SE-Net:Squeeze-and-Excitation Networks(CVPR2018)

文章目录
原文链接
源代码
Abstract
卷积神经网络(cnn)的核心构建块是卷积算子,它使网络能够通过在每层的局部接受域中融合空间和通道信息来构建信息特征。之前的广泛研究已经调查了这种关系的空间成分,试图通过提高整个特征层次的空间编码质量来加强CNN的表征能力。
在本文中,我们将重点放在通道关系上,并提出了一种新的架构单元,我们称之为“挤压和激励”(SE)块,该单元通过明确建模通道之间的相互依赖性,自适应地重新校准通道特征响应。我们表明,这些块可以堆叠在一起形成SENet架构,在不同的数据集上非常有效地泛化
我们进一步证明,SE块在略微增加计算成本的情况下,为现有最先进的CNNs带来了显著的性能改进。
挤压和激励网络构成了我们2017年ILSVRC分类提交的基础,该分类提交获得了第一名,并将前5名的错误率降低到2.251%,比2016年的获奖作品相对提高了25%
Introduction
表征的重要性
计算机视觉研究的一个中心主题是寻找更强大的表征,只捕获图像中对于给定任务最显著的那些属性,从而提高性能。作为一种广泛应用于视觉任务的模型家族,新的神经网络架构设计的发展现在代表了这一研究的关键前沿。
以前的方向
最近的研究表明,通过将学习机制集成到网络中,可以增强cnn产生的表征,从而帮助捕获特征之间的空间相关性。其中一种方法,由Inception系列架构[5],[6]推广,将多尺度进程合并到网络模块中以实现改进的性能。进一步的研究试图更好地模拟空间依赖性[7],[8],并将空间注意力纳入网络结构[9]。
本文提出
在本文中,我们研究了网络设计的另一个方面——通道之间的关系。我们引入了一个新的架构单元,我们称之为挤压和激励(SE)块,其目标是通过明确地建模其卷积特征通道之间的相互依赖性来提高网络产生的表征的质量。为此,我们提出了一种允许网络执行特征重新校准的机制,通过该机制,网络可以学习使用全局信息来选择性地强调有用的特征并抑制不太有用的特征。
