pytorch12:GPU加速模型训练

目录
1、CPU与GPU
CPU(Central Processing Unit, 中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器):处理统一的,无依赖的大规模数据运算
cpu的控制单元和存储单元要比GPU多,比如我们加载的数据缓存一般都在cpu当中,GPU的计算单元到比cpu多,在算力方面要远远超过cpu
注意:运算的数据必须在同一个处理器上,如果一个数据在cpu一个在gpu上,则两个数据无法进行相关的数学运算。

2、数据迁移至GPU
如果想要将数据进行处理器迁移,所使用的工具是to函数,并在中间选择想要迁移的处理器类型。
data一般有两种数据类型:tensor、module。

2.1 to函数使用方法
to函数:转换数据类型/设备
- tensor.to(args, kwargs)
- module.to(args, kwargs)
区别: 张量不执行inplace,要构建一个新的张量,模型执行inplace,不需要等号赋值。
inplace操作:"inplace"操作是指对数据进行原地修改的操作,即直接在原始数据上进行更改,而不是创建一个新的副本。在深度学习框架中,许多函数和方法都支持"inplace"操作,这意味着它们可以直接修改输入的张量或数组,而不需要额外的内存来存储结果。

1、将tensor数据放到gpu上
import torch
import torch.nn as nn
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #调用gpu只需要一行代码
# ========================== tensor to cuda
# flag = 0
flag = 1
if flag:
x_cpu = torch.ones((3, 3))
print("x_cpu:\ndevice: {} is_cuda: {} id: {}".format(x_cpu.device, x_cpu.is_cuda, id(x_cpu)))
x_gpu = x_cpu.to(device)
print("x_gpu:\ndevice: {} is_cuda: {} id: {}".format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)))
打印结果:
发现数据id地址发生了变化,说明创建的新的变量存储数据。

2、module转移到gpu上
flag = 1
if flag:
net = nn.Sequential(nn.Linear(3, 3))
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
net.to(device)
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
打印结果:
id地址没有发生变化,执行了inplace操作。

3、torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
推荐:== os.environ.setdefault(“CUDA_VISIBLE_DEVICES”, “2, 3”)==
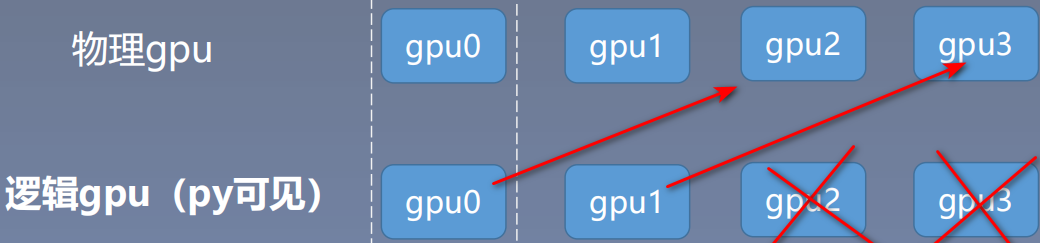
该方法要如何理解呢?
需要理解两个概念:物理gpu和逻辑gpu;物理gpu是我们电脑真实存在的0、1、2、3等显卡,逻辑gpu是Python脚本可见的gpu。
当我们设置2,3时,我们物理gpu连接的是我们真实电脑存在的第2号和第3号gpu。
4、多GPU并行运算
分发 → 并行运算 →结果回收
在AlexNet这篇网络中,使用了多gpu训练,在第三层卷积开始,每个特征图的信息都是从2个gpu获取,在2个gpu提取特征并进行训练,最后再将信息汇总到一起;

4.1 torch.nn.DataParallel
torch.nn.DataParallel(module, device_ids = None, output_device=None, dim=0)
功能:包装模型,实现分发并行机制;假设我们batch_size=16,如果有两块gpu,在训练的时候将会将数据平均分发到每一个gpu上进行训练,也就是每一块gpu训练8个数据。
主要参数:
- module: 需要包装分发的模型
- device_ids : 可分发的gpu,默认分发到所有可见可用gpu
- output_device: 结果输出设备,也就是主gpu上
代码实现:
# -*- coding: utf-8 -*-
# 导入必要的库
import os
import numpy as np
import torch
import torch.nn as nn
# ============================ 手动选择gpu
# flag变量用于控制是否手动选择GPU或根据内存情况自动选择主GPU
# 如果flag为1,则执行以下代码块
flag = 1
if flag:
# 手动选择GPU列表,这里选择第一个GPU
gpu_list = [0]
# 将GPU列表转换为逗号分隔的字符串形式,并设置环境变量CUDA_VISIBLE_DEVICES
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
# 根据CUDA是否可用选择设备,如果可用则使用cuda,否则使用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ============================ 依内存情况自动选择主gpu
# flag变量用于控制是否根据显存情况自动选择主GPU
# 如果flag为1,则执行以下代码块
flag = 1
if flag:
# 定义一个函数get_gpu_memory,用于获取GPU的显存情况
def get_gpu_memory():
import platform
if 'Windows' != platform.system():
import os
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')
memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]
os.system('rm tmp.txt')
else:
memory_gpu = False
print("显存计算功能暂不支持windows操作系统")
return memory_gpu
# 调用get_gpu_memory函数获取显存情况,如果显存可用则执行以下代码块
gpu_memory = get_gpu_memory()
if gpu_memory:
print("\ngpu free memory: {}".format(gpu_memory))
# 根据显存情况对GPU列表进行排序,取排序后的第一个GPU作为主GPU,并设置环境变量CUDA_VISIBLE_DEVICES
gpu_list = np.argsort(gpu_memory)[::-1]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class FooNet(nn.Module):
def __init__(self, neural_num, layers=3):
# 初始化FooNet类,继承自nn.Module,用于构建神经网络模型
super(FooNet, self).__init__()
# 定义一个线性层列表,用于存储多个线性层,层数为layers个
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
def forward(self, x):
# 前向传播方法,输入参数为x,输出结果为x经过多个线性层和ReLU激活函数后的结果
print("\nbatch size in forward: {}".format(x.size()[0])) # 打印输入张量的batch size
for (i, linear) in enumerate(self.linears): # 遍历线性层列表中的每个元素进行循环迭代
x = linear(x) # 将输入张量传入线性层进行计算,得到输出结果x'
x = torch.relu(x) # 对输出结果应用ReLU激活函数,得到新的输出结果x''
return x # 返回新的输出结果x''
if __name__ == "__main__":
# 如果是主程序运行,则执行以下代码块
batch_size = 16 # 设置批量大小为16
inputs = torch.randn(batch_size, 3) # 生成一个形状为(batch_size, 3)的随机张量作为输入数据
labels = torch.randn(batch_size, 3) # 生成一个形状为(batch_size, 3)的随机张量作为标签数据
inputs, labels = inputs.to(device), labels.to(device)
# model
net = FooNet(neural_num=3, layers=3)
net = nn.DataParallel(net)
net.to(device)
# training
for epoch in range(1):
outputs = net(inputs)
print("model outputs.size: {}".format(outputs.size()))
print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
print("device_count :{}".format(torch.cuda.device_count()))
打印结果:

