商品销售数据采集分析可视化系统 京东商品数据爬取+可视化 大数据 python计算机毕业设计(附源码)?
发布时间:2023年12月30日
博主介绍:?全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业?感兴趣的可以先收藏起来,点赞、关注不迷路?
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Flask框架、Vue框架、requests爬虫、Echarts可视化、MySQL数据库、HTML
使用爬虫爬取京东商品信息数据,对数据进行清洗、存储、分析展示
2、项目界面
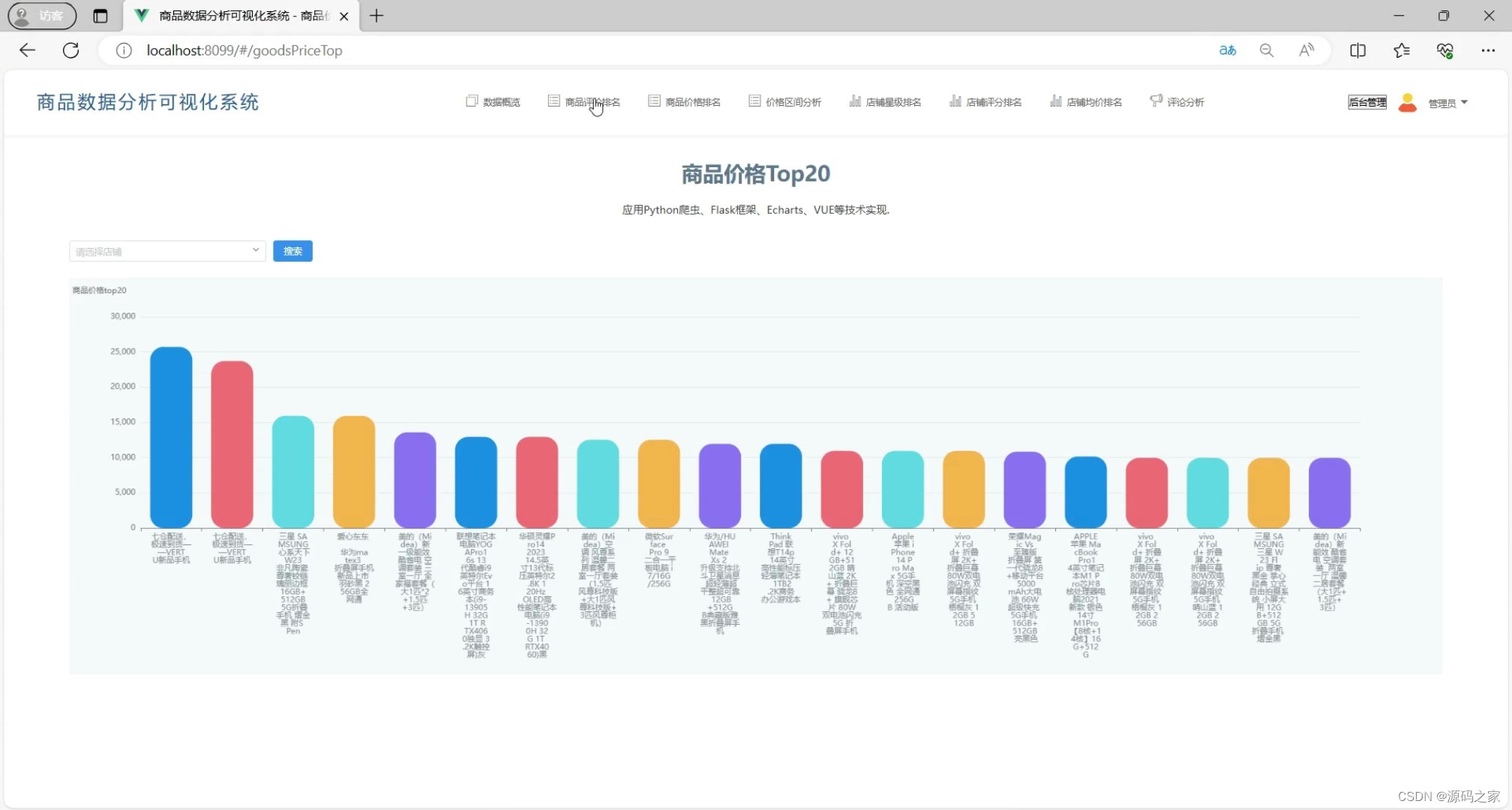
(1)商品价格可视化分析
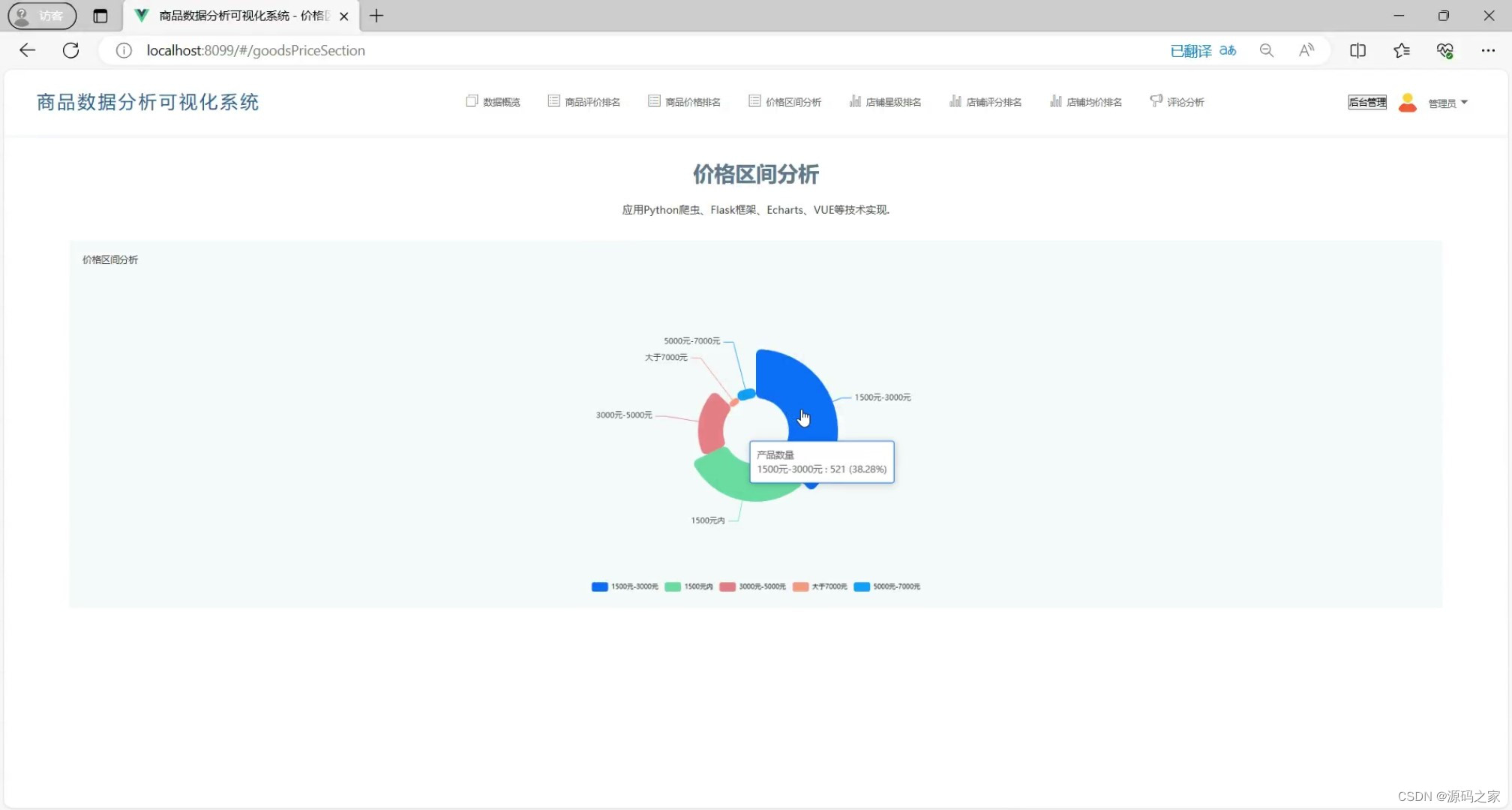
(2)商品价格区间分析
(3)商品数据信息

(4)店铺评分排名

(5)平均价格排名

(6)商品评论分析

