【学习代码】PyTorch代码 练习
发布时间:2023年12月23日
文章目录
Attention
SEAttention【显式地建模特征通道之间的相互依赖关系】【easy】
【论文解读】SENet网络: https://zhuanlan.zhihu.com/p/80123284

注意点:最后是sigmoid()
代码来源:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/SEAttention.py
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid() # 这里是sigmoid
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
CBAM Attention【SEAttention通道注意力 + 空间注意力】【middle】
图画得不错
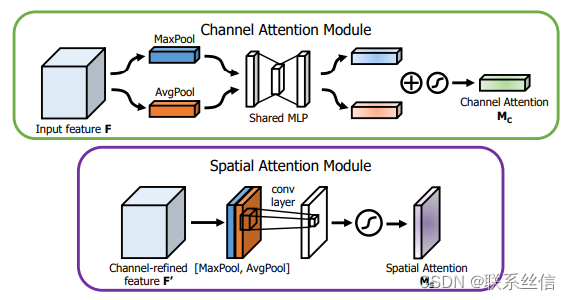
注意点:
1. 最后 也是接sigmoid激活 ,限制值 0-1范围
2. 是 残差连接
3. 逐元素相乘 *,自动 会用 广播机制
代码来源:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/CBAM.py
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16):
super().__init__()
self.maxpool=nn.AdaptiveMaxPool2d(1)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.se=nn.Sequential(
nn.Conv2d(channel,channel//reduction,1,bias=False),
nn.ReLU(),
nn.Conv2d(channel//reduction,channel,1,bias=False)
)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
print(f'ChannelAttention ===============>')
print(f'x.shape = {x.shape}')
max_result=self.maxpool(x)
avg_result=self.avgpool(x)
max_out=self.se(max_result)
avg_out=self.se(avg_result)
output=self.sigmoid(max_out+avg_out)
print(f'output.shape = {output.shape}') # output.shape = torch.Size([50, 512, 1, 1])
return output
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
print(f'SpatialAttention ===============>')
print(f'x.shape = {x.shape}')
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
print(f'output.shape = {output.shape}') # output.shape = torch.Size([50, 1, 7, 7])
return output
class CBAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,kernel_size=49):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(kernel_size=kernel_size)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
residual=x
out=x*self.ca(x) # 逐元素相乘 *,自动 会用 广播机制
out=out*self.sa(out)
return out+residual
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
SelfAttention【重点:理解意义 and 实践!】【hard】
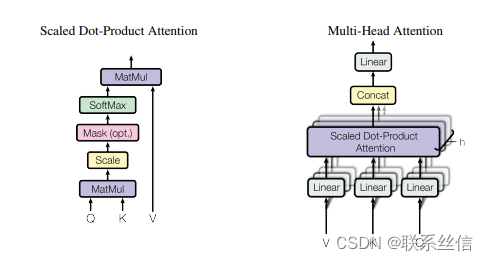
注意点:
- 理解矩阵乘法的意义,torch.matmul 矩阵乘法
- 理解各个参数的含义
代码来源:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/SelfAttention.py
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
文章来源:https://blog.csdn.net/weixin_43154149/article/details/135170638
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!