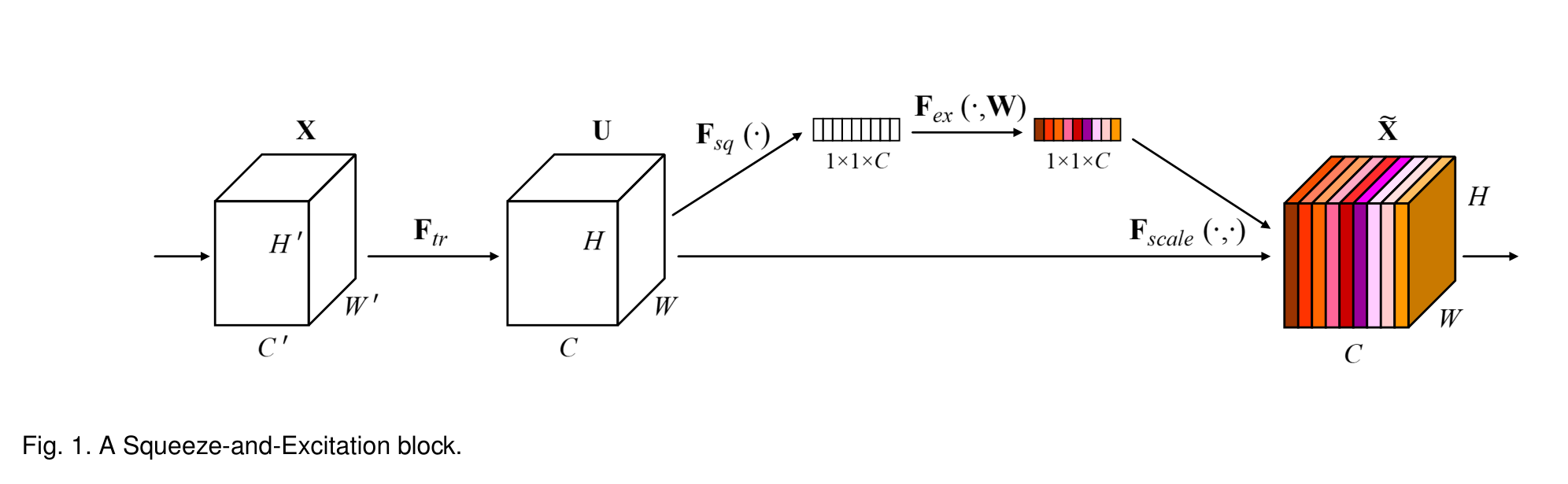
SE构建块的结构如图1所示。(全部跳过直接见summarize)对于任意给定的变换Ftr,将输入X映射到U∈R H×W×C的特征映射,例如卷积,我们可以构造一个相应的SE块来执行特征重新校准。特征U首先通过挤压操作传递,该操作通过聚合跨空间维度的特征映射(H ×W)生成通道描述符。这个描述符的功能是产生通道特征响应的全局分布的嵌入,允许来自网络的全局接受域的信息被其所有层使用。聚合之后是激励操作,该操作采用简单的自门机制的形式,将嵌入作为输入并产生每个信道调制权重的集合。这些权重被应用到特征映射U上,以生成SE块的输出,该块可以直接馈送到网络的后续层。
SE块的结构很简单,可以直接在现有的最先进的体系结构中使用,通过用SE对应的组件替换组件,可以有效地增强性能。SE块在计算上也是轻量级的,只会略微增加模型复杂性和计算负担。
为了使这些说法站得住脚,我们开发了几个SENets,并对ImageNet数据集进行了广泛的评估[10]。我们还展示了ImageNet之外的结果,表明我们的方法的好处并不局限于特定的数据集或任务。通过使用SENets,我们在2017年ILSVRC分类比赛中获得了第一名。我们的最佳模型集成在测试集1上实现了2.251%的前5误差。与前一年的优胜者相比,这大约代表了25%的相对改进(相对改进用的真棒)。
Related Work
Deeper Architecture
VGGNets和Inception模型表明,增加网络的深度可以显著提高其能够学习的表征的质量,此后的工作进行了进一步的改进
相比之下,我们表明,为单元提供一种机制,使用全局信息显式地模拟通道之间的动态、非线性依赖关系,可以简化学习过程,并显着增强网络的表征能力
Algorithmic Architecture Search
