性的强保证。这通常需要通过复杂的协议来实现,如通过重试机制、故障检测和消息确认等手段确保消息能够被所有正确的进程所接收。
3.5 结论
这三个术语描述了不同级别的广播保证,它们在分布式系统中用于定义消息如何在进程间传递。让我们分别解释每一个:
1. 最大努力广播(Best Effort Broadcast):
????????此类广播确保如果一个正确的进程(未崩溃的进程)广播了一条消息,那么所有其他正确的进程都必须接收这条消息。
????????它不保证如果一个进程崩溃了,消息仍然会被传递。
????????这是基本的广播层,没有考虑节点故障的情况。
2. 常规可靠广播(Regular Reliable Broadcast):
????????如果至少有一个正确的进程投递了一条消息,那么所有其他正确的进程也必须投递这条消息。
????????这提供了比最大努力广播更强的保证,确保消息的可靠性,即使有进程在传递过程中崩溃。
????????这是在可能会有节点故障的环境中常用的一个更可靠的广播。
3. 统一可靠广播(Uniform Reliable Broadcast):
????????即使消息由将要崩溃的进程投递,只要消息被至少一个进程(无论其状态如何)投递,那么所有正确的进程都必须投递这条消息。
????????这是最强的保证,它确保所有正确的进程都有一个统一的消息视图,即使有进程崩溃。
????????这对于维护系统一致性在面对不确定的节点故障时是非常重要的。
简而言之,这三个术语从最基本的广播保证(最大努力广播)到最强的广播保证(统一可靠广播)提供了不同级别的消息传递可靠性。随着保证的增强,系统能够更好地处理节点崩溃和其他类型的故障。
4?广播机制的使用场景
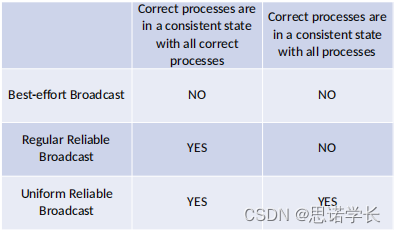
在您提供的图表中,展示了三种广播机制(最大努力广播、常规可靠广播和统一可靠广播)何时使用以及它们是否保证正确进程的一致状态。这里的“正确的进程”指的是没有失败的进程。
4.1?最大努力广播(Best-effort Broadcast):
????????正确的进程不一定与所有其他正确的进程保持一致状态。
????????此类广播适用于容错要求不高的应用,如非关键的信息传递和某些类型的服务发现。
4.2?常规可靠广播(Regular Reliable Broadcast):
????????正确的进程与所有其他正确的进程保持一致状态。
????????但正确的进程不一定与已崩溃的进程保持一致状态。
????????适用于需要高度一致性但可以容忍部分失效的场景,如分布式数据库的同步操作。
4.3?统一可靠广播(Uniform Reliable Broadcast):
????????正确的进程与所有其他进程(无论它们是否崩溃)保持一致状态。
????????这是最强的一致性保证,适用于即使在面对任意数量的进程崩溃时也需要维护一致性的关键应用,如金融服务中的交易系统、航空交通控制系统等,这些系统中信息的一致性对于系统的安全和可靠运行至关重要。
5 实例讲解
5.1 实例1:事件驱动编程
????????事件驱动编程是一种编程范式,在这种范式中,程序的流程是由事件如用户操作、传感器输出或消息传递等来决定的。在分布式系统中,事件驱动编程经常用于组件间的交互和消息通信。
????????在您描述的场景中,组件通过事件进行交互,事件包含了属性,事件处理由事件处理器(Event Handlers)负责。
这里的代码伪代码:
On event <coi Event1, attr1, attr2,...> do?
// local computation
trigger <coj Event2, attr3, attr4,...>?????????这表示当事件Event1发生时,事件处理器将执行一些本地计算,并可能触发另一个事件 Event2。
????????代码中定义了如何在节点之间传递消息。这个模块提供了两种类型的交互:
5.1.1?Request
????????用于请求消息 m 发送到目标节点 dest。
????????语法是 〈pp2p, Send | dest, m〉,表示组件通过完美点对点链接(PerfectPointToPointLink)实例 pp2p 发送消息。
5.1.2?Indication
????????用于指示由源节点 src 发送的消息 m 已经到达。
????????语法是 〈pp2p, Deliver | src, m〉,表示组件通过 pp2p 实例收到了消息。
????????"PerfectPointToPointLink"这个名字表示了这个模块保证了消息的可靠传递,即消息一定会被成功送达,不会丢失、重复或乱序。这通常意味着底层传输机制提供了确认和重传机制以确保每个发送的消息最终都会准确无误地到达目的地。
????????在分布式系统的设计中,这样的模块对于构建可靠的通信协议是非常重要的,它们使得上层的应用逻辑可以假定通信是可靠的,并专注于实现业务逻辑。
5.2?实例2:最大努力广播