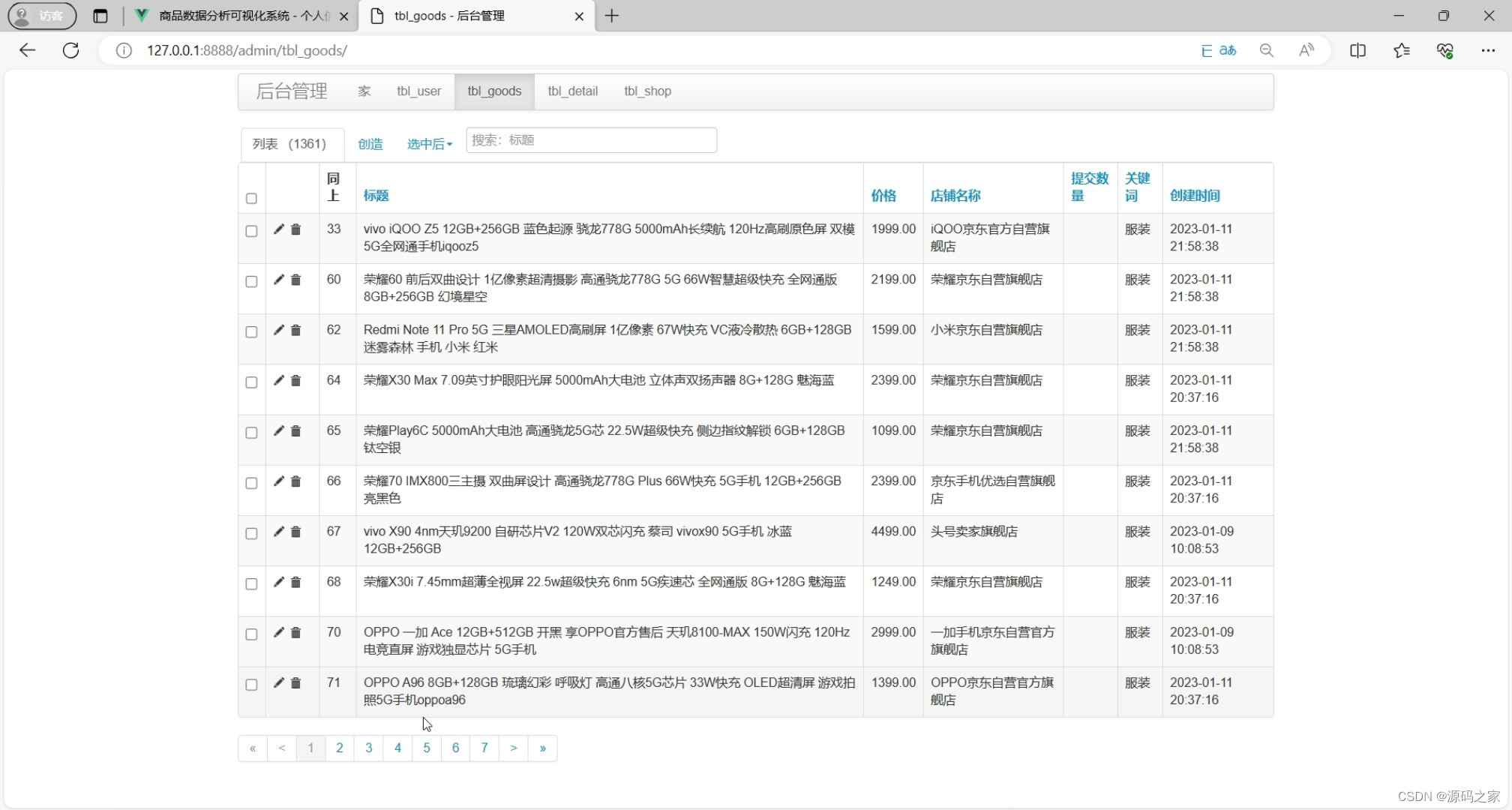
(7)后台数据管理
3、项目说明
(1)介绍
使用爬虫爬取[京东商品信息]数据,对数据进行清洗、存储、分析展示,应用Python爬虫、Flask框架、Vue、Echarts等技术实现。此系统适用于目标网站任何类型的商品分析。
(2)系统功能
1、数据概览
? 使用爬虫爬取京东商品数据后,将数据在此模块进行展示。所有爬虫在文章后面进行介绍
? 搜索:输入商品标题,可对商品进行模糊查询
? 获取评论:管理员功能,点击此按钮调用获取评论爬虫,开始获取对应商品的评论信息,默认爬5页,可在程序中修改爬取页数
? 获取店铺信息:管理员功能,点击此按钮调用获取店铺信息爬虫,获取该商品对应店铺的信息,包括店铺星级、店铺评分等
? 详情:点击详情按钮,跳转到商品详情页面
? 店铺:点击按钮,跳转到店铺页面
2、商品价格排名
? 将所有商品的价格进行排序,使用echarts柱状图从高到低展示前20条数据。支持按照店铺查询店内商品排名
