YOLOv7基础 | 手把手教你如何去训练明火烟雾算法模型

前言:Hello大家好,我是小哥谈。数据标注完成之后,本节课就带领大家如何基于YOLOv7来训练自己的目标检测模型,此次作者就以明火烟雾检测为例子进行说明,让大家可以轻松了解整个模型训练及测试过程!~🌈?
? ? ?目录

🚀1.算法介绍
YOLOv7是一种目标检测算法,它是YOLO系列中最先进的算法之一。YOLO(You Only Look Once)算法是一种one-stage目标检测算法,它基于深度神经网络进行对象的识别和定位,并具有实时性能。
YOLOv7在准确率和速度上超越了以往的YOLO系列算法。它引入了一些新的技术和策略,包括模型重参数化、标签分配策略、ELAN高效网络架构和带辅助头的训练。
模型重参数化是指将重参数化思想应用于网络架构中,这个思想最早出现于REPVGG中。标签分配策略采用了YOLOv5的跨网格搜索和YOLOx的匹配策略。ELAN高效网络架构是YOLOv7提出的一个新的网络架构,以高效为主。带辅助头的训练是YOLOv7提出的一种训练方法,通过增加训练成本来提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中。
总结来说,YOLOv7是一种先进的目标检测算法,它在准确率和速度上都有很好的表现,并引入了一些新的技术和策略来提升性能。?

说明:??????
YOLOv7网络架构图引自文章:《YOLOV7详细解读(一)网络架构解读》 ,作者:江小皮不皮
关于更清晰的YOLOv7网络架构图请参考本作者后续文章。作者目前正在绘制中......🍉 🍓 🍑 🍈 🍌 🍐
说明:??????
YOLOv7源码官方网站:GitCode - 开发者的代码家园?
在官网下载后发现存在部分问题,作者已解决,并将含有权重文件的YOLOv7源码进行了上传,大家可自行下载。?
🚀2.数据标注
利用labelimg或者make sense软件来标注数据,关于如何使用labelimg或者make sense软件来为自己的数据集打上标签,请参考作者专栏文章:

说明:??????
数据标注工具的使用教程:
🚀3.模型训练
第1步:准备数据集
将数据集放在datasets文件夹中。datasets属于放置数据集的地方,位于PycharmProjects中,C:\Users\Lenovo\PycharmProjects中(这是我的电脑位置,跟你的不一定一样,反正位于PycharmProjects中),属于项目的同级文件夹。具体如下图所示:

打开datasets文件夹,可以看到本次明火烟雾算法模型训练所使用的数据集。

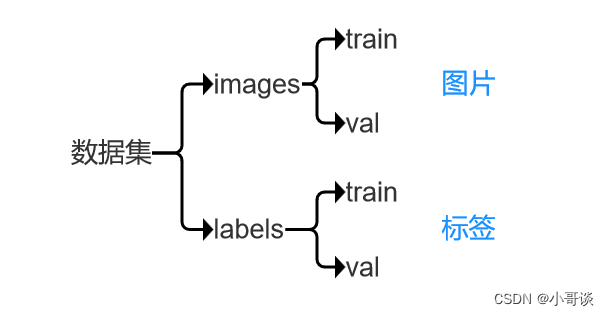
打开数据集文件,我们会看到数据集文件包括images和labels两个文件夹,其中,images放的是数据集图片,包括train和val两个文件夹,labels放的是经过labelimg标注所生成的标签,也包括train和val两个文件夹。

关于此处数据集的逻辑关系,用一张图总结就是:??????
第2步:创建yaml文件
打开pycharm,选择YOLOv7项目源码文件,在data文件夹里新建一个fire_smoke.yaml,如下图所示:

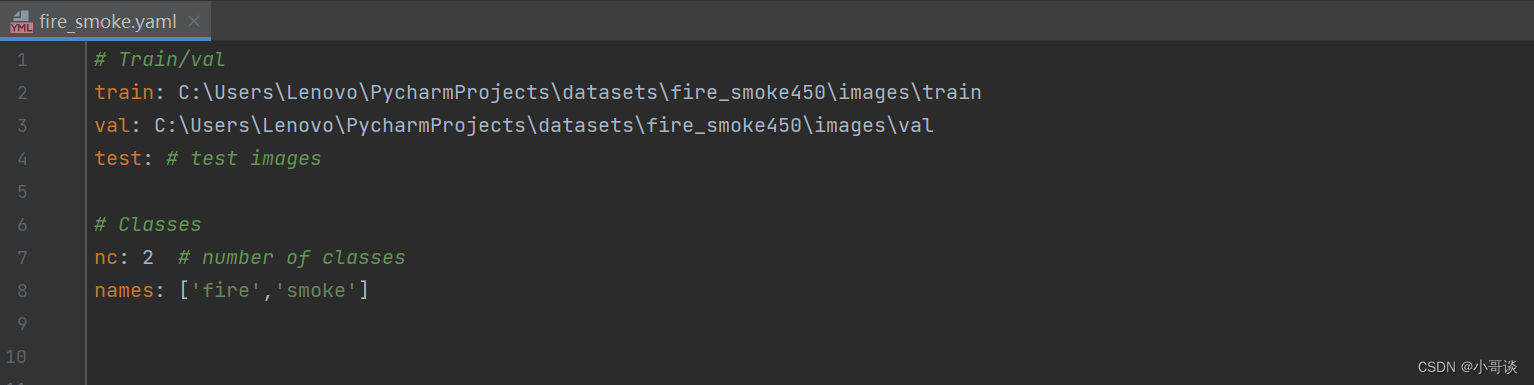
打开fire_smoke.yaml,按照如下图所示的进行配置:
说明:??????
1.train和val为绝对路径地址,可根据自己数据集的路径地址自行设置。
2.nc指的是分类,即模型训练结果分类,此处为在用labelimg或者make sense为数据集标注时候确定。
3.由于本次进行的是明火烟雾算法模型训练,所以分两类,分别是:fire(火)和smoke(烟雾)
?第3步:路径配置
在项目里找到train.py?,在--cfg加入yolov7.yaml的路径地址,在--data这里放上fire_smoke.yaml的路径,具体如下图所示:

说明:??????
weights为权重文件路径地址,下载本作者所上传源码的时候可以看到。
?第4步:调节参数

- 将epochs中的参数设置为100,表示需经过100轮训练。
- batch-size表示一次训练所抓取的数据样本数量,其大小影响训练速度和模型优化,此处将其参数设置为8。
第5步:开始训练
当参数调节完毕之后,即可点击“运行”。具体运行结果如下图所示:
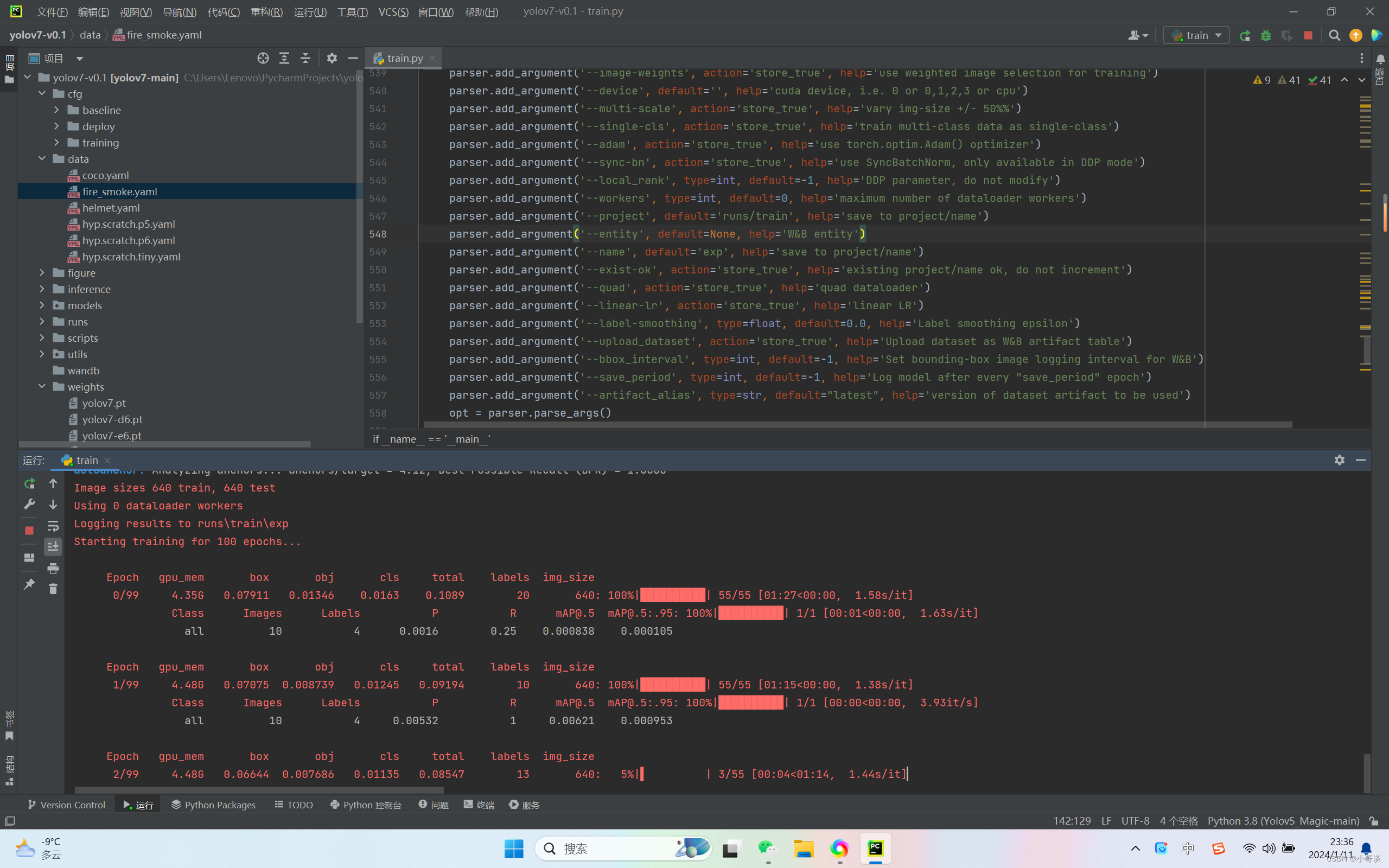