旨在放弃手工架构设计,而寻求自动学习网络的结构,此前提出了许多架构搜索算法,且强化学习技术取得了有力的结果
我们提出SE块可以用作这些搜索算法的原子构建块,并且在并发工作中被证明是非常有效的[45]。
Attention and gating mechanisms
注意力可以解释为一种将可用计算资源分配向信号中信息量最大的组成部分倾斜的手段(资源只给天才)[46]、[47]、[48]、[49]、[50]、[51]。一些研究对空间注意力和通道注意力的结合使用进行了有趣的研究[58],[59]。Wang等人[58]引入了一种基于沙漏模块[8]的强大的trunk-and-mask注意机制,该机制被插入到深度残差网络的中间阶段之间。相比之下,我们提出的SE块包含一个轻量级的门控机制,该机制侧重于通过以计算高效的方式对通道相关关系进行建模来增强网络的表示能力。
Squeeze-and-Excitation Blocks
SE块是一个计算单元,它可以建立在映射输入X∈R(H‘W’C’)的变换Ftr映射到U∈R(HWC),在下面的符号中,我们取F tr为一个常规算子,并使用V = [V 1, V 2,…,vc]表示学习到的滤波器核集合,其中vc表示第c个滤波器的参数。输出U = [u 1 ,u 2 ,…,u c ]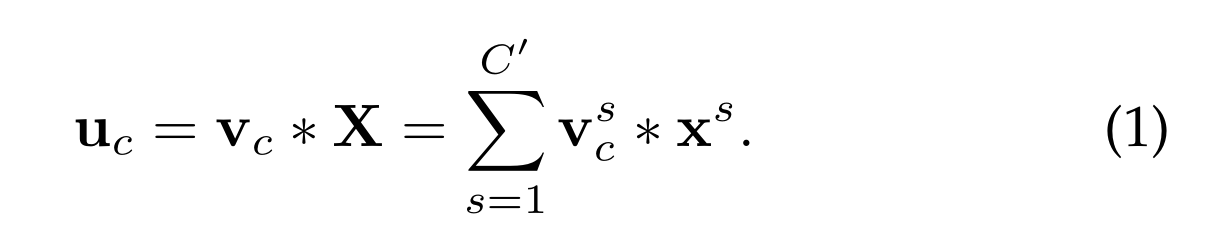
其中*表示卷积
v s c是一个二维空间核,表示作用于X的相应通道的v c的单个通道。为了简化符号,省略了偏置项。由于输出是通过所有通道的求和产生的,通道依赖关系隐式地嵌入在vc中,但与滤波器捕获的局部空间相关性纠缠在一起。由卷积建模的通道关系本质上是隐式的和局部的(最顶层的通道关系除外)。我们期望通过显式建模通道相互依赖性来增强卷积特征的学习,以便网络能够提高其对信息特征的敏感性,这些信息特征可以被后续转换利用。因此,我们希望为其提供对全局信息的访问,并在将其馈送到下一个变换之前,分挤压和激励两步重新校准滤波器响应。图1显示了SE块的结构示意图。