? 搜索:选择店铺(可以输入)后点击搜索,查询该店铺所有商品排名
3、店铺星级排名
? 对已获取信息的店铺星级进行排序,使用echarts折线图进行展示。
4、店铺评分排名
? 对已获取信息的店铺评分进行排序,可分别展示商品评分,物流评分和售后评分。
5、店铺均价排名
? 计算所有店铺的商品均价,使用echarts折线图从高到低展示前20条数据。
6、评论分析
? 展示评论信息的词云图和评分占比,使用词云和饼状图实现。可根据条件展示不同的结果
? 店铺空、商品空:展示所有数据的评论信息词云,以及评分占比
? 店铺不空、商品空:展示该店铺的评论信息词云,以及评分占比
? 店铺不空、商品不空:展示该商品的评论信息词云,以及评分占比
7、个人信息
? 用户查看个人信息,输入新的信息点击提交,可更新个人信息
9、修改密码
? 输入原密码与新密码,可修改密码
10、登录注册
? 用户登录注册
11、用户管理
? 该功能是管理员功能,管理用户信息
? 新增:点击新增按钮,输入用户信息,可添加新用户
? 搜索:输入用户名字和手机号码,点击搜索即可查询用户信息
? 编辑:
? 重置密码:点击重置密码,可重置该用户密码
? 启用/停用:对用户账号状态进行修改,被停用的用户无法登录系统
? 删除:删除该账号
(3)软件架构
后端
- python
- flask
前端
- vue
- iview
- echarts
python库
4、核心代码
def getData(username,page):
all_data = []
log = ''
start_time = getNowDataTimeStr()
key_word_tosql = '空调' #1、输入爬取关键词,该字段是写入数据库的视频类别字段
try:
log += '============ {} 商品数据获取,开始运行 ============\n'.format(getNowDataTimeStr())
for item in range(1, page):
print("------------第" + str(item) + "页 获取开始!")