训练结束后,训练结果如下所示:

第6步:评估指标
模型评估指标主要包括精度P(precision)、召回率R(recall)和平均精度均值(mAP)。精确率表示预测结果中预测为正的样本中有多少是真正的正样本的比率,召回率表示原始样本中的正例有多少被预测正确的比率,mAP即所有类别的平均精度求和除以数据集中所有类的平均精度。在本次训练过程中,TP、FP和FN分别表示正确检测框、误检框和漏检框的数量:

🚀4.模型测试
模型训练完成之后,训练结果会保存在run/train文件夹中。
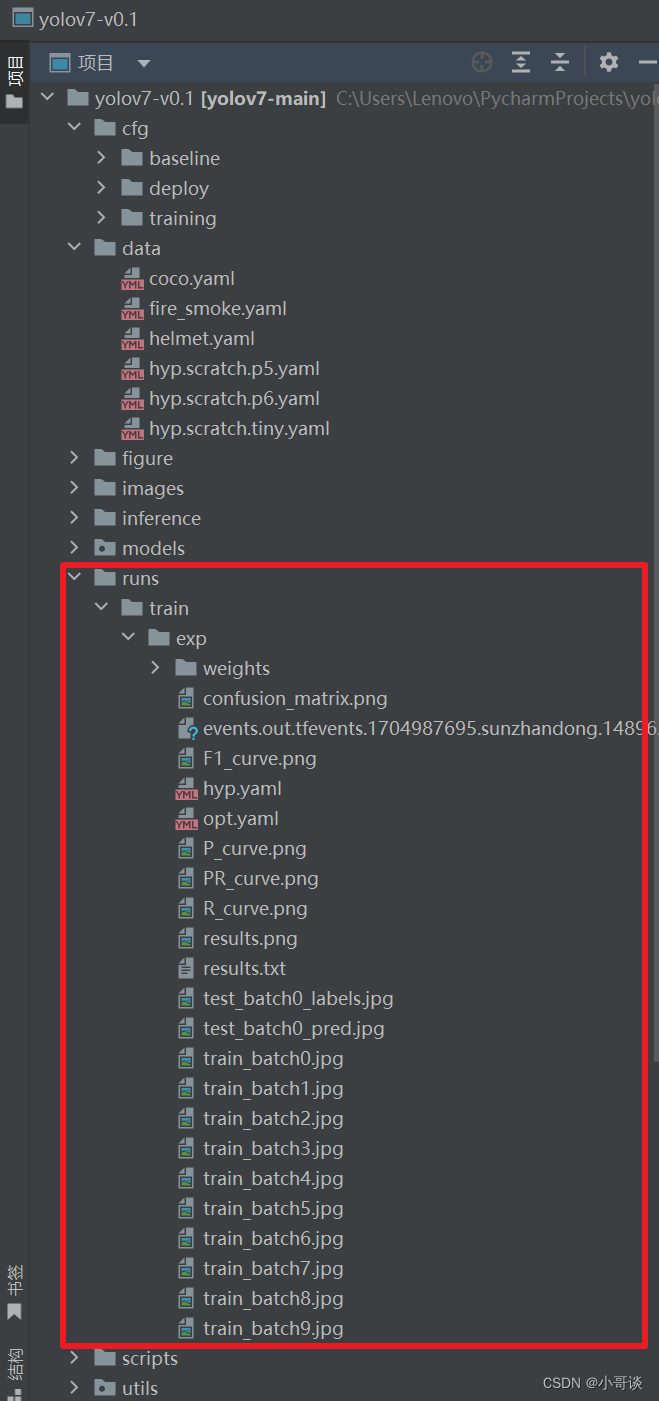