Squeeze: Global Information Embedding
为了解决利用通道依赖性的问题,我们首先考虑输出特征中每个通道的信号。每个学习到的过滤器都与一个局部接受域一起操作,因此转换输出U的每个单元都无法利用该区域之外的上下文信息
为了缓解这个问题,我们建议将全局空间信息压缩到信道描述符中。这是通过使用全局平均池来生成通道统计信息来实现的。形式上,统计量z∈R C通过U的空间维度H ×W收缩生成,使得z的c-th元素计算为: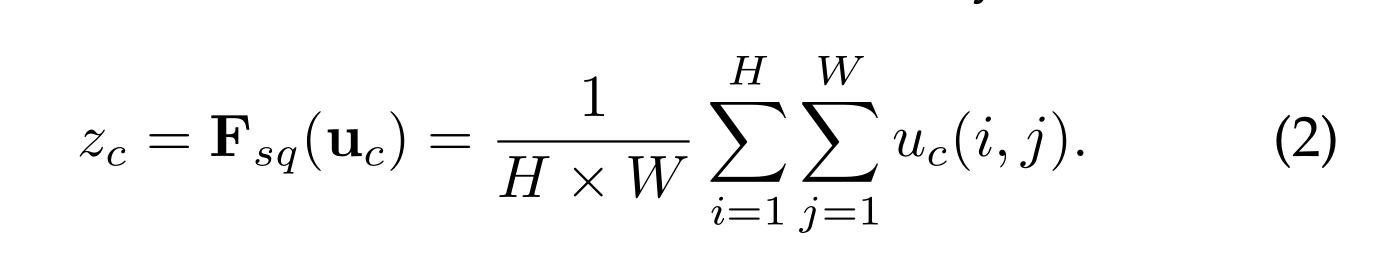
转换U的输出可以被解释为局部描述符的集合,这些局部描述符的统计量可以表达整个图像。利用这些信息在之前的特征工程工作中很普遍[60],[61],[62]。我们选择最简单的聚合技术,即全局平均池,并注意到这里也可以采用更复杂的策略
Excitation: Adaptive Recalibration
为了利用在挤压操作中聚合的信息,我们在它之后进行第二个操作,目的是完全捕获与通道相关的依赖关系。为了实现这一目标,函数必须满足两个标准:首先,它必须是灵活的(特别是,它必须能够学习通道之间的非线性相互作用),其次,它必须学习非互斥关系,因为我们希望确保允许多个通道被强调(而不是强制一个热激活)。为了满足这些标准,我们选择采用一种简单的s型激活门控机制: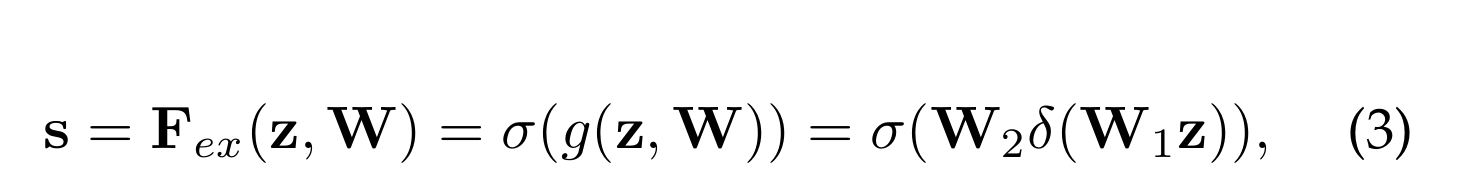
δ表示Relu,W1∈R C/r×C,W2∈R C×C/r
为了限制模型复杂性和帮助一般化,我们通过在非线性周围形成两个完全连接(FC)层的瓶颈来参数化门控机制
一个降维比为r的降维层,一个ReLU,然后是返回到变换输出U的通道维数的增维层。块的最终输出是通过用激活s重新缩放U来获得的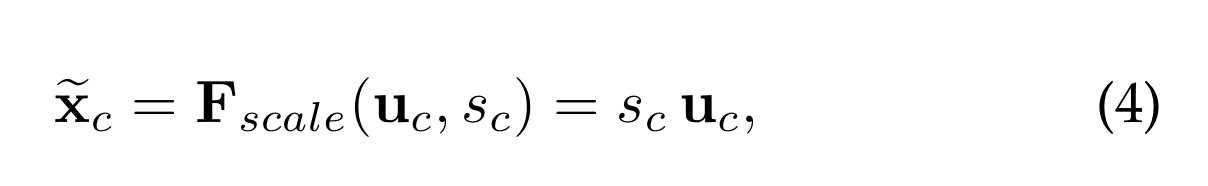