????????此实例是最大努力广播(Best Effort Broadcast)算法的伪代码以及它的属性。这种广播在分布式系统中用来尽可能确保消息从一个进程传递到其他进程。在算法中有以下几个关键点:
5.2.1?算法使用
????????它实现了基本的广播机制,并使用了完美点对点链接(PerfectPointToPointLinks)的实例,称为 `pp2p`。
5.2.2?广播事件
????????当进程希望广播消息时,它触发 `beb.Broadcast` 事件。对于所有的其他进程 q,它将通过 pp2p?发送消息 m。
5.2.3 投递事件
????????当 pp2p?实例从进程 p?接收到消息 m?时,它将触发 beb.Deliver?事件,表示消息已经被本地投递。

此算法还提供了三个属性保证:
????????BEB1. Validity:如果进程 ?和
?都是正确的,那么由
?广播的每个消息最终都会被
?投递。
????????BEB2. No duplication:没有消息会被投递多于一次。
????????BEB3. No creation:除非消息被广播,否则不会有消息被投递。
????????这些属性确保了广播的基本可靠性,即消息不会被无故创造或重复,而且如果进程是正确的,则它们最终会接收到广播的消息。
????????下图展示了最大努力广播在实际应用程序中如何工作。应用程序通过广播层发送和接收消息,广播层与通道层交互来处理网络消息。这个模型展示了应用层和网络层之间的分离,允许开发者编写高层的应用程序逻辑,而不必关心底层的网络通信细节。

5.3?实例3:懒惰可靠广播(Lazy Reliable Broadcast)

????????这是懒惰可靠广播(Lazy Reliable Broadcast)算法的描述,以及这种算法在可靠广播中如何与完美故障检测器和最大努力广播配合使用。
5.3.1 算法概述
????????实现:算法实现了一个可靠的广播机制,称为 rb。
????????使用:它依赖于最大努力广播(beb)和完美故障检测器(P)的实例。
5.3.2 算法的主要步骤
????????初始化:在初始化时,delivered?集合和 correct?集合被设置为空,而 from?数组(用于跟踪每个进程接收的消息)被设置为对于每个进程都是空集。
????????广播消息:当一个进程想要广播消息 m?时,它触发了最大努力广播的 Broadcast?事件,消息被封装在一个带有 DATA?标签的容器中,以及发送者的标识。
????????接收消息:当一个进程通过 beb?接收到消息时,如果这个消息之前没有被收到,它就会触发可靠广播的 Deliver?事件,并将消息添加到 from?集合中。如果消息的发送者不在 correct?集合中,意味着发送者可能已经崩溃,因此它重新触发 beb.Broadcast?事件来确保其他进程也能接收到这个消息。
????????处理崩溃:当检测到一个进程崩溃时,如果有任何消息是从该崩溃进程接收的,那么这些消息会被再次广播出去,以确保所有正确的进程都能收到这些消息。
5.3.3 算法的属性
????????需要一个完美的故障检测器来检测和广播崩溃信息。
????????使用最大努力广播来广播消息。
????????当通过 beb.Deliver?接收到消息时,保存消息并触发 rb.Deliver?消息。
????????如果发送者崩溃,检测并从发送者那里接收到的消息会被重新广播给所有人。
????????消息在投递前会被检查是否重复,以确保不会多次投递相同的消息。
????????这个算法的关键在于它对故障的处理:即使消息的原始发送者崩溃,通过重新广播接收到的消息,算法也能保证所有正确的进程最终都会接收到这些消息。这种“懒惰”的方法意味着只有在检测到发送者崩溃的情况下才重新广播消息,这可以减少不必要的网络流量,因为在没有检测到崩溃的情况下不会重新广播消息。
5.3.4 属性
????????RB1. Validity:如果进程 和 `pj` 是正确的(即没有发生故障),那么由 `pi` 广播的每个消息最终都会被 `pj` 投递。这意味着系统确保所有正确的进程都能够接收到由其他正确进程发送的消息。
????????RB2. No duplication:任何消息不会被一个进程投递超过一次。这防止了同一消息的多次投递可能导致的混乱或重复处理。
????????RB3. No creation:除非一条消息被广播了,否则它不会被任何进程投递。这保证了系统不会自发地产生不存在的消息,从而避免了错误信息的传播。
????????RB4. Agreement:对于任何消息m,如果一个正确的进程投递了 `m`,那么每一个正确的进程都会投递 `m`。这是一个关于一致性的强保证,它确保了一旦某个消息被某个正确的进程接收,所有其他正确的进程也都将最终接收并处理这个消息。
????????这些属性一起定义了一个可靠的广播系统,确保了消息的正确传递和系统的一致性。在分布式系统中,这些属性是非常重要的,它们保证了即使在有进程可能会发生故障的环境中,系统的通信也能正确无误地进行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Tomcat调优Service
- 手把手写深度学习(1):WebVid-10M数据清洗之文字/水印检测清洗-复现Stable Video Diffusion论文
- BUUCTF--hitcontraining_heapcreator1
- C语言汇总(持续更新)
- 安卓微信聊天记录的解密
- JavaScript 获取当前日期时间 年月日 时分秒的方法
- Jmeter 性能 —— 阶梯式性能指标监听
- JVM工作原理与实战(八):类加载器的分类
- 20240102_AIO-3399J的开发板刷Firefly的官方Andorid10使用EC20的模块不能上网!
- mybatis-plus雪花算法自动生成ID到前端后精度丢失问题