找到detect.py?,将这里的权重路径换成我们刚刚训练好的那个模型的路径?(即best.pt的绝对路径)
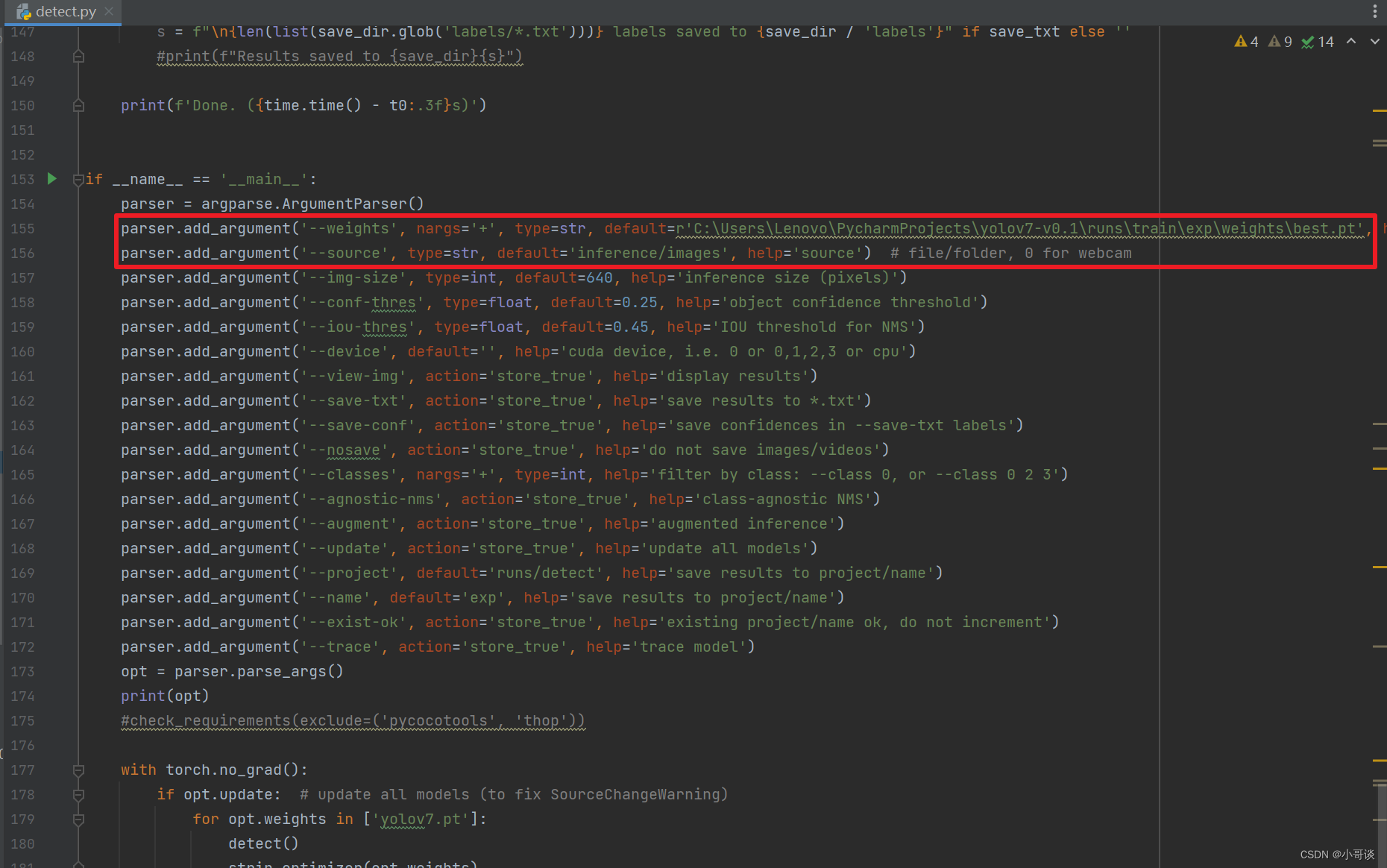
接着然后找到inference/images文件夹,在这个文件夹中放上我们想检测的图片。?
放完后我们就可以执行detece.py了,执行后会打印出检测后图片的路径,我们直接打开就可以看到了。?
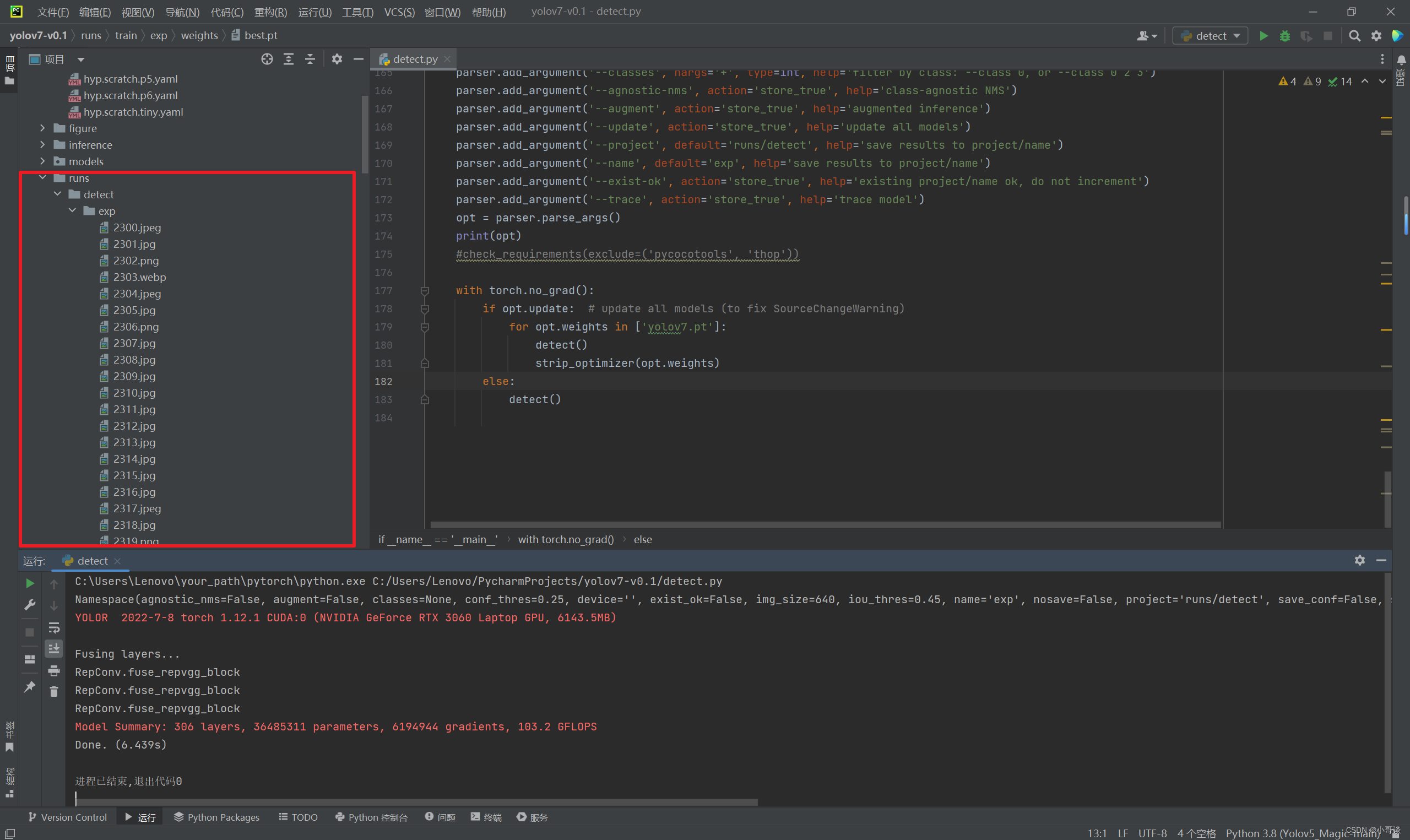
测试结果:






本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JUC CAS 和 原子操作类
- Docker与微服务实战(基础篇)
- 【应用方案】基于MT7628 JN5169 和SUN724的4G-Zigbee智能网关方案
- 【STK】手把手教你利用STK进行关联分析仿真01-STK/CAT模块介绍
- 第32次CCF计算机软件能力认证-第二题
- STM32项目设计:智能门禁系统核心板版本 4种解锁方式
- 「小明赠书活动」2024第一期《TVM编译器原理与实践》
- R包免费分享 | 你还为下载R包烦恼吗??
- ReactNative进阶(五十三)ios组包报错getaddrinfo ENOTFOUND static.realm.io问题修复
- 函数递归(Recursion)一篇便懂