F scale (u c,s c)是指标量s c与特征映射u c∈R H×W之间的逐通道乘法
激励算子将特定于输入的描述符z映射到一组信道权重。在这方面,SE块本质上引入了以输入为条件的动态,可以将其视为通道上的自注意函数,通道的关系不局限于卷积滤波器响应的局部接受野
Instantiations
SE块可以在每个卷积块之后插入分支聚合之前,此外,SE块的灵活性意味着它可以直接应用于标准卷积之外的转换。
每个SE块在挤压阶段使用一个全局平均池化操作,在激励阶段使用两个小FC层,然后是一个廉价的通道缩放操作
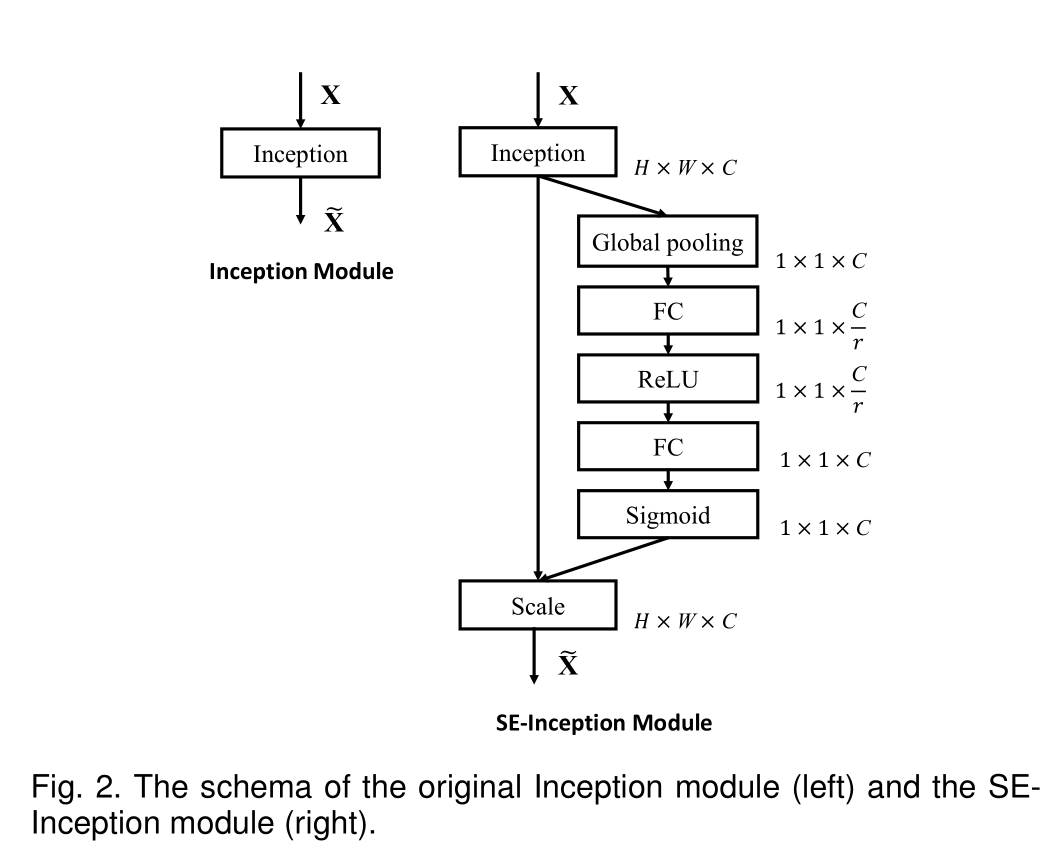
SE-Inception Model
SE-ResNet Model
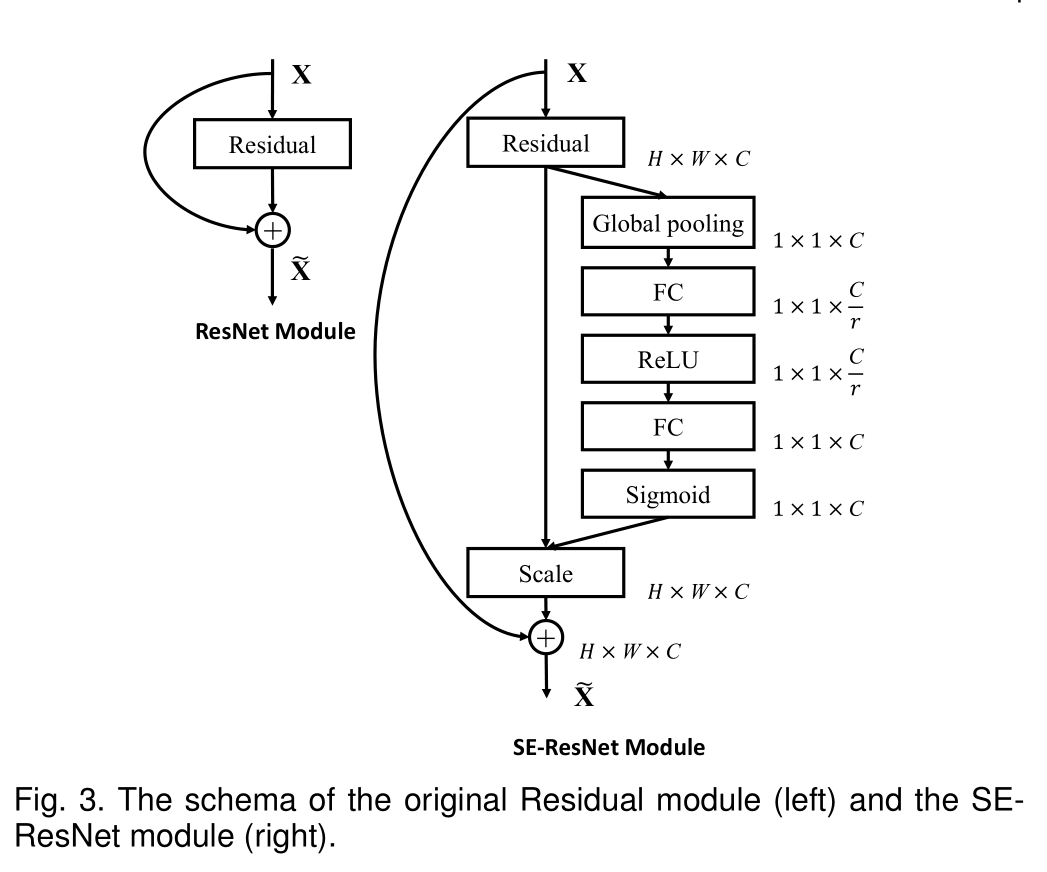

括号内列出了剩余构建块的形状和具有特定参数设置的操作,外部显示了一个阶段中堆叠块的数量。fc后面的内括号表示SE模块中两个完全连接层的输出维度。
summarize
SE块首先通过Ftr将X映射到U,然后通过挤压将全局空间信息压缩到通道描述符中得到统计量Zc,接着通过激励算子完全捕获与通道相关的依赖关系,得到s,最后经过Fscale算子得到最终的输出X~
Model and Computation Complexity
每个SE块在挤压阶段使用一个全局平均池化操作,在激励阶段使用两个小FC层,然后是一个廉价的通道缩放操作。总的来说,当将缩减比r设置为16时,SE-ResNet-50需要~ 3.87 GFLOPs,相当于比原始ResNet-50相对增加0.26%。为了换取这一轻微的额外计算负担,SE-ResNet-50的精度超过了ResNet-50,实际上,接近更深的ResNet-101网络,需要~ 7.58 GFLOPs(表2)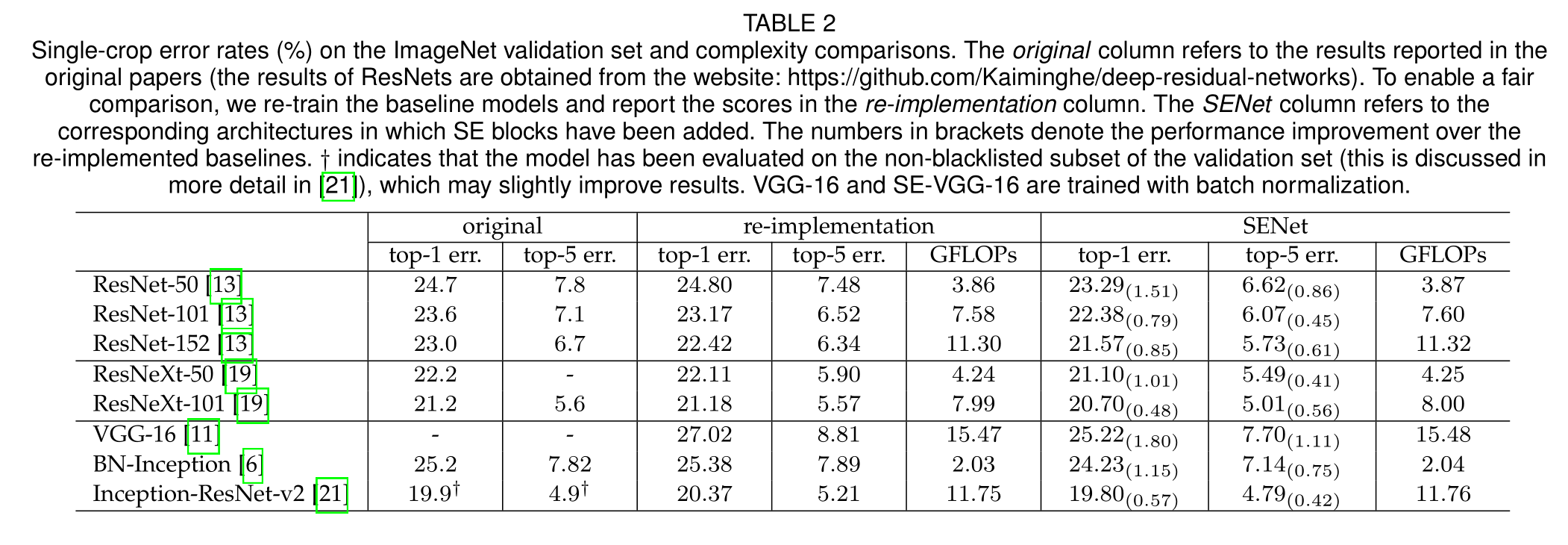
