生成超清分辨率视频,南洋理工开源Upscale-A-Video
大模型在生成高质量图像方面表现出色,但在生成视频任务中,经常会面临视频不连贯、图像模糊、掉帧等问题。
这主要是因为生成式抽样过程中的随机性,会在视频序列中引入无法预测的帧跳动。同时现有方法仅考虑了局部视频片段的时空一致性,无法保证整个长视频的整体连贯性。
为了解决这些难题,新加坡南洋理工大学的研究人员开发了一种Upscale-A-Video框架,无需任何训练便能快速集成到大模型中,提供视频超分辨率、去噪、还原等强大功能。
论文地址:https://arxiv.org/abs/2312.06640
开源地址:https://github.com/sczhou/Upscale-A-Video
项目地址:https://shangchenzhou.com/projects/upscale-a-video/
Upscale-A-Video主要借鉴了图像模型中的扩散方法,设计了一种无需大规模训练即可快速迁移的框架。
该框架融合了局部和全局两种策略来维持时间的一致性。局部层,模型通过 3D 卷积和时序注意力层增强特征提取网络U-Net在短视频片段内的一致性。
全局层,则通过光流指导的循环潜码传播功能,提供跨视频片段强化更长时间尺度下的连贯性。
除了时间一致性,Upscale-A-Video还可以通过文本提示指导细节纹理的生成,不同的提示词可产生不同风格、质量。

时序U-Net
U-Net作为特征提取网络,对视频质量起决定性作用。传统只考虑空间信息的U-Net在处理视频时往往会引入高频误差,表现为抖动和闪烁。
Upscale-A-Video通过向U-Net中插入3D卷积块和时序自注意力层,增强其对时间维度的建模能力。这使U-Net可以学习视频数据中帧与帧之间的依赖,从而在局部序列内实现一致的超分辨重建。
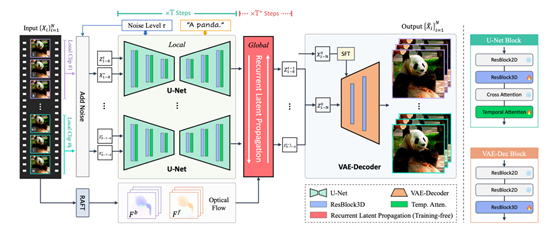
另一方面,研究人员选择固定U-Net中的空间层参数,只对新增时序层进行调优。这种策略的优点是可以避免从头大规模预训练,充分利用图像模型中提取的丰富特征。同时也缩短了网络收敛的时间,起到事半功倍的效果。
循环潜码
时序U-Net的作用范围仅局限于短视频片段,难以约束更长序列的全局一致性。而视频抖动和质量波动往往都是长时间范围内的现象。
为解决这一问题,Upscale-A-Video设计了一个基于光流的循环潜码传播模块。
该模块可以在不增加训练参数的情况下,通过前向和后向传播推断所有帧的潜码信息,有效扩大模型感知的时间范围。

具体来说,该模块利用预先估计的光流场,进行逐帧传播与融合。它根据光流的前向-后向一致性误差判断传播的有效性,只选择误差小于阈值的区域进行特征传播。
而超出阈值的区域则保留当前帧信息。这种混合融合策略,既利用了光流建模的长期信息,又避免了传播错误的累积。
文本提示增强指导
Upscale-A-Video还支持文本条件和噪声水平的控制,用户可以依据实际情况,引导模型生成不同风格和质量的结果。

文本提示可以指导模型合成更逼真的细节,如动物皮毛、油画笔触等。噪声水平的调整也提供了在还原与生成间权衡的灵活性:加入更少噪声有利于保真,而更高水平的噪声则促使模型补充更丰富的细节。
这种可控制的生成能力进一步增强了Upscale-A-Video处理复杂真实场景的鲁棒性
实验数据
研究人员从定量和定性两个方面全面验证了Upscale-A-Video的性能。在四个合成低质量视频基准上,皆取得了最高的峰值信号噪声比和最低的流式感知损失。
流式验证集和AI生成视频上, Upscale-A-Video的非参考画质评分也高居各方法之首。这也证明了Upscale-A-Video在保真还原和感知质量上的优势。

从生成效果对比来看,Upscale-A-Video重建的视频展现了更高实际分辨率下的细节层次;运动轨迹更加连贯自然,没有明显的抖动和裂缝。这得益于强大的扩散先验和时空一致性优化。
相比之下,卷积神经网络和扩散等方法会出现模糊不清,失真等效果,无法达到同等水准。
本文素材来源Upscale-A-Video论文,如有侵权请联系删除
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#,入门教程(19)——循环语句(for,while,foreach)的基础知识
- CodeWave智能开发平台--03--目标:应用创建--06变量作用域和前后端服务逻辑
- Fiddler抓包,怎么抓抓得好抓得快?
- nacos与eureka的区别
- 2024年【裂解(裂化)工艺】考试报名及裂解(裂化)工艺考试总结
- flink 1.18 sql gateway /sql gateway jdbc
- 使用Python编写自动传输脚本详解
- ESP32-WIFI(Arduino)
- Python迭代(python系列24)
- c# 视频播放之Windows Media Player