log += '============ {} 第{}页 开始爬取\n'.format(getNowDataTimeStr(), item)
url = 'https://search.jd.com/Search?keyword=空调&page={}' #2、 输入爬取关键词 例如:%E7%94%B5%E8%84%91
# url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&page={}'
url = url.format(item)
print(url)
log += '============ {} url {}\n'.format(getNowDataTimeStr(), url)
# 页面数据获取
resp = requests.get(url, headers=headers)
response = resp.text
# print(response)
# 解析器 解析数据
soup = BeautifulSoup(response,'html.parser')
# print(soup)
for tony in soup.find_all('div',class_='ml-wrap'):
for sp in tony.find_all('div',class_='goods-list-v2 gl-type-1 J-goods-list'):
for li in sp.find_all('li', class_='gl-item'):
# 标题
title_div = li.find('div', class_='p-name p-name-type-2')
title = title_div.find('em').text
# 详情链接
hreff_a = title_div.find('a')
href = hreff_a['href']
# 价格
price_div = li.find('div',class_='p-price')
price = price_div.find('i').text
# 店铺名
shop_div = li.find('div', class_='p-shop')
shop_name_a = shop_div.find('a')
if shop_name_a == None :
shop_name = '——'
shop_href = '——'
else:
shop_name = shop_name_a.text
# 店铺地址
shop_href = shop_div.find('a')['href']
# 评价地址
commit_href = href + '#comment'
print(title,href,price,shop_name,shop_href,commit_href)
all_data.append({
"title": title,
"href": href,
"price": price,
"shop_name": shop_name,
"shop_href": shop_href,
"commit_href": commit_href
})
print("------------第" + str(item) + "页 获取完毕!")
log += '============ {} 第{}页 获取完毕\n'.format(getNowDataTimeStr(), item)
# TODO 延迟5秒,爬取数据多延时更长时间
time.sleep(2)
# 数据入库
print("------------数据入库开始!")
log += '============ {} 数据入库开始\n'.format(getNowDataTimeStr())
count_insert = 0
count_update = 0
mysql = get_a_conn()
for item in all_data:
sql_select = 'select * from tbl_goods where href = "%s"' % item.get('href')
result = mysql.fetchall(sql_select)
if (len(result) > 0):
sql_update = "update tbl_goods set title='%s',price='%s',shop_name='%s',shop_href='%s',commit_href='%s',create_time='%s' where href = '%s'" \
% (item.get('title'), item.get('price'), item.get('shop_name'), item.get('shop_href'), item.get('commit_href'), start_time, item.get('href'))
mysql.fetchall(sql_update)
count_update += 1
else:
insert_sql = 'insert into tbl_goods (title,href,price,shop_name,shop_href,commit_href,key_word,create_time) values ("%s","%s","%s","%s","%s","%s","%s","%s")' \
% (item.get('title'), item.get('href'), item.get('price'), item.get('shop_name'), item.get('shop_href'), item.get('commit_href'), key_word_tosql, start_time) # 倒数第2个参数,就是写入数据库的【key_word】 例如: '手机'
mysql.fetchall(insert_sql)
count_insert += 1
print("============ 数据入库完毕,新增{}条数据,更新{}条数据 ".format(count_insert, count_update))
log += '============ {} 数据入库完毕,新增{}条数据,更新{}条数据\n'.format(getNowDataTimeStr(), count_insert,
count_update)
log += '============ {} 评论获取,运行成功,结束 ============\n'.format(getNowDataTimeStr())
# 插入日志
saveLog(username, start_time, getNowDataTimeStr(), str(len(all_data)), url, '商品评论', log, '1')
return log
print("------------数据入库完毕!")
print('运行完毕')
except Exception as e:
print(e)
print(traceback.print_exc())
# 插入日志
saveLog(username, start_time, getNowDataTimeStr(), str(len(all_data)), url, '商品信息', log, '0')
log += '============ {} 评论获取,运行失败,结束 ============\n'.format(getNowDataTimeStr(), e)
return log
if __name__ == '__main__':
# TODO 参数代表爬取的页数
getData('管理员后台', 5) # 参数代表爬取的页数
🍅?感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅?
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/vx_biyesheji0001/article/details/135297531
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 中国人民大学与加拿大女王大学金融硕士毕业生:精进、收获、喜悦
- 智慧校园大数据云存储和云灾备
- 晶圆表面缺陷检测现状概述
- 防抖与节流:Vue中的优化技巧
- 把袜子翻过来,里朝外,挂起来,整个世界都是你的礼物。
- crontab任务调度
- Windows进程和线程and线程局部存储TLS---notes
- 【力扣刷题练习】33. 搜索旋转排序数组
- SIP(Session Initiation Protocol,会话初始协议)
- C++基础-this指针详解