SENet列指的是在其中添加了SE块的相应体系结构。括号中的数字表示相对于重新实现的基线的性能改进。?表示该模型已经在验证集的非黑名单子集上进行了评估,这可能会略微改善结果。VGG-16和SE-VGG-16采用批归一化训练
相对模型性能的贡献 ,SE块产生的少量额外计算成本是可接受的
接下来我们考虑由提议的SE块引入的附加参数。这些附加参数仅由门控机制的两个FC层产生,因此只占总网络容量的一小部分。具体而言,这些FC层的权重参数引入的总数为:

其中r表示缩放比,S表示阶段数,Cs表示输出通道的维度,Ns表示阶段S重复块的数量(当在FC层中使用偏置项时,引入的参数和计算成本通常可以忽略不计)。
Experiments
Image Classification
在ImageNet上训练基线架构和相应的SE Model。SENets表现出改进的优化特性,并在整个训练过程中产生持续的性能收益
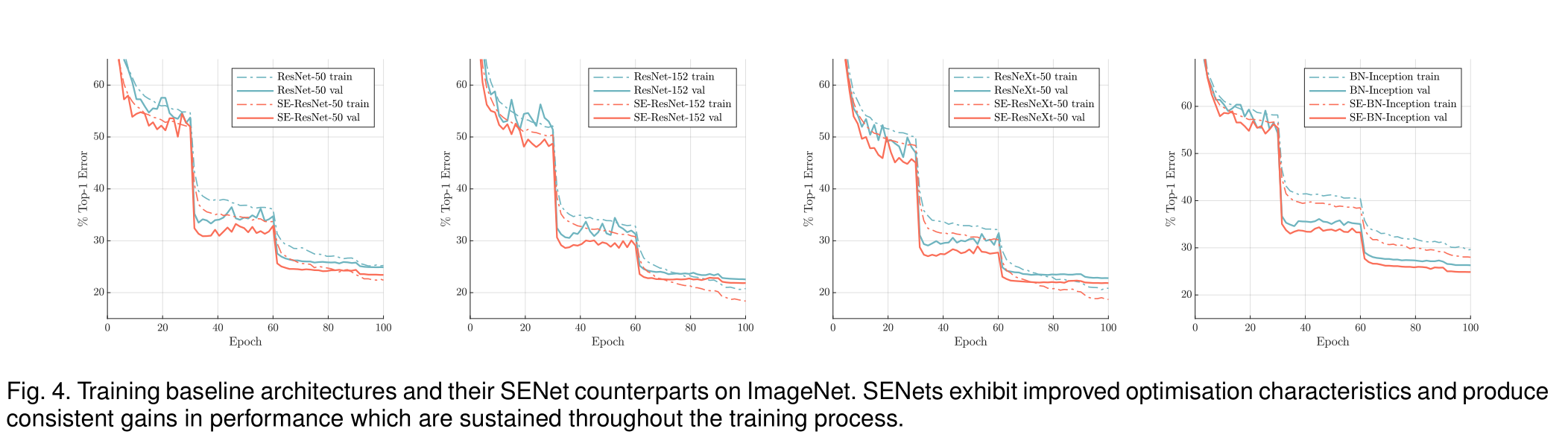
在SE块在增加少量计算成本的情况下,大幅提高了准确性

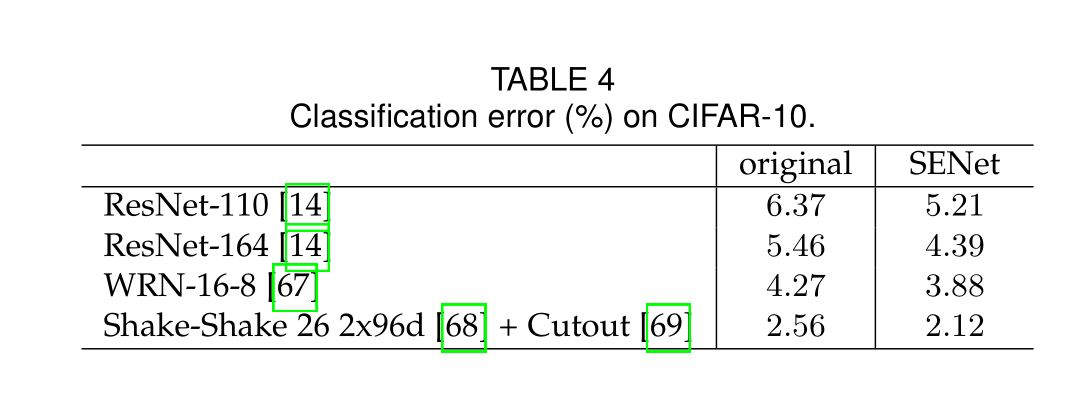
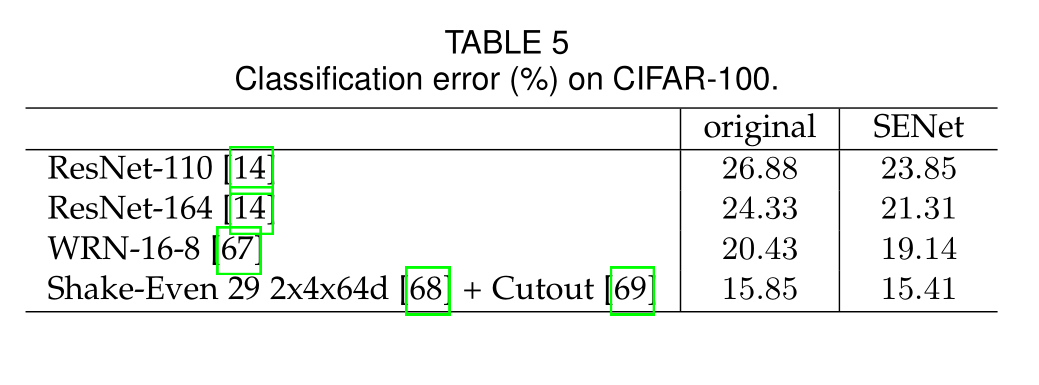
表4和表5说明了SE块在其他数据集上仍旧表现优异
Scene Classification
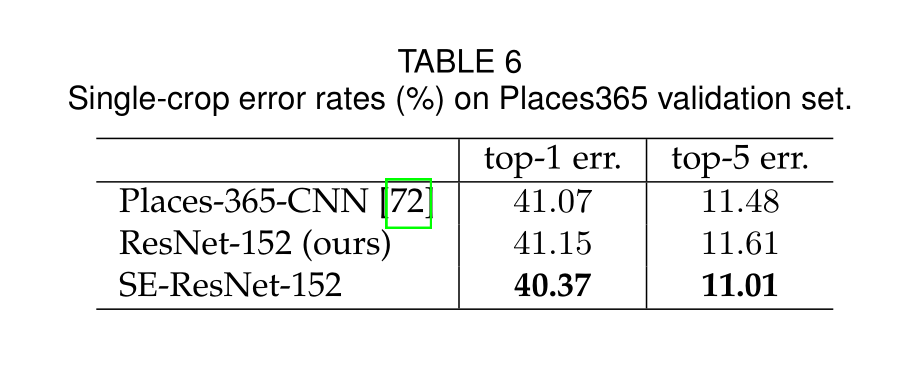
SE块也可以提高场景分类的精度
Object Detection on COCO
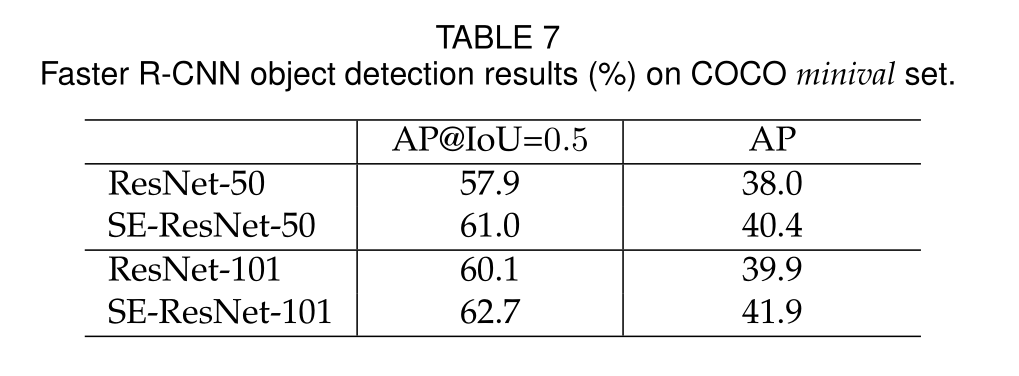
SE块在COCO数据集上表现良好,证明了SE块的通用性
ILSVRC 2017 Classification Competition
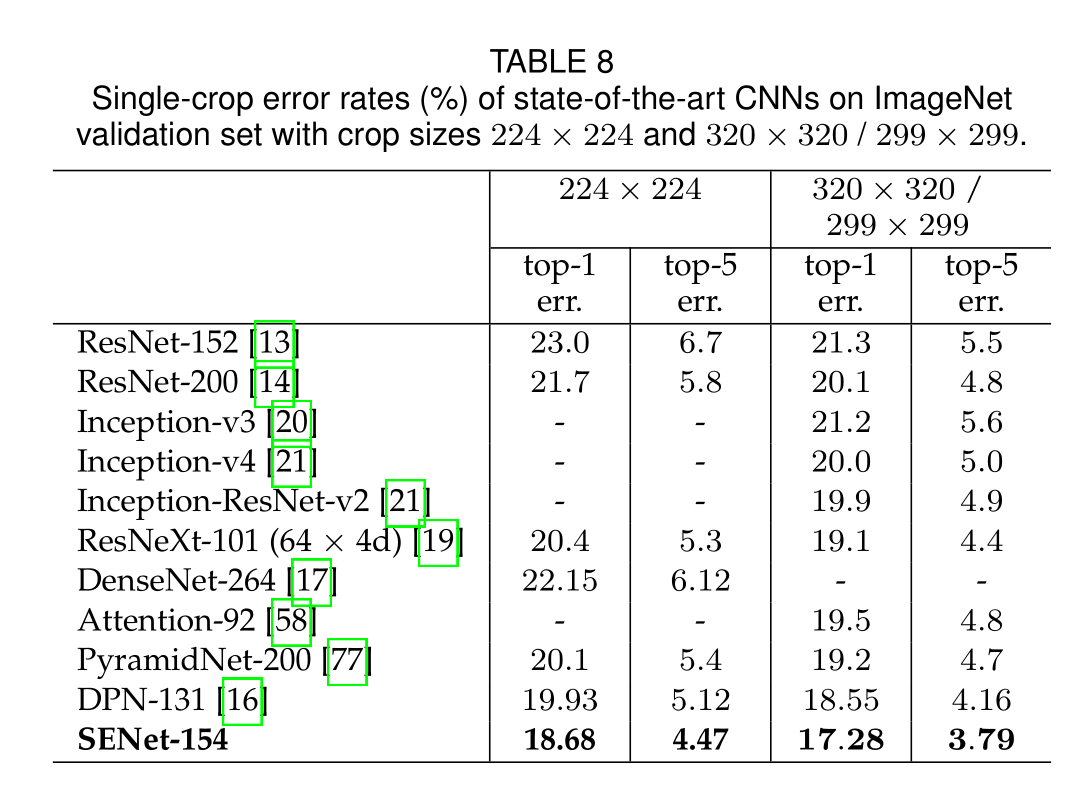
在ILSVRC 2017比赛中取得了最佳结果