4.2 torch.distributed加速并行训练
DataParallel: 单进程控制多GPU
DistributedDataParallel: 多进程控制多GPU,一起训练模型
和单进程训练不同的是,多进程训练需要注意一下事项:
- 在喂数据的时候,一个batch被分到了多个进程,每个进程在取数据的时候要确保拿到的是不同的数据(DistributedSampler)
- 要告诉每个进程自己是谁,使用哪块GPU(args.local_rank)
- 在做BN的时候注意同步数据。
使用方式
在多进程的启动方面,我们无需自己手写multiprocess进行一系列复杂的CPU、GPU分配任务,PyTorch为我们提供了一个很方便的启动器torch.distributed.launch用于启动文件,所以我们运行训练代码的方式就变成这样:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
初始化
在启动器为我们启动python脚本后,在执行过程中,启动器会将当前进行的index通过参数传递给python,我们可以这样获得当前进程的index:即通过参数local_rank来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device:
def parse():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=0, help='node rank for distributed training')
args = parser.parse_args()
return args
def main():
args = parse()
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(
'nccl',
init_method='env://'
)
device = torch.device(f'cuda:{args.local_rank}')
其中torch.distributed.init_process_group用于初始化GPU通信方式(NCLL)和参数的获取方式(env代表通过环境变量)。使用init_process_group设置GPU之间通信使用的后端和端口,通过NCCL实现GPU通信
Dataloader
在我们初始化data_loader的时候需要使用到torch.utils.data.distributed.DistributedSampler这个特性:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
这样就能给每个进程一个不同的sampler,告诉每个进程自己分别取哪些数据
模型的初始化
和nn.DataParallel的方式一样,
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
使用DistributedDataParallel包装模型, 它能帮助我们为不同GPU上求得的提取进行all reduce(即汇总不同GPU计算所得的梯度,并同步计算结果)。all reduce 后不同GPU中模型的梯度均为all reduce之前各GPU梯度的均值。
5、gpu总结
我们在模型训练当中想要提高训练速率,需要在以下三个地方添加gpu
- 将模型放到gpu上:resnet18_ft.to(device)
- 训练过程中数据: inputs, labels = inputs.to(device), labels.to(device)
- 验证过程中数据: inputs, labels = inputs.to(device), labels.to(device)
常见的gpu报错:
报错1:
RuntimeError: Attempting to deserialize object on a CUDA device but
torch.cuda.is_available() is False. If you are running on a CPU -only machine, please
use torch.load with map_location=torch.device(‘cpu’) to map your storages to the
CPU.
解决: torch.load(path_state_dict, map_location=“cpu”)
报错2:RuntimeError: Error(s) in loading state_dict for FooNet:
Missing key(s) in state_dict: “linears.0.weight”, “linears.1.weight”, “linears.2.weight”.
Unexpected key(s) in state_dict: “module.linears.0.weight”,
“module.linears.1.weight”, “module.linears.2.weight”.
解决:
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items ():
namekey = k[7:] if k.startswith(‘module.’) else k
new_state_dict[namekey] = v

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Go语言错误处理全指南:如何优雅地使用error
- 恭喜!中移集成、广西移动、辽宁移动三家客户学员通过亚信安慧AntDB ACP认证
- python 知识点
- C++版-学生考勤系统 不能运行私信骂我
- 几个资金盘集体跑路——疑似同一个团伙运作!
- 再见卷积神经网络,使用 Transformers 创建计算机视觉模型
- 基于python的电脑租赁管理系统的设计与实现+56026(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案
- Vue用<br>自定义换行,用v-html渲染,hover的时候title也需要使用自定义换行或者显示一行用省略号展示,hover展示全部
- 双位置继电器 DLS-34A 跳闸线圈220V 1A 合闸线圈 1A 板前接线带底座
- ros2 ubuntu 20.04 安装 foxy