Ablation Study
Reduction ratio
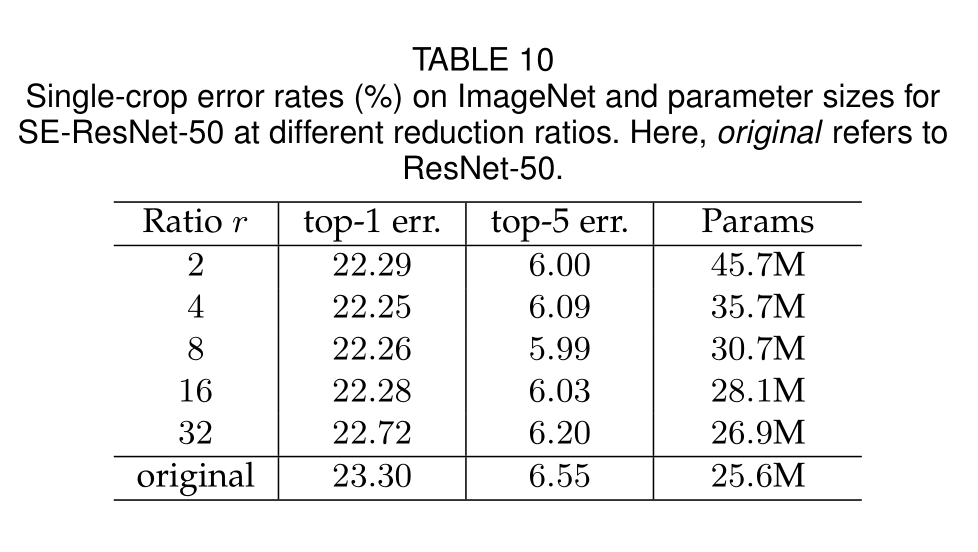
性能在一定的减排量范围内是稳健的,复杂度的增加不会单调地提高性能,而较小的比例会显著增加模型的参数大小,在上表中r=16是速度和精度的最佳平衡
Squeeze Operator
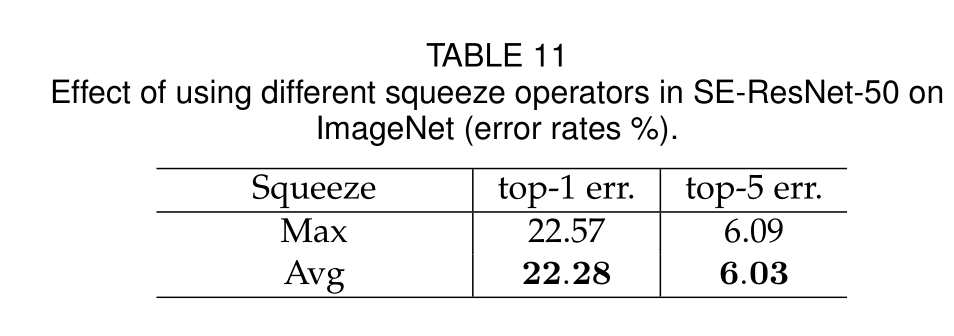
显然平均池化的性能略好
Excitation Operator
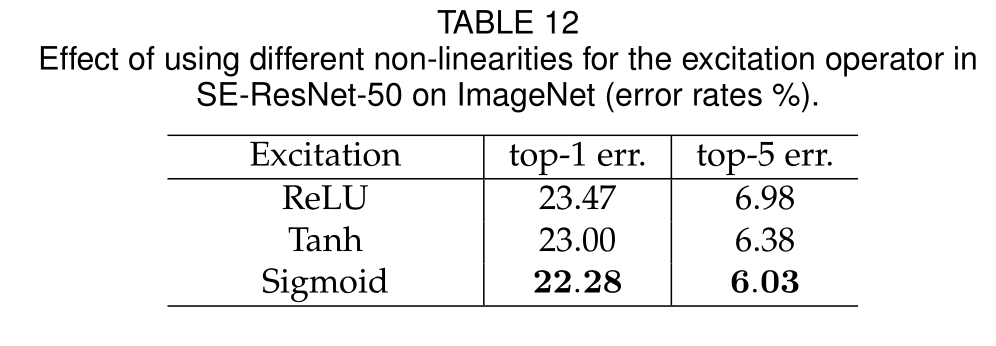
通过比较发现sigmoid函数取得了最佳结果
Different stages
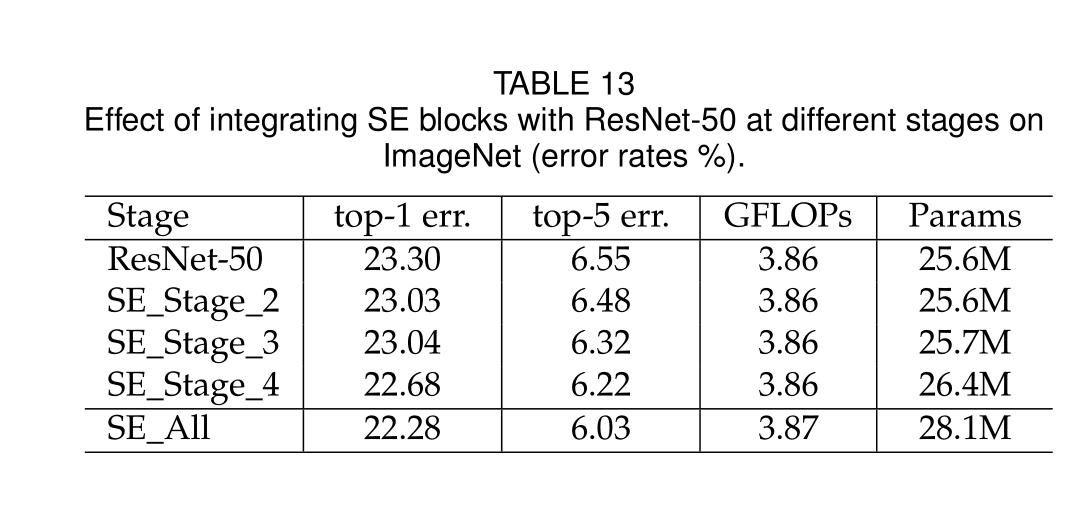
SE块在不同阶段产生的增益是互补的,它们可以有效地组合在一起,进一步增强网络性能
Integration strategy
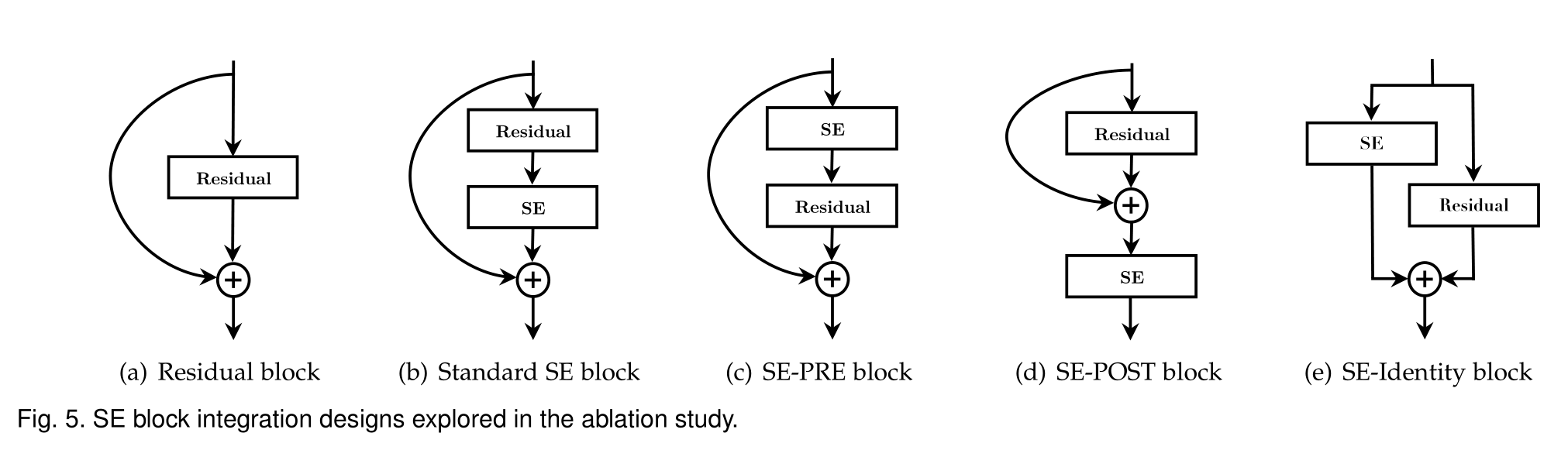
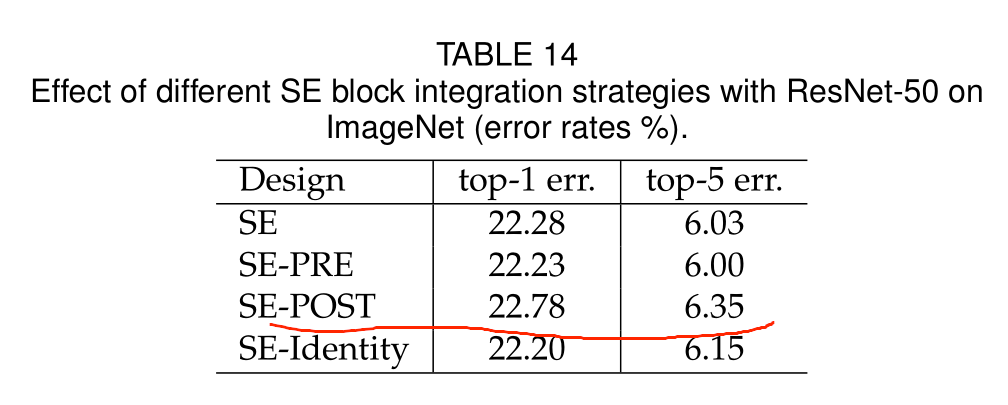
该实验表面,SE块应放在分支聚合之前
将SE块之间放在3×3卷积层之后,使用更少的参数实现了相当的分类精度
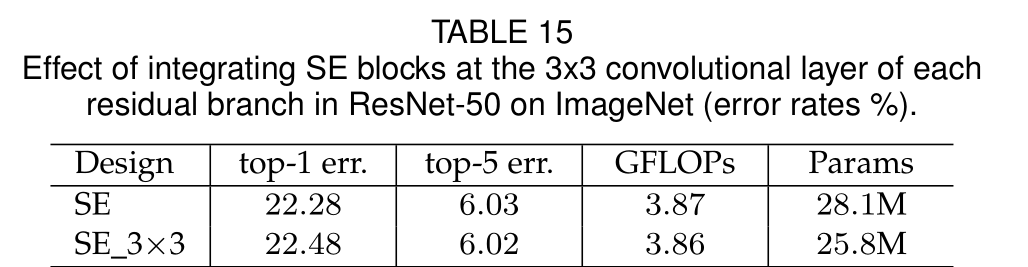
Role of SE Blocks
Effect of Squeeze
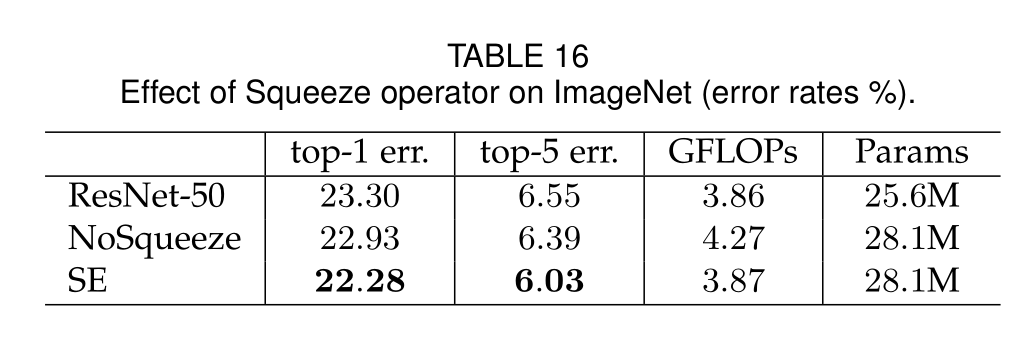
上表中可以得到使用全局信息对模型性能有显著影响,强调了挤压操作的重要性
Role of Excitation
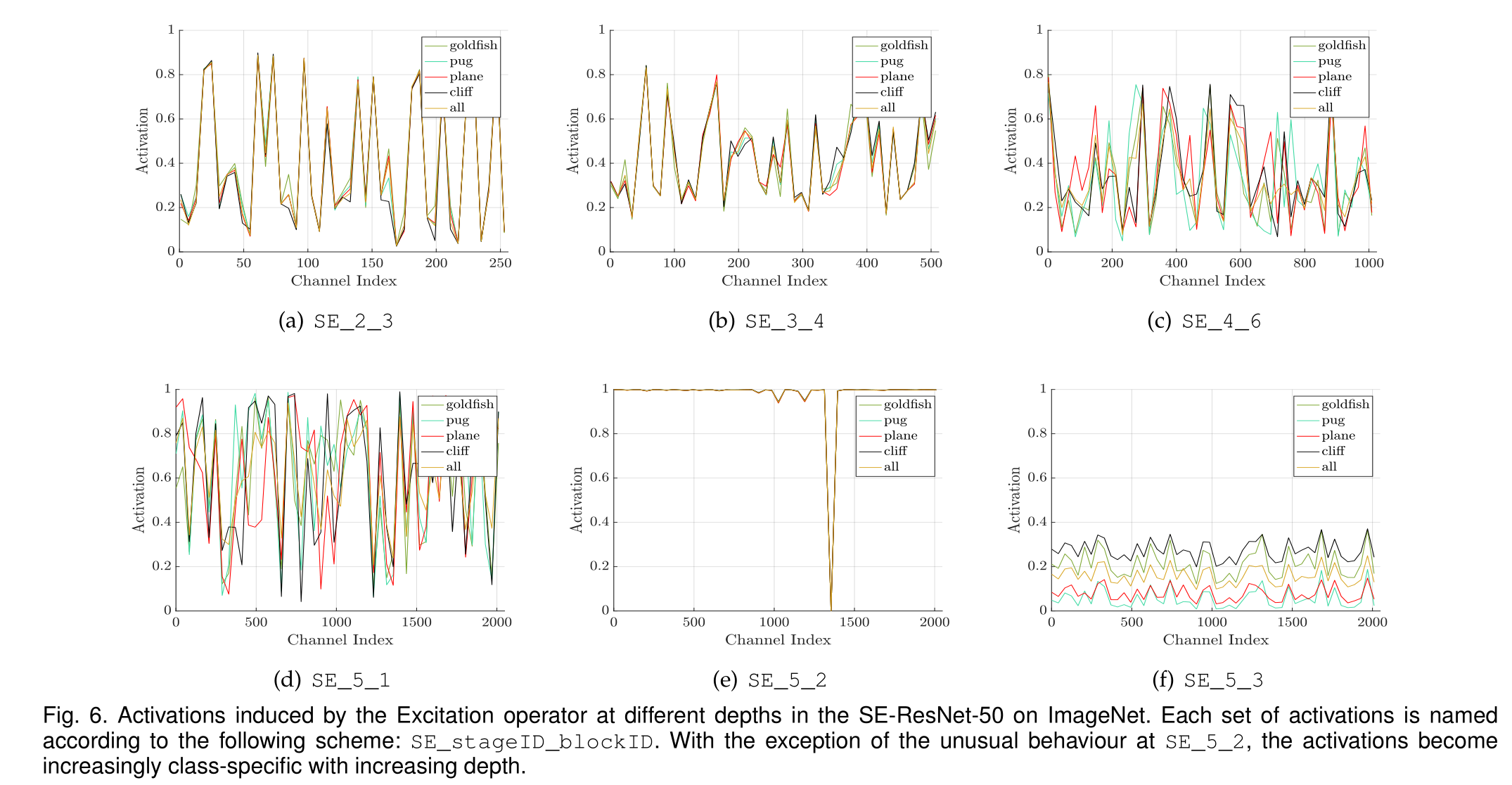
除了SE_5_2的异常行为外,随着深度的增加,激活变得越来越具有类特异性。较早的层特征通常更普遍(例如,在分类任务的背景下,类别不可知论),而较晚的层特征表现出更高水平的特异性。上图SE5-25-3出现了趋于饱和的状态,该结果表明,通过在最后阶段删除SE块,可以显著减少额外的参数计数,而性能损失很小。
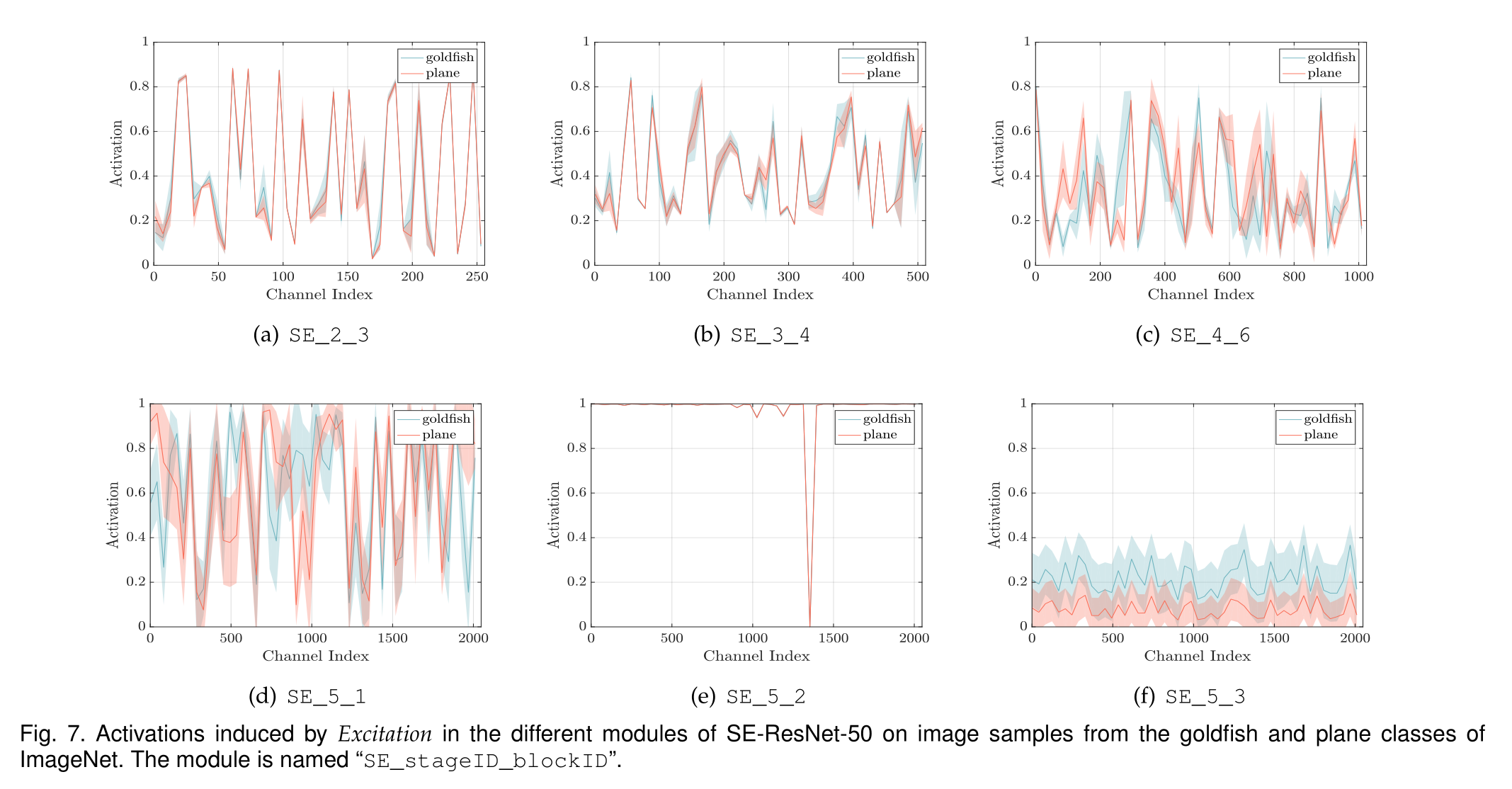
显示了两个样本类(金鱼和飞机)在同一类中图像实例的激活的均值和标准差。我们观察到与类间可视化一致的趋势,表明SE块的动态行为在类和类内的实例中都是不同的。特别是在网络的后一层,在单个类中存在相当大的表示多样性,网络学习利用特征重新校准来提高其判别性能
总之,SE块生成特定于实例的响应,这些响应在体系结构的不同层支持模型日益增长的特定于类的需求
Conclusion
一系列的实验完全支持起了模型的有效性
在本文中,我们提出了SE块,这是一个架构单元,旨在通过使网络能够执行动态信道特征重新校准来提高网络的表示能力。广泛的实验表明了SENets的有效性,它在多个数据集和任务中实现了最先进的性能。
此外,SE块还揭示了以前的体系结构无法充分地对通道相关的特征依赖进行建模的问题。我们希望这一见解可以证明对其他需要强判别特征的任务有用。
最后,由SE块产生的特征重要性值可以用于其他任务,例如用于模型压缩的网络修剪
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【csapp】bufferlab
- [自用代码]基于LSTM的广州车牌售价预测
- 【目标检测】Anchor-based模型:基于K-means算法获取自制数据集的Anchor(yolo源码)
- 分布式事务基本原则和设计理念
- LeetCode 20.有效的括号(python版)
- QSettings功能介绍及应用
- 苹果小绿灯电路。
- 描述一个bug及定义bug的级别
- spring retry 配置及使用
- 代码随想录算法训练营Day5 | 454.四数相加||、383.赎金信、35.三个之和、